32B超越671B,M-A-P全开源数学定理证明模型OProver,五项评测三项第一
来源:互联网 更新时间:2026-06-10 14:27
形式化定理证明,一直是LLM领域公认最严苛的推理试金石。每一步推导都必须通过Lean 4内核的机器验证,容不得半点模糊。
过去两年,开源社区在MiniF2F、PutnamBench这类基准测试上的成绩持续攀升,但大家逐渐发现,增长路径越来越趋同:扩模型、堆数据,到了部署阶段再叠加检索和多轮修正。
这里有一个关键问题始终没解决——检索信号、编译器反馈和失败修复,大多只在部署时作为外部流程接入。模型在训练阶段根本没有系统学习如何利用这些信号。训练和部署之间,其实一直存在一道“策略错位”的裂缝。
为了真正弥合这道裂缝,M-A-P开源社区与南京大学等团队联合提出了OProver。这套框架的核心思路很直接:把检索增强、编译器反馈与多轮修复直接内化到训练策略中,而不是让它们沦为部署时的“外设”。
 在五个主流的Lean 4 whole-proof prover评测中,OProver-32B拿下三项第一、两项第二。具体来说:MiniF2F达到93.3,ProverBench是58.2,PutnamBench跑到11.3,这些成绩都领先于LongCat-Flash-Prover w/ TIR。更难得的是,在全部五项评测中,它对671B规模的DeepSeek-Prover-V2形成了全面超越。
研究团队还同步开源了OProofs语料库,包含176万条形式化陈述和680万个经编译器验证的证明,以及8B和32B共7个模型权重。
代码、权重与训练脚本已经全部开源。
在五个主流的Lean 4 whole-proof prover评测中,OProver-32B拿下三项第一、两项第二。具体来说:MiniF2F达到93.3,ProverBench是58.2,PutnamBench跑到11.3,这些成绩都领先于LongCat-Flash-Prover w/ TIR。更难得的是,在全部五项评测中,它对671B规模的DeepSeek-Prover-V2形成了全面超越。
研究团队还同步开源了OProofs语料库,包含176万条形式化陈述和680万个经编译器验证的证明,以及8B和32B共7个模型权重。
代码、权重与训练脚本已经全部开源。
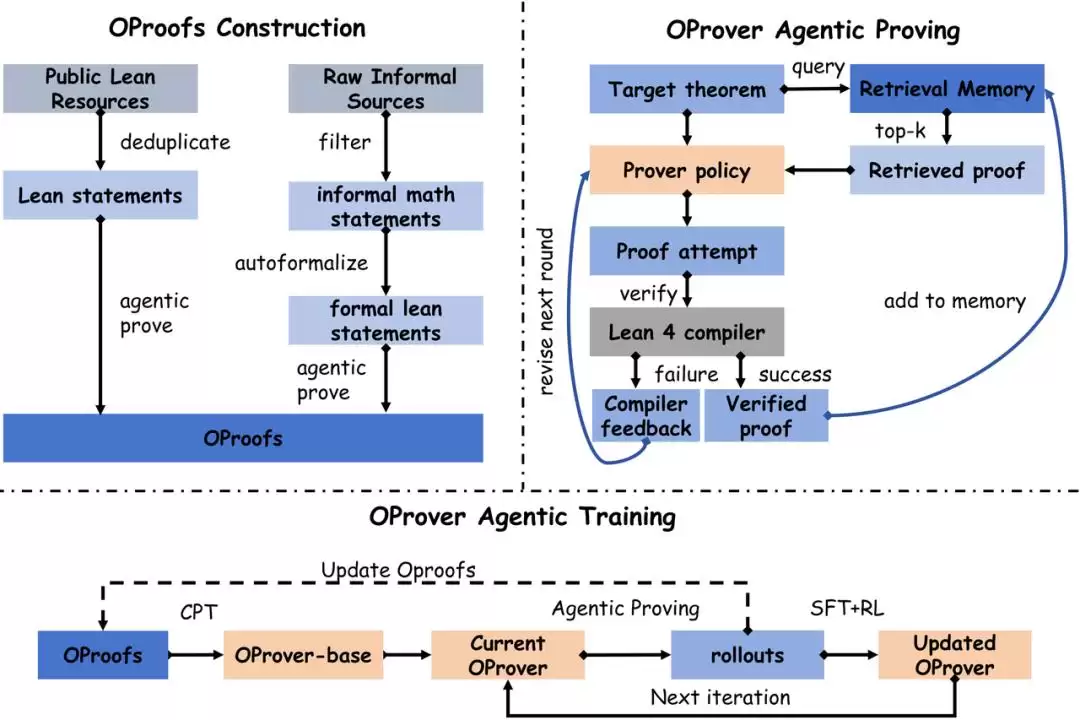
 OProofs由两条构建分支组成。
**1、公开资源再证明**
以NuminaMath-LEAN、Lean-Workbook、Leanabell-Prover-FormalStmt等公开Lean资源为起点,清洗去重后,通过agentic proving流程重新生成并验证证明,同时收集检索上下文、失败尝试和修复轨迹。
