高德广告工程 AI Native 全流程提效实践
来源:互联网 更新时间:2026-06-16 12:56
高德广告工程团队最近在 AI Native 方向上做了一些阶段性探索,覆盖研发、测试、运维和知识沉淀几个环节。今天这篇文章,就把这些实践和思考整理出来,供大家参考。
先给出一个核心判断:
AI Native 不是“用 AI 写代码”,而是把整个研发体系设计成 AI 能持续参与、稳定执行、可验证、可复用、可进化的工程闭环。
基于这个判断,我们把 Spec、知识、验收、执行状态和 Skills 这几样东西,从辅助性材料升级成了和代码同等地位的工程产物。配合广告 Harness、统一知识库、统一 SkillHub、Tool Gateway、Aone 沙箱和 Agent Team,逐步把研发链、运维链和知识链串在一起。
目前,团队已经在 SDD、ATDD、垂类 Agent、Case 排查、巡检报警、Skills 建设这些方向跑出了真实案例。最近两周的团队使用样本显示,多数有效反馈落在
30%-60% 的阶段性提效区间
这些问题的存在恰恰印证了一个观点:
AI Native 的核心不是换个工具,而是把 Harness、知识库、测试验收、执行状态和治理闭环这些基础设施补齐。
下面按“为什么、怎么做、做到哪儿”三层来展开。
一、为什么不是“用 AI 写代码”,而是研发体系升级
AI 在研发中的应用大致走过了三个阶段。
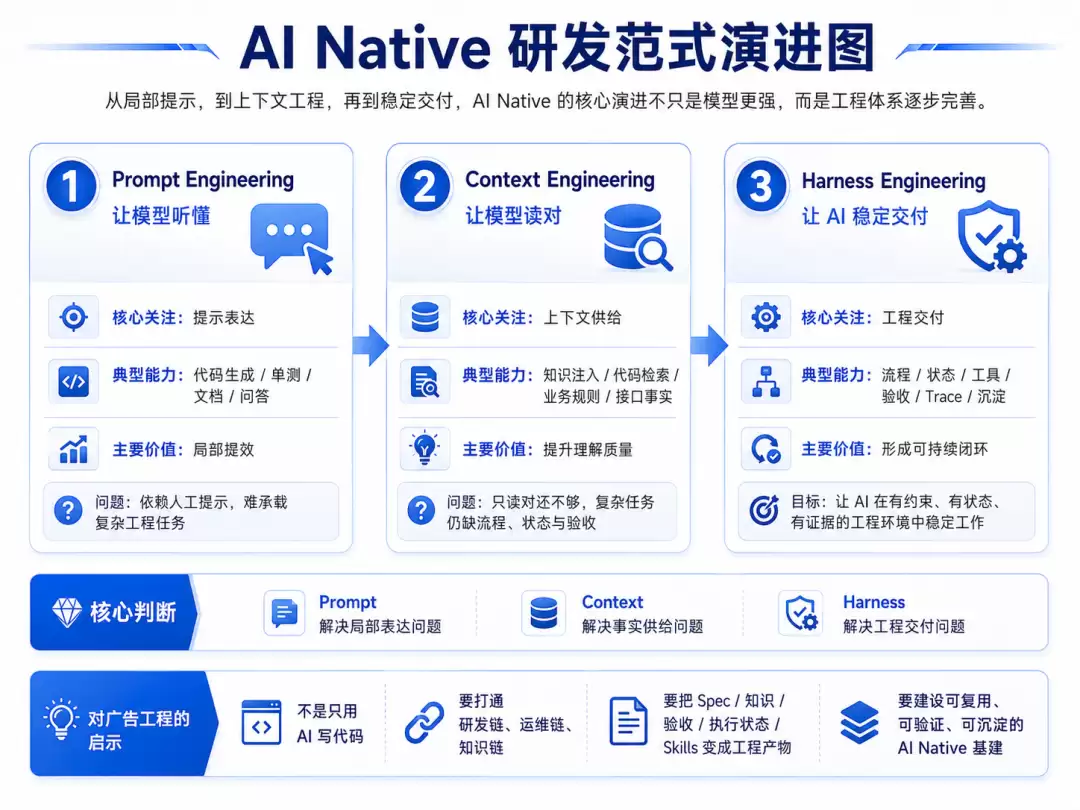
第一阶段是 Prompt Engineering。
第二阶段是 Context Engineering。
第三阶段是 Harness Engineering。
所以我们对 AI Native 的理解可以概括成三句话:
Prompt 解决局部表达问题,Context 解决事实供给问题,Harness 解决工程交付问题。
对高德广告工程来说,真正要解决的不是“某一段代码写得更快”,而是整个研发、运维、知识沉淀链路中的人工翻译、人工集成和人工兜底。从产品意图到研发理解、技术方案、代码实现、测试验证、发布上线、线上排查、经验沉淀——每一步都可能发生信息丢失、口径偏差、重复沟通、上下文断裂和质量风险。AI 如果只停留在“帮我写代码”,最终会被卡在需求不清、知识缺失、测试不通、部署不通、上下文丢失和结果不可验证上。
模型能力决定上限,工程环境决定能不能稳定落地。
高德广告工程要解决的不是某一个单点 Agent 能力,也不是单纯的 Coding Agent,而是研发链、运维链、知识链如何通过 Agent Team 形成统一闭环。
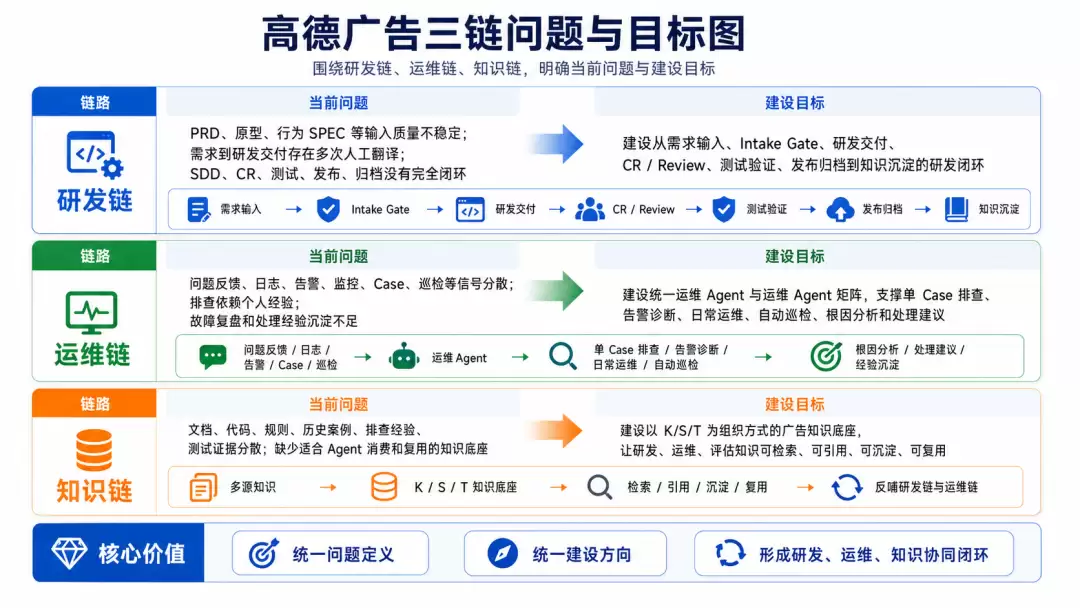
| 链路 | 当前问题 | 建设目标 |
| 研发链 | PRD、原型、行为 SPEC 等输入质量不稳定。需求到研发交付存在多次人工翻译。SDD、CR、测试、发布、归档没有完全闭环 | 建设从需求输入、Intake Gate、研发交付、CR/Review、测试验证、发布归档到知识沉淀的研发闭环 |
| 运维链 | 问题反馈、日志、告警、监控、Case、巡检等信号分散,排查依赖个人经验,故障复盘和处理经验沉淀不足 | 建设统一运维 Agent 与运维 Agent 矩阵,支撑单 Case 排查、告警诊断、日常运维、自动巡检、根因分析和处理建议 |
