推荐系统融合排序的多目标寻优技术
来源:互联网 更新时间:2026-06-17 14:11
掌握推荐系统核心技能,提升算法性能与效率,是每一位算法工程师的追求。今天这篇分享,主要聚焦于融合排序中的多目标寻优技术——从排序公式的核心地位,到业务夹角下的多目标权衡,再到离线寻参的原理和实践,最后带大家看一个开箱即用的自动寻参框架。
分享内容分为五个部分:推荐系统中的排序公式及其地位;工作中常见的业务夹角与多目标权衡;离线寻参技术如何解决问题及其基本原理;高效自动寻参框架的演示;以及最后的问答环节。分享嘉宾是快手资深算法专家程引博士,内容由社区编辑整理。
推荐系统中的排序公式
先聊聊排序公式在推荐系统里到底有多重要。对于有全局视角的算法工程师来说,哪怕日常工作看起来像是在做数据分析、开发或者策略制定,本质上所有努力都是为了一个目标——最终的排序结果。推荐系统的最终输出,说白了就是排序结果。
无论你是在做特征工程、模型训练,还是推荐策略,抑或是努力把业务理念融入推荐结果,所有这些工作的最终目的,都是要把个性化差异体现在最终的排序结果里。而实现这个目标,必须依赖排序公式。它就像是连接所有努力和最终呈现的那座桥。
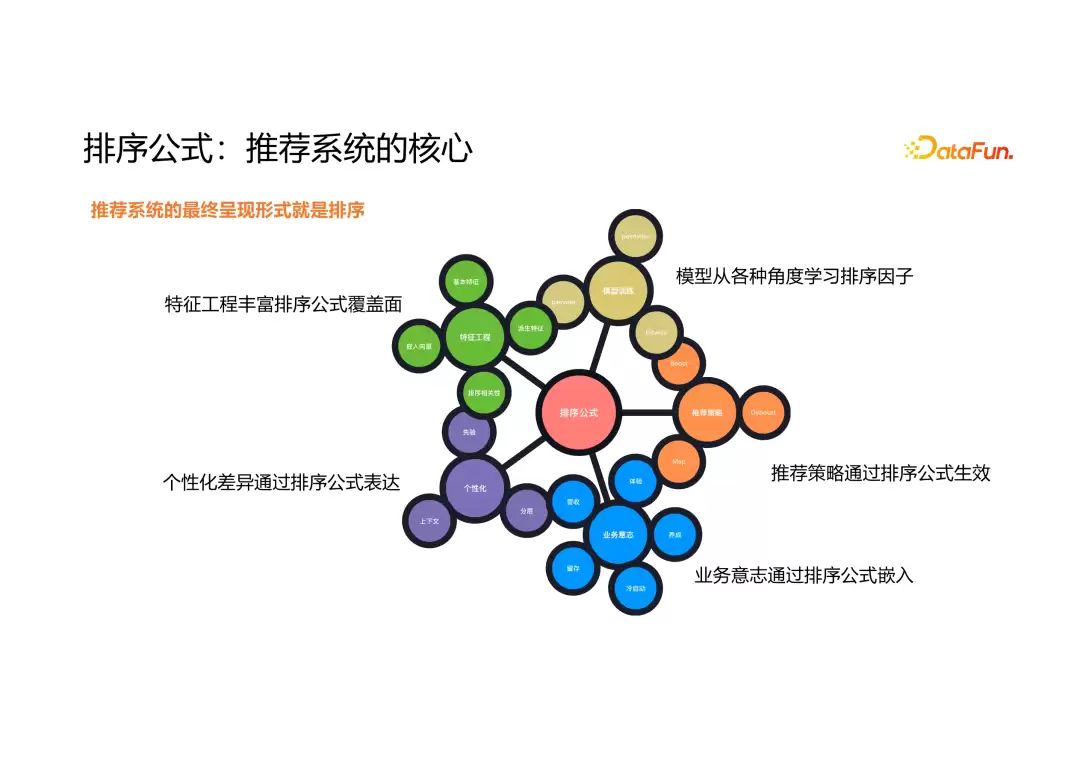
正因为排序公式在推荐系统中处于核心地位,大公司对它研究和迭代的深度和广度都相当可观。排序公式的融合方式主要分为两种:序融合和值融合。
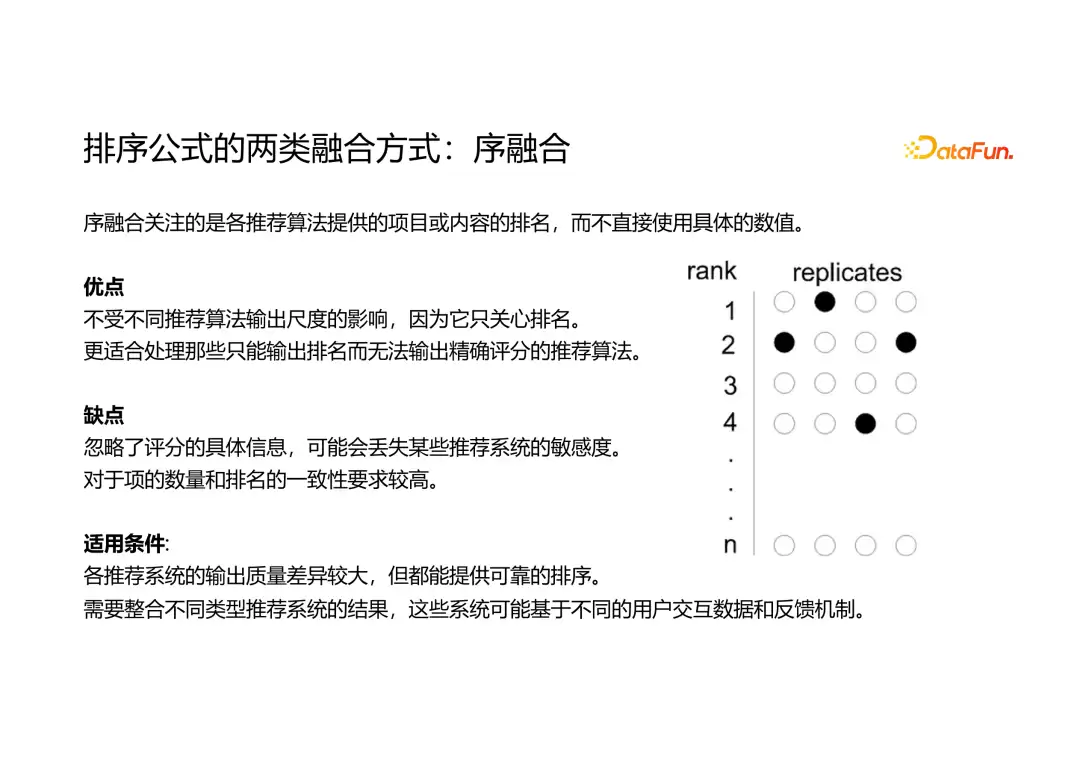
序融合主要关注各个模型或特征给出的排序信号,只关心排名,不关心具体数值。这样做的好处是,直接基于排名维度进行融合,摆脱了各子模块之间尺度差异的影响。它更适合那些只需要最终排名、无法确定精确评分的场景,比如混排。但缺点是会丢失大量信息。
很多大公司在两种方法之间反复尝试。有些团队以前主推值融合,后来觉得方差或差异性不够,转向序融合,过一段时间又改回值融合。没有绝对的好与坏,关键在于结合业务需求选择,或者将两者组合使用。
序融合中最简单常见的是 rank product 方法,这个思路源自遗传算法——用于研究哪个基因最重要。之后很多融合算法都受生物信息学启发。在实际应用中,序融合的研究和应用数量更多。

值融合是直接对各推荐子模块的输出值进行操作。优点是易于理解和调整。调参时,可以清晰地看到每个子模块或公式如何影响结果范围,如何挤压其他信号,如何改变融合分的均值。这些都可以通过离线或在线方式预估。因此值融合实现简单,迭代压力小。但缺点也很明显:如果某些排序因子的预估值分布集中在0.1附近,融合效果就会不理想。
