沐曦股份曦云C系列GPU产品Day 0适配智谱GLM-5.2旗舰模型
来源:互联网 更新时间:2026-06-18 13:59
6月17日,智谱AI正式开源发布了全新旗舰大模型GLM-5.2。而这次,沐曦股份的曦云C系列GPU几乎是同步完成了Day 0适配——也就是说,模型一发布,算力准备就已经到位。这背后靠的是全栈自主软硬件技术,也让沐曦在国产GPU生态适配这条赛道上,又稳稳踩实了一步。
GLM-5.2,这次可以说是智谱迄今为止能力最强的开源模型。它支持真正可用的1M上下文,在长程任务上依然保持着领先位置。说实话,这个“1M上下文”能落地,本身就是个硬功夫。
说起来,沐曦和智谱的合作已经不是第一次了。从GLM-5、GLM-5.1、GLM-OCR到GLM-4.6V,智谱全系列模型,沐曦都做到了Day 0同步适配。而这次对GLM-5.2的支持,凭借的是曦云C系列本身的硬件算力和MXMACA软件栈的深度优化。这套方案主打的就是全场景、高稳定、低成本——说白了,就是要解决大模型落地时那三个老大难问题:“适配慢、迁移难、性能损耗大”。帮企业尽快把GLM-5.2的技术红利变成真金白银的产业价值。
自2025年12月以来,沐曦已经累计完成了27款主流顶尖模型的Day 0适配,合作名单涵盖了智谱AI、通义千问、阶跃星辰、百度飞桨、DeepSeek等头部厂商。适配的模型类型从通用语言到多模态、OCR、机器翻译,覆盖面相当广。无论从适配速度、数量,还是生态广度来看,沐曦都处在一个比较靠前的位置。这次GLM-5.2的无缝接入,无疑会进一步拉动“模型-芯片-框架-应用”这条全国产AI自主闭环的落地节奏。
曦云C系列GPU采用的是沐曦全自研的核心GPU IP、指令集和架构,能效比高、通用性强,天然适合处理大模型的超大参数规模和长上下文推理。而MXMACA软件栈的作用,更像是连接硬件算力和上层应用的那座“桥”——从底层驱动、用户态接口、MXCC编译器,到算子的深度适配,再到主流训练/推理框架的对接,全链路覆盖。它原生兼容PyTorch、TensorFlow、vLLM、SGLang等40多种主流AI框架,已经跑通了500多个AI模型和4500多个热门开源项目。这样一来,传统模型适配周期被大幅压缩,曦云C系列也就顺理成章地为GLM-5.2的前沿能力提供了稳定的算力底座。
 这次GLM-5.2是专门冲着长程任务能力来的。它的几个新特点值得关注:
- 扎实的1M上下文,能稳定支撑长程任务