| 知识链 | 文档、代码、规则、历史案例、排查经验、测试证据分散,缺少适合 Agent 消费和复用的知识底座 | 建设以 K/S/T 为组织方式的广告知识底座,让研发、运维、评估知识可检索、可引用、可沉淀、可复用 |
因此,目标不是让 AI 替代研发,而是重构人、AI、系统之间的分工:
人
AI
系统
研发同学的工作重心会从“重复翻译和重复执行”转向更高价值的判断:维护业务 Spec、定义验收标准、评审 AI 产物、补充边界场景、建设知识库、沉淀 Skills、治理质量与风险。
这不是工具升级,而是研发体系升级。
二、实践路径:从点状探索到统一闭环
高德广告工程不是从零开始讲一个愿景,而是从一批真实场景出发,逐步把点状 AI 能力收敛为统一工程体系。
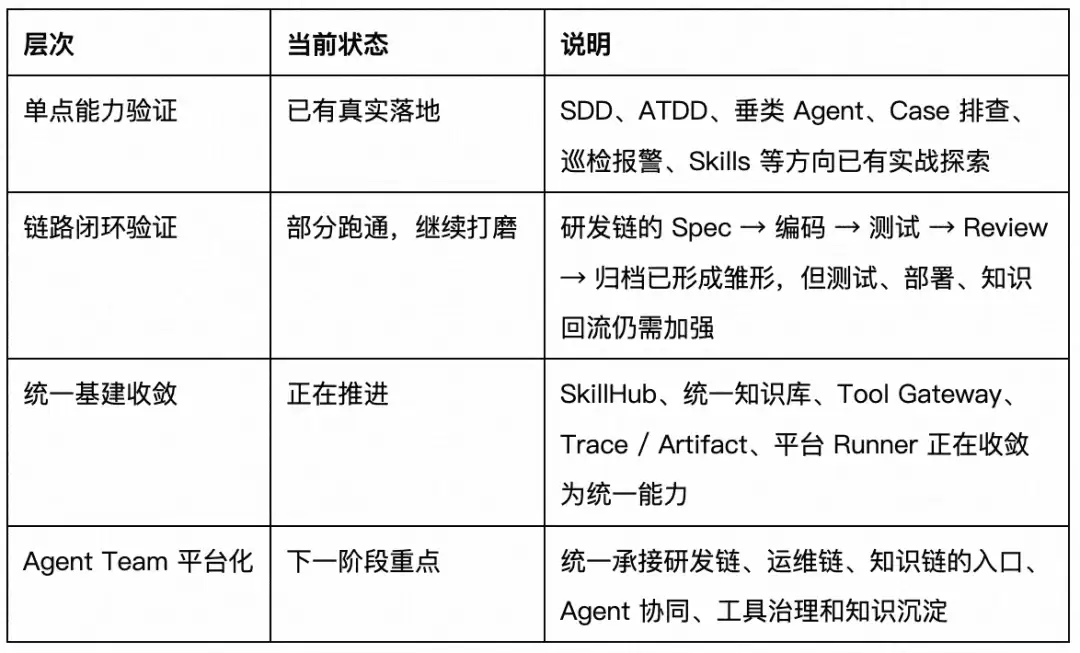
当前已经验证的基础能力包括:
- SDD / gad-sdd-all 的真实项目验证
- ATDD 测试流程与测试 MCP 对接
- gad-sdd-all / gad-atdd-all / gaode-ad-rd-test 等 Skill 实践
- Case 排查、巡检报警、品牌广告全链路排查等垂类 Agent 探索
- UMA / TPP / Aone 等测试平台接入方向
- 知识库和 Skills 仓库的初步沉淀
面上正在收敛的统一能力包括:多 Skill 仓库 → 统一 SkillHub,零散知识文档 → K/S/T 知识底座,工具直连 → Tool Gateway,一次性 Agent 输出 → Trace / Artifact,经验总结 → Knowledge Delta,本地使用 → 平台 Runner + 任务入口,点状 Agent → Agent Team。
这里需要强调一下:当前平台 Runner 方向优先收敛到 OpenCode,但并不等于强制统一所有个人研发入口。Claude Code 等个人研发入口仍然可以保留。长期原则是
框架可替换、资产不可替代
三、核心思路:五类工程产物 + 一套统一基建
3.1 五类工程产物
整套体系的底层心智可以概括为一句话:
把 Spec、知识、验收、执行状态、Skills 都升级为与代码同等地位的工程产物。
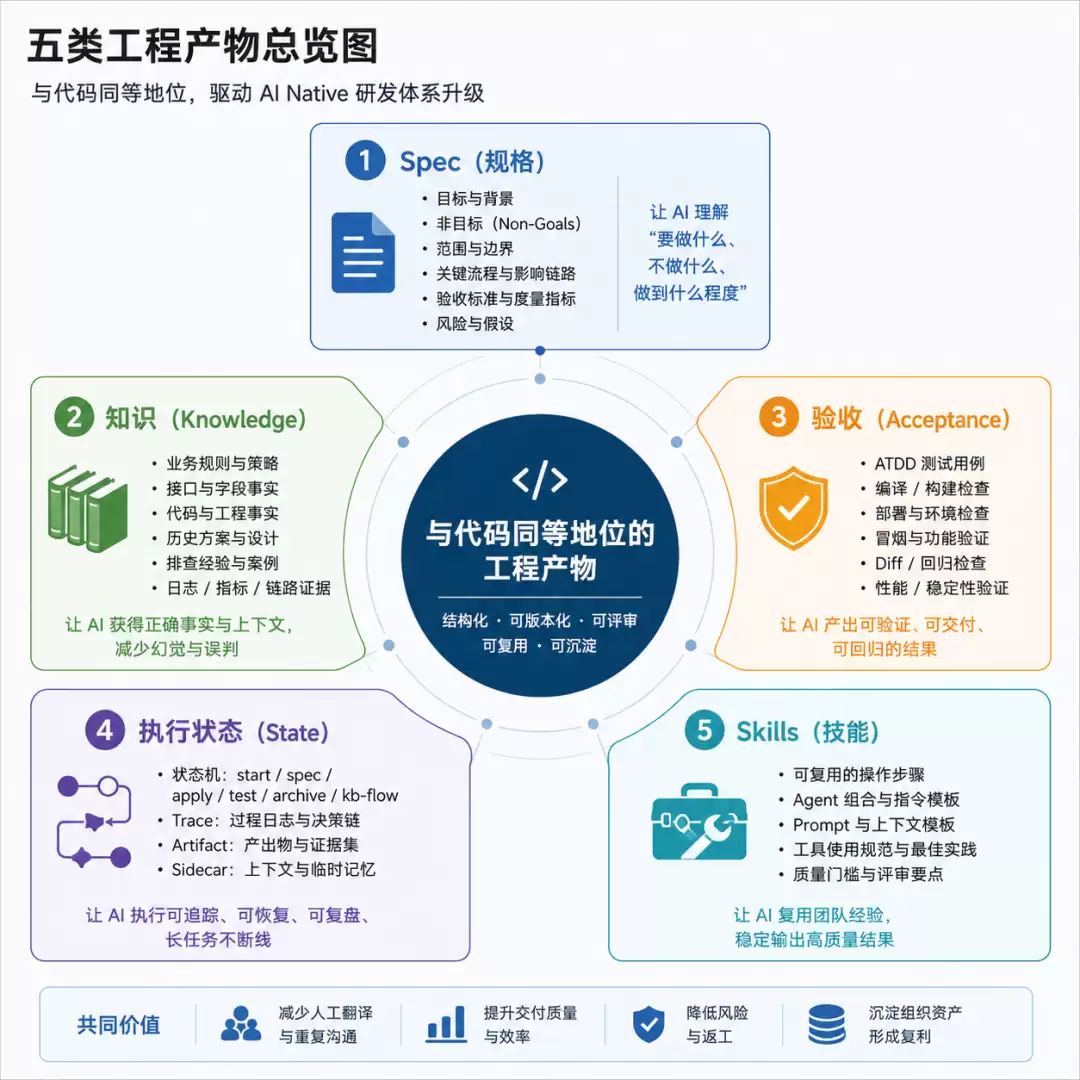
| 类型 | 过去的状态 | 升级为工程产物后 |
| Spec | PRD、钉钉文档、口头沟通,自然语言为主,前后容易矛盾 | 结构化 proposal / design / spec / tasks,带目标、非目标、影响范围、风险、验收标准 |
| 知识 | 散落在文档平台、代码仓库、个人经验和聊天记录中 | 统一知识库,支持分层索引、自动注入、证据引用、审核更新 |
| 验收 | 依赖人工 CR、灰度兜底、线上发现问题再修 | ATDD、测试建议、编译部署、冒烟、Diff、性能、稳定性等反馈闭环 |
| 执行状态 | Agent 会话断了就丢,跨窗口失忆,无法恢复 | Harness 状态机、中间产物落盘、Trace、Artifact、Sidecar 记录 |
