LLMChainExtractor:为律师、新闻编辑和客服团队带来高效解决方案
来源:互联网 更新时间:2026-06-14 14:15
信息量爆炸式增长的今天,企业和个人几乎每天都要面对海量文档。如何快速提取关键信息,成了效率提升的核心命题。LLMChainExtractor 正是在这个背景下进入视野的工具——它能够智能地从文档中抽取出你需要的那部分内容,省去大量手动筛选的时间。下面从几个具体业务场景出发,看看它到底能怎么用。
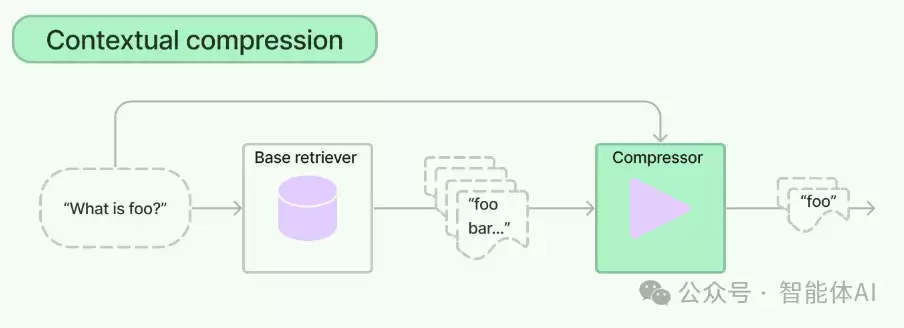
一、法律领域:合同与案件文档分析
1、背景
法律行业里,律师和法务每天要处理的合同、诉讼材料、判决书堆积如山。这些文档动辄几十页,术语密集,手动查找关键条款不仅费时,还容易漏掉重要信息。效率就是时间,而时间在法庭上往往等于胜负。
2、业务挑战
- 合同里密密麻麻的条款和细节,人工检索费时且易出错。
- 案件文书量大,快速定位法律条文中的关键信息,对律师团队而言是硬骨头。
3、如何使用 LLMChainExtractor
LLMChainExtractor 能从合同和案件文书中智能抽取相关段落。比如律师输入“违约金”或“合同解除条件”作为查询,系统会自动把合同中对应的条款拎出来。
4、业务操作示例
- 审查一份合同时,律师只需输入关键词“违约金”,系统就能提取所有涉及违约金的段落,省去逐页翻找的功夫。
- 处理案件文书时,输入“赔偿条款”即可快速定位赔偿相关的内容,案件推进速度明显提升。
5、示例代码
from langchain.retrievers.document_compressors.chain_extract import LLMChainExtractor
from langchain.chains.llm import LLMChain
from langchain_core.documents.base import Document
# 创建 LLMChain 实例
llm_chain = LLMChain(...)
# 创建 LLMChainExtractor 实例
llm_chain_extractor = LLMChainExtractor(llm_chain=llm_chain)
# 示例文档:法律合同
documents = [
Document(page_content="如果一方违约,另一方有权要求支付违约金。"),
Document(page_content="违约金的具体金额应在合同签订时协商确定。"),
Document(page_content="合同解除条件包括双方自愿解除等情形。")
]
# 查询违约金相关内容
query = "违约金"
# 提取与违约金相关的段落
relevant_paragraphs = llm_chain_extractor.compress_documents(documents, query)
# 输出相关段落
for paragraph in relevant_paragraphs:
print(paragraph.page_content)6、输出示例
如果一方违约,另一方有权要求支付违约金。违约金的具体金额应在合同签订时协商确定。
7、业务价值
- 效率提升:快速定位关键信息,律师能把更多精力放在案件策略上,而不是翻文档。
- 减少人工错误:智能提取避免了手动筛查的遗漏或误读,条款把控更精准。
二、新闻领域:新闻摘要生成与内容检索
1、背景
新闻网站每天产出海量报道,读者其实只想快速抓取核心要点,而不是从头到尾看完几千字。传统的摘要生成和信息检索方式效率偏低,很难满足这种“快准狠”的需求。
2、业务挑战
- 新闻内容冗长,读者需要第一时间抓住重点。
- 海量文章里,如何高效提取关键信息,提升阅读体验,是新闻平台普遍面临的难题。
3、如何使用 LLMChainExtractor
LLMChainExtractor 可以自动生成新闻摘要或提取相关段落。用户输入查询,系统就从新闻库中拉出匹配的内容,甚至直接给出简洁的摘要。
4、业务操作示例
- 编辑处理一篇背景复杂的报道时,可以用它自动提取关键信息,生成摘要直接发布给读者。
- 用户搜索“关键事件”或“相关报道”,系统能快速从数据库中找到对应的文章段落,检索效率直线上升。
5、示例代码
# 假设新闻内容文档
documents = [
Document(page_content="今天,政府宣布将推出新的经济刺激计划,预计将帮助缓解经济压力。"),
Document(page_content="经济刺激计划将包括减税、财政补贴等多项措施。"),
Document(page_content="专家认为,此举将为中小企业提供更多资金支持。")
]
# 查询相关的关键内容
query = "经济刺激计划"
