基于指标+标签的经营分析 Agent 创新实践
来源:互联网 更新时间:2026-06-16 14:04
导读
数势科技研发的数据资产和数据分析相关产品,主要面向零售和金融企业,帮助其进行业务语义层资产构建,为企业提供基于大模型增强的数据分析 AI Agent、智能指标平台、智能标签平台及智能营销平台,从而助力企业提升数字化决策能力,推动企业数字化升级。本文将分享如何基于大模型能力,叠加指标和标签平台能力,构建企业内智能数据分析产品。主要分为以下五部分:
- 企业经营分析的难点和挑战
- 智能分析的路线选择
- 如何设计经营分析 Agent
- 企业经营分析的展望和思考
- 问答环节
01 企业经营分析的难点和挑战
企业内部的数据分析涉及诸多环节:加工制作报表、基于数据发现异常因素(开发人员需要通过 SQL 或算法做多维异常检测)、进一步挖掘异常背后的原因(又离不开因果推断或归因洞察等算法)、以及分析之后撰写数据分析报告。早期主要靠写 SQL 或 Python 实现,开发门槛极高,企业内部能参与的不到1%。随着 BI 时代到来,通过无代码化平台拖拉拽、配置业务规则,能快速生成报表和可视化展示,但使用 BI 的人既要有业务分析思维,又要熟悉产品配置,这仍然难以推广到一线业务人员——受众大约只有15%到20%。其余人想看数据做决策,只能提需求,经过层层传递,最终由业务分析师帮忙出结果。
所以,业务团队的痛点是:洞察数据需要在一个链条上层层传递需求,等到看到数据和结论,黄花菜都凉了。而数据开发人员的痛点是:每天把时间和精力投入到无限的报表开发中。这正是我们希望用智能分析产品来解决的核心矛盾。
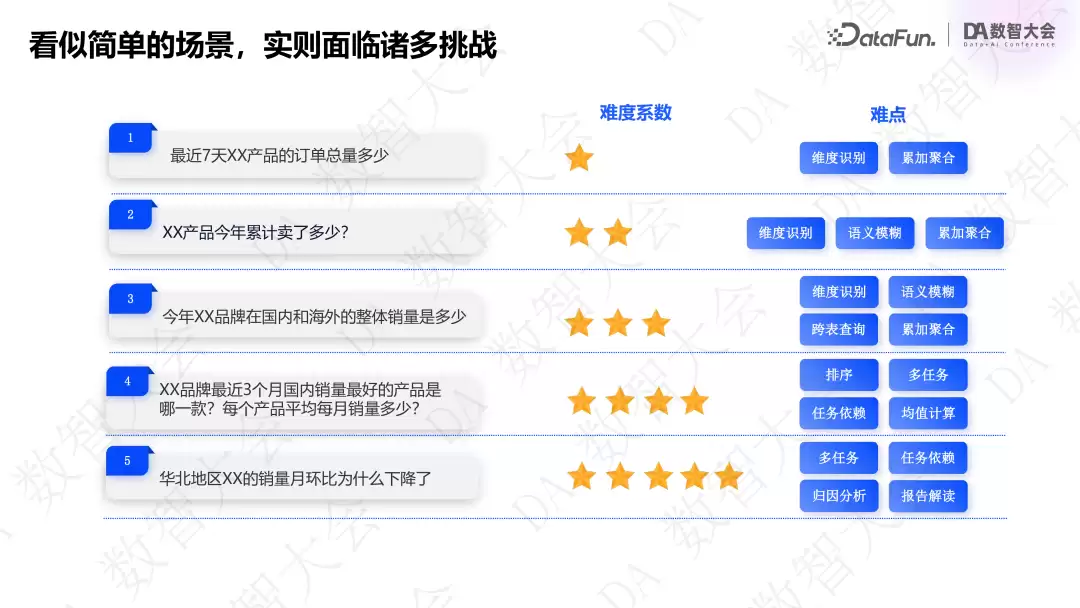
智能分析的需求可以总结为5个范式,每个范式都有对应的挑战:
- “最近7天XX产品的订单总量多少?”——需要找到时间范围、维度及指标字段(如订单总量)。
- “XX产品今年累计卖了多少?”——用户提问中“卖了多少”可能有歧义(销量、订单量、销售额),大模型很难直接找到背后的字段含义。
- “今年XX品牌在国内和海外的整体销量是多少?”——可能涉及多表查询(国内国外各有一张表),需要通过 join 关联关系取出两个销量字段。如何用语言实现跨表关联是挑战。
- “XX品牌最近3个月国内销量最好的产品是哪一款?每个产品平均每月销量多少?”——一句话包含两个子任务:先找出国内前三个月销量最好的产品,再求该产品的月均销量。
- “华北地区XX的销量月环比为什么下降了?”——隐含假设任务:先计算月环比,判断下降值,再通过归因算法做维度归因;用户可能还需要绘制折线图等。这些任务靠单纯的 NLP2SQL 难以实现。
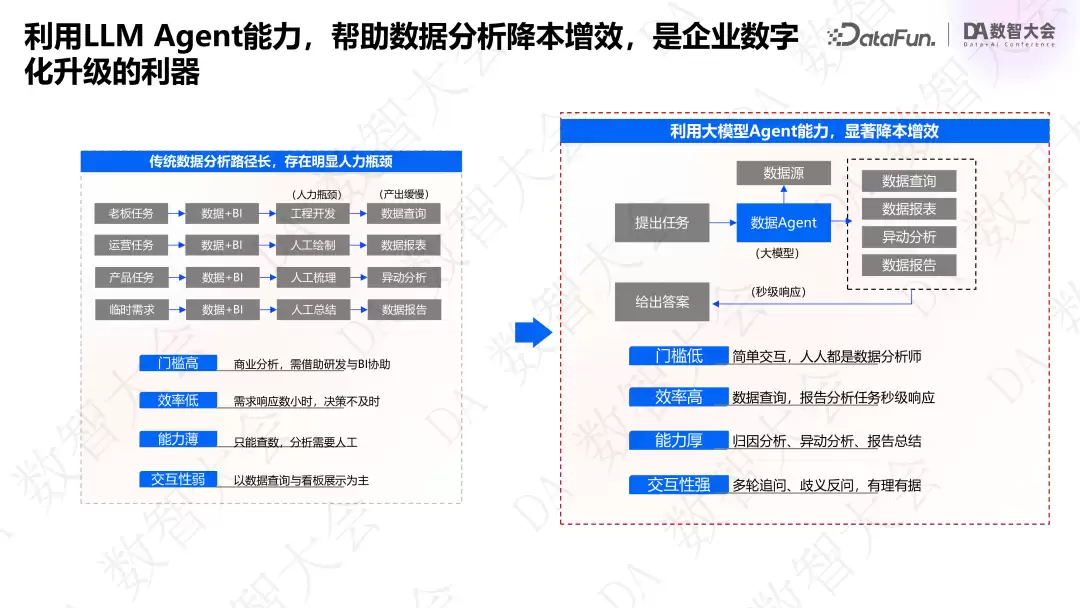
用户的一句话需求具有多样性。利用大模型,可以把需求拆成多个子任务,再根据能力需求串行或并行调用。Agent 的工作就是拆解任务、调用对应能力的 function 或 API,返回结果后根据反馈决定是否需要进一步拆解或重新规划——这才是 Agent 给数据分析领域带来的真正价值。
02 智能分析的路线选择
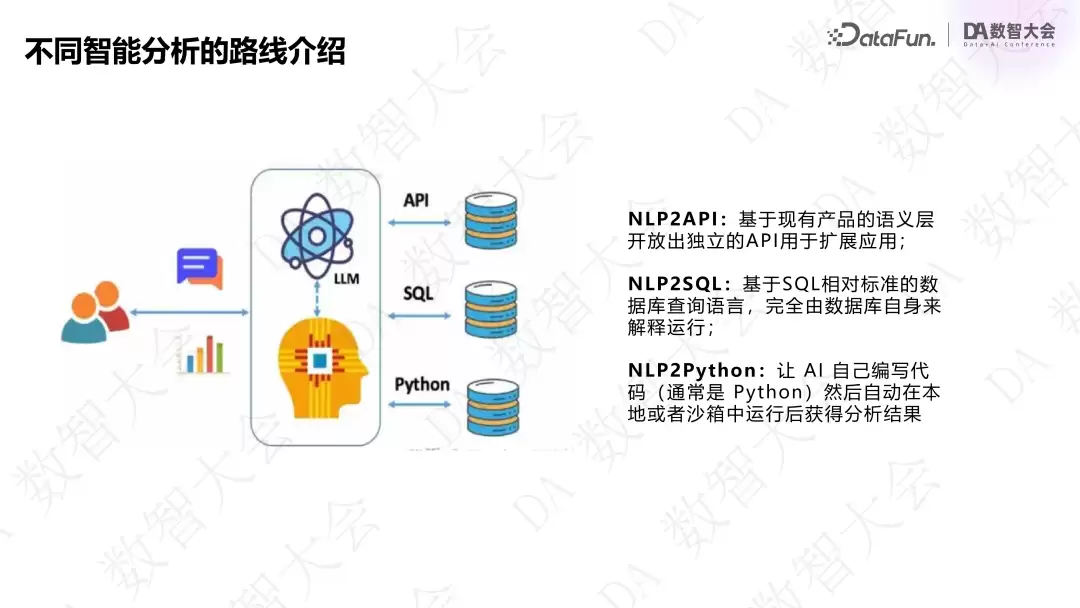
智能分析有不同的实现路线:
- :本质是取数。大模型通过微调或 SQL 训练集生成 SQL。当前常结合 RAG,把生成式任务改为填充式——生产中发现大模型“填空”比“生成”稳定性高得多。大模型在生成 100 个 token 后随机性会增加(即使固定 temperature 或随机种子),网络间的梯度传递也有波动。此外,还要结合归因洞察、异常检测、可视化图表等衍生能力,需要给大模型各表描述才能找到多表关联,但大模型判断表间关系的稳定性相对不足。