| Skills | 个人技巧、Prompt 片段、经验脚本 | 统一 SkillHub,可版本化、可评审、可分发、可复用 |
只有这些要素都变成工程产物,AI 才能稳定地在工程体系里运行。否则,AI 只能靠临时上下文猜测;上下文一断、需求一复杂、知识一缺失,就会退化成“看起来很聪明,但不可控、不可复盘、不可规模化”。
3.2 一套统一基建
围绕五类工程产物,我们建设了一套统一 AI Native 基建。
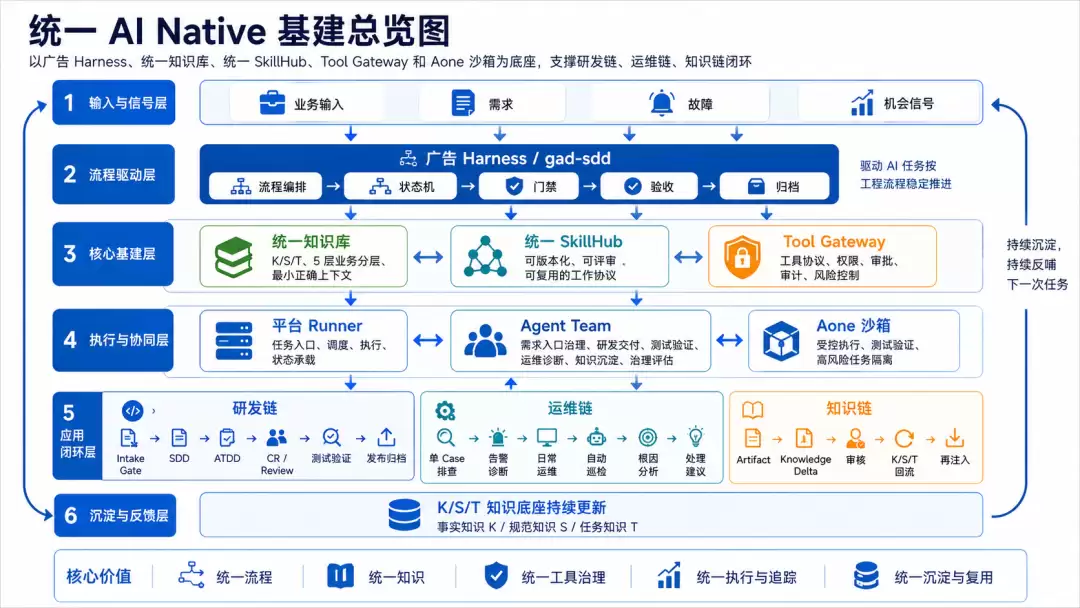
各模块分工如下:
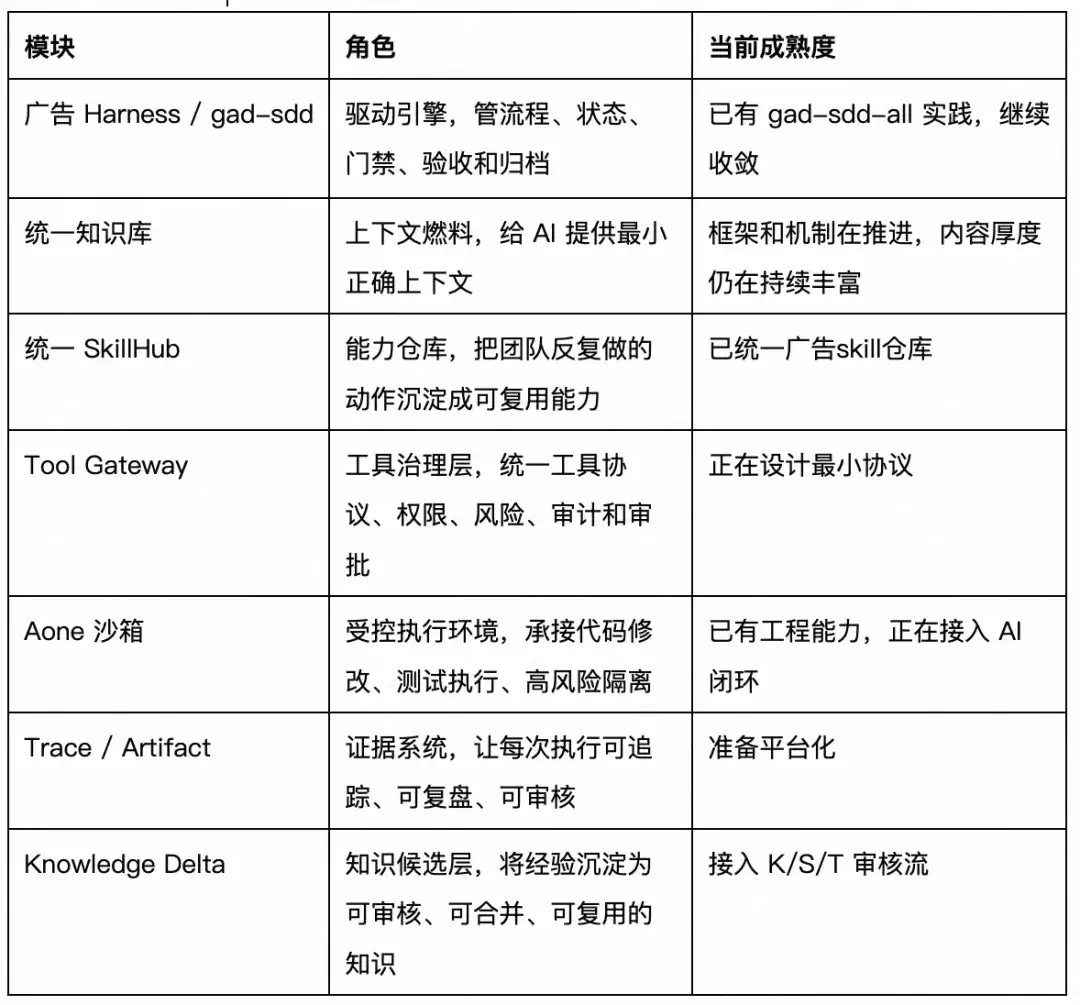
这套体系的关键,不是把某个工具做强,而是把工具、知识、流程、状态和证据组织成完整闭环。
四、广告 Harness:让 SDD 变成可机器校验的工作流
4.1 为什么需要广告自己的 Harness
通用 SDD / OpenSpec 能解决一部分问题,但广告工程的复杂性决定了我们不能只依赖通用骨架。广告场景涉及召回、排序、出价、计费、客资、反作弊、投放平台等复杂链路。一个需求往往不是改一个接口,而是跨系统、跨数据、跨策略、跨测试、跨发布的综合变更。
如果 Spec 只是自然语言文档,AI 会在以下问题上失控:需求是否完整?哪些字段是硬约束?哪些边界必须验收?哪些业务规则不能破?哪些测试必须跑?哪些变更需要人工确认?哪些知识需要回写?
因此,我们在通用 OpenSpec 风格工件之上,叠加了广告工程自己的 Harness 约束:强类型 Spec、阶段门禁、ATDD、测试证据、知识沉淀和回流机制。
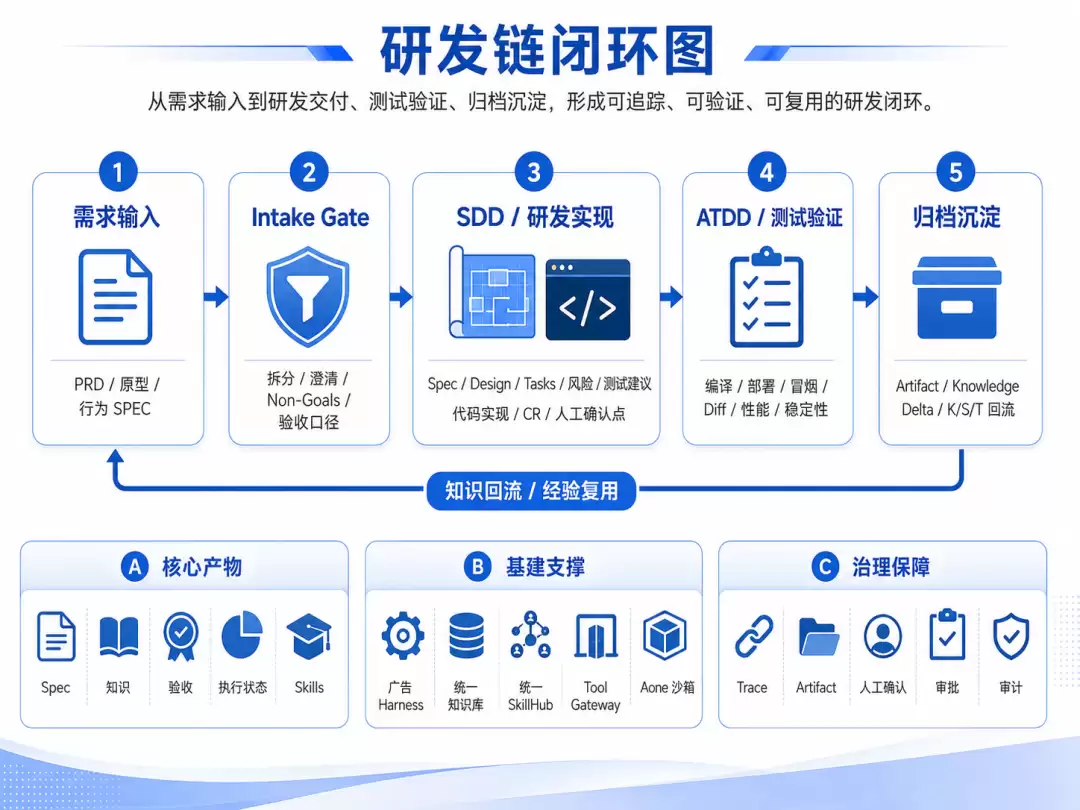
4.2 已验证出的核心机制
gad-sdd 的核心不是“生成一份设计文档”,而是把 SDD 变成可机器校验的工作流。
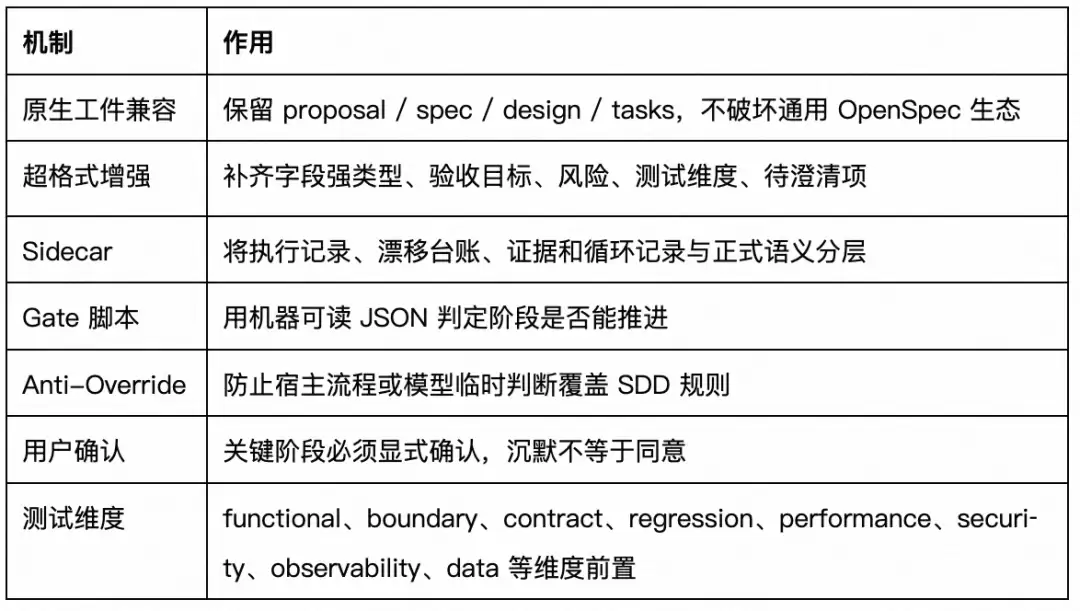
这类机制的价值在于:AI 不再是“根据当前上下文自由发挥”,而是在有门禁、有产物、有状态、有人工确认点的工程流程中工作。
4.3 状态机:解决 AI 长周期任务跑断问题
一次需求交付可以被抽象为六个阶段:start(启动新需求)→ spec(规格成文)→ apply(编码实现)→ test(ATDD 闭环)→ archive(归档变更)→ kb-flow(知识回流)。任何阶段都可以触发 clarify 澄清子流程。
每个阶段都有四个关键要素:进入门禁(什么条件满足才能进入)、产物清单(必须落盘哪些中间文件)、退出门禁(什么验证通过才能前进)、状态记录(如何跨窗口恢复、复盘和归档)。
一线反馈中,“上下文记忆丢失”“大型项目时间周期长时,每次小改动都要重新总结”“思考时间过长”等问题非常典型。这正是 Harness Engineering 要解决的核心:
模型的能力可以持续进化,但工程系统的状态、记忆、检查点必须由 Harness 提供。
4.4 Intake Gate:AI Native 研发链的入口闸口
复杂需求不能直接交给 Agent 写代码。研发链入口必须先做 Intake。Intake Gate 要把 PRD、原型、行为 SPEC、验收口径、Non-Goals、上下游影响范围整理成可执行、可追踪、可确认的研发输入。
