解锁数据新动能:从统一数据治理迈向企业级Data Agent
来源:互联网 更新时间:2026-06-22 17:25
先说一个基本判断:在AI的世界里,数据就是那个最底层的驱动力。没有数据,AI就像没有燃料的引擎,再先进的技术也运转不起来。而随着AI技术的全面渗透,企业对数据的需求已经进入了“饥渴”状态——这不是为了存而存,而是为了用,为了训练出更聪明、更精准的模型。
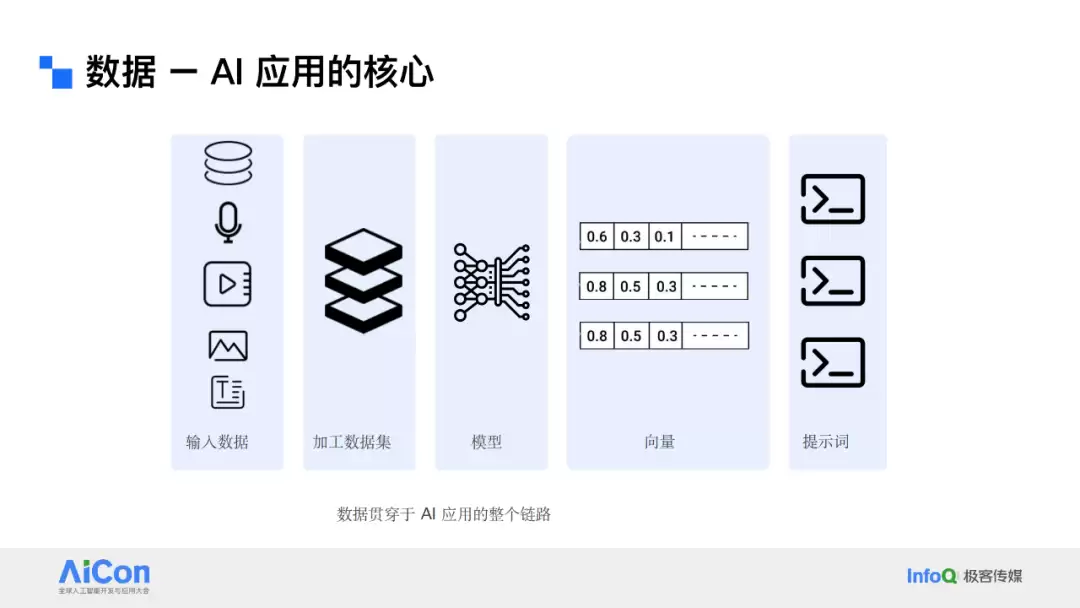
从输入数据、加工成数据集,到模型训练、生成向量、喂给提示词,数据贯穿了AI应用的全链路。拿图像识别来说,想让AI准确认出图像中的物体,你得给它看足够多的样本——不同角度、不同光照、不同背景。海量且高质量的数据,是训练出强大模型的“燃料”。自然语言处理也是一样的道理,语料库的质量直接决定了模型是“能说会道”还是“词不达意”。
但这里有一个核心问题:数据不是越多越好,关键在质量。AI领域有句老话叫“垃圾进,垃圾出”(Garbage in, garbage out)。数据如果存在错误、缺失或者不一致,AI的输出就会偏差,甚至全盘皆错。所以,数据治理在AI时代已经不是“锦上添花”,而是“绕不开的必修课”。
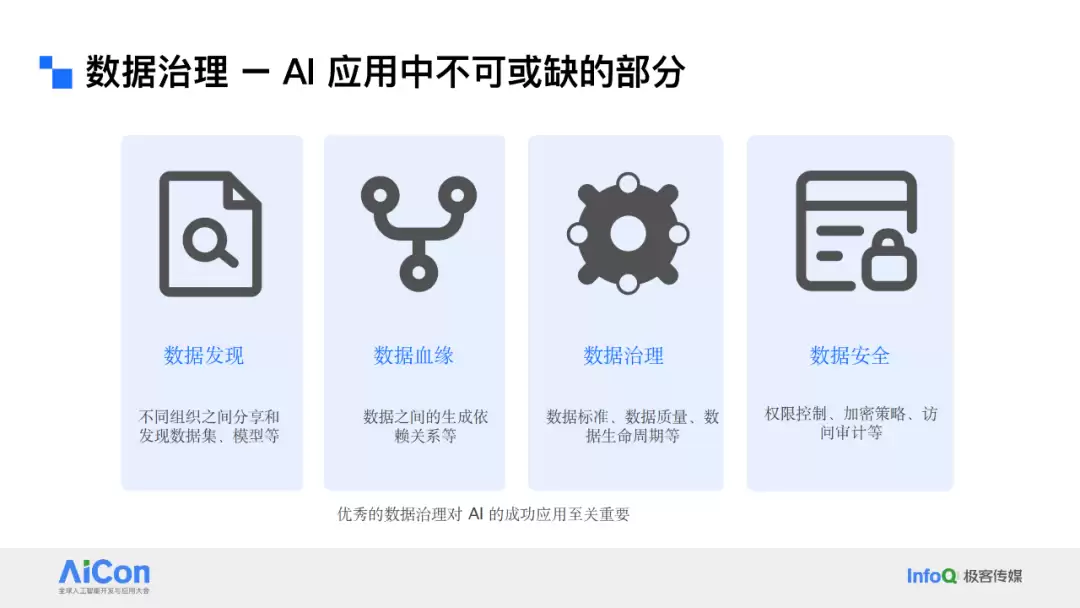
数据治理涵盖的东西很多:数据发现、数据血缘、数据标准、数据质量、数据生命周期管理,还有数据安全。比如,数据发现解决的是“我们有哪些数据、在哪里、能用吗”;数据血缘追踪数据的来龙去脉;数据标准和数据质量确保数据的一致、准确和完整;生命周期管理帮你想清楚数据什么时候该存、什么时候该删;安全治理则通过权限控制、加密和审计来防止泄露和滥用。这些维度环环相扣,缺一不可。
01 — 传统困境:治理挑战重重
尽管数据对AI如此关键,但现实是——大多数企业数据管理系统中,传统技术正被各种困境压得喘不过气。
数据被锁定在不同的数据源中,就像一座座孤岛。
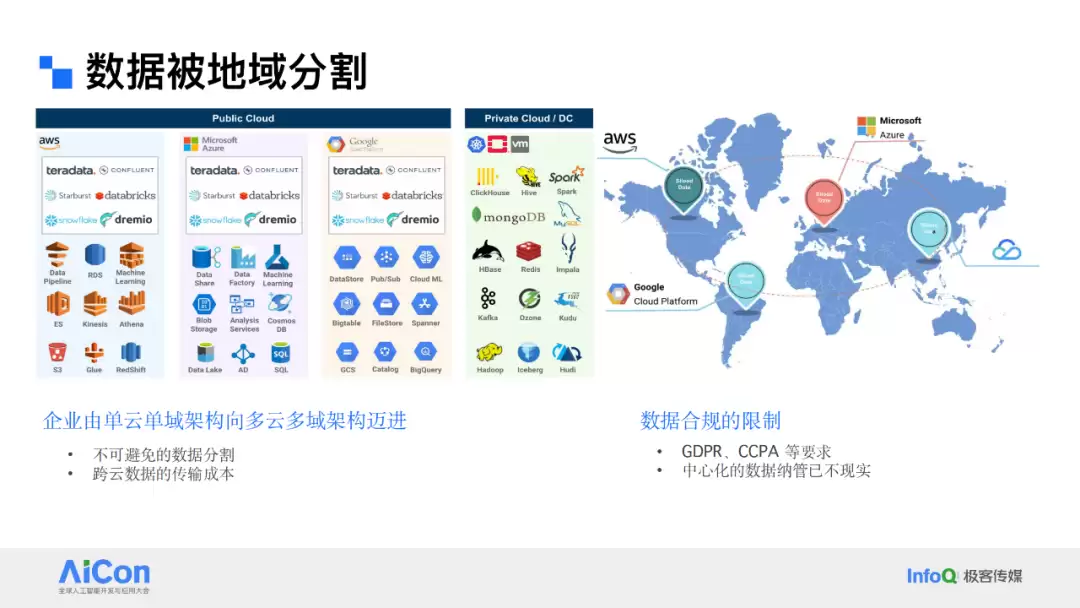
数据被地域分割的问题也日益突出。
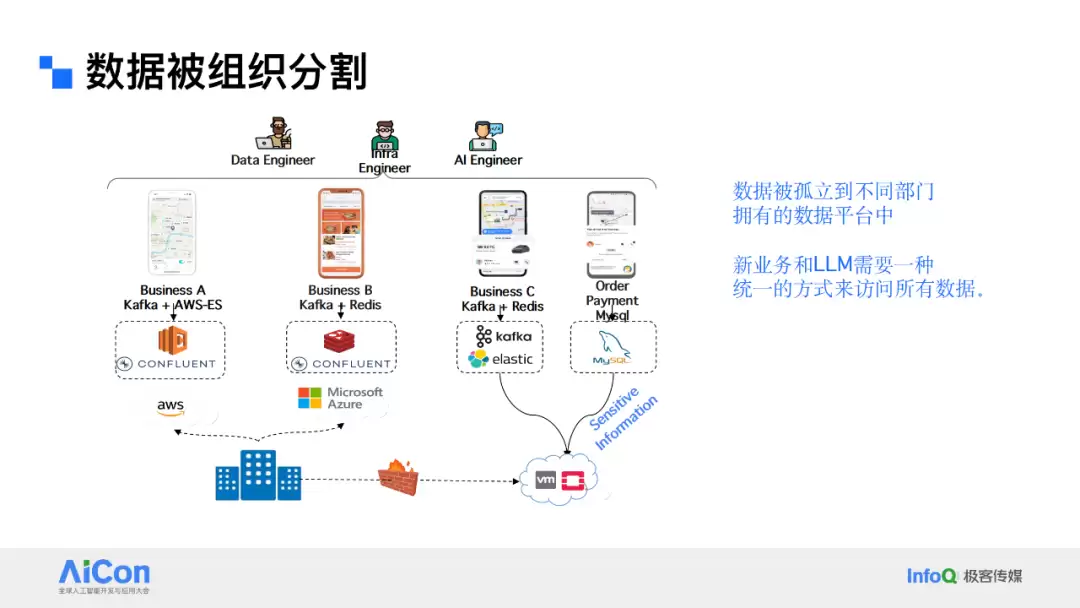
数据还被组织分割。
数据连接、数据主权、数据分类、元数据语义、生命周期管理……这些问题纠缠在一起,让数据管理变得极其复杂。带来的后果很直接:决策信息不完整、基础设施重复建设、数据不一致甚至泄露风险、内部数据流通不畅。说白了,就是“数据资产”没发挥出该有的价值。



统一破局,治理价值凸显
面对重重困境,统一数据治理站了出来。它的核心思路是构建一个统一的管控面,打破数据孤岛,释放数据价值。
全方位管理,构建统一架构。
Apache Gra vitino:统一的核心力量。
在数据访问上,Gra vitino针对表格数据和非表格数据分别提供统一API。举个例子,一家媒体公司既有结构化的用户订阅数据(存在表格里),又有大量非结构化的视频和图片素材。通过Gra vitino,数据分析师可以方便地查询订阅数据,视频编辑也可以快速获取素材,工作效率大幅提升。权限管控方面,它通过统一访问控制API和授权API,结合IAM Plugin和Apache Ranger,实现了精细化的权限控制——企业内部部门或外部合作伙伴,都能按权限安全访问数据。
02 — 创新进阶:RAG与Data Agent登场
在统一数据治理打下基础之后,技术创新的脚步没有停下。企业级RAG和Data Agent作为新兴力量,正逐渐登上舞台,给数据管理和分析带来更智能、更高效的可能性。
RAG:传统与现代的融合
RAG,全称检索增强生成(Retrieval-Augmented Generation),本质上是一个将传统信息检索与生成式大语言模型结合起来的人工智能框架。它的出现,是为了弥补大模型在处理自然语言时的知识局限性和准确性短板——模型不能只靠训练时学到的知识,遇到没见过的问题就瞎编。RAG通过引入检索机制,从外部知识库或企业内部数据中先检索相关信息,再结合生成模型输出更准确、更符合上下文的答案。
RAG也有不同进化形态。Basic RAG基于向量检索,实现简单,但信息来源有限,缺少对查询和结果的校验。适合简单的文档检索场景,但面对复杂问题就力不从心了。Advanced RAG则做了升级:结合关键字和语义检索,并在检索前后做预处理。比如,检索前分析并改写用户问题,检索后对结果进行重排序和内容总结,这样回答的质量和准确性就高多了,适合智能客服、智能问答等场景。而Multi-modular RAG则更进了一步:它有一个决策引擎,根据问题类型和用户需求,在不同的数据源/知识库之间选择最合适的,并在不同的检索方式间切换。意图理解更准、知识更丰富、准确度更高。处理一个跨多领域的复杂业务问题时,它可以同时从业务数据库、行业报告库、专家知识库找信息,然后选出最佳检索和生成方式,给出全面深入的解答。
企业级Multi-modular RAG系统构建
构建企业级Multi-modular RAG系统,听上去就有点复杂。传统的做法是:为每种数据源开发不同的连接器/读取器,获取描述信息、做自然语言到SQL的转换、查询数据、再喂给大模型。在有关系型数据库、文档数据库、向量数据库等多种数据源的环境里,这个方案问题不少:配置复杂、开发效率低、不同连接器难以复用、维护成本高、安全管理困难。说白了,就是费力不讨好。
更好的思路是用统一元数据平台来管理各类数据。通过它,企业可以获取数据内容描述、结构、访问方式等信息,由大模型生成查询指令,统一进行查询、结果返回、模型传递等操作。优势很明显:适配简单、开发效率高;统一数据访问和权限管控,安全又一致;易于扩展——新数据源或新需求来了,只需在统一元数据平台配置扩展,不用动每个连接器。灵活性、可扩展性都上了一个台阶。
03 — 案例说明
某先进制造企业:Data+AI一体化变革
在Data+AI一体化的实践中,这家制造企业面临的挑战很有代表性。数字化转型深入后,海量非结构化数据(设计图纸、生产日志、设备监控视频)不断涌现,怎么把这些数据“资产化”是一大难题。还要实现Data AI一体化,把数据开发和AI开发流程打通,让DataOps/MLOps/LLMOps协同工作。这不仅需要技术革新,还要优化组织架构和业务流程。在支持业务场景上,它要对接各种机器学习框架,无论是传统算法还是大模型预训练/微调,都需要稳定高效的数据支撑。
该企业最终选择了基于Gra vitino的新一代数据管理方案。数据开发方面,构建了数据开发平台和数据工场,集成Flink、Spark、Trino等多种计算引擎;数据消费环节,BI平台和数鲸提供了直观的分析工具;数据管理和治理方面,治理平台DAC和统一元数据元仓发挥作用,确保安全合规。存储引擎方面,采用了Hive、Iceberg、Doris、ES、Talos、RMQ、MySQL、TiDB等多种技术,满足不同数据类型的存储需求。
存量数据纳管上,企业将存量数据挂载至External Fileset,并支持设置TTL(生存时间)与TTV(有效时间)。这样实现了上下游迁移解耦,不强制迁移,还能支持多种存储类型。在Data+AI一体化开发中,Gra vitino让数据处理和AI流程无缝衔接:数据集成后,通过Notebook和OLAP进行加工分析,然后写入Fileset,供AI团队训练和使用。在统一AI资产管理上,Gra vitino实现了数据血缘、健康度、使用记录、权限详情等全面管理,做到AI资产可追溯、可管理、可优化。
结果很亮眼。业务案例①中,某业务纳管存量数据后大幅降本——通过识别血缘推荐TTL、TTV,冷备和清理无用数据,降本达到40%。业务案例②中,推荐工作流得到简化:基于统一元数据打通流程,数据加工直接产生Fileset,特征分析和训练效率都提升了。业务案例③中,LLM微调工作流得以优化,未来将实现在线加工微调数据和自动化模型测试,准确性和可靠性进一步提升。
某互联网社交平台:元数据管理优化
这家社交平台的痛点也很典型。业务侧耦合度高,元数据使用方调用异构数据源的方式五花八门,维护十分复杂。数据治理能力有限,缺乏统一审计、权限管理、TTL能力,在安全和合规上风险较大。半结构化/非结构化数据源(评论、图片、视频)缺乏管理,跨源数据Schema维护成本高。随着业务发展,这些挑战越来越大。
平台的解题思路是引入OneMeta统一元数据管理服务。它集成了Gra vitino,并提供定制化接口(如dropPartitionsByFilter、loadFileDetail、loadFiles等),满足复杂业务场景需求。定制化catalog实现(如BiliIcebergCatalog、BiliKafkaCatalog等),降低了代码侵入性,便于同步社区最新代码。通过OneMeta,平台解耦了业务方的复杂依赖,降低了元数据使用成本,解决了引擎间差异、数据源差异导致的元数据不一致问题,也解决了Hive MetaStore的性能瓶颈。
基于Gra vitino Fileset的文件治理效果显著。平台通过数据治理平台制定策略,经OneMeta对Fileset进行TTL和EC打标,SDM读取tag后向HDFS服务器发送指令,再根据看板优化治理策略。最终HDFS EC减少了超过100PB+的存储成本,HDFS TTL减少了超过300PB+的存储成本。通过有效的Fileset管理,数据利用效率提高了,存储成本降下来了,治理水平也上了新台阶。
回到起点:在AI时代,通过OneMeta这样的统一元数据管理服务,企业能够实现对数据湖仓的安全、快速访问,而且对原有业务系统的侵入性很低。本文选择Gra vitino来实现结构化、非结构化数据的元数据管理,当然,其他具备相同功能的组件也可以达到类似效果。这个案例的意义在于提供了一条AI Agent访问湖仓数据的实用思路。希望对正在探索这一方向的团队有所启发。

-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
帅气继父网名女生可爱英文(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
蒙古上单是什么梗
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
韦一敏是什么梗
-
韩漫小少爷网名大全女生(精选100个)
-
网络热词聊污是什么意思
-
archiveofourown 实战指南:常见用法整理
-
有寓意的易经网名男生(精选100个)
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
抖音最火沙雕男生网名(精选100个)
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
小众游戏抖音网名男生(精选100个)
-
1 用腾讯ima对微信读书书架分类,还是DeepSeek懂我 06-22
-
2 Cline 浪费 token?记忆库助你提质增效,成本骤减! 06-22
-
5 Cline 3.8.0:工作流集成、账户管理与供应商优化 06-22
-
6 核对2个表格,Deepseek才是YYDS,看我30秒搞定! 06-22
-
7 阿福号召“科学减重1亿斤”,专家:减重难在坚持,AI能搭把手 06-22
-
8 美国新提案:「国有化」AI巨头,「全民持股」50% 06-22
-
9 谷歌强推 AI 搜索引发用户不满 功能异常反向为竞品引流 06-22
-
10 当 5 亿人放弃 ChatGPT 06-22