**2、自然语言到形式化**
从Common Crawl和GitHub挖掘数学陈述,用CriticLean自动形式化为Lean 4,再通过agentic proving流程生成并验证证明。
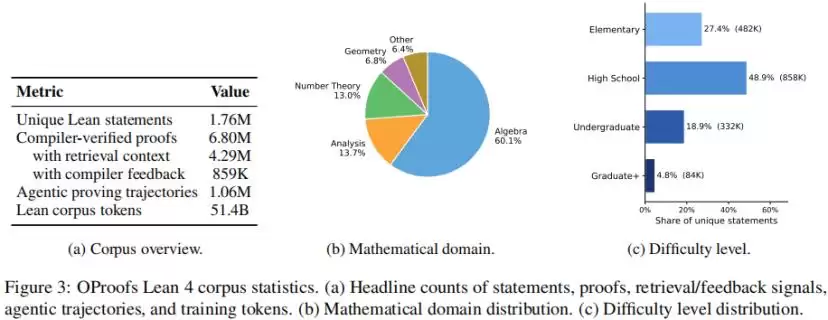
从覆盖范围来看,OProofs横跨多个数学方向:代数占60.1%、分析13.7%、数论13.0%、几何6.8%。难度分布以elementary(27.4%)和high-school(48.9%)层级为主,同时包含18.9%的本科水平和4.8%的研究生水平问题。
OProofs由两条构建分支组成。
**1、公开资源再证明**
以NuminaMath-LEAN、Lean-Workbook、Leanabell-Prover-FormalStmt等公开Lean资源为起点,清洗去重后,通过agentic proving流程重新生成并验证证明,同时收集检索上下文、失败尝试和修复轨迹。
**2、自然语言到形式化**
从Common Crawl和GitHub挖掘数学陈述,用CriticLean自动形式化为Lean 4,再通过agentic proving流程生成并验证证明。
从覆盖范围来看,OProofs横跨多个数学方向:代数占60.1%、分析13.7%、数论13.0%、几何6.8%。难度分布以elementary(27.4%)和high-school(48.9%)层级为主,同时包含18.9%的本科水平和4.8%的研究生水平问题。
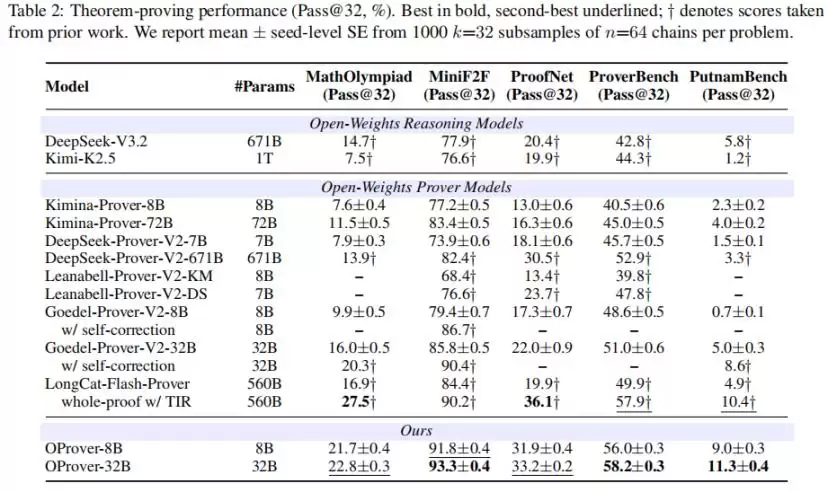 在open-weight whole-proof prover范围内,OProver-32B有三个值得关注的结论:
**1、32B全面超越671B**
OProver-32B在全部五项评测中都超越了DeepSeek-Prover-V2(671B),在MiniF2F(93.3)、ProverBench(58.2)、PutnamBench(11.3)上同时领先LongCat-Flash-Prover w/ TIR(560B)。
**2、8B打平32B**
OProver-8B在五个benchmark上全部超越了Goedel-Prover-V2-32B,参数量只有后者的四分之一。
**3、迭代后训练持续增益**
在MiniF2F-Test上,OProver-8B从79.5提升至91.8(+12.3),OProver-32B从84.7提升至93.3(+8.6)。
在open-weight whole-proof prover范围内,OProver-32B有三个值得关注的结论:
**1、32B全面超越671B**
OProver-32B在全部五项评测中都超越了DeepSeek-Prover-V2(671B),在MiniF2F(93.3)、ProverBench(58.2)、PutnamBench(11.3)上同时领先LongCat-Flash-Prover w/ TIR(560B)。
**2、8B打平32B**
OProver-8B在五个benchmark上全部超越了Goedel-Prover-V2-32B,参数量只有后者的四分之一。
**3、迭代后训练持续增益**
在MiniF2F-Test上,OProver-8B从79.5提升至91.8(+12.3),OProver-32B从84.7提升至93.3(+8.6)。
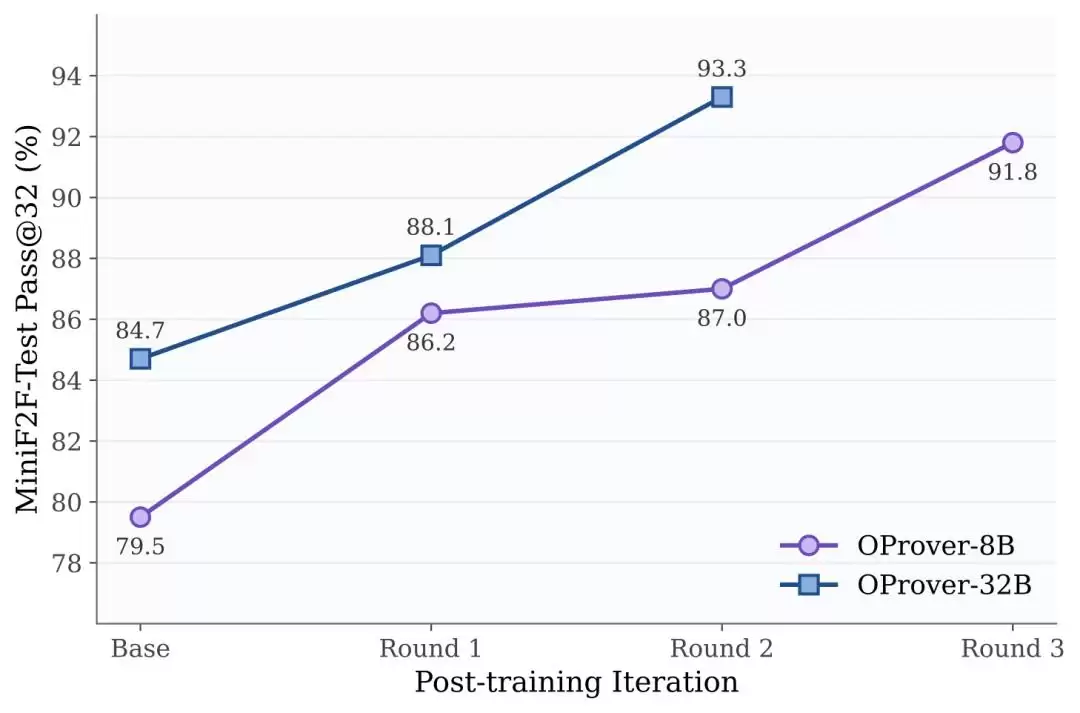
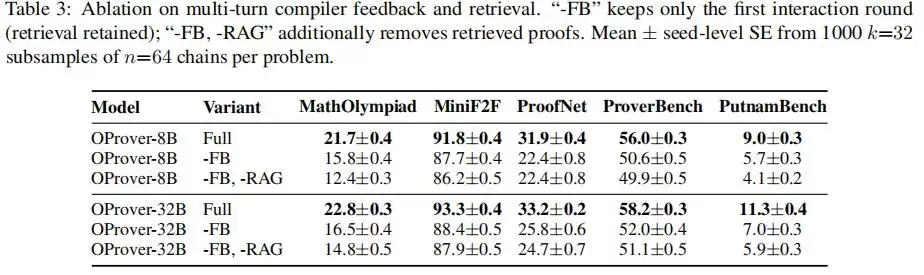
 最优预算分配与benchmark的难度相关:多数benchmark更偏向增加refinement深度,而PutnamBench这类低成功率难题则需要在修复深度与并行探索之间取得平衡。
最优预算分配与benchmark的难度相关:多数benchmark更偏向增加refinement深度,而PutnamBench这类低成功率难题则需要在修复深度与并行探索之间取得平衡。
在五个主流的Lean 4 whole-proof prover评测中,OProver-32B拿下三项第一、两项第二。具体来说:MiniF2F达到93.3,ProverBench是58.2,PutnamBench跑到11.3,这些成绩都领先于LongCat-Flash-Prover w/ TIR。更难得的是,在全部五项评测中,它对671B规模的DeepSeek-Prover-V2形成了全面超越。
研究团队还同步开源了OProofs语料库,包含176万条形式化陈述和680万个经编译器验证的证明,以及8B和32B共7个模型权重。
代码、权重与训练脚本已经全部开源。
策略错位:训练与部署之间的核心矛盾
近年来,Goedel-Prover-V2、DeepSeek-Prover-V2、Kimina-Prover等Lean 4证明系统,在MiniF2F上已经把Pass@32推到了相当高的水平。同时也有工作开始引入检索、编译器反馈或self-correction。 问题在于,这些信号主要作为部署阶段的增强流程被接在外部,而不是从训练阶段就被正式纳入学习目标。 这就形成了典型的错位—— - 训练阶段,模型看到的是一组清晰的theorem→verified proof监督对 - 部署阶段,系统却把检索到的相关证明、上一轮失败的尝试,以及Lean编译器的反馈重新提供给模型,要求它进行多轮修复 OProver的核心思路,就是让训练目标和部署时的证明过程真正对齐。让模型在训练阶段就开始学习如何执行agentic refinement loop,把多轮修正、检索相关证明和编译器反馈都内化为训练策略的一部分,而不是部署阶段临时接上的外包装。轻量、可端到端训练