NLP2SQL
- :把数据语义化封装到 API。本质也是做填空题——确定 k 值后填充对应 value。API 能把复杂逻辑封装起来,大模型只需把用户语句转化为 API 参数,稳定性更高。
NLP2API
- :用 code 灵活性最高,可以突破 SQL 的局限性(比如生成算法预测和归因模块),但稳定性不足。随着大模型代码生成能力增强,这条路会越来越可行。
NLP2Python

上图是 NLP2SQL 的实现路径示例(来自 OpenAI 的标准 SQL 生成方式)。但在实际生产中远没那么简单:需要指定系统指令、告知模型数据库及表描述、基于标准 SQL 规范拼接 SQL,同时还要针对问题设计 prompt 模板、对模型做微调和评测。评测也有挑战——如何定义 SQL 生成的准确度?如何评估可执行性和执行性能?不能只追求能跑出结果,还要考虑耗时,才能达到企业级应用标准。
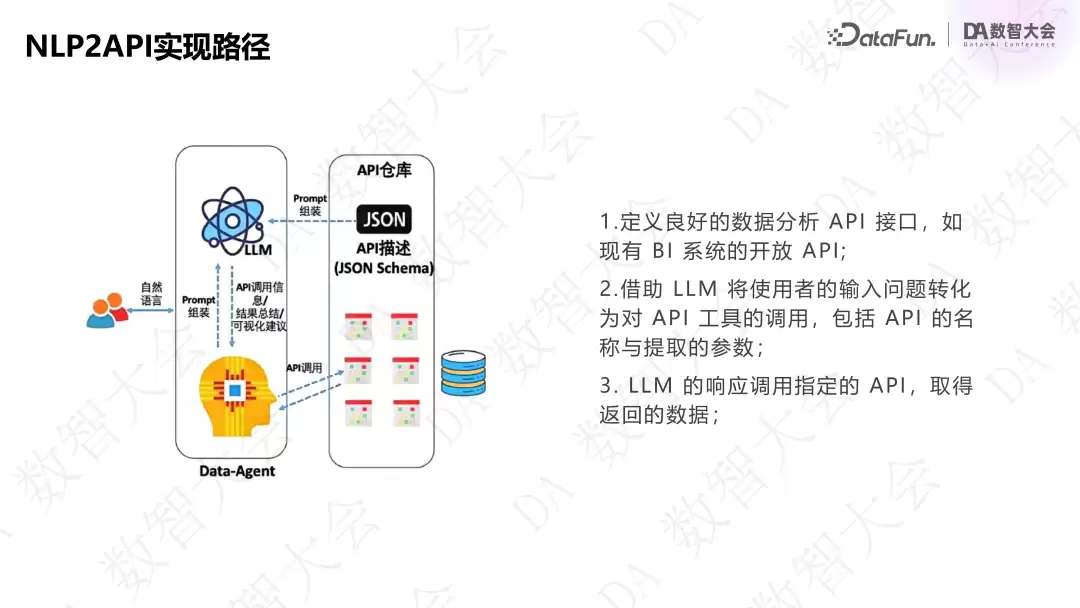
NLP2API 是先定义好数据分析相关 API(如 BI 系统、指标平台、算法 API 等),形成一个 API 池。通过搜索找到合适的 API,再把用户语句翻译成 API 参数完成调用。这种方式的好处是:API 自带校验性,通过工程化而非大模型生成的方式,可以产出性能较好的 SQL 结果。
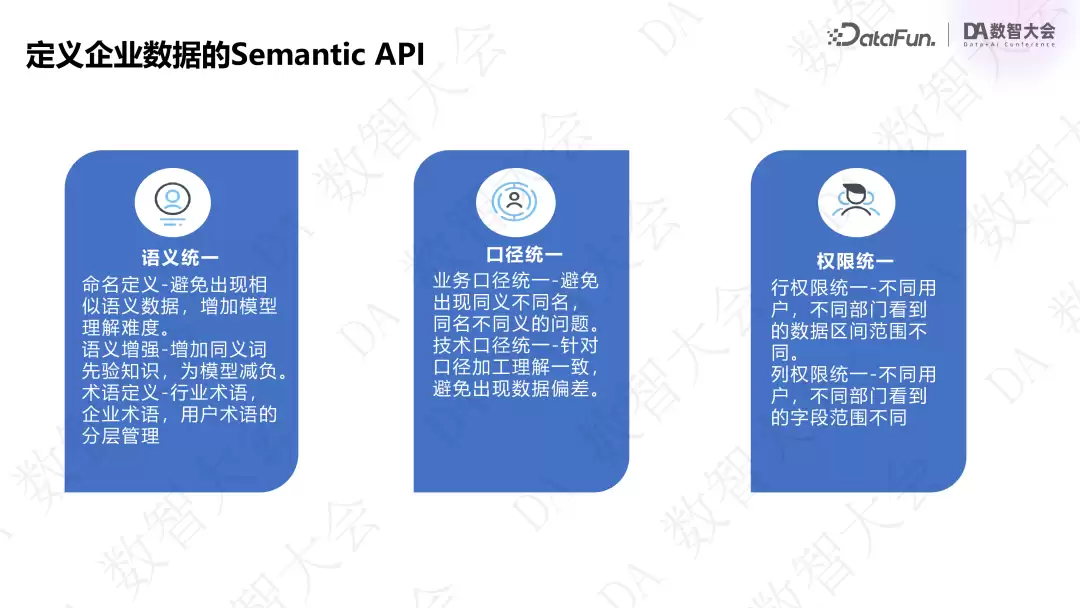
如何定义 Semantic API?数据本身没有语义,需要通过工具和手段对已有数据定义语义。需要做到三点:
- :大模型对通用语义理解不错,但学不到企业内部的行业黑话和术语,因此要增加同义词帮助企业语义理解。
语义统一
- :统一数据字段的技术口径和业务口径,确保字段与描述一致。
口径统一