它负责:需求完整度评估、业务目标识别、影响范围判断、缺失信息召回、澄清问题生成、需求拆分、Non-Goals 明确、优先级建议、准入/打回/待澄清判断。
Intake 不是“可选增强”,而是进入 SDD 之前的必要闸口。
五、ATDD:让测试从“事后动作”进入研发闭环
5.1 过去的问题
过去研发完成代码后,常见问题:编译失败后再回头找 AI 修,部署失败后再人工排查,测试问题发现后再重新对话,功能验证依赖人肉操作,Diff/性能/稳定性测试与研发链割裂。这导致 AI 开发看似很快,但实际交付仍然卡在测试、验证、修复和回归阶段。
5.2 已经形成的研发测试协作方式
统一 ATDD 流程已经明确了研发侧和测试侧的协作方式:
- :输入 PRD / 方案设计 / 知识库 / 人工 Prompt,输出研发 Spec / 代码 CR / 测试建议 Spec
研发侧
- :输入研发阶段产物 + PRD,输出编译结果 / 部署结果 / 功能 Case / Diff / 性能 / 稳定性测试结果
测试侧
这说明测试不再是代码完成后的纯人工兜底,而是逐步进入 SDD 之后的研发闭环。
5.3 当前短板:测试闭环还没有完全打通
ATDD 方向已经跑起来,但还没有完全成熟。一线反馈集中暴露出几类问题:
| 问题 | 表现 |
| 测试未充分使用 | 部分需求没有真正跑 test 阶段,或者测试耗时过长 |
| 部署/编译环境未完全打通 | TPP、US 等场景存在自动部署、编译、功能测试不完整的问题 |
| 功能测试生成不足 | 需求对应的冒烟用例、定制化功能测试仍需要人工补齐 |
| Diff / bug 修复未闭环 | Diff 报告分析、bug 自动修复、复验流程仍需加强 |
| 测试进度感知弱 | 环境搭建后,编译 / Diff 阶段通知和状态感知能力不足 |
这些反馈说明,当前 ATDD 的重点不是再证明“能跑测试”,而是要把测试结果结构化回流到研发闭环里。下一步要做:测试失败结果结构化回流研发侧,测试证据纳入 Trace / Artifact,复验结果作为归档门禁,高频测试失败沉淀为 Knowledge Delta,环境适配矩阵补齐,功能测试/冒烟/Diff 分析能力增强。
这一步的关键价值是:
AI 不仅要能写代码,还要对交付结果负责。
六、运维链:从经验排查到证据化诊断
6.1 运维链已经有真实场景验证
运维和业务诊断方向已经有多个垂类 Agent 探索,包括 Case 排查、巡检报警、品牌广告全链路排查、客资助手等方向。AI 在运维链上已经不只是“问答”,而是开始进入真实问题排查、日志分析、业务诊断和处理建议场景。
6.2 运维链的关键认知
广告运维的难点不是“没有日志”或“没有监控”,而是信息分散且依赖经验串联。一个线上问题往往需要同时看:用户反馈、商家反馈、日志、指标、告警、链路拓扑、近期变更、Case 历史、配置、策略、代码。这适合 Agent Team 介入:工具负责提供事实,Agent 负责串联、解释、归因和生成建议。
6.3 运维 Agent 矩阵
下一步运维链不应只是一个问答机器人,而应形成 Agent 矩阵。