# 提取与查询相关的段落
relevant_paragraphs = llm_chain_extractor.compress_documents(documents, query)
# 输出相关段落
for paragraph in relevant_paragraphs:
print(paragraph.page_content)6、输出示例
今天,政府宣布将推出新的经济刺激计划,预计将帮助缓解经济压力。经济刺激计划将包括减税、财政补贴等多项措施。
7、业务价值
- 提高用户体验:自动生成摘要让读者一目了然,不用在冗长文章里大海捞针。
- 节省阅读时间:关键信息被直接打捞出来,用户满意度自然更高。
三、客户服务:智能问答系统与文档检索
1、背景
客服团队每天要解答大量客户咨询,而这些答案往往藏在产品文档、操作手册、FAQ里。人工翻阅资料既繁琐又耗时,客户等待时间一长,体验就直线下降。
2、业务挑战
- 客服需要快速从文档中找到准确信息,才能给出靠谱回答。
- 客户问题五花八门,如何自动化从海量文档中提取答案,是提升服务效率的关键。
3、如何使用 LLMChainExtractor
LLMChainExtractor 可以作为智能问答系统的核心,自动从文档中定位与客户问题相关的答案。比如客户问“如何申请退货”,系统就能把退货政策条款直接拎出来。
4、业务操作示例
- 客户提问:“如何申请退货?”客服输入“退货政策”,系统秒级提取相关文档内容。
- 系统通过 LLMChainExtractor 从产品手册中找到退货流程的具体描述,直接呈现给客户。
5、示例代码
# 假设产品文档
documents = [
Document(page_content="如果产品有质量问题,客户可以在30天内申请退货。"),
Document(page_content="退货需要提供有效的购买凭证。"),
Document(page_content="无关信息...")
]
# 客户查询:退货政策
query = "退货政策"
# 提取与退货政策相关的段落
relevant_paragraphs = llm_chain_extractor.compress_documents(documents, query)
# 输出相关段落
for paragraph in relevant_paragraphs:
print(paragraph.page_content)6、输出示例
如果产品有质量问题,客户可以在30天内申请退货。退货需要提供有效的购买凭证。
7、业务价值
- 提高服务响应速度:自动提取文档信息,客服秒回问题,客户不用干等。
- 提高客户满意度:准确、快速的回答,直接拉升服务体验。
四、总结
LLMChainExtractor 的适用场景远比想象中更广。法律文件分析、新闻摘要生成、客服智能问答……无论哪个领域,只要涉及大规模文档处理和信息提取,它都能帮上大忙。把繁琐的检索工作交给工具,人就能把精力放在更有价值的分析和决策上。对于需要处理海量文档的团队来说,这是一个值得认真考虑的选择。

-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
免费影视剧APP推荐
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
帅气继父网名女生可爱英文(精选100个)
-
网络热词聊污是什么意思
-
抖音最火沙雕男生网名(精选100个)
-
蒙古上单是什么梗
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
韦一敏是什么梗
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
免费看片软件下载地址推荐
-
免费看电影的软件推荐
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
有寓意的易经网名男生(精选100个)
-
三角洲行动卡战备怎么弄 三角洲行动卡战备攻略
-
晨字沙雕网名大全女生(精选100个)
-
1 高效、智能、权威的智能体设计—让法律咨询体验超简单 06-14
-
2 每个IP都需要AI分身,每家企业都需要AI客服 06-14
-
4 哪些事必须对AI“零信任”? 06-14
-
5 我在GEO公司卧底30天:这里的工作就是骗AI 06-14
-
7 千问电脑版推出 AI 语音输入法 轻松语音操作新体验 06-14
-
8 AI记账软件调侃用户买衣服像“寿衣”,官方致歉并紧急整改 06-14
-
9 该不该对AI征税?一场跨时代的讨论正在美国展开…… 06-14
-
10 千问PC端上线AI语音输入,各类应用里“开口”直接用千问 06-14