有些目标,比如观看时长或打赏金额,本身有明确的物理含义,但尺度差异可能非常大。这种情况下直接融合效果很差,需要采用标准化或映射方法来解决。当数据来源相对统一——比如同一模型的不同预估值,或尺度接近的场景——值融合的效果更好,操作也更简单。
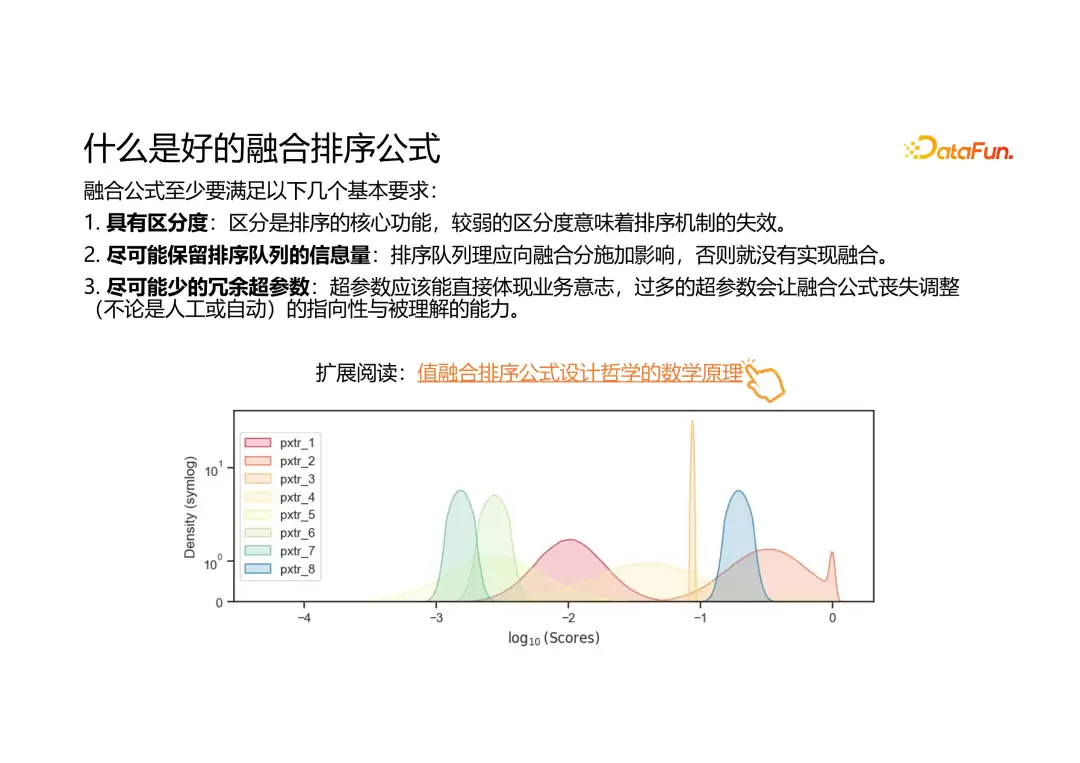
为了更好理解排序公式的融合方式,我们需要明确融合公式要解决的问题,以及如何定义优秀的融合公式。一个优良的融合公式至少应满足以下基本要求:
第一,要有区分度。融合公式综合了各种先验信息、预估信号和业务需求,得到综合评分。如果评分没有区分度,排序机制就会失效。
第二,要最大限度保留各排序因子的信息量。如果融合公式因为设计问题无法保留原始排序因子的信息,那就等于这个因子白做了。
第三,公式不能太复杂。超参数过多会大大增加人工调参的难度,让人容易陷在局部最优里看不清整体趋势。后面我们会提供一些方法,帮助减少参数冗余,更好地理解数据分布,从而更高效地进行参数调整。
在实际工作中,优化从来不只是单一指标的事。优化过程中涉及的指标之间,有时同向优化,有时不相关,有时甚至相互制约。认识和处理好这些关系,对推荐系统的优化意义重大。
业务夹角与多目标权衡
实际工作中,调整模型参数常常“牵一发而动全身”。某个业务的微调可能会影响到其他相关业务,这对参数优化过程带来了很大压力。想要实现“帕累托优化”——在保障所有业务不受影响的同时还能取得收益——实际上非常困难,除非我们关注的指标集合很少。但在现实环境下,各个业务方都有自己的需求,我们得尽量满足。于是问题就变成了:我们需要牺牲多少及哪些业务来换取我们需要的指标?这些指标之间如何折算?对融合公式的迭代来说,这种权衡是必须面对的。
做权衡时,需要基于两种判断:价值判断和事实判断。价值判断来自高层决策,比如公司战略决定大力发展短视频或直播——这种决策反映了公司的价值取向,不是我们能主观改变的。事实判断则是一种客观存在,比如即使我们决定用短视频业务去置换直播业务的某种收益,这两项业务之间的置换难度是客观存在的。多目标优化中,需要尽可能感知这种置换的难易度。可以通过某些工具或调参方式来发现业务间置换的实际难度。制定多目标权衡设计框架时,必须同时考虑公司战略的价值判断和事实判断,这是优化权衡的基本出发点。
上面就是调整推荐系统排序公式融合过程中会遇到的挑战和需要做出的决策。
排序公式离线寻参原理