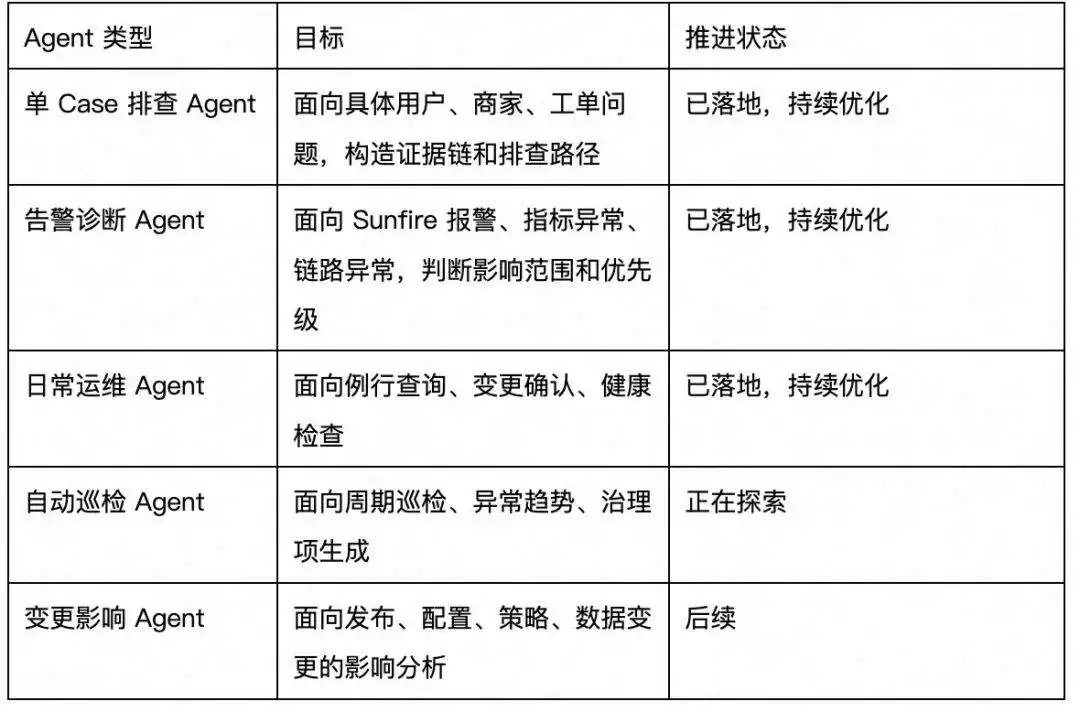
运维链必须坚持一个原则:
Agent 的结论不是事实源,日志、指标、变更、Case、巡检结果才是事实源。
最终产出应包括:诊断结论、影响范围、证据链、根因分析、处理建议、稳定性治理项、Knowledge Delta。
6.4 运维链的当前卡点
运维链的主要短板不是“没有 Agent”,而是事实链路还不够完整:告警与业务场景关联不足、指标与链路拓扑关联不足、多次报警和投放策略调整之间缺少可被 AI 检索的关系、历史处理经验和 SOP 不完整、Case、变更、指标、配置之间没有统一事实图谱。
这本质上是把运维领域的
K:事实知识做扎实
七、知识库与 SkillHub:效果上限和组织复利
7.1 知识库是当前效果上限的核心约束
AI 能不能做好研发任务,很大程度不取决于模型本身,而取决于它读到了什么上下文。广告工程知识分散在多个系统里:KBase、钉钉文档、Aone、代码仓库、历史 CR、故障复盘、个人经验、运维记录。
团队使用反馈中,知识库不足是最集中的卡点之一:客资链路字段映射薄、历史方案缺失、离线任务链路缺统一维护、告警诊断无法关联业务场景和指标、接口事实不可靠等问题反复出现。因此,统一知识库不是装饰项,而是 AI Native 效果上限的关键约束。
7.2 K/S/T:按知识用途组织,而不是按文档来源堆积
按 K/S/T 组织知识:
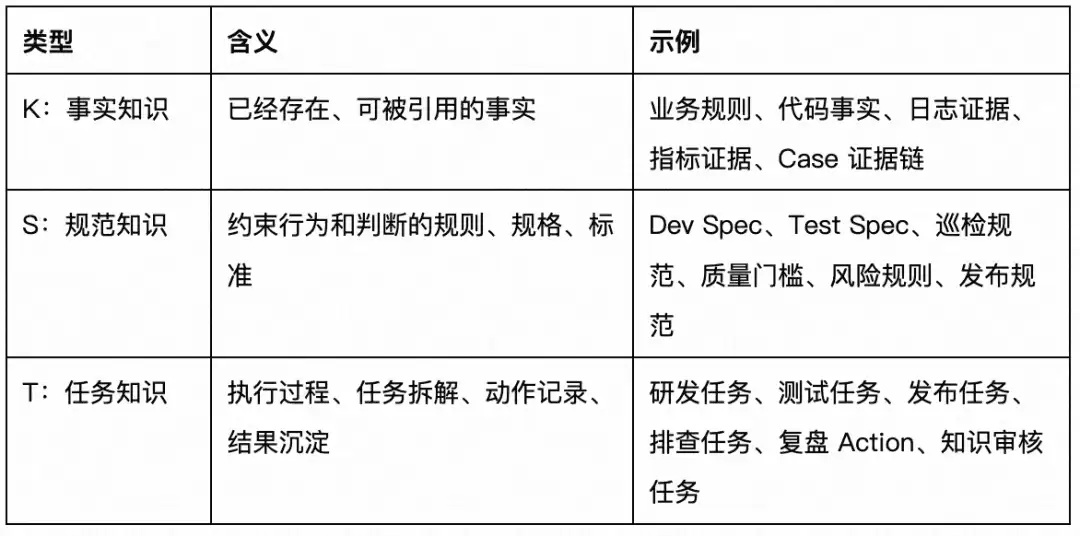
K/S/T 的价值在于:AI 不只是“搜文档”,而是知道当前任务需要事实、规范还是任务经验。
7.3 广告工程知识库:K/S/T + 5 层业务分层
K/S/T 是知识的用途分类,回答“这条知识用于什么”;5 层业务分层是知识的工程组织方式,回答“这条知识应该放在哪里、在哪个研发阶段被消费”。两者互相支撑:
- K/S/T:事实 / 规范 / 任务
- 5 层分层:语义 / 架构 / 服务 / 项目 / 运维
广告工程知识库当前采用 5 层结构:
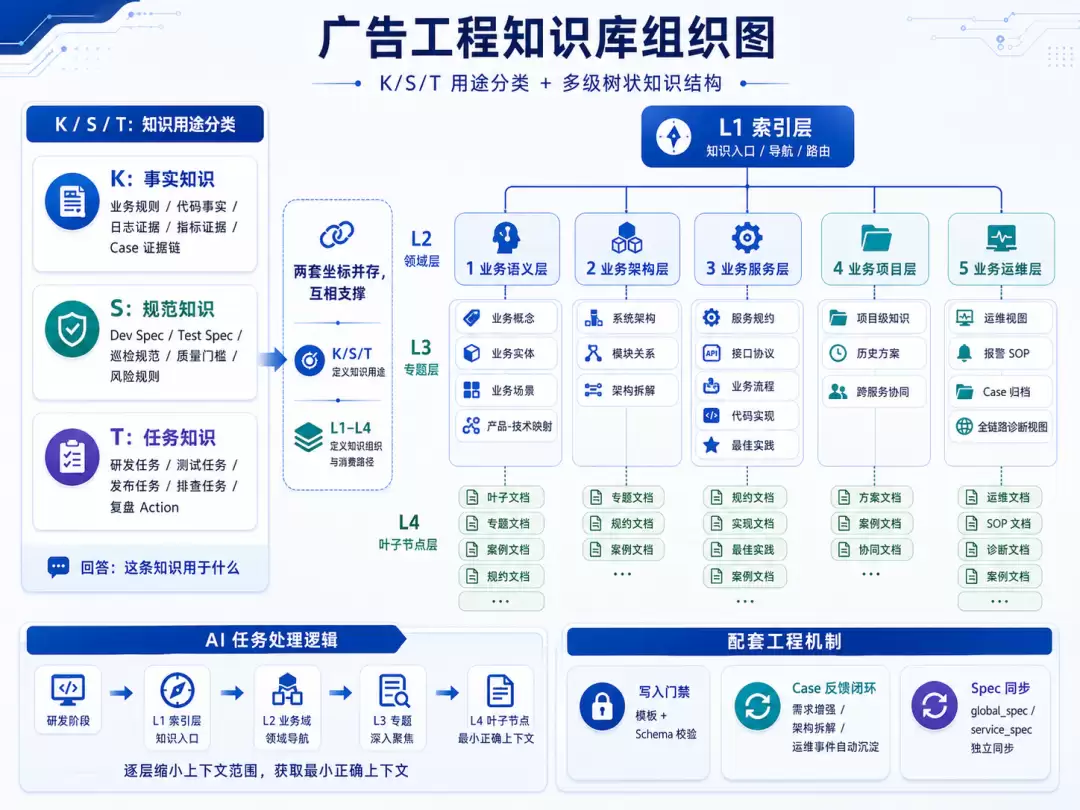
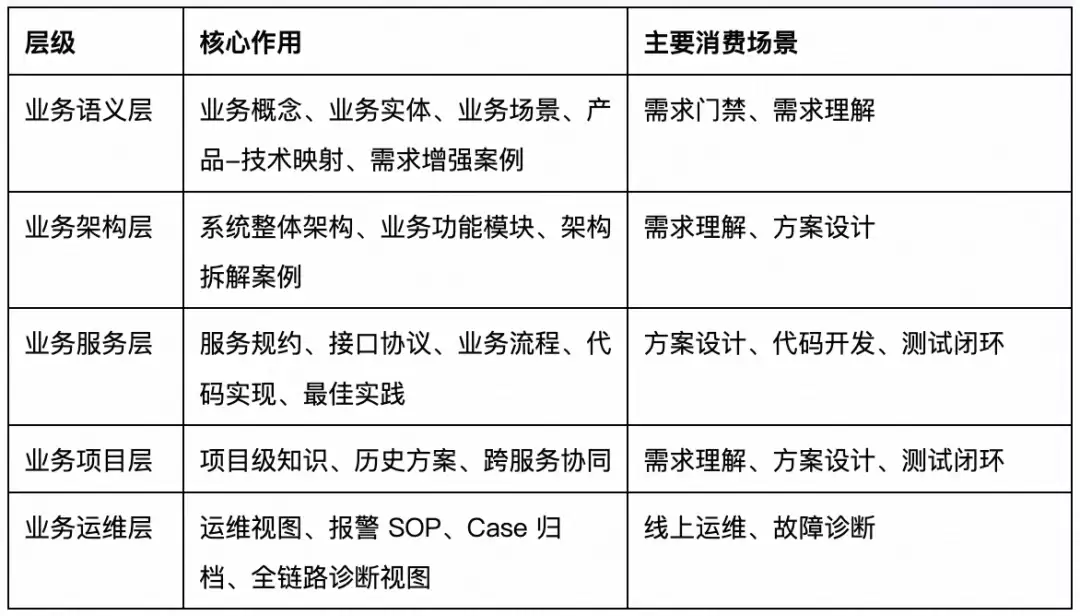
AI 在处理任务时,不做全库 Dump,而是按照:研发阶段 → 优先读取层 → 当前业务域 → L3 专题 → L4 叶子文档,逐层缩小上下文范围,确保拿到“最小正确上下文”。
例如:
| 研发阶段 | 优先读取层级 |
| 需求门禁 | 业务语义层、业务项目层 |
| 需求理解 | 业务语义层、业务架构层、业务项目层 |
| 方案设计 | 业务服务层、业务架构层、业务项目层 |
| 代码开发 | 业务服务层、业务项目层 |
| 测试闭环 | 业务服务层、业务项目层 |
| 线上运维 | 业务运维层、业务服务层、业务架构层 |
为了避免知识库变成“文档堆”,当前还配套建设了三类工程机制:
| 机制 | 实现方式 | 作用 |
| 写入门禁 | 文档模板发布前强制 Schema 校验 | 保证知识结构合规,避免低质量知识进入知识库 |
| Case 反馈闭环 | 需求增强、架构拆解、运维事件等 Case 自动沉淀 | 将实战经验反哺知识库 |
