PDF Extract API:OCR文档提取与解析工具,Python+自然语言实现
来源:互联网 更新时间:2026-06-13 13:52
在处理文档解析这件事上,市面上其实已经有不少工具了,但能把精度、效率和安全性都照顾到的,还真不多。今天要聊的这款
PDF Extract API
核心功能
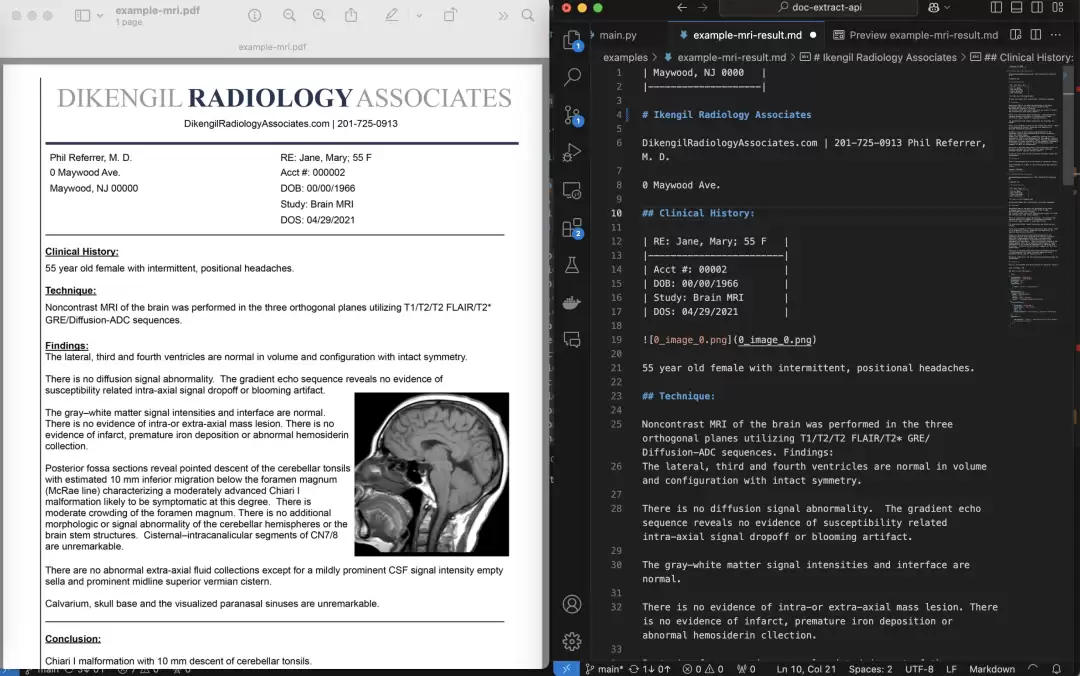
1、高精度文档提取
说到提取,最怕的就是识别不准,尤其是面对那些排版复杂、内容杂乱的资料。PDF Extract API采用的是现代OCR(光学字符识别)技术,能精准把PDF或图像里的文本信息“读”出来。更值得说的是,哪怕文档里夹杂着复杂的表格、数字甚至数学公式,它也能给咱梳理得清清楚楚,信息在转化的过程中几乎不丢、不错。
2、个人识别信息(PII)匿名化
隐私保护嘛,现在谁不重视?这款API自带一个隐藏技能——自动移除文档中的个人识别信息(PII)。也就是说,当你需要处理一些敏感数据时,比如合同、病例、身份证照等,它可以自动把涉及隐私的部分抹掉,整个过程无需人工介入。这样一来,不仅可以安心分享文件,也更容易满足各类隐私合规要求。
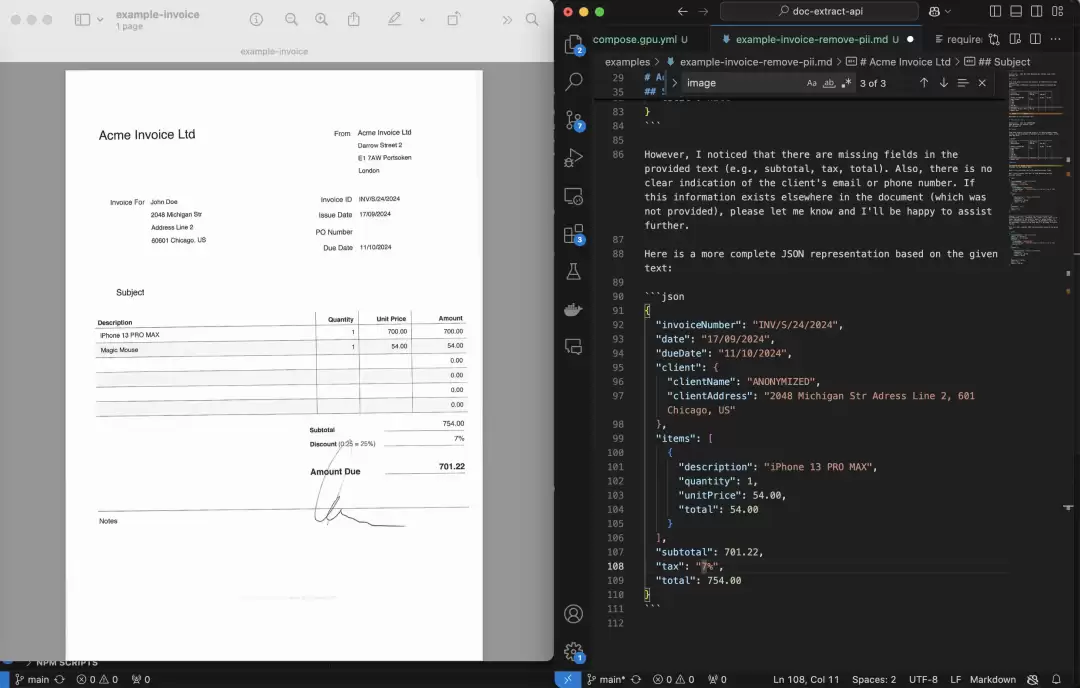
3、结构化输出
提取出来的内容最终以什么形式呈现,也很关键。PDF Extract API支持直接将内容转为JSON或Markdown格式。前者适合做后续的数据分析和系统集成,后者则更适合生成网页或快速排版的文档。简单说,两头都沾得上,既能给机器读,也能给人看。
4、高效的后台处理
技术底子上,这个API是用
FastAPI
Celery
Redis
结语
PDF Extract API

-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
免费影视剧APP推荐
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
抖音最火沙雕男生网名(精选100个)
-
网络热词聊污是什么意思
-
帅气继父网名女生可爱英文(精选100个)
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
我的末日校园海斗手游上线时间是哪天
-
蒙古上单是什么梗
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
免费看电影的软件推荐
-
韦一敏是什么梗
-
晨字沙雕网名大全女生(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
短剧《情绪超市》剧情介绍
-
2 关于工作流Chatbot产品的设计思考 06-13
-
3 我对超大型文本多Agent的编排设计思路 06-13
-
4 腾讯分析型 BI+AI 产品 OlaChat 创新探索 06-13
-
6 AI世代,警惕一场静悄悄发生的“认知投降” 06-13
-
8 融资813亿,估值3000亿,这家AI公司创办仅一年 06-13
-
9 SK集团拟在日本新建AI工厂 计划两三年内投产运营 06-13
-
10 当AI取代智力劳动,是时候考虑“全民分红”了 06-13