下面要探讨的是如何迭代排序公式,从而提升技术效能。首先需要思考为什么要进行离线迭代,以及它的必要性。许多公司投入大量人力在调整排序公式上,算法工程师们可能要投入巨大精力在这类任务上。这是一项费时、费心、又费力的工作,却又必不可少。参数一旦调整成功,效果会非常显著。
那么为什么选择离线调整参数?其实也有公司尝试将强化学习接入线上系统,实时学习和调整参数。但这种方法并没有成为主流,原因主要有三点:
首先,线上调参的质量很难保证。线上调参是在实时运行的系统中试错,不能使用大规模流量进行广范围搜索,无法有效覆盖整个样本空间。而且由于是实时交互的过程,结果有很大不确定性,几乎没有试错余地。用强化学习在这种环境下训练非常困难和缓慢。
其次,线上调参的效率无法保证。线上调参过程中,系统不能保证快速收敛,而且状态在不断变化,无法预知最终状态。排序公式其实没必要实时更新——它不需要做到分钟级,我们完全有条件进行离线调参。
最后,线上过程很难处理多目标优化问题。如前所述,多目标优化需要同时考虑价值判断和事实判断,也就是上层的业务需求和当前系统的实际状态。在线上环境下很难实现这种优化,因为无法反复或交叉验证。比如我们无法获取A置换B、B置换C所需的置换难度。而在离线环境下,由于系统是封闭的,我们可以测定各种置换的边际效益和置换效果。
基于以上三点考虑,我们提出了离线调整排序公式的优化路径。

下面介绍离线调参框架的基本原理。首先需要确定要构造什么样的融合公式。有些工程师倾向于加法公式,有些倾向于乘法公式,甚至可能设计有特定物理含义的公式(在广告行业比较常见),还有复合公式——基于某个公式输出进行二次配置,可以写成树状结构的JSON格式。这些都是融合公式。
先确定要迭代的公式形式,然后就能知道有多少超参数需要迭代。迭代公式本质上就是迭代超参数——我们希望知道在新的公式形式下,超参数调到什么样子,线上指标会如何变化。确定了融合公式形式后,就可以开始收集离线样本。
收集离线样本时,需要考虑关注哪些指标,比如点击率、观看时长、分享数、打赏数等。每次迭代时都要明确定义。对于这些目标,要定义自己的计算方式:对于离散变量如点击/未点击,可以用AUC来衡量;对于连续变量如观看时长,可以进行分桶或使用其他评估方法。第二步就是确定希望优化的目标,并决定怎么计算。
确定离线目标后,就要考虑如何将这些目标融合,这又回到我们刚讨论的多目标融合——价值判断和事实判断。你可能认为点击的AUC和分享的AUC同样重要,那么优化目标中两个指标的权重就可以设为1:1。这就是价值判断部分。事实判断部分在于:当你完成离线寻参后,一定会发现有些指标降不下去,有些很容易改进。根据这个认知更新,你需要调整优化目标的设计。