部署阶段:有限轮次修复循环
OProver把定理证明建模为一个有限轮次的修复循环。具体来说,每次尝试都基于当前的形式化目标、从检索记忆库中拿到的top-k个已验证证明、上一轮的证明尝试记录,以及Lean 4编译器返回的诊断信息,来生成下一次的证明。只要任意一轮通过了验证,整条轨迹就算成功。训练阶段:两阶段训练
- **持续预训练(CPT)**:在约65B token的混合语料上预训练,其中约30%来自OProofs的Lean 4数据,20%是代码数据(OpenCoder),40%是数学语料(Nemotron-Math-4-Plus),还有10%的长CoT数据 - **迭代后训练**:交替进行agentic proving rollout、SFT(基于round-level修复样本)和RL(基于GSPO算法与难题集) 关键设计在于,检索结果、失败尝试和编译器反馈不再是部署阶段的临时外部机制,它们被正式纳入模型需要学习的证明策略中。数据与模型的协同进化
OProofs语料库和prover策略在迭代中相互促进。每轮迭代里,当前prover在题库上生成的新验证证明会被加入OProofs,并索引进检索记忆库;修复轨迹成为下一轮SFT的训练样本;而那些尚未解决的“难题组”,则为下一轮RL提供训练信号。 数据、训练与策略,形成了一个持续演化的闭环。OProofs:面向agentic prover的Lean 4语料
研究团队同步构建并开源了OProofs,包含约176万条形式化陈述和680万条经编译器验证的证明。 其中,429万条证明保留了检索到的相关证明上下文,85.9万条样本包含此前失败尝试的Lean编译器反馈。模型不只是看到“最终正确证明是什么”,还能学到“证明失败后,如何利用检索结果和编译器反馈继续修复”。
OProofs由两条构建分支组成。
**1、公开资源再证明**
以NuminaMath-LEAN、Lean-Workbook、Leanabell-Prover-FormalStmt等公开Lean资源为起点,清洗去重后,通过agentic proving流程重新生成并验证证明,同时收集检索上下文、失败尝试和修复轨迹。
**2、自然语言到形式化**
从Common Crawl和GitHub挖掘数学陈述,用CriticLean自动形式化为Lean 4,再通过agentic proving流程生成并验证证明。
从覆盖范围来看,OProofs横跨多个数学方向:代数占60.1%、分析13.7%、数论13.0%、几何6.8%。难度分布以elementary(27.4%)和high-school(48.9%)层级为主,同时包含18.9%的本科水平和4.8%的研究生水平问题。