- 更强体感、更实用的Coding能力
- 极致的Infra优化,做到了Day 0在国产算力平台上跑通
- MIT开源协议,无地域限制,技术平权
这次GLM-5.2是专门冲着长程任务能力来的。它的几个新特点值得关注:
- 扎实的1M上下文,能稳定支撑长程任务
- 更强体感、更实用的Coding能力
- 极致的Infra优化,做到了Day 0在国产算力平台上跑通
- MIT开源协议,无地域限制,技术平权
 实际体验更直观。GLM-5.2可以自主完成从开发、联调、测试到打包上线的整个流程,最后交付一个覆盖Web、移动端和小程序的多端应用。整个过程累计处理了88万以上的tokens,几乎用满了1M上下文窗口。过去这种级别的工程,一支团队要协作好几周,现在GLM-5.2在一次连续的长程任务里就能跑完。
实际体验更直观。GLM-5.2可以自主完成从开发、联调、测试到打包上线的整个流程,最后交付一个覆盖Web、移动端和小程序的多端应用。整个过程累计处理了88万以上的tokens,几乎用满了1M上下文窗口。过去这种级别的工程,一支团队要协作好几周,现在GLM-5.2在一次连续的长程任务里就能跑完。
 GLM-5.2还引入了effort level,也就是“思考档位”控制。开发者可以根据需要,在能力、速度、成本之间灵活平衡。在相近的token预算下,GLM-5.2的Coding能力大致落在Claude Opus 4.7和Claude Opus 4.8之间。
GLM-5.2还引入了effort level,也就是“思考档位”控制。开发者可以根据需要,在能力、速度、成本之间灵活平衡。在相近的token预算下,GLM-5.2的Coding能力大致落在Claude Opus 4.7和Claude Opus 4.8之间。

关于智谱GLM-5.2
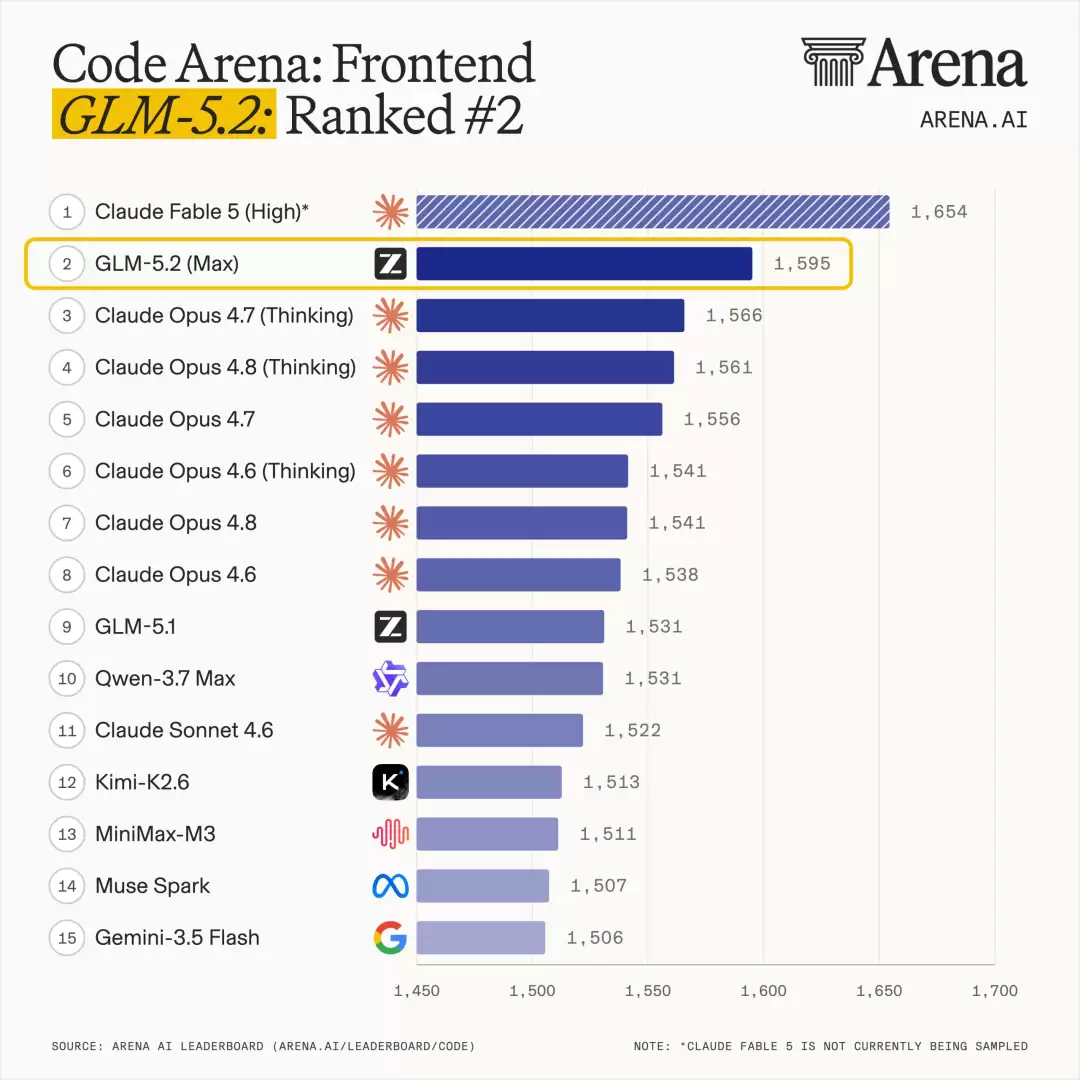
聊几个关键的数据点。在全球百万用户参与盲测的前端开发评估系统Code Arena上,GLM-5.2拿下了全球可用模型第一的成绩。
这次GLM-5.2是专门冲着长程任务能力来的。它的几个新特点值得关注:
- 扎实的1M上下文,能稳定支撑长程任务
- 更强体感、更实用的Coding能力
- 极致的Infra优化,做到了Day 0在国产算力平台上跑通
- MIT开源协议,无地域限制,技术平权
1M上下文与长程任务
