5秒完成3D场景编辑,北大&港中文&上海AI Lab搞出VGGT-Edit,120倍加速太炸了
来源:互联网 更新时间:2026-05-28 09:44
3D世界现在“会看”了,但离“会改”还差得远。
从NeRF到3D Gaussian Splatting,再到VGGT、π³这类前馈式重建模型,技术迭代的速度快得惊人——几张图片,几秒钟,一个完整的3D场景就能跃然眼前。
但瓶颈也恰恰在此。这些模型已经学会了“理解”三维世界,却远未掌握“修改”三维世界的本领。你可以让它重建一个房间,但很难真正对它下达指令:
“把椅子挪到窗边,删掉中间那把,再把灰色的皮沙发换成白色的长毛款。”
更棘手的是,一旦涉及这类复杂编辑,现有方法往往立刻“露馅”——从某个角度看椅子消失了,换个角度它又“鬼魂”般重现;明明只想改动前景物体,背景却跟着一起扭曲变形。
面对这个核心挑战,一支由北京大学、香港中文大学、上海AI Lab、NTU等机构组成的研究团队,提出了一套全新的解决方案:
VGGT-Edit
彻底抛弃迂回的2D路径,直接在3D空间里完成编辑。
在DeltaScene测试集上,VGGT-Edit在语义一致性、多视角稳定性和推理速度三个关键维度全面超越现有方法,单次编辑仅需约
5秒
120倍
问题的根源,始终在2D
问题的根源,始终在2D
目前绝大多数3D编辑方法,骨子里仍是“2D思维”。它们通常先把3D场景拆解成一系列2D视角图片,然后对每张图进行独立编辑,最后再试图把这些修改拼回一个3D整体。
这种“分而治之”的策略带来了一个根本性难题:由于每个视角被单独处理,编辑结果在多视角间无法自洽。于是就会出现:
- 这个视角里椅子被删除了;
- 转到另一个角度,椅子却还在;
- 不该动的背景区域发生了漂移;
- 物体边缘充斥着恼人的重影和闪烁。
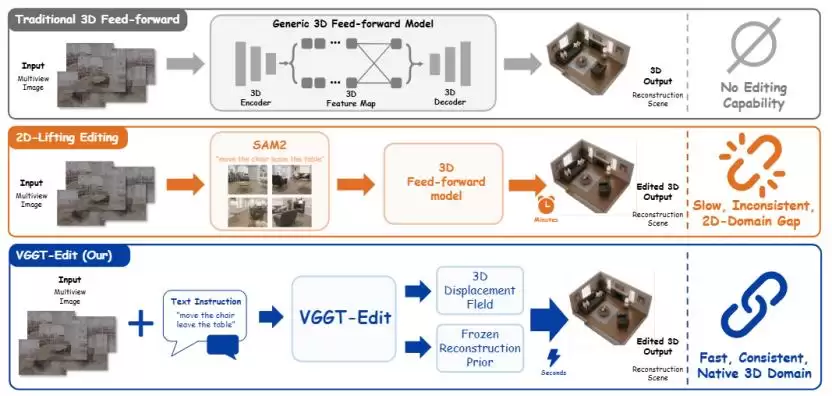
△ 传统2D编辑方法导致的多视角不一致问题
很多结果看起来更像是“在不同角度硬P出来的图片集合”,而非一个内在统一、稳定的3D空间。对于追求高可靠性的机器人导航、AR/VR应用乃至未来的空间智能而言,这种不一致几乎是致命的——它们需要的不是“某个角度看起来正确”,而是整个3D世界在任何视角下都保持逻辑一致。
原生3D编辑:从概念到可用
原生3D编辑:从概念到可用
VGGT-Edit的应对策略非常直接:
既然问题出在2D转换的损耗上,那就干脆不回去了
整个框架构建在VGGT这类高效的前馈式3D重建模型之上,继承了其快速生成紧凑3D表示的能力。但团队的巧思在于,他们没有选择笨拙地重新生成整个场景,而是引入了一个精妙的机制:
残差场预测。
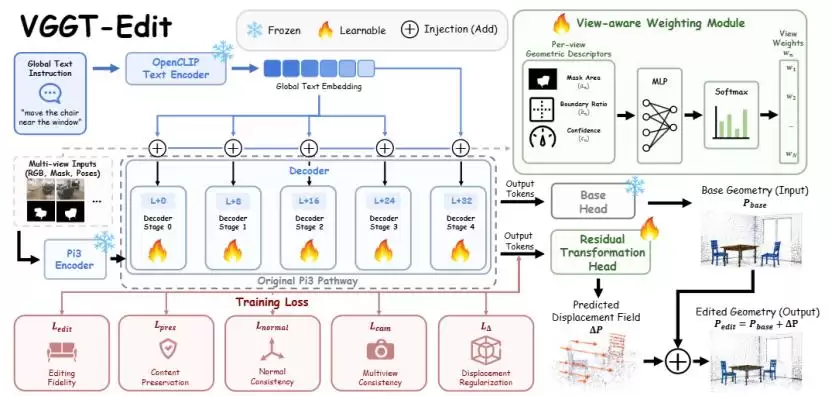
△ VGGT-Edit的“残差场预测”核心思路
这个概念可以简单理解为:模型首先牢牢抓住原始场景中稳定的3D结构,然后只去学习“哪里需要发生变化”。比如:
- 椅子需要向右平移;
- 沙发的表面材质要从皮质变为绒布;
- 某个物体需要被移除;
- 一个新的家具需要被添加进来。
所有这些编辑操作,都被统一表达为一个简洁的公式:
新场景 = 原场景 + 局部残差变化
这个设计带来了一个显著优势:由于场景中大部分区域无需改动,模型就不必费力不讨好地“重新构想整个世界”,只需聚焦于局部修改。其结果就是,那些未被编辑的背景区域能够保持惊人的稳定性,这正是VGGT-Edit与众多现有方法最直观的区别之一。
文本语义,首次与3D空间深度对齐
文本语义,首次与3D空间深度对齐
研究团队在实践中发现,如果只是简单地将一句文本指令(如“移动椅子”)输入模型,很容易出现“指令理解偏差”——模型大概知道你想改什么,却不太确定具体该改哪里。
为了解决这个“对齐”难题,VGGT-Edit设计了一套关键机制:
深度同步文本注入
其本质是让文本语义信息与3D空间特征,在模型处理的多个深度层级中持续、同步地进行融合。传统方法往往只在网络前端注入一次文本信息,而VGGT-Edit则在多个关键层反复融合文本语义。这使得模型在整个3D表示的形成过程中,始终能明确:
- 当前应该修改哪个空间区域;
- 修改的具体目标是什么;
- 目标在3D空间中的确切位置。
与此同时,团队还设计了一套
视角重要性加权
一个为“编辑”而生的专用模块
一个为“编辑”而生的专用模块
除了整体框架创新,VGGT-Edit还有一个至关重要的组成部分——一个
专门为3D编辑任务设计的编辑头
团队发现,对于VGGT这类原生用于重建的模型,其输出头更专注于“如何精准地恢复场景”。但3D编辑的核心需求截然不同,它需要解决的是:
如何在保持整体场景稳定的前提下,精准且一致地修改局部区域
因此,VGGT-Edit额外引入了一个独立的编辑分支,专门用于预测场景中需要发生的局部变化。这个编辑头直接作用于模型的3D表示空间,并输出对应的残差场。本质上,它学习的是:
- 哪些区域应该原封不动;
- 哪些区域是编辑的目标;
- 编辑后如何确保所有视角看到的结果都一致。
相比直接重新生成整个场景,这种“外科手术式”的局部修改方式不仅结果更稳定,而且计算效率也高得多。这正是让VGGT这类快速重建模型获得实用化编辑能力的关键一步。
十万级数据集:专为训练“3D编辑”而生
十万级数据集:专为训练“3D编辑”而生
为了有效训练VGGT-Edit,团队构建了一个全新的、规模接近10万样本的3D编辑数据集——
DeltaScene

△ DeltaScene数据集示例
更关键的是,其数据生成流程实现了高度自动化。研究团队利用Qwen3.5-Plus、SAM3、Qwen-Image-Editing-Max等一系列模型,自动完成编辑指令生成、目标物体识别、多视角编辑模拟,并经过严格的3D一致性过滤,最终得到真正满足“多视角几何一致”要求的高质量训练数据。
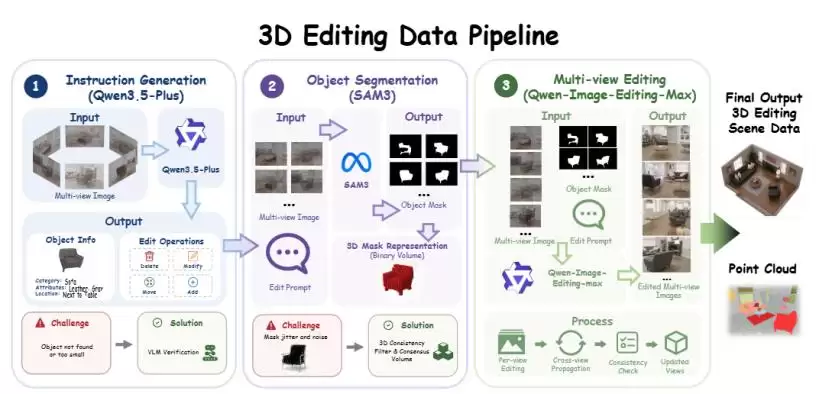
△ 自动化数据生成与过滤流程
对于原生3D编辑任务来说,这一步至关重要。模型需要学习的,不仅仅是图像层面的像素变化,更是同一条编辑指令如何在所有不同视角下,引发同一个协调、一致的3D空间变化。
3D编辑,首次触及实时交互门槛
3D编辑,首次触及实时交互门槛
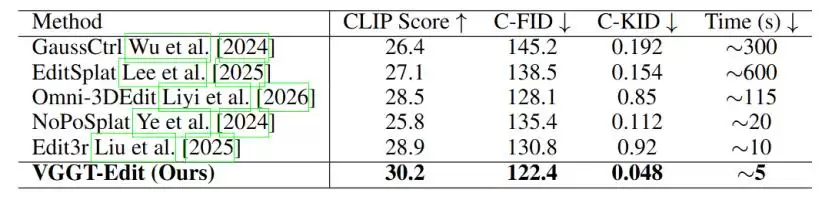
从实验结果看,这条“原生3D编辑”的路线是行之有效的。
在DeltaScene测试集上,VGGT-Edit在语义一致性、多视角稳定性和推理速度这三个核心评估维度上,均超越了现有的主流方法。
特别是在添加家具、调整物体位置、修改材质属性等复杂编辑任务中,许多传统方法产生的输出仍带有明显的“贴图感”和几何错位,而VGGT-Edit生成的结果,则更接近一个真实、稳固的3D空间。

△ VGGT-Edit与其他方法的编辑效果对比
速度的提升更为关键。根据论文数据,VGGT-Edit完成单次编辑仅需大约
5秒
120倍
对于机器人实时环境重构、数字孪生更新、AR/VR内容创作等领域而言,这种速度的飞跃意义重大。只有当编辑操作足够快,3D世界才能真正从一个静态的“观看对象”,转变为一个可以实时、动态操作的“交互空间”。
△ 快速编辑能力开启实时交互可能性
模型开始理解“空间变化”本身
模型开始理解“空间变化”本身
论文中还有一个颇有意思的发现。研究人员输入了一条模型在训练中从未见过的指令:“将中间那把椅子顺时针旋转90度。”
结果,模型依然成功地完成了编辑任务。

△ 对未见过指令(旋转)的泛化编辑能力
这表明,VGGT-Edit所学到的,并非简单的编辑模板匹配,而是开始真正理解文本语义如何映射到3D空间中的几何与属性变化。这种对“空间变化”本身的泛化理解能力,可能比“生成一个静态3D场景”更为重要。
因为对于未来的空间智能而言,最核心的能力或许不在于“创造一个世界”,而在于能否像人类一样,对这个已存在的世界进行自由、稳定、实时的感知与修改。VGGT-Edit,正将我们向这个目标推近了一步。
论文链接:https://arxiv.org/abs/2605.15186

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
无尽花界时装合辑
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
免费影视剧APP推荐
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
1 开源的AI MPU 05-28
-
2 OpenAI Codex Skills 深度技术解读 05-28
-
4 一个Skill,治好了所有AI模型的“洋毛病” 05-28
-
5 亚马逊12亿美元收购Zoox,自动驾驶又迎来巨头? 05-28
-
6 愚人节特辑:AI比你想象得更蠢 05-28
-
7 宣布关闭所有线下零售店,互联网公司到底需不需要实体店? 05-28
-
8 多稿合并:从手动比稿到一键 Skill 05-28
-
9 零帧起手 Codex × Figma 双向工作流实操 05-28
-
10 NoteAI - AI 一站式知识提取工具,支持视频、网页、音频 05-28