五项评测三项第一、两项第二
研究团队在MiniF2F、MathOlympiad、ProofNet、ProverBench、PutnamBench五个Lean 4 benchmark上做了评估,默认报告Pass@32,基于n=64条独立multi-round rollouts的无偏估计。
在open-weight whole-proof prover范围内,OProver-32B有三个值得关注的结论:
**1、32B全面超越671B**
OProver-32B在全部五项评测中都超越了DeepSeek-Prover-V2(671B),在MiniF2F(93.3)、ProverBench(58.2)、PutnamBench(11.3)上同时领先LongCat-Flash-Prover w/ TIR(560B)。
**2、8B打平32B**
OProver-8B在五个benchmark上全部超越了Goedel-Prover-V2-32B,参数量只有后者的四分之一。
**3、迭代后训练持续增益**
在MiniF2F-Test上,OProver-8B从79.5提升至91.8(+12.3),OProver-32B从84.7提升至93.3(+8.6)。
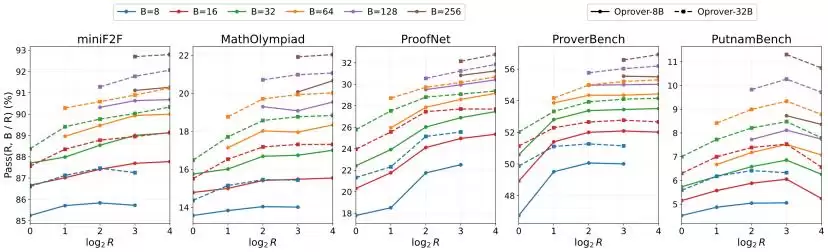
消融实验:检索与编译器反馈协同贡献
移除多轮compiler feedback后,性能下降最为明显:OProver-32B在PutnamBench从11.3降至7.0,在ProofNet从33.2降至25.8。进一步移除检索后,性能继续下滑到5.9和24.7。 这说明提升并非来自简单的best-of-N采样,而是来自检索增强的证明生成与编译器反馈引导的多轮修复之间的协同。其中,Lean编译器反馈提供了主要的修复信号;检索上下文则提供了相关的证明结构和可参考的证明片段。
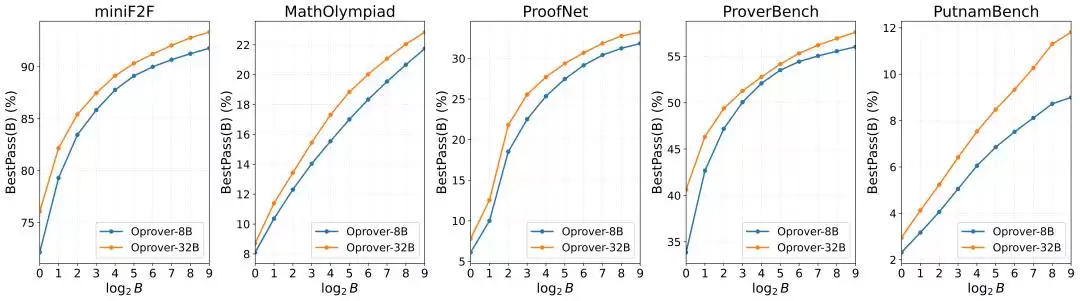
测试时扩展:更多推理预算稳定转化
随着推理预算从8增加到256,OProver-32B在五个benchmark上都呈现稳定提升:MiniF2F从87.5到92.8,MathOlympiad从15.5到22.0,ProofNet从25.6到32.8,ProverBench从51.3到56.9,PutnamBench从6.4到11.3。
最优预算分配与benchmark的难度相关:多数benchmark更偏向增加refinement深度,而PutnamBench这类低成功率难题则需要在修复深度与并行探索之间取得平衡。
开源与发布
研究团队同步开源了OProver的模型、数据与训练代码,覆盖不同训练阶段的checkpoint、OProofs语料和训练pipeline。 - m-a-p/OProver-32B / OProver-8B — 最终模型 - m-a-p/OProver-32B-Base / Round1 — 32B各阶段checkpoint - m-a-p/OProver-8B-Base / Round1 / Round2 — 8B各阶段checkpoint - m-a-p/OProofs — 176万条形式化陈述 / 680万条证明 / 106万条轨迹 当然,OProver目前仍主要围绕Lean 4 whole-proof proving展开。后续值得关注的是,这种agentic refinement框架能否迁移到Coq、Isabelle以及工程级的formal methods工具中,以及在更长的数据与模型协同进化周期里,性能提升的持续性究竟能有多强。 论文:https://arxiv.org/abs/2605.17283 代码:https://github.com/multimodal-art-projection/OProver 模型与数据:https://huggingface.co/collections/m-a-p/oprover-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
免费影视剧APP推荐
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
网络热词聊污是什么意思
-
帅气继父网名女生可爱英文(精选100个)
-
抖音最火沙雕男生网名(精选100个)
-
蒙古上单是什么梗
-
免费看电影的软件推荐
-
韦一敏是什么梗
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
有寓意的易经网名男生(精选100个)
-
韩漫小少爷网名大全女生(精选100个)
-
美国市场:股票相对债券的风险溢价正在消失
-
动漫《情色漫画老师OVA》剧情介绍
-
2 重量很轻的笔记本推荐:惠普星Book Pro Air 14 06-03
-
4 智能预约+多模式!九阳K7Pro承包你全家的营养早餐 06-05
-
5 新标准落地!海信小墨E5SPro成为首批金E权威护眼认证电视 06-06
-
6 海螺AI提示词不听指令怎么办_掌握任务拆解Prompt技巧 06-08
-
7 画世界Pro如何调整分辨率 06-08
-
8 如何编写海螺AI高转化率提示词_掌握结构化Prompt公式技巧 06-08
-
10 《前端项目技术文档生成器》Prompt(可复用模板) 06-10