- :企业内部不同部门能看到的数据不同,必须把权限问题融合到语义层。
权限统一

为什么要基于指标和标签做 NLP2API?
- :指标和标签封装了业务逻辑和口径,分层结构包含过滤条件和表达式。模型不需要理解具体内容,只需将指标和标签视为对象。
面向对象理解
- :每个指标层级下的维度是少数几个,天然有助于语义过滤,让召回范围小且准,生成效果自然更准。
体系化设计
- :解析结果可以通过要素反显给用户,比 SQL 更容易被非技术人员理解。
可解释性高
- :基于指标体系可以衍生出归因、预警、趋势预测等 API 或 function,被大模型无缝调用。
衍生能力
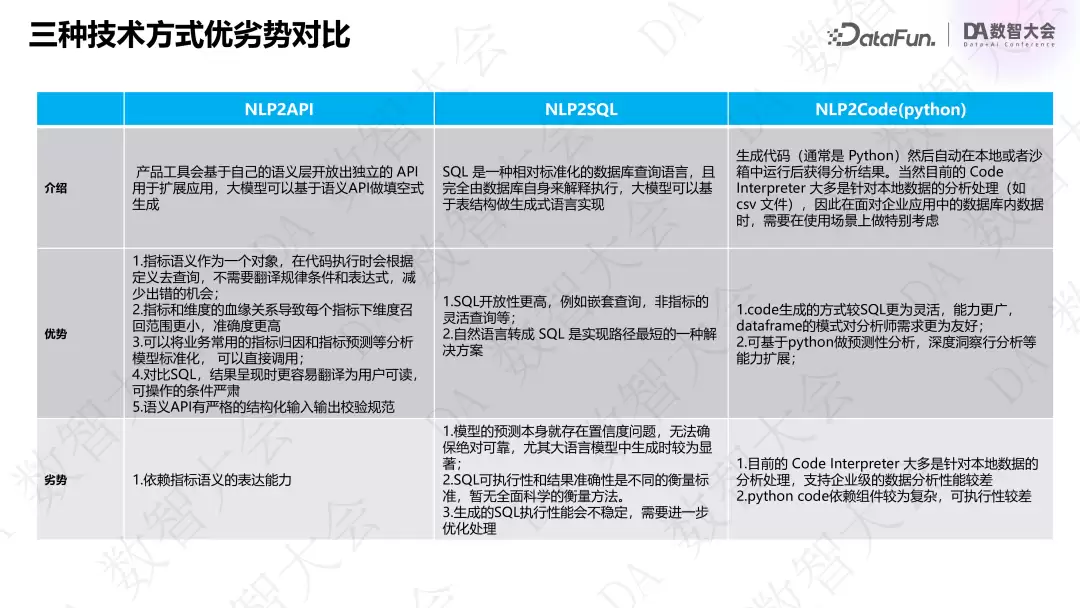
上图对比了三种路径的优劣势。实际场景中需根据具体情况选择:表不多且逻辑不复杂时,可用 NLP2Code 或 NLP2SQL;业务逻辑复杂或表多时,需要先通过工程手段对数据做聚合,再让大模型更好地理解。
03 如何设计经营分析 Agent
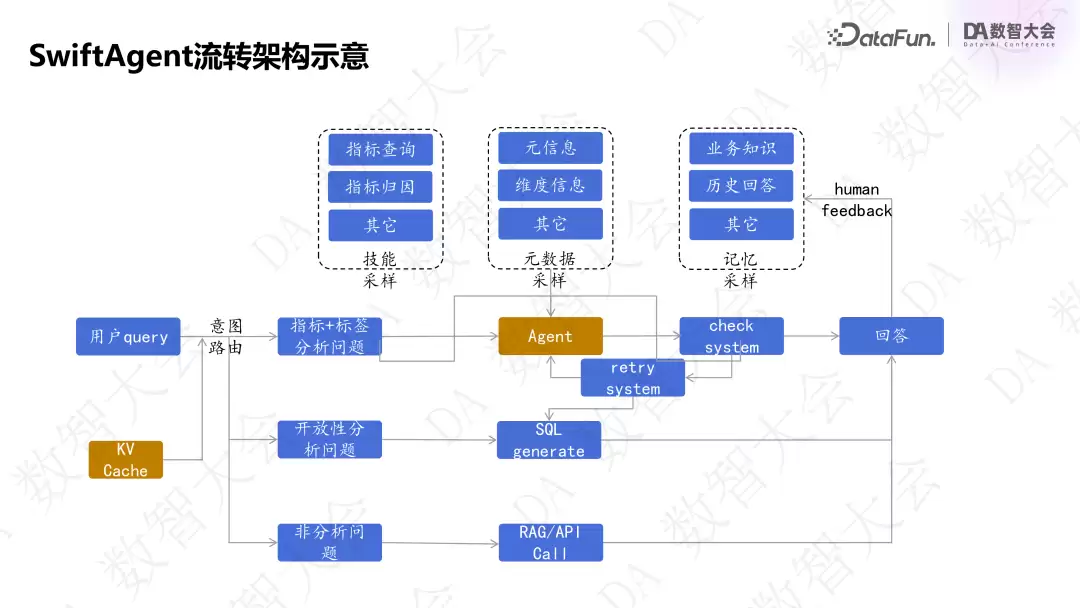
上图展示的是 SwiftAgent 的流转链路。用户请求进入后,并没有完全抛弃 NLP2SQL 和 NLP2Code,而是通过一套意图路由机制:在每个节点判断是否能通过指标和标签解决问题。如果是,则在 Agent 机制下进行技能采样、元数据采样、记忆采样(围绕指标和标签的 API 技能、元数据、历史记忆)。如果是指标和标签之外的问题,则通过开放性的分析生成 SQL 做兜底。
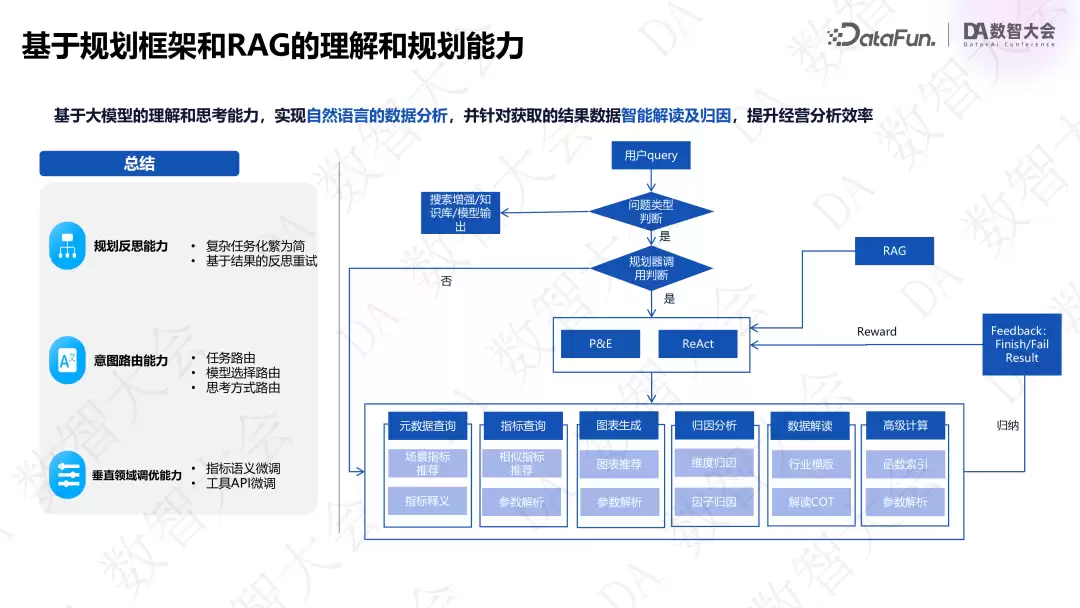
