表格数据合成—GOT_OCR数据合成
来源:互联网 更新时间:2026-06-15 14:58
这一节我们重点聊聊表格数据是怎么合成的——这个问题在实际项目中经常碰到,很多朋友也问过。下面就把整个思路和具体操作拆开来讲。
表格数据现状
目前市面上比较常见的表格数据集,主要就这几个:
- PubTabNet:https://github.com/ibm-aur-nlp/PubTabNet —— 偏英文,数据来自 arxiv 上的论文表格。
- 好未来表格识别竞赛数据集:https://ai.100tal.com/dataset —— 现在好像已经下不到了。
- WTW 中文场景表格数据集:https://github.com/wangwen-whu/WTW-Dataset —— 只有单元格坐标,没有文本内容,做不了端到端模型。
看下来,PubTabNet 算是相对适合做端到端训练的一个:既有表格布局信息,也包含单元格内部的文本。唯一的硬伤——
它是英文的
在用 PaddleOCR 的过程中,发现它里面有个叫 TableGeneration 的表格生成工具,能生成各种样式的表格图片。具体效果可以看它的 GitHub 首页。这里简单列几个它存在的缺点(纯属个人观察):
- 生成的表格内容通常没什么实际意义;
- 和真实表格差异比较大,模型训练出来迁移能力一般。
但优点也很突出:速度快、量管够,而且不需要人工标注,这一点在数据紧缺时特别香。
latex 表格数据合成
我们这边选择用 latex 格式来表示表格,而不是 html。原因很简单:html 标记里 下面手把手走一遍生成流程。需要提前确认一下环境是否按照《环境准备-GOT_OCR数据合成》那节做好了准备——如果还没搞定,后面就只能先当理论看看了,因为环境没配好,图片是渲染不出来的。 确认 latex 相关工具链已安装,确保 texlive 和必要的依赖都在。没有环境的话,代码跑不动。 我们需要准备 PubTabNet 的英文数据,总共大约 首先要把 这段代码可以把 JSON 里的 token 数据还原成我们平时能看到的 html 表格。原始输入形式(部分截图)就不再重复贴了,实际跑一遍就能看到效果。 接下来就是利用大模型把 html 表格转成 latex 格式。这里提供一个基础的提示词模板: 用上面生成的 html_table 喂给大模型(这里用的是 Qwen2-72B),能得到类似下面的 latex 输出(示例): 把这个 latex 放到 texlive 里去渲染,就能得到正式的表格图片。 这篇文章主要梳理了表格数据的现状,以及如何利用 PubTabNet 和大模型来批量生成中文 latex 表格数据。文中给出的提示词只是一个起点,实际使用时可以根据具体需求调整,适配不同的表格结构和业务场景。数据合成这条路,虽然绕了点,但在标注资源有限的情况下,确实是性价比很高的备选方案。 《Off Campus》第二季官宣:这对CP还在,但不再是主角 和平精英如何做到压枪稳-和平精英怎样才能压枪稳 客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长 免费影视剧APP推荐 HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战 DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买! 网络热词聊污是什么意思 帅气继父网名女生可爱英文(精选100个) 抖音最火沙雕男生网名(精选100个) 蒙古上单是什么梗 免费看电影的软件推荐 韦一敏是什么梗 金铲铲之战s17六暗星卡莎阵容玩法构筑指南 SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景 作家助手如何上传自制封面 作家助手如何设置小说的封面 阿里发布Qwen3.7-Max大模型,全球第五、国产第一 有寓意的易经网名男生(精选100个) 韩漫小少爷网名大全女生(精选100个) 帅到极致的网名女生霸气(精选100个) 美国市场:股票相对债券的风险溢价正在消失
手机号码测吉凶
、
、 这种标签太多了,token 数量暴增,解码效率和训练速度都会受影响。
第一步:检查环境
第二步:先验数据准备
50w
50w
wget -O 第三步:数据处理