| Spec 同步 | global_spec / service_spec 独立同步 | 保障全局规约和服务规约持续更新 |
这意味着,知识库不是静态文档仓库,而是研发链、运维链和知识链的共同底座。Spec、Case、排查结论和项目经验都会通过门禁和审核机制进入知识库,再反过来支撑下一次需求理解、方案设计、代码开发、测试闭环和运维诊断。
7.4 SkillHub:把团队经验变成可复用动作
Skill 不只是 Prompt,而是可执行的工程工作协议。它要规定:什么时候使用、需要哪些输入、允许调用哪些工具、禁止做什么、何时必须暂停、何时必须找人确认、必须生成哪些产物、完成标准是什么、失败如何处理、如何沉淀知识。
统一 SkillHub 要沉淀的能力包括:需求治理 Skill、SDD Skill、ATDD Skill、CR/Review Skill、测试触发 Skill、Case 排查 Skill、知识沉淀 Skill、发布检查 Skill、工具适配 Skill。
当前已经有 gad-sdd-all、gad-atdd-all、gaode-ad-rd-test 等实践基础,已建设统一的广告工程 Skill 仓库 gaode-ad-skills,并逐步收敛为统一 SkillHub。
7.5 当前 Skills 全景
当前 gaode-ad-skills 已经沉淀出 50+ Skill,展现出较丰富的能力雏形。这里不把数字包装成最终成果,而是作为“能力覆盖面”的阶段性说明。
| 类目 | 代表能力 | 解决的问题 |
| 研发流程 | gad-sdd-all、gad-atdd-all、OpenSpec 相关 Skill | 端到端研发工作流 |
| 产品输入治理 | gad-product-intake、PRD enhancer | 需求输入质量和准入 |
| 知识库 | KB 检索、文档索引、知识发布 | 最小正确上下文 |
| 测试/部署 | gaode-ad-rd-test、pre-push check、deployment check | 测试与部署反馈 |
| 故障排查 | ad-server troubleshooting、计费 / oCPC / 客资排障 | 运维诊断 |
| 配置查询 | Diamond、Libra、A/B 实验查询 | 配置事实获取 |
| 代码审查 | code-review、remote review | CR / MR 风险发现 |
| 元工具 | skill 管理、skill 创建、聊天转 skill | SkillHub 生产效率 |
SkillHub 的长期目标不是“堆更多 Skill”,而是让团队经验可版本化、可评审、可复用、可评估。
八、真实反馈闭环:典型案例、提效区间、真实卡点
高德广告不是在写概念,而是在用真实需求推动 Harness、知识库、Skills、测试和执行状态迭代。
8.1 三个典型场景
| 场景 | AI 参与阶段 | 收益口径 | 暴露问题 |
| 品牌广告旧索引下线/配置清理 | Intake / SDD / ATDD 全流程 | 从约 1 天压缩到约 0.5 天,完整跑通链路 | 测试阶段有少量 owner 跟进的小问题 |