上图是 Agent 的简要框架。并非每个问题都需要规划拆解:用户问题有简单有复杂,而交互时效性要求高,所以前期会通过意图识别判断问题类型。简单问题直接调用技能做参数 mapping 和解析;复杂问题则通过 planner 机制(如 ReAct 和 P&E)。P&E 是分步执行不加反思,ReAct 耗时较长但每步都做反思校正。此外,还利用 RAG 做动态 embedding,以及用历史上下文反馈(告诉大模型 goodcase 和 badcase)。
总结下来,它具备规划反思能力、意图路由能力、垂直领域调优能力。每个技能都要定义好描述(出参、入参),才能解析;之后拼接各项技能串行或并行执行,汇总结果并通过 reward 分数判断是否需要重新规划路径。完成状态后将结果返回给前端。
在设计 Agent 时,遇到了以下几个难点:
1. 静态规划思路无法解决所有个性化提问方式
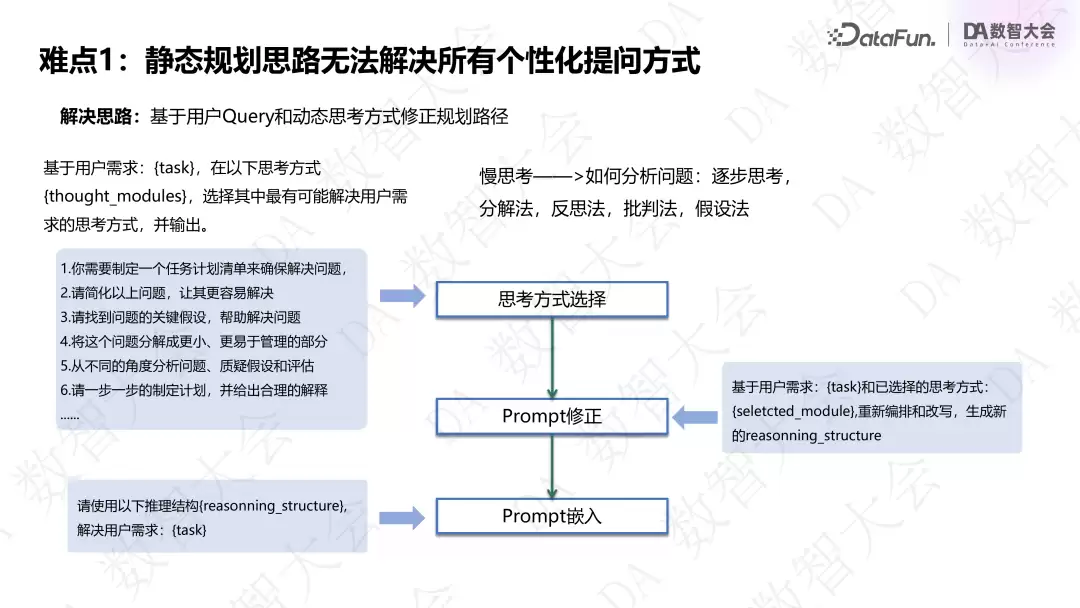
Planner 机制无法满足千人千面的个性化 query。规划方式有多种(逐步思考分解、P&E、批判法、假设法等),我们把每种方式形成原子 module。当用户 query 进来时,先判断应该选择哪种思考方式,然后基于所选组件形成 planner prompt,再让大模型解析执行。同时引入动态 Few-Shot 引导大模型持续执行。
2. 任务规划“穿越性”问题
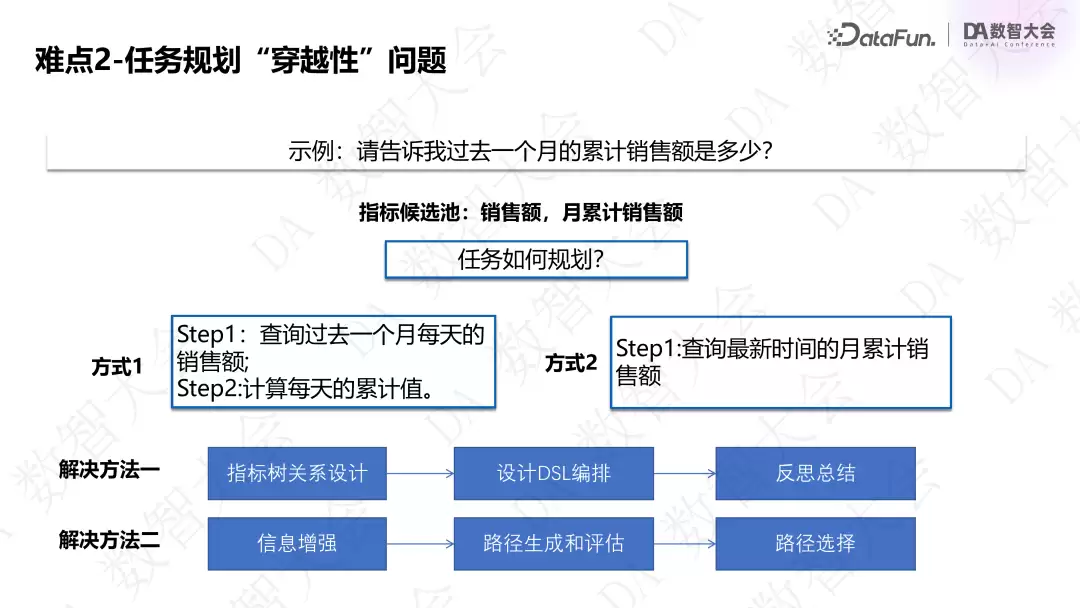
指标分为原子指标、派生指标和衍生指标。比如用户想查“过去一个月的累计销售额”,数据库中可能既有原子指标“销售额”,也有派生指标“月累计销售额”。大模型如何生成规划?如果只有月累计销售指标,只能生成直接查询的规划;如果两个指标都有,可以规划成两种方式:先查每天原子指标再累计求和,或者直接查月累计指标。应该选哪条路径?目前有两种解法正在对比:
- 基于指标树关系编排 DSL 模板(含 SUM 算子)。若指标已包含 SUM 口径,则去掉模板中的算子;否则保留。