PubTabNet_2.0.0.jsonl 里每一行的表格结构转成 html 格式。下面是一段参考代码:from bs4 import BeautifulSoup as bs
from html import escape
def format_html(line):
''' Formats HTML code from tokenized annotation of img '''
html_code = line['html']['structure']['tokens'].copy()
to_insert = [i for i, tag in enumerate(html_code) if tag in ('', '>')]
for i, cell in zip(to_insert[::-1], line['html']['cells'][::-1]):
if cell['tokens']:
cell = [escape(token) if len(token) == 1 else token for token in cell['tokens']]
cell = ''.join(cell)
html_code.insert(i + 1, cell)
html_code = ''.join(html_code)
html_code = '''
%s
''' % html_code
soup = bs(html_code)
html_code = soup.prettify()
return html_code
第四步:大模型 latex 格式数据获取
system_prompt = "你是一个乐于助人的智能助手,你可以根据用户的要求完成用户给定的任务。"
user_prompt = "请根据给定的html格式的表格,将其转化为latex格式的表格,下面是html格式的表格:\n{html_table}"begin{tabular}{|l|l|l|l|}
\hline
\textbf{变量} & \textbf{风险比} & \textbf{95% CI} & \textit{\textbf{p值*}} \\
\hline
年龄 (中位数) &&& 0.716 \\
\hline
\leq 69 & 1.000 &&\\
\hline
\gt 69 & 0.839 & 0.310–2.268 &\\
\hline
性别 &&& 0.142 \\
\hline
男性 & 1.000 &&\\
\hline
女性 & 0.426 & 0.152–1.190 &\\
\hline
手术类型 &&& 0.010 \\
\hline
低位前切除术 & 1.000 &&\\
\hline
腹会阴联合切除术 & 3.140 & 0.919–10.725 &\\
\hline
肿瘤位置 &&& 0.710 \\
\hline
上段直肠 & 1.000 &&\\
\hline
中段直肠 & 1.267 & 0.381–4.213 &\\
\hline
下段直肠 & 1.716 & 0.419–7.026 &\\
\hline
分化程度 &&& 0.936 \\
\hline
G1 & 1.000 &&\\
\hline
G2 & 1.933 & 0.416–3.423 &\\
\hline
G3 & 1.119 & 0.137–9.137 &\\
\hline
组织学类型 &&& 0.299 \\
\hline
腺癌 & 1.000 &&\\
\hline
粘液腺癌 & 0.381 & 0.096–1.514 &\\
\hline
肿瘤浸润深度 &&& 0.925 \\
\hline
T3 & 1.000 &&\\
\hline
T4a & 0.919 & 0.316–2.673 &\\
\hline
T4b & 0.745 & 0.172–3.223 &\\
\hline
肿瘤大小 &&& 0.329 \\
\hline
\leq 4 cm & 1.000 &&\\
\hline
\gt 4 cm & 0.594 & 0.214–1.651 &\\
\hline
end{tabular}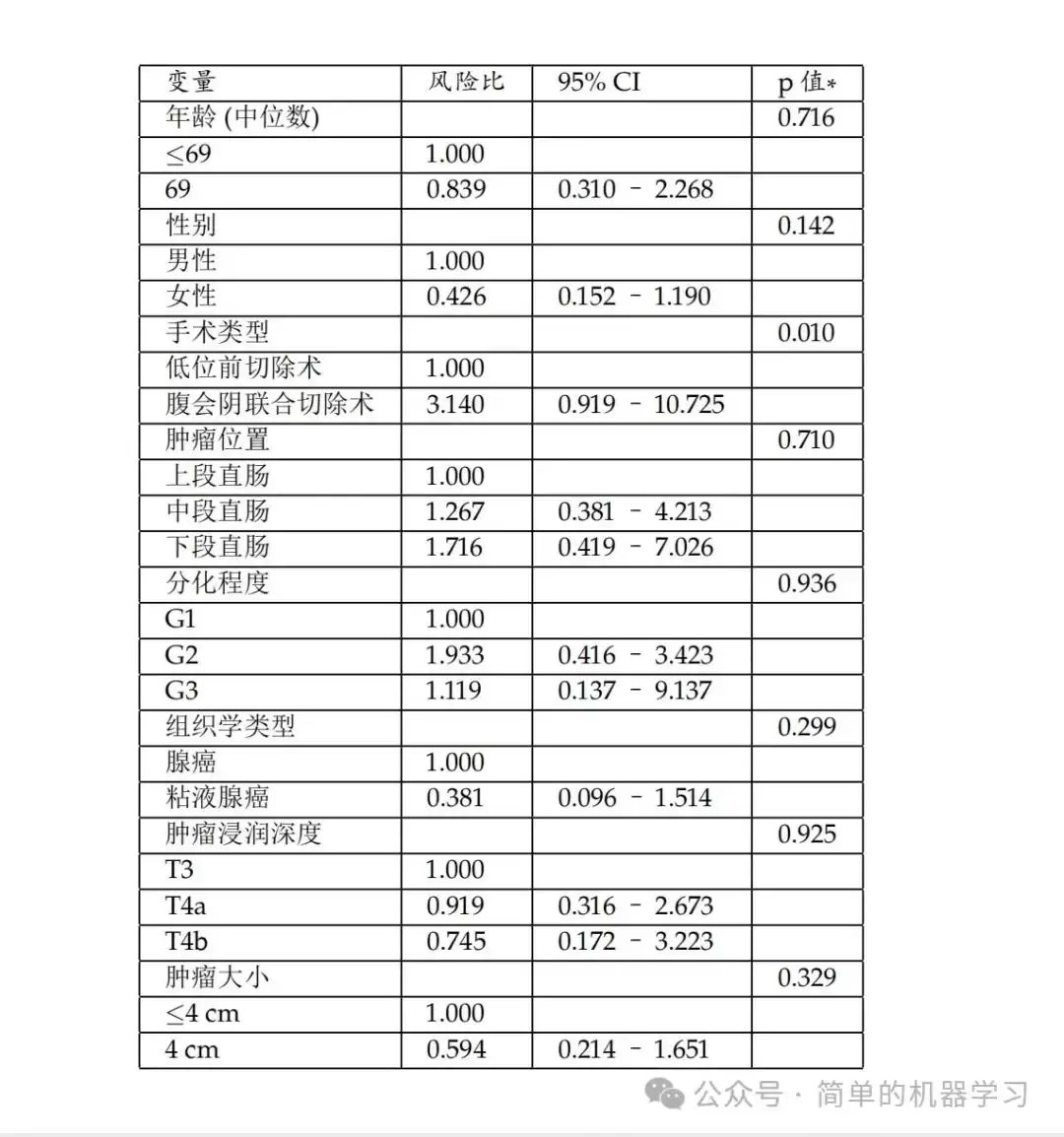
总结
本站所有软件,都由网友上传,如有侵犯你的版权,请发邮件haolingcc@hotmail.com 联系删除。 版权所有 Copyright@2012-2013 haoling.cc