| openCreativeChain 迁移 | 知识库建设 / 方案设计 / 代码开发 | 主要收益在历史逻辑梳理、迁移方案生成和代码开发辅助,迁移周期明显缩短 | 长任务上下文、人工审核、部署链路仍需补齐 |
| 汇川 ADX 程序化接入 | 历史逻辑梳理 / 方案设计 / 代码开发 | 逻辑梳理阶段反馈约 50% 提效 | ODPS / Flink / 脚本链路知识缺口大 |
这几个案例的共同点是:AI 在逻辑梳理、方案设计、代码生成、迁移辅助上效果明显;但越靠近复杂链路、测试部署、历史知识和跨系统事实,越依赖工程基建补齐。
8.2 提效区间:不要包装成统一指标
从最近两周团队样本看,多数有效反馈集中在
30%-60% 阶段性提效区间
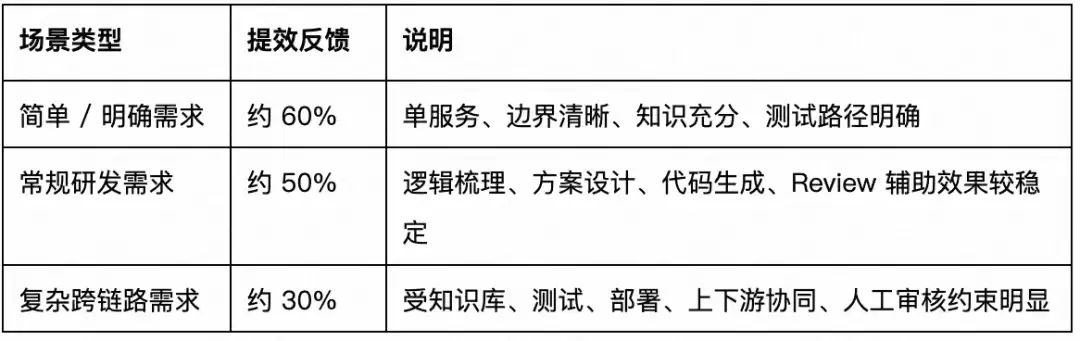
8.3 当前真实卡点与工程动作
真实卡点比成功故事更重要,因为它们指向下一阶段工程化建设方向。
| 真实反馈 | 暴露问题 | 对应工程动作 |
| PRD 太大、上下文占用高 | 输入未结构化 | Intake 增加需求拆分、Non-Goals、验收口径确认 |
| HSF 接口被 AI 自行构造 | 接口事实缺失 | 建设接口事实库,Tool Gateway 提供可信接口查询 |
| test 未使用或能力不足 | 验收链路弱 | ATDD 补功能测试、冒烟、Diff 分析、复验闭环 |
| TPP / US 无法自动部署编译 | 环境未打通 | 补仓库/环境适配矩阵 |
| 告警诊断无法关联指标 | 运维事实链路不足 | 建设场景-指标-链路-变更事实网络 |
| 上下文丢失、长任务慢 | 执行状态不可持续 | Trace / Artifact / session 状态沉淀 |
| AI 自行 git commit | 行为约束不足 | Skill 中明确禁止动作,关键动作必须人工确认 |
| 默认跑错 Skill 或旧流程 | Skill 路由不稳定 | SkillHub 统一路由、版本、触发条件和强制入口 |
真实反馈不是“负面信息”,而是工程化迭代的输入。
8.4 当前阶段的真实结论
更准确的阶段性结论是:
- SDD 是当前最先跑通的主链路
- ATDD / test 已打通,但需跟测试同学持续共建完善
- 知识库是效果上限的核心约束
- Intake 是复杂需求进入 SDD 前的必要闸口
- 长任务状态和 Trace 是复杂需求能否交付的关键
- 运维 Agent 的核心不是自动给结论,而是证据化诊断
九、下一阶段平台化方向:Agent Team 与可治理执行
9.1 从点状 Agent 到 Agent Team
下一阶段目标,是把研发链、运维链和知识链纳入统一 Agent Team 平台。它围绕三条链建设:
- :需求输入 → Intake → SDD → ATDD → CR → 测试 → 发布 → 归档
研发链
- :信号 → 分流 → 排查 → 诊断 → 处理建议 → 治理项 → 回流
运维链
- :Artifact → Knowledge Delta → 审核 → K/S/T → 再注入
知识链