- 规划时提前把已有指标告诉大模型,通过向量和关键词召回候选指标,再生成多条规划路径,从中选择最短可执行路径拆分成具体任务。
3. 提升工具调用的效果
每次通过语言解析参数难以保证稳定性。我们的基座模型针对一些 case 生成相应结果,下次它就能遵循该结果解析,稳定性较高。具体做法:告诉大模型工具的 description 和出参、入参,生成 query,再基于这些 query 正向调用工具得到结果。这样会产生正负样例存入数据库。下次调用时索引到对应样例,动态引入 prompt,通过调优学习保证准确性。
4. 时间推理效果不稳定
大模型的时间推理效果极其不稳定,主要原因包括:
- :比如“帮我看一下去年的销售额是多少,按月呈现”,大模型可能忽略“按月呈现”而解析成2023年。
语义割裂
- :比如“6月第3周”,大模型可能先推理具体是哪几天,经常不准。
时间推理判断
- :比如“最近几天”,大模型可能今天返回最近三天,明天返回最近七天,结果不稳定。
陈述模糊
- :比如“6月前两天的销售额”,大模型可能有三种理解:6月1号和2号,5月30号和31号,或5月31号和6月1号。
歧义冲突
这种不稳定严重影响用户体验。解决思路是先以规则保障稳定性:开发一系列日期识别算子(包括农历和公历),通过规则性实体抽取,把实体解析成具体年月日。大模型只需判断规则抽取的实体是否满足 query。经测试,准确率可达98%以上。对于剩余2%的 badcase,大模型先抽取时间实体,再基于实体解析,而不是端到端地将 query 解析成日期。
5. Agent 记忆缓存和命中较难
大模型每做新题都不会保证答案稳定,旧题可以参考历史答案。Agent 是产品机制而非算法能力,所以我们通过用户历史问询样例,解析正确要素并复用到相似样例上。除了历史问询记忆,还有知识库记忆,通过记忆对用户 query 做标准化改写。实验发现,改写为标准版本后大模型理解更加准确,实现“标准问询、标准出结果”,稳定性显著提升。Query 改写遵循通用公式:最近性、相关性和重要性。