根据定义的结果合并方法和子目标方法,可以使用算法工具(比如Optuna)进行寻优。这就是在sorted top-K prediction问题中的求解方法。
总的来说,离线调参框架至少需要四个功能:确定融合公式、评估子目标、融合子目标,以及一个优化器来求解。这就是从技术角度拆解的离线调参框架。
融合排序量化寻参实战
下面介绍一款业界广泛使用的开源框架——ParaDance。这是一款开箱即用的全自动排序公式迭代框架,支持在Linux和Mac上通过pip工具安装。
ParaDance是开源项目,主要在业余时间开发和维护。如果你感兴趣,也可以贡献代码。它的特点是开箱即用,非常适合一线算法工程师调整排序公式。其次,它支持离线计算并且实现了并行处理,运行速度很快。
得益于许多同行的帮助和建议,ParaDance已经具备丰富的评估手段,不仅支持AUC这类评估方式,也支持其他各种子目标的计算方式。它还支持丰富的公式形式——不仅仅是加法和乘法公式,你甚至可以把想要的自定义公式以JSON形式传入,框架都能很好地支持。
此外,ParaDance提供全程监控功能,可以监控每个子目标和综合目标在迭代过程中的变化,让你直观地看到哪些指标有明显改进,哪些指标难以迭代。安装后就可以开始准备离线数据。
举个例子,这里模拟了一些数据,包括四种类型的XTR(XTR 0到XTR 3),并关注“点击”和“分享”两个子目标。我们更关注“点击”这个目标,认为它比“分享”更重要——这由实际经验和业务需求决定。如果决定按这种方式调参,就需要收集相应的离线数据。这种基础设施在各公司应该已经存在。对离线数据进行采集和均匀采样,很容易实现。根据经验,大约需要几百万条数据才能获得相对稳定的调参状态。
第一步是确定融合公式的形式。很多公司在加法公式和乘法公式之间反复调试。为了方便使用,这里还支持一种叫freestyle的类型,可以在其中任意编写各种形式的公式——支持函数类型推导,甚至条件语句。更复杂的形式是直接传入一个JSON来定义融合公式,几千行的复杂公式都能支持。无论你想调整公式中的一部分还是整体,框架都能支持。确定了融合公式形式后,就可以开始构造融合公式。
代码实现上,首先选择四个排序因子作为考虑对象,用融合公式进行组合。这个例子中采用freestyle形式的融合公式,它具有一定的逻辑意义和物理解释。比如“weight”乘以紧随的两个排序因子(columns1和columns2),它们恰好是对应的排序因子。这个公式是根据实际情况、专业知识和经验判断定义的,代表预期公式应该是什么形式。
