大模型再强也白搭,企业 AI 最后卡在数据底座上
来源:互联网 更新时间:2026-07-03 13:34
刚看完OceanBase AI数据库的线上发布会,感触挺深。这场发布回答了一个非常务实的问题:当数据库的主要使用者不再是人,而是Agent时,企业的数据底座到底该往哪个方向演进?
先说几个核心判断:企业AI往前走,卡点已经越来越少出在模型本身,更多会落到数据这一层。上下文够不够完整,非结构化数据能不能进治理,搜索结果准不准,Agent试错会不会污染生产环境——这些问题如果压不住,AI应用就很难真正跑进核心业务。
过去我们聊数据库,最常说的就是高并发、事务、容灾、成本和性能。到了Agent时代,问题突然多了好几层:
- Agent要理解业务上下文
- Agent要处理文档、图片、语音、视频这些多模态数据
- Agent要随时调用实时业务数据
- Agent会试错,会改数据,会搞坏环境
- Agent数量可能会从几十个扩到几百万、几千万个轻应用和小任务
这时候,数据库如果还只是人类点开后台查表的地方,显然就不够用了。OceanBase这次给出的主口径很清晰:
OceanBase AI 数据库 = 湖库一体 · 多模态 · AI 原生
一句话概括

为什么企业AI最后会卡在数据上
过去三年,企业AI的预算大头几乎都砸在了模型和算力上——买模型、接API、建知识库、做智能客服、上Copilot,这些方向热闹得很。但真正跑进业务流程之后,很多项目都会发现一个尴尬的问题:大模型越来越强,业务价值却经常卡在数据上。
原因很简单:大模型解决的是通用智能问题,企业要的是业务智能问题。通用智能会说话、会推理、会生成;但业务智能还要知道:这个客户是谁、这笔订单到哪一步了、这份合同有没有风险条款、这个规则现在还生不生效、这个用户过去几次交互留下了什么状态、这次操作能不能写回生产系统……
这些答案,全都在企业数据里。所以OceanBase这次反复强调一个核心变化:
数据库的使用者正在从人变成Agent
人用数据库的时候,大多是明确查询:查一条订单、看一张报表、筛一批异常记录。Agent用数据库的时候,动作要复杂得多:先理解上下文,再混合检索,再调用工具,再写入状态,再根据结果继续下一步,失败之后还要回滚,成功之后还要沉淀经验。这就把数据库从后台系统,直接推到了Agent工作流的正中央。

OceanBase这次真正想解决的三个问题
第一,企业的数据形态已经变了
过去数据库主要管结构化数据:表、行、列、字段。现在Agent要吃的上下文里,有合同PDF、客服录音、会议纪要、体检报告、商品图片、行车视频、风控规则、知识库片段、对话记忆、向量、JSON……这些东西如果还散落在对象存储、文件系统、搜索引擎、向量库、业务库之间,Agent每做一步都要跨系统拼上下文。拼一次,就多一次延迟;搬一次,就多一份冗余;同步一次,就多一个一致性风险。
第二,企业的数据流动方式也变了
传统链路往往长这样:交易库 → ETL → 数仓/数据湖 → 搜索引擎/向量库 → RAG/Agent。这条链路能跑,但它很慢,也很重。Agent产生bad case、用户反馈、执行轨迹之后,如果要等几天才被离线分析挖出来,再回到线上验证,数据飞轮根本转不快。OceanBase强调“数据飞轮”的概念:Agent产生数据,数据回流优化模型和知识,优化后的能力再服务业务。飞轮转得快,AI才会越用越准。
第三,Agent会带来新的风险
人改生产数据之前会犹豫,Agent很可能直接开干。尤其在企业里,Agent会越来越多地执行生产任务——写数据、改流程、调工具、做评测。这时候数据库必须给它准备好安全边界:可以试错,但不能污染生产;可以并行,但不能互相踩脚;可以失败,但失败之后要能快速丢弃、回滚、重来。这也是这次发布最值得关注的地方:它把多模态、混合搜索、数据沙箱、海量逻辑表、开放计算放进一套架构里一起回答,避免把AI数据库收窄成向量检索。
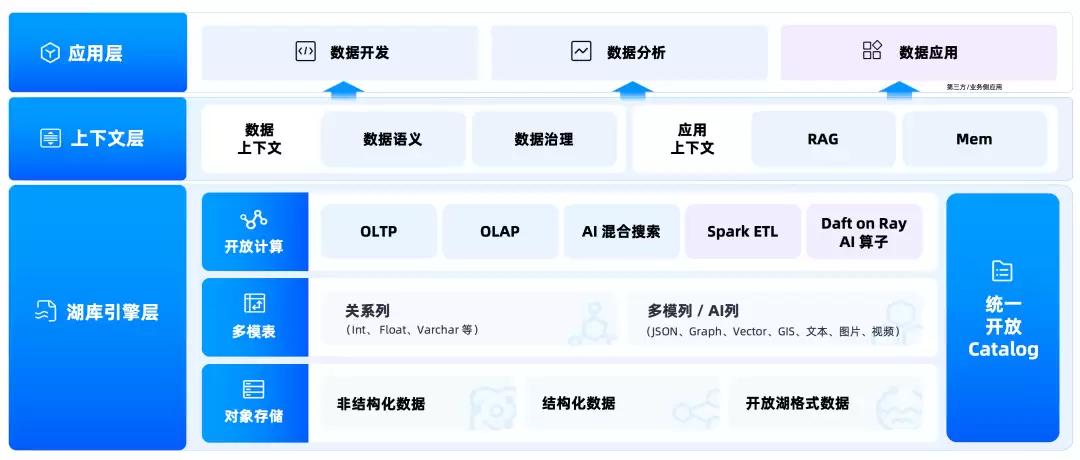
Lakebase:把湖和库放到同一张底座上
OceanBase Lakebase是这次发布里的核心引擎。它面向湖库一体、多模态数据和Agent场景,目标是用一套底座统一管理结构化、半结构化、非结构化数据,同时承载TP、AP和AI工作负载。
这句话听起来有点大,但理解起来不难:企业不想再为了一个AI应用,同时维护交易库、数仓、对象存储、搜索引擎、向量库、权限系统、ETL链路、RAG服务一堆东西。Lakebase要做的,是把关键数据底座和核心治理能力收敛起来。SQL继续处理在线事务和查询;Spark继续做批量加工;Ray/Daft继续跑AI数据链路;对象存储、S3兼容接口、Iceberg开放表格式继续接入现有生态。
这条路线很务实。企业的数据平台不会一夜重建,真正可落地的路径,通常是先减少系统接缝、减少数据搬运、减少权限割裂,再慢慢把高价值场景收敛到统一底座上。
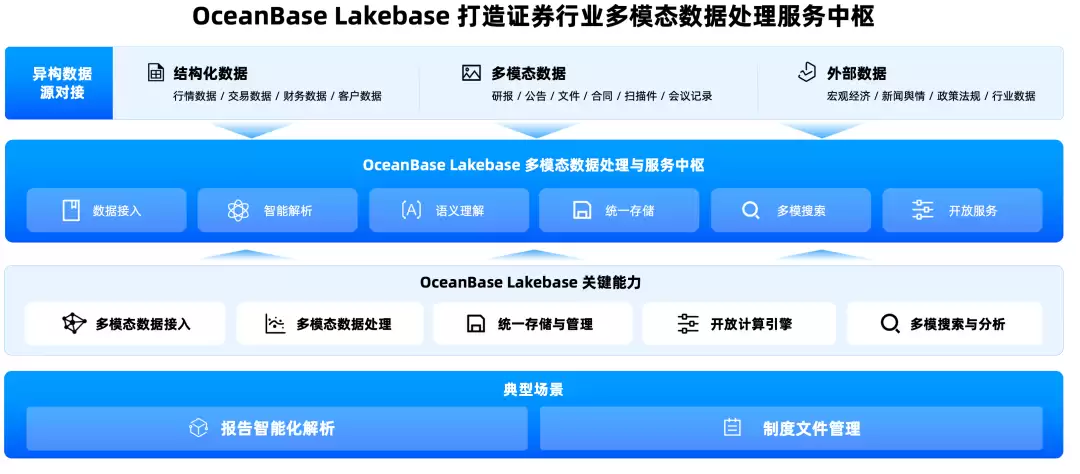
多模态数据管理:让非结构化数据有正式身份
这次最让人眼前一亮的设计,是多模表和AI列。过去企业里的非结构化数据,很多时候只是附件——合同PDF放对象存储,图片视频放文件系统,文本摘要写业务库,向量塞进向量库,权限再单独做一套。业务上明明是同一个对象,技术上被拆成好几份。Agent要理解它,就得从多个系统里把这些碎片拼回来。
OceanBase的多模表想解决这个问题。一张表里可以同时放结构化字段、文本、图片、音频、视频、JSON、LOB、向量。比如一张合同表,可以同时包含:
合同编号
合同 PDF
合同正文
关键条款 JSON
摘要向量
风险标签
审批状态
权限信息
用户看到的还是一张表,但非结构化数据已经进入同一套事务、权限、元数据、版本和生命周期管理。企业AI不缺文件,缺的是能被统一治理、统一检索、统一计算的数据资产。
AI列也很有意思——它相当于让数据库内部长出一条语义加工线。原始数据进来之后,可以在库内生成摘要、标签、特征、向量等结果。对一张表中的多行数据做embedding或打标,AI列可以保证使用同一套算法,并且要么都成功,要么都失败。懂RAG的人应该明白这个细节的分量:向量化任务跑一半挂了,一半旧向量一半新向量,后面的召回质量会变得很玄学。数据库愿意认真处理这种一致性细节,说明它面对的是生产场景,不只是Demo场景。

混合搜索:别把数据库该干的活全丢给模型
现在做企业RAG,大家越来越清楚一件事:单纯向量检索很容易翻车——语义相似,不代表业务正确。一个生产级Agent查资料的时候,往往要同时满足很多条件:语义接近、关键词命中、结构化条件符合、权限范围正确、时间、部门、客户、状态一起参与过滤。
如果把所有候选都丢给大模型,让模型自己判断,成本高、速度慢、结果也容易飘。更好的分工应该是:数据库先做过滤、索引、权限、一致性和粗排,模型再处理真正高价值的候选。OceanBase对混合搜索的表达很准确:一条SQL组合执行,多路召回与粗排在引擎内统一完成,模型只处理高价值候选。关系过滤、全文搜索、向量搜索、图搜索组合在一起,先把全量数据缩成候选集,再交给模型精排。
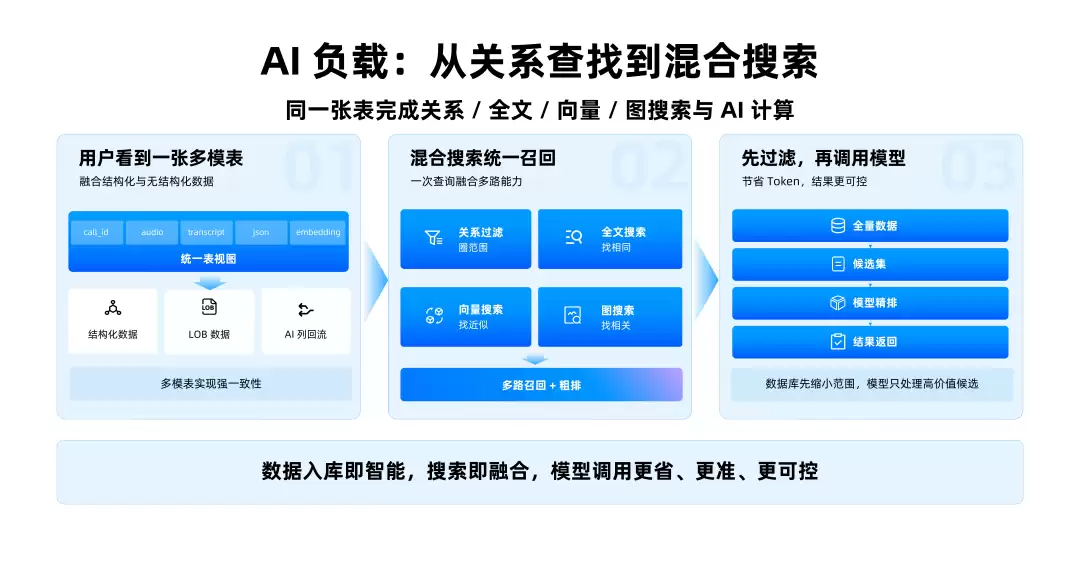
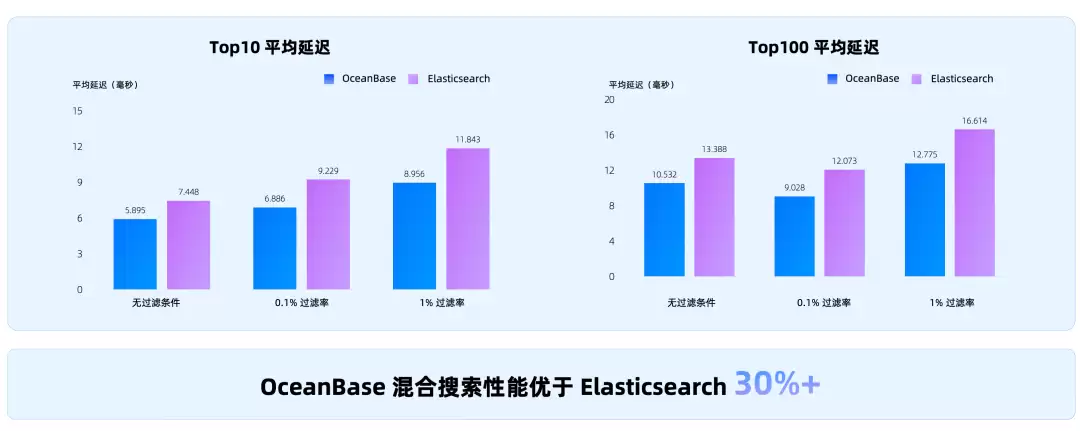
这件事并非为了炫技,解决的是企业AI里非常实际的问题:让上下文更准,让token更省,让权限更可控。在VectorDB Benchmark上,同等召回率下,OceanBase的向量性能领先于Milvus、PGVector、Elasticsearch。
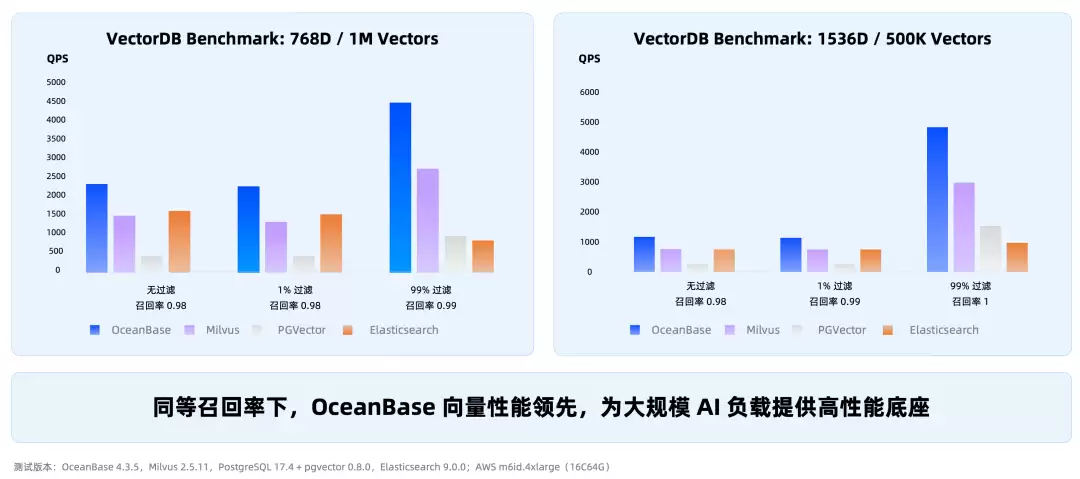
在MSMARCO数据集上,OceanBase混合搜索性能优于Elasticsearch 30%以上。
Agent友好:允许AI安全犯错
从实际落地经验来看,企业真正担心的点并不在于“Agent会不会干活”——它太敢干活,反而才是风险。人类工程师改库之前会备份、会评审、会问同事;Agent很可能一边推理一边执行,直接把环境改了。
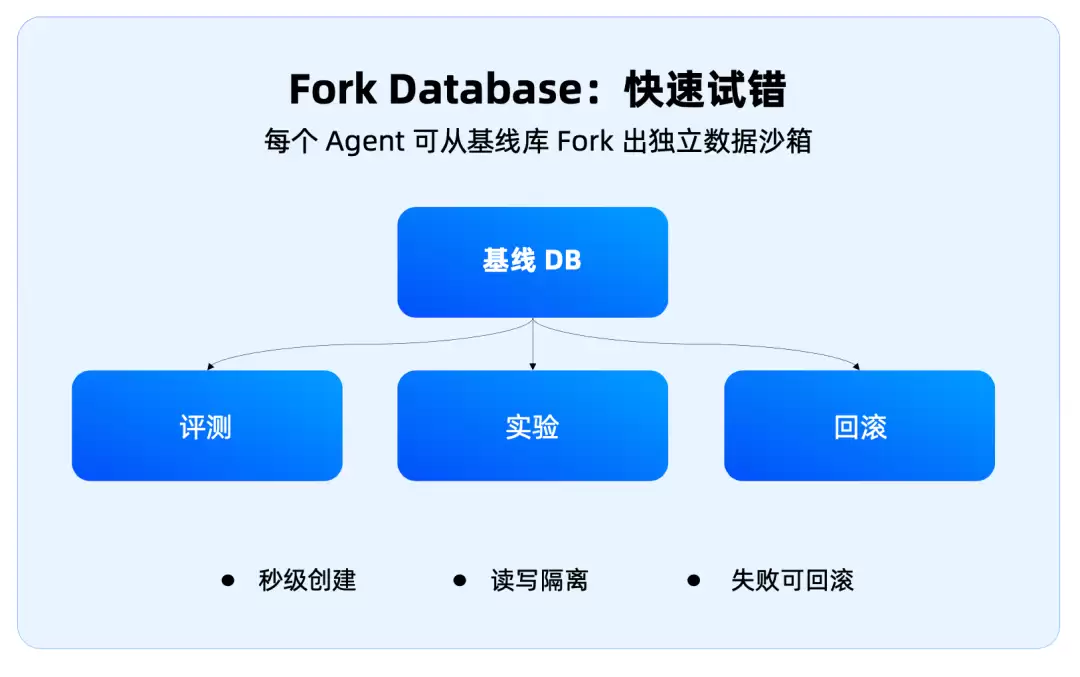
所以OceanBase这次提到的Fork Database、Copy-on-Write、Diff/Merge,非常关键。它本质上是把代码世界的分支工作流,搬进了数据库世界:Fork——给Agent开一个独立数据沙箱;Diff——看它到底改了什么;Merge——确认没问题再合并;Rollback——失败之后快速回到原状态。
比如蚂蚁阿福这个案例——服务上亿用户的AI健康应用,回答准不准至关重要。它要持续发现bad case、修复问题、重新评估,也就是一套生产级Agent评测工程。问题是,评测过程会改流程、改策略、改数据,这些动作不能污染线上生产数据。为了评测稳定,又要克隆线上数据,甚至还要复制Memory、RAG、行为数据。在AI coding加速之后,十几个feature分支以周为单位并行迭代,如果每个分支都完整复制一套环境,成本和管理复杂度都会很高。
OceanBase Branch的解法,是像代码分支一样创建数据库沙箱,它可以毫秒级创建,内部目标是5分钟拉齐一个评测环境,用完直接销毁。Agent改错了,就丢掉这个分支,重新从main拉一个出来。这才是生产级Agent需要的数据训练场。它的价值,就是把犯错的影响圈住。
Fork Database解决单个Agent的安全试错,而逻辑表解决海量Agent的低成本并行。

海量逻辑表:AI时代的海量,可能是小库太多

还有个案例很有意思:蚂蚁灵光短短几个月承载了3000多万个闪应用;妙思这类面向内部员工的平台,也上线了上万个应用。这些应用有一个共同点:平均每个应用表里也就百余行数据。这和过去我们理解的海量很不一样——以前说海量,往往是单库大、单表大、并发高。Agent时代还有一种新海量:
库很多,表很多,应用很多,但每个都很小,绝大部分时间还在睡觉
如果每个Agent、每个轻应用都建自己的物理表,schema会爆炸。OceanBase给出的能力叫逻辑表:每个Agent看起来有独立表和独立边界,底层通过逻辑隔离把大量表收敛到共享物理资源里。再配合共享资源池、按需唤醒、闲时资源归零,才能支撑海量Agent低成本并行运行。
这个设计非常务实。因为企业里未来不会只有一个超级Agent,更可能是客服、财务、销售、合规、采购、研发、运营,每个部门都有一堆小Agent、小应用、小流程。它们都需要边界,但企业不可能按每个小Agent一套完整数据库的成本去买单。
真实案例里,灵光为什么需要JSON Table
灵光这个案例也很能说明Agent时代的数据形态变化。它号称30秒手搓一个AI闪应用,但用户创建出来的应用schema完全不固定。一开始可以把数据全序列化成JSON,塞进KV大宽表。问题来了,SUM、SORT这些数据库算子基本用不上,只能把数据捞回业务层算,性能很差,多用户权限也难控。
另一种办法是每个闪应用建一张物理表,但几千万张小表会把数据库控制面和存储打爆。灵光的方案是OceanBase JSON Table:闪应用后端接SDK,用户照常写标准SQL,SDK自动转成JSON写入虚拟表。用户的SQL不用改,OceanBase侧继续提供索引、SUM、SORT等能力,存储成本也能降下来。如果某个闪应用真的火了,再把这部分JSON Table数据迁到物理表获得更好的性能。
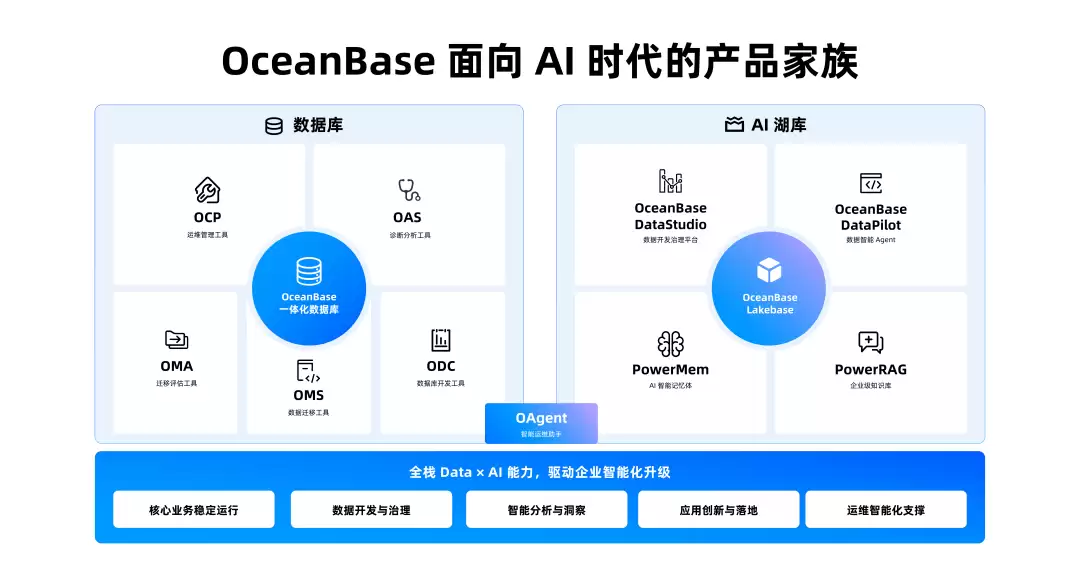
DataStudio、DataPilot、PowerMem、PowerRAG:产品家族开始成型
Lakebase是底座,但OceanBase这次发的是一整套产品组合。完整产品体系包括:
- :底层湖库一体和多模态数据核心引擎
Lakebase
- :面向数据开发、治理、服务发布和资产管理的工作台
DataStudio
- :面向业务人员的数据智能Agent
DataPilot
- :Agent记忆体
PowerMem
- :企业级知识库
PowerRAG
- :帮助Agent理解业务语义、指标口径和上下文图谱
OSI语义层
这套组合的方向很清晰:底层解决数据怎么存、怎么算、怎么搜;中间解决数据语义、治理、记忆和知识;上层解决业务人员怎么问数、取数、生成报告和看板。
DataPilot这一块,尤其适合拿给业务团队理解。业务人员不关心底层表结构,也不想等数据开发排期。他想问的是:本月经营指标为什么波动?用户增长下降的主要原因是什么?帮我生成一个销售分析报告?搭一个经营监控看板?DataPilot的关键远不止自然语言问数,它背后依赖业务对象、计算口径、指标定义、上下文图谱这些东西——也就是OceanBase OSI想解决的问题:让数据库从记录事实,往理解业务更进一步。
总结
把OceanBase这次发布看成一个信号:
企业AI的竞争,正在从模型调用层,下沉到数据基础设施层
很多企业前两年忙着选模型、买算力、做知识库,下一阶段真正拉开差距的,很可能是数据底座。谁的数据更完整,谁的上下文更准,谁的权限更稳,谁的多模态数据更容易被治理,谁的Agent更敢进生产流程——谁就更容易做出真正能落地的AI应用。

-
archiveofourown 实战指南:常见用法整理
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
电视剧《小欢喜》剧情介绍
-
俄罗斯最大yandex入口外贸日报直达链接
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
美好的简约网名男生(精选100个)
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
腾讯元宝怎么用来分析股票基金的基本面信息?
-
盖乐世社区怎么删除帖子?盖乐世社区个人发布内容撤回步骤
-
二次元男生网名可爱(精选100个)
-
问题:CIA币好不?Cia Protocol币今日上线:价格预测、代币经济学和未来潜力
-
wallpaper壁纸声音怎么开启
-
免费观看国外短视频的app有哪些 观看国外短视频的软件下载
-
国际贵金属走低,现货黄金价格跌0.49%
-
新浪人工智能热点小时报丨2026年06月20日02时_今日实时人工智能热点速递
-
独家/李宰旭入伍前「登上孤岛服役」 惊见前辈裸体:忍不住笑了
-
动漫《无赖勇者的鬼畜美学》剧情介绍
-
短剧《嫡女她是山大王》剧情介绍
-
AO3网址链接入口 教程:从入门到实际使用
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
1 AI智能访谈上线,让用户随时开口说真话 07-04
-
2 我们是AI训练师:一堂轻设备的AI启蒙课 07-04
-
3 百度商家智能体焕新升级,打造专属AI销售团队 07-04
-
4 AI知识管理 | 从文档管理员到知识工程师:岗位说明与能力模型 07-04
-
5 微软、字节、福特都在高薪招人 AI又衍生了一个新岗位 07-04
-
6 AI企业画的饼,正在反噬自己 07-04
-
7 跃迁维度 - 一站式国产 AI 模型 API 聚合平台 07-04
-
9 ChatGPT 用户突破 10 亿,女性用户占比首次超过 50% 07-04