上图是我们产品的架构,核心优势包括:
- (指标和标签),确保数据分析准确可靠。
统一语义层构建
- :每一次干预都是对模型、产品逻辑和业务规则迭代的反馈。
用户可干预
- :不仅需要结构化数据分析,还需要知道分析后的决策和行动。可搭配知识库,把结构和非结构数据串联,分析洞察后告诉业务人员下一步行动。
多源异构数据链接
- :让系统更懂用户。
持续反思学习
- :通过工程化手段优化底层 SQL,极大提升查询性能。
数据计算加速引擎
04 企业经营分析的展望和思考
对经营分析 Agent 的未来发展,有以下几个方向:
- :当前 chatbot 是被动问答模式,未来希望 Agent 能主动根据用户画像、历史提问和角色权限,每天生成分析目标和任务,用户确认后自动后台运行,最终输出分析报告,甚至额外产出有洞见的结论。
从能听懂人话升级为帮人说话
- :数据分析是为了发现本质原因并采取行动。Agent 的本质是连接,通过连接企业内部系统工具,实现整体互联互通,进行各种决策和行动。
从总结归纳升级为自动决策
- :初期阶段 Agent 还无法达到专家水平,未来希望它能像资深业务专家一样帮助用户解决问题。
从像人一样规划升级为像业务专家一样规划
通过这三个方向的升级,才能让产品基于大模型的工具和能力创造出更大价值。
05 问答环节
Q1:企业用到您介绍的分析产品之后,数据分析人员的职业定位会有什么改变?
A1:产品并不是替代分析人员,而是作为助手,帮助其完成日常大量枯燥、没有技术含量的报表开发工作。分析人员只需要聚焦于更复杂的工作,比如像专家一样做更深度的洞察和分析。
Q2:医疗行业的企业使用你们的产品,怎么确保数据的安全性?
A2:首先该产品并非为医疗行业定制,而是用于企业经营分析。从产品本身来看,可私有化部署,数据不出企业,不存在数据出域的安全性问题。
Q3:Agent 应用开发是定制化的,还是依据几个主要的成熟的 Agent 开发框架来开发?更倾向于哪种方式?
A3:更倾向于第二种。做 Agent 开始要参考一些开源的 Agent 框架,目前已经有十几种,一定会有适合当前场景的。基于框架的思路再做针对性的业务嵌套和开发。我们会参考多种框架,因为每个都有优劣势。AutoGPT 是鼻祖但不够稳定;单 Agent 可参考 ReAct,多 Agent 可参考阿里的通义千问 Agent 或国外的一些开源框架——需要根据具体场景选择最合适的。
Q4:在产品和技术上怎么去引导用户更高质量地提问?
A4:内部技术层面,query 改写让用户无感知是最理想的,但难度较高。产品引导层面也包含很多技术,比如搜索联想(提供标准问题供参考),或者要素联想(用户问“卖了多少”,产品给出销售额、订单量等选项让用户选择)。搜索联想效果通常更好,因为给出的是完整问题,不会打断用户输入思路。
Q5:怎么能让用户相信返回的数据是准确的?
A5:包括两层。第一层是相信大模型翻译出来的是准确的——通过要素反写,让用户知道提问被翻译成了哪些要素组合,从而增加可信度。第二层是取的数字结果准确——这需要指标和标签开发时,从数仓到平台的数据核准和校验做准确,这是基础工作,与大模型本身无关。
Q6:Agent 现在是内部自己训练,还是用外面的公共大模型?在私有环境中需要自己部署还是可以配其他大模型?
A6:两方面考虑。第一,部署时要考虑企业可承担的算力成本——百亿左右模型成本相对低,超过500亿成本就高了。根据经验,300亿以下要靠微调,300亿(尤其500亿)以上,靠 prompt 调优即可。500亿以上通过 prompt 和工程手段能避免大多数错误;500亿以下可能很多情况工程手段无法避免,需要靠微调。最终部署方式要看客户对资源的要求。
Q7:SwiftAgent 流转框架里有 check system 和 retry system,它们都有最终的 output 分支,执行标准是什么?
A7:Check system 是我们内部的重试机制。当找不到对应指标、API 逻辑回答结果错误、或与用户提问要素不匹配时,会通过 SQL 方式直接侵入底层模型表,生成 SQL 检索结果。判断 query 和解析要素是否一致由大模型完成。此外,还有很多工程化手段(如 API 底层引擎代码报错)也需要重试机制。Retry system 部分会回到 Agent 重试,另一部分会到 SQL generate——Agent 部分融合了标签和指标,而生成 SQL 是一种兜底(单独线路和技能),SQL 生成效果不稳定,一般也会让它重试,但会设置最大重试次数。
Q8:用户对数据的信任问题,除了用数据治理去解决之外,还有其他方式吗?
A8:只能保证底层数据准确,数据治理是必不可少的。
Q9:产品的优势之一是用户可干预,在哪些环节用户比较适合介入干预?干预和辅助提问的临界点应该怎么把握?
A9:其实是召回和生成的平衡。比如大模型召回字段生成的结果,你判断它在候选集里分数排得并不靠前,但大模型却选择了它,这时就需要反问用户,同时附上分数较高的几个选项——这要根据具体业务场景抉择。出现冲突矛盾时,就需要反问。除了反问,对结果的赞和踩也是一种用户干预,本质上是对结果的校准。

-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
网络热词聊污是什么意思
-
帅气继父网名女生可爱英文(精选100个)
-
抖音最火沙雕男生网名(精选100个)
-
蒙古上单是什么梗
-
帅到极致的网名女生霸气(精选100个)
-
韦一敏是什么梗
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
免费看电影的软件推荐
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
因空难被判“过失杀人罪” 空客、法航均被顶格处罚22.5万欧元
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
有寓意的易经网名男生(精选100个)
-
韩漫小少爷网名大全女生(精选100个)
-
1 无法分类的AI专利 06-16
-
2 腾讯混元3D AI创作引擎:开启3D内容创作的新纪元 06-16
-
3 预测:生成式 AI 时代下的网络安全未来 06-16
-
6 谷歌CEO斯坦福再被嘘,竟被逼不敢提AI 06-16
-
7 皮肤问题心中没底?“AI问诊+医生复核”新模式上线 06-16
-
8 思想市场的价格发现:当AI决定什么思想被调用 06-16
-
9 拥抱 AI 的无限可能 06-16
-
10 AI音乐视频创作新风向:立刻MV 1. 1 版本实现“一键成片”跨越 06-16