近期重点不是把 Agent 名字铺得很满,而是优先建设六类能力:需求入口治理、研发交付、测试验证、运维诊断、知识沉淀、治理评估。每类能力都要有清晰的输入输出、工具权限、风险边界、证据要求和归档机制。
9.2 平台 Runner 与多 Harness 可替换
当前平台 Runner 方向优先收敛到 OpenCode,同时保留 Claude Code 等个人研发入口和回退路径;长期不绑定单一框架,真正沉淀的是广告工程自己的 Spec、知识库、Skills、测试门禁和 Trace / Artifact。真正不可替换的是:Spec 结构、SkillHub、知识库、Tool Gateway、Trace、Artifact、Knowledge Delta、验收标准、评估样本。
一句话:
框架可以换,资产不能丢。
这不是悲观主义,而是对模型和工具演进速度的清醒认知。只有这样,团队才能在每一次模型/框架升级中,把广告工程的能力顺着迁移过去,而不是从零开始。
9.3 执行治理:Tool Gateway、Trace、Knowledge Delta
第八章列出的具体工程动作,在 Agent Team 平台上需要通过 Tool Gateway、Trace、Artifact、Knowledge Delta 等治理能力落地。核心原则如下:
- :解决谁能调用工具、能调用什么工具、调用前是否需要审批、调用后如何审计、失败后如何降级。
Tool Gateway
- :AI 不是只给最终答案;每次执行必须能复盘过程;每个关键产物必须能归档;每次失败必须能定位阶段和原因。
Trace / Artifact
- :Agent 不直接写正式知识库,先生成候选知识,带来源、证据、owner、置信度、有效期和冲突检查,审核后再进入 K/S/T。
Knowledge Delta
这些能力的目标是让 AI 从“能干活”升级为
“可治理地干活”
十、下一步:从点状探索到统一平台
10.1 第一阶段:统一基建骨架形成(基本完成,持续完善)
目标是让团队在同一套基建上工作。
当前状态
完成标志
10.2 第二阶段:广告内部跨团队闭环(持续建设中)
目标是跨投放、引擎、计费、客资、平台、运维等团队形成协同。
关键事项
完成标志
10.3 第三阶段:跨组织端到端闭环
目标是打破工种壁垒,让产品、研发、测试、运维、平台围绕统一 AI Native 工程体系协作。
关键事项
完成标志
这一步的目标不是“减少人”,而是把人从重复翻译、重复编码、重复排查中释放出来,转向架构、质量、稳定性和工程创新。
结语
高德广告工程的 AI Native 实践,不是一个“AI 已经完全接管研发”的故事,而是一个更真实、更有工程价值的过程:我们已经跑通了一批点状能力,看到了 30%-60% 的阶段性提效,也清楚看到了知识、测试、状态、接口事实、复杂需求拆分上的瓶颈——我们正在把这些瓶颈反向沉淀为 Harness、知识库、SkillHub、Tool Gateway、Trace 和 Agent Team。
这正是 AI Native 从“个人效率工具”走向“组织工程能力”的关键路径。最终目标不是让 AI 替代人,而是让人从重复翻译、重复编码、重复排查中释放出来,把精力投入到架构判断、边界定义、质量治理、业务创新和平台建设上。
一句话总结: