大模型转行土木工程,首个「打灰人」评估基准:检验读、改工程图纸能力
来源:互联网 更新时间:2026-06-23 07:15
AI竞赛白热化的当下,大语言模型早就不是只会关起门来刷题背书的“学霸”了。
GPT-4o能拿下物理奥赛题,DeepSeek能熟练搭个网站……但这些号称“专家级”的大模型,真能下工地干活吗?在钢筋水泥的图纸世界里,它们到底是得力助手,还是纸上谈兵?
答案还没揭晓,但有人已经迈出了评测的第一步。
加拿大麦吉尔大学AIS实验室联合加州大学圣芭芭拉分校(UCSB),正式推出了面向工程自动化任务的大模型评估基准——
DrafterBench

论文链接:https://arxiv.org/abs/2507.11527
代码链接:https://github.com/Eason-Li-AIS/DrafterBench
数据链接:https://huggingface.co/datasets/Eason666/DrafterBench
为什么需要DrafterBench?
工程图纸修改,在土木工程、建筑设计领域,是最耗时间、最高频的苦差事,也是自动化改造呼声最高的环节。每天成千上万的工程师和制图员,都在反复处理“把这根梁挪一下”、“把这根管道直径加粗几毫米”、“给这个构件补个标注”——琐碎,但责任重大。
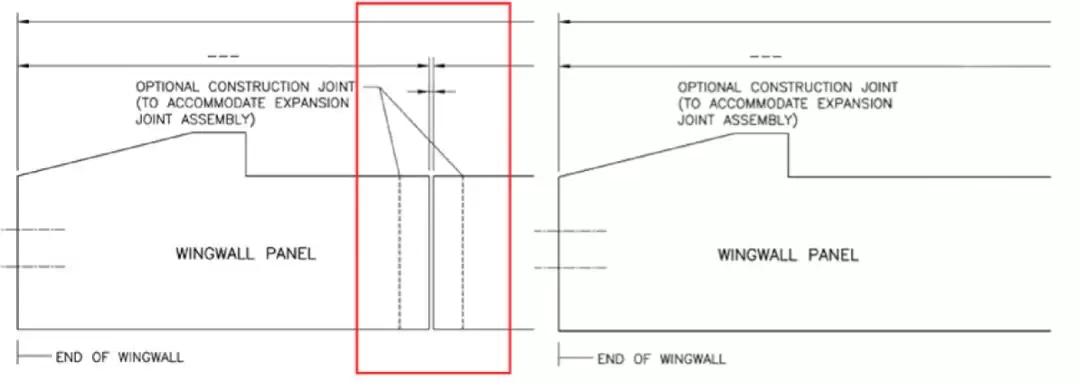
这类工作量大、标准高、容错低,技术门槛倒不算太高,但对执行力的要求极强——你得看懂指令、把控细节、还得把多个步骤串起来干。于是团队抛出一个问题:如果大模型能读懂图纸指令、调用工具链、精确修改图元,那它就不只是“写PPT的好手”,而是实打实的“工程打工人福音”。
DrafterBench怎么做的?
DrafterBench的核心任务是图纸修改。它在20个真实项目中收集并设计了1920个高质量任务,涵盖12类指令类型,模拟了各种难度和风格的真实工程命令。
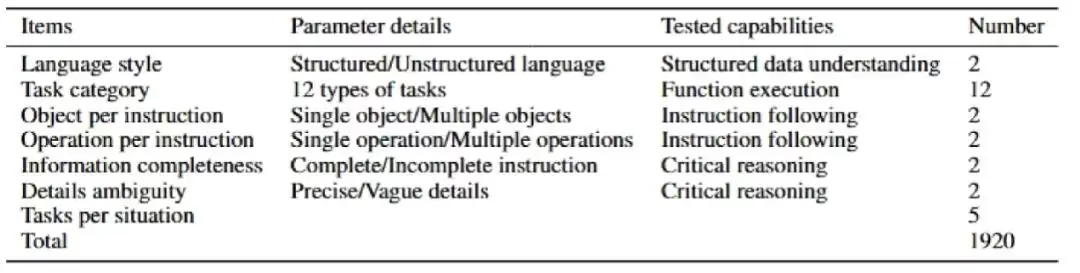
它不要求模型“按部就班”,而是全面考察四大能力维度:
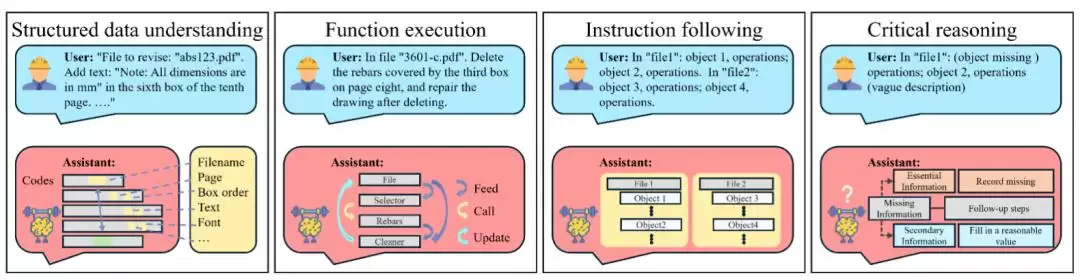
结构化数据理解能力
工具调用能力
指令跟随能力
批判性推理能力
这不是纸上作文,是工程实战。
DrafterBench如何评估模型?
在DrafterBench中,模型必须用“代码调用工具”的方式完成任务。这些工具涵盖图元编辑、标注调整、绘图逻辑等,彼此间有输入输出依赖,环环相扣,构成一条“工程任务链”。
问题来了:工具调用对不对?组合合理吗?中间步骤有没有成功传递?有没有出现冗余或错误命令?
直接看图纸输出,根本判断不了。于是DrafterBench设计了一套
对偶工具系统
换句话说,它不只看模型有没有答对,更看它
为什么答错、哪一步出错、错在哪里
模型表现如何?喜忧参半。
团队评测了主流SOTA大模型:OpenAI GPT-4o / o1系列、Claude 3.5 Sonnet、Deepseek-V3-685B、Qwen2.5-72B-Instruct、LLaMA3-70B-Instruct。
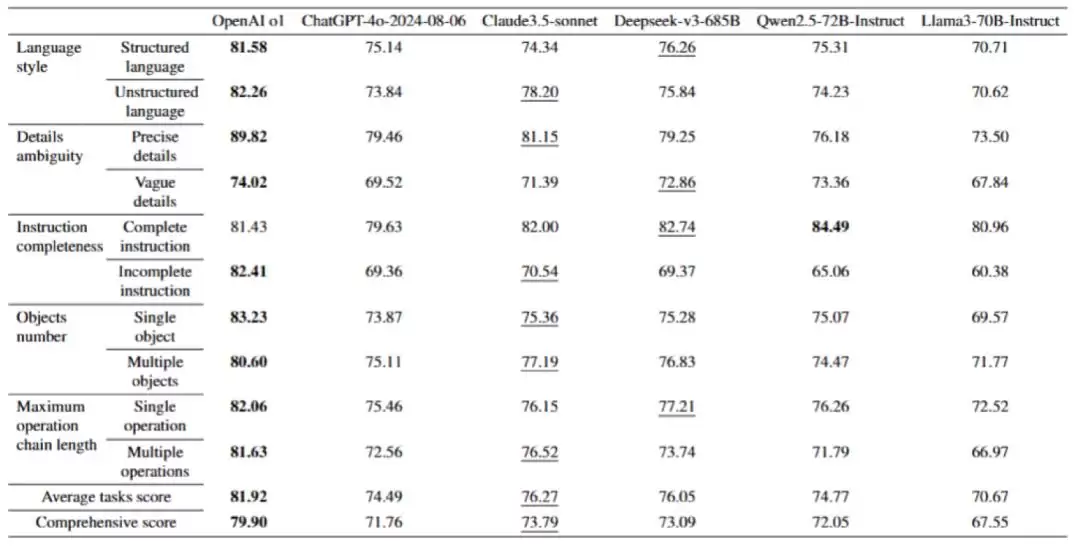
综合来看,这些模型得分普遍超过65分,说明它们确实具备一定的工程任务处理能力,尤其在简单指令执行上表现稳定。其中OpenAI o1以79.9分领跑,Claude 3.5 Sonnet(73.79)和Deepseek-V3-685B(73.09)紧随其后。
但整体水平还远未达到工业一线对执行精度和流程完整性的要求。更值得注意的是,不同模型在四大能力维度上差异显著。
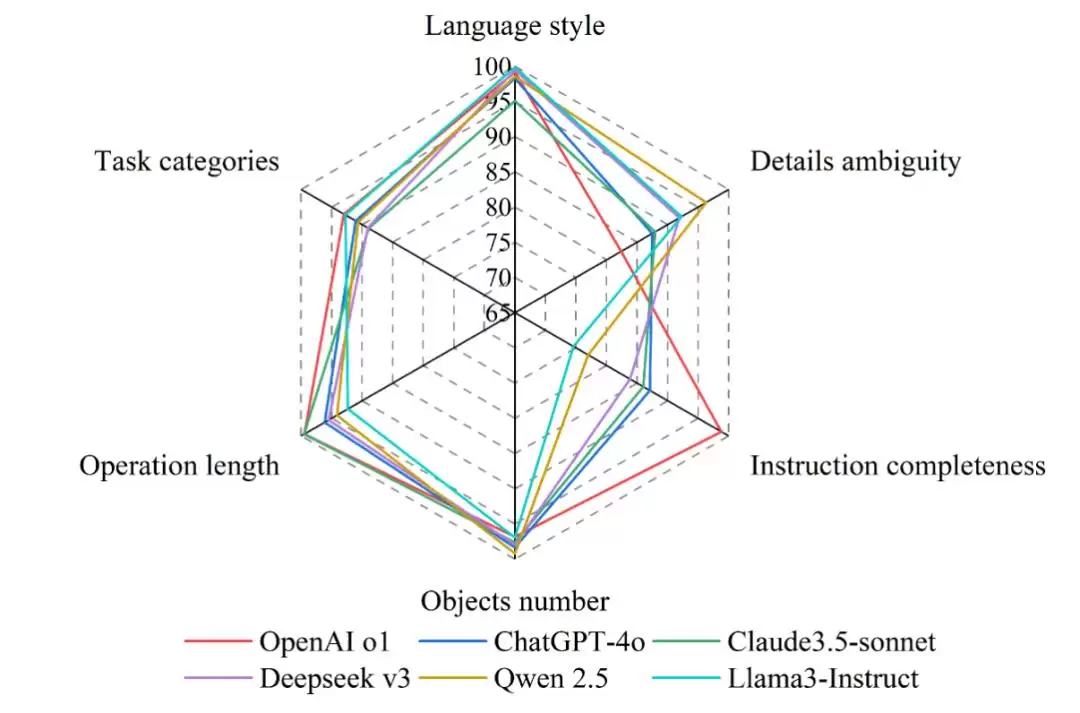
比如在结构化数据理解任务中,模型整体表现稳定,对语言风格的鲁棒性较强。但在工具调用方面,准确率波动明显,平均差距可达9个百分点。指令跟随能力上,OpenAI o1和Claude 3.5 Sonnet抗噪声能力较好,能保持基本的任务完整性;而在批判性推理任务中,模型间能力分化尤为突出——OpenAI o1擅长识别信息缺失、筛选关键信息,Qwen2.5则更擅长细节补充,其余模型波动较大。
研究团队还用了自动化错误分析工具,对每个任务的失败原因进行了结构化溯源。结果发现:常见错误包括参数定义不清、变量传递失败、函数调用结构错乱、工具选择偏差以及多工具组合逻辑混乱。更关键的是,即便多个步骤都执行正确,只要某一关键环节出问题,最终图纸修改就会失败。这解释了为什么多数模型的单项能力准确率能维持在60%左右,但整体目标修改完成度却只有40%上下。
结论与展望
这些评估结果说明:当前大模型已经具备一定能力去拆解复杂任务结构、调用工程工具,但还远不能稳健地掌控完整任务链的所有细节,对实际场景的适应能力还撑不起工程一线的需求。
如果说过去的大模型评测多数停留在“会不会”,那么DrafterBench的贡献在于首次让模型接受了“干不干得好”的落地考核。工程现场需要的是高容错、强判断、懂规则、能执行的助手,而DrafterBench正是在为这个目标提供数据支持和路径验证。
接下来,研究团队计划把任务类型扩展到图纸校审、规范检测、施工日志智能生成等更多工程应用场景,持续拓展模型能力边界。
你有模型,DrafterBench有任务。看看你的模型,能不能真在图纸上动真格。

-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
帅气继父网名女生可爱英文(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
蒙古上单是什么梗
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
韦一敏是什么梗
-
韩漫小少爷网名大全女生(精选100个)
-
archiveofourown 实战指南:常见用法整理
-
网络热词聊污是什么意思
-
抖音最火沙雕男生网名(精选100个)
-
有寓意的易经网名男生(精选100个)
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
小众游戏抖音网名男生(精选100个)
-
2 王兴兴抢跑 “具身智能” 红利,宇树产业链能否啖头汤? 06-23
-
4 豆包的野心已经浮出水面 06-23
-
5 特朗普嫌AI名字太土,建议改名 06-23
-
6 Anthropic最新研究:在被对齐前,模型已经会说谎了 06-23
-
7 “保守1000亿”,这个赛道正在批量制造90后富豪 06-23
-
8 炉边对话 | 施密特与沈向洋议AI:靠竞争谋发展,靠合作守底线 06-23
-
9 不管你来不来32°C的上海逛WAIC,都需要这份探展指南 06-23
-
10 AI 编码的探索与思考 06-23