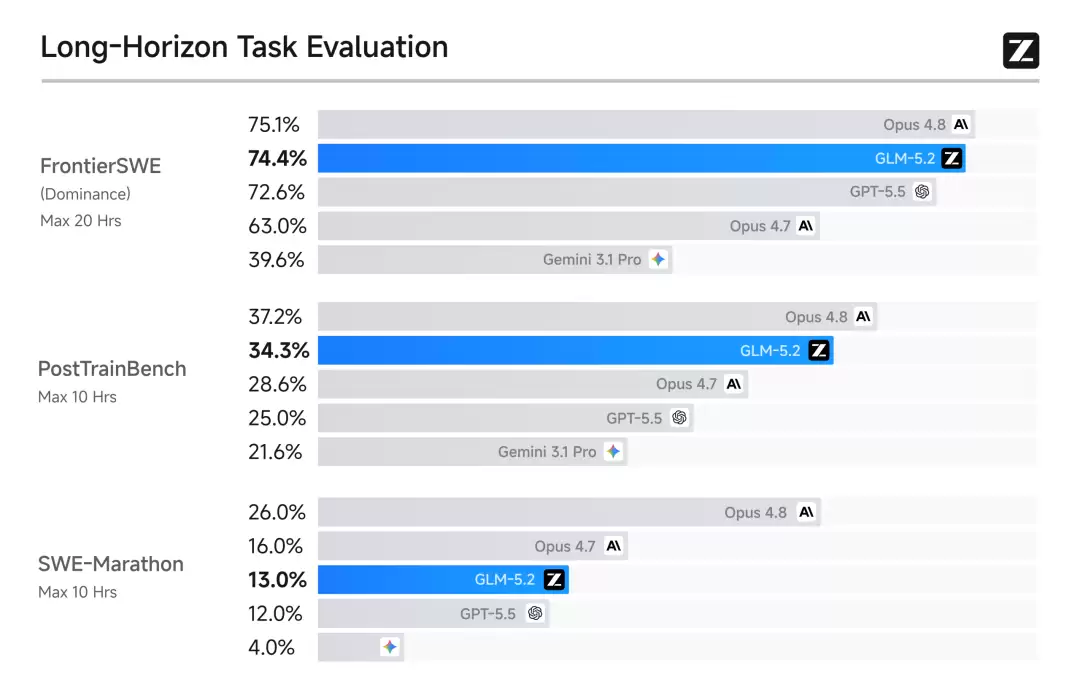
GLM-5.2这次把1M Coding Agent的训练环境狠狠拓宽了,覆盖了大规模实现、自动化研究、性能优化等多个典型领域。在一些场景下,它1M上下文的真实表现甚至能超过Opus。这个1M上下文构成了GLM-5.2的长程交付能力——在FrontierSWE、SWE-Marathon、PostTrainBench等多个长程任务基准上,它的表现介于Claude Opus 4.7与4.8之间,是开源模型里排名最高的。
实际体验更直观。GLM-5.2可以自主完成从开发、联调、测试到打包上线的整个流程,最后交付一个覆盖Web、移动端和小程序的多端应用。整个过程累计处理了88万以上的tokens,几乎用满了1M上下文窗口。过去这种级别的工程,一支团队要协作好几周,现在GLM-5.2在一次连续的长程任务里就能跑完。
Coding体感
在Coding这块,GLM-5.2在前端、后端、长程任务等场景下的成功率,相比上一代GLM-5.1有了明显提升。复杂系统工程和深度调试也更加稳定。在主流编程基准上,GLM-5.2仍然保持开源SOTA,跟Claude Opus 4.8处在可比区间。举个例子,在Terminal-Bench 2.1上(评测AI Agent通过命令行操作计算机的数据集),GLM-5.2比Opus 4.8低4%,但比GLM-5.1提升了17.5%;在MCP-Atlas上(工具使用评测数据集),它只比Opus 4.8低0.8%。
GLM-5.2还引入了effort level,也就是“思考档位”控制。开发者可以根据需要,在能力、速度、成本之间灵活平衡。在相近的token预算下,GLM-5.2的Coding能力大致落在Claude Opus 4.7和Claude Opus 4.8之间。
极致Infra优化
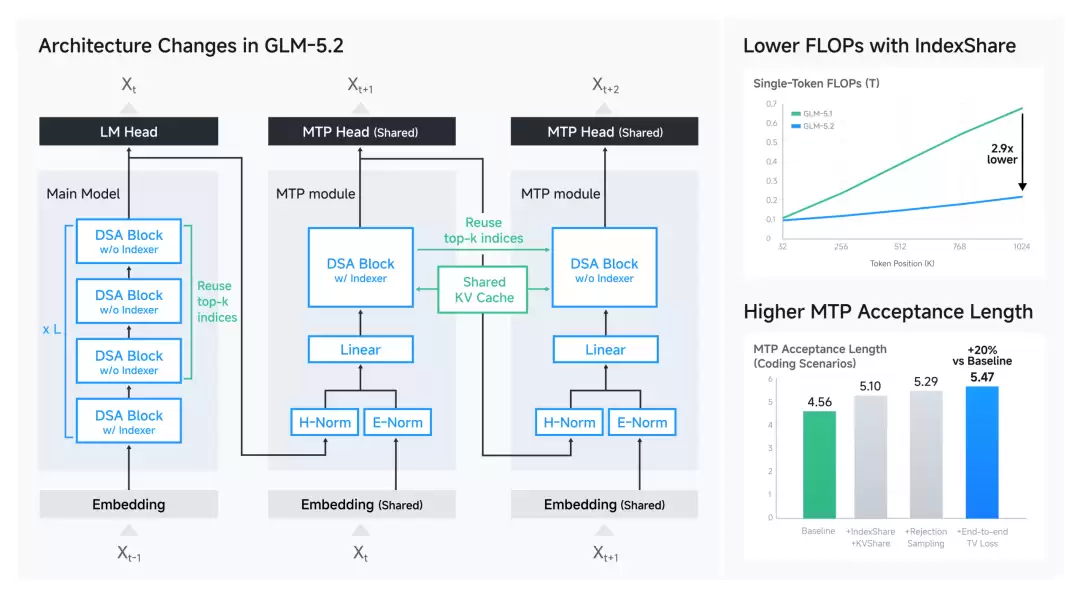
GLM-5.2的进步,并不仅仅是模型本身的升级,更是模型架构、推理系统和训练基础设施协同设计的结果。智谱团队提出了IndexShare方案——在每四层稀疏注意力层之间复用同一个索引器(indexer),在1M上下文长度下,把单位token的FLOPs降到了2.9倍。同时,他们还改进了MTP层(用于投机解码),让接受长度(acceptance length)最多提升了20%。训练侧则依赖自研的Slime框架来支撑大规模Agentic RL和OPD训练。