在框架中,根据确定的公式形式,会评估并挑选出最佳的公式组合。这个场景下,公式形式为freestyle,有四个超参数需要调整(weights[0]到weights[3])。迭代完成后,框架会给出最佳的参数组合,使公式达到预期效果。
然后,将离线数据传递给模型,指定所需的排序因子、融合公式的类型和形式——这些都已事先定义好。这是确定融合公式形式后的必要步骤,代码实现非常直接。
此外,还需要确定子目标的评估方式以及融合方式。前述的“点击”和“分享”分别作为子目标考虑,需要提前确定如何评估。例如对于“点击”,可以采用AUC进行评估。需要注意的是评估方式可以多种多样,AUC只是其中一种相对容易接受和理解的方式。然后确定子目标之间的融合方式,即如何设定综合目标的计算公式。
一个业务决策的例子:我们可能认为“点击”的AUC更重要,因此给它赋予更大权重,比如设为2。这个决定完全来自业务洞察——比如老板觉得“点击”指标是其他指标重要性的两倍。这将作为初始设定。然后创建一个多目标优化器对象,包含刚刚创建的融合公式和我们希望优化的目标方向。这里设置成“maximum”,表示我们希望AUC尽可能大。然后输入融合目标,设定所需的超参数数量,这些都可以用默认值。如果有具体需求,可以为每个超参数设置精确范围——比如大于0小于1、大于-1小于10、大于1小于100、大于-1小于50等,都可以自由设定。
另外,“studyname”选项会生成包含所有结果的文件夹。这有助于准确了解每次实验的内容,尤其当一天内进行多次尝试时,很容易混淆每次实验的目标和结果。这个命名功能可以为实验记录添加具体描述。
在定义好融合公式和目标后,剩下的代码实现只有一行“run”。“run”后的参数设定循环次数,这里设为300次。实际轮次可能根据具体问题的难度有所不同,但通常几百次迭代就足够使结果收敛。因为排序公式本身也有容量限制,不能无限优化一个指标。
代码运行结束后会输出一个文件夹,第一个文件是实验配置信息。第二个文件paradance_best_trials.csv记录了优化过程——包括两个子目标的优化过程,以及每个超参对应的非列解值。一般情况下取最后一行,即最好的一组参数使用。文件paradance_storage.db和paradance.log分别是check_point和完整的迭代记录。示例数据和代码可通过获取。
Q&A
Q1:离线评估如何构建样本数据?有些候选集在线上的排序方式可能根本没有下发,没有这部分候选集的后验数据,如何保障离线评估的准确性?