面向开发者与知识工作者
凭借着扎实的1M上下文和稳定的长程任务能力,GLM-5.2可以长时间自主推进更复杂、更长链路的任务,锁定高价值场景。它正在改变开发者和知识工作者的工作方式。 比如在大型重构工程上,GLM-5.2表现就很亮眼。在开发者的Moonshot实验中,它用Rust从零再造了送人类登月的计算机——阿波罗11号制导计算机(AGC):先把约4600行的定点CPU逐比特移植为Rust,再让当年65000行、一字未改的登月飞控程序在上面原样起飞。整个过程由Agent全自主走完,甚至连那个差点中止登月的1202报警都复现了出来。 通过智谱的Agent产品AutoClaw,GLM-5.2的1M上下文与长程任务能力还可以服务于设计、法务等专业场景。比如从需求一次性生成数十个原型页面,然后自主持续迭代和微调,在长上下文中保持品牌规范与一致性。-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
帅气继父网名女生可爱英文(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
蒙古上单是什么梗
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
韦一敏是什么梗
-
韩漫小少爷网名大全女生(精选100个)
-
网络热词聊污是什么意思
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
抖音最火沙雕男生网名(精选100个)
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
小众游戏抖音网名男生(精选100个)
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
1 视频模型巨大的“隐形成本”,没人告诉你 06-07
-
2 Intel入门Xe3核显首测!别考虑玩游戏 06-11
-
4 谷歌正式推出Gemma 4 12B多模态模型 06-12
-
6 国产 GPU 厂商沐曦股份筹划赴港上市 06-13
-
7 Fable 5突遭下架,GLM-5.2全量开放 06-14
-
8 谷歌推出DiffusionGemma开源模型 06-14
-
10 英伟达与Abridge合作开发人工智能医疗保健模型 06-14