A1:这个问题非常关键。目前的方式确实必须要有落盘的数据。如果没有落盘,这部分数据就视为缺失,在离线环境下确实无法解决。离线评估是分阶段的,因为排序从召回一直到最后重排,中间经历了多个阶段。实际上,离线数据采集越靠近真正曝光的环节,这段数据空间对公式的要求越接近,线上线下一致性越好。但如果数据完全偏离、没有落盘,确实无法进行离线评估。
Q2:readme文件上缺少使用文档和示例,这是什么原因?
A2:readme文件很久没有更新了。内部有文档和示例库,但无法对外公布。如果使用中遇到具体问题,可以直接联系分享嘉宾,有相关的用户群提供共享数据和示例,但目前精力有限,readme文档未能及时更新。
Q3:如何处理多样性或流行度高的商品问题?有些商品可能在多个目标上得分都很高。
A3:可以直接设计一个多样性的评估算子,在收盘时进行约束。任何想法都可以转化为算子,然后在迭代过程中进行约束。多样性也不例外,可以用熵或基尼系数作为约束算子。
Q4:不同的用户可能有不同的个性化需求,而离线寻参对所有用户都是一样的,你们有对这点进行比较吗?
A4:总体情况并不是对所有用户一样。算子支持group by方法,这样就可以以用户为单位进行聚类,实现千人千面。
以上就是本次分享的全部内容。希望对大家在推荐系统排序公式和多目标优化方面有所启发。

-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
帅气继父网名女生可爱英文(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
蒙古上单是什么梗
-
韦一敏是什么梗
-
网络热词聊污是什么意思
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
抖音最火沙雕男生网名(精选100个)
-
韩漫小少爷网名大全女生(精选100个)
-
有寓意的易经网名男生(精选100个)
-
因空难被判“过失杀人罪” 空客、法航均被顶格处罚22.5万欧元
-
免费看电影的软件推荐
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
三角洲行动卡战备怎么弄 三角洲行动卡战备攻略
-
5 消息称豆包日活超2亿但收入不足百万,字节AI资源或向企业端倾斜 06-17
-
7 AI移花接木造谣“地铁塌顶”,一女子博流量被依法拘留 06-17
-
8 大厂网盘变天?腾讯悄然上线“AI原生网盘”打破传统 06-17
-
9 AI音乐混战,谁能成为“中国版Suno”? 06-17
-
10 李想的AI延长线 06-17



