ChatBI,其实跟你想得不一样!
来源:互联网 更新时间:2026-06-16 13:56
ChatBI是今年比较火的一个话题。它和企业知识库问答类似,属于ToB领域极少数有希望用相对低成本落地的大语言模型应用。不少企业已经做过一些探索,但更多企业仍认为技术不够成熟,还是选择先观望。
朋友圈里有人预测,在不做任何配套工作的前提下,90%的ChatBI项目都会失败。说实话,这个判断,我觉得很在理。
那么,问题来了,到底该选什么样的技术路线?适合哪些用户来用?想要真正落地,又得提前做哪些功课?相信这些问题,很多计划或正在探索ChatBI的朋友都有类似的困惑。
经过二十多个项目的陪跑实践,以及与超过一百家客户的深入交流,团队积累了不少一手经验。很多结论与直觉相悖,在这里做一些分享,希望能帮你少踩几个坑。

技术路线选择
首先得说,让LLM直接写SQL这事儿,真心不靠谱。这主要体现在三个方面:精度、性能和可信性。
1. 精度
对业务用户来说,即便容忍度再高,平均精度也得达到75%到80%,否则大概率会被弃用。大模型幻觉是已知问题,在非结构化数据场景下,结果不满意大不了再问一次,可一旦落到结构化数据上,答案错了就是错了,这个风险会被严重放大。在实际测试中,LLM写SQL时,时间理解错误、排序逻辑出错、子查询偏差、表关联关系误解之类的问题层出不穷,而且很难彻底解决。所以另一种选择是:让LLM把用户问题转写成结构清晰的查询语言,再通过OLAP操作指令集调用成熟的BI底座,模拟人工拖拉拽的方式直接出图。这样一来,生成的图表与清晰意图直接匹配,精度大幅提升。
2. 性能
现在不少写SQL的产品,一个问题能6秒内返回已经算优秀了,有的甚至要12秒甚至15秒以上。问题是,用户等10秒真的能接受吗?实际经验表明,最长返回时间超过3秒,体验就相当糟糕,用户很难坚持用下去。影响LLM写SQL性能的因素很多,比如模型尺寸、是否本地部署、硬件投入、SQL复杂度等。既然不让LLM写SQL,那方案就变成了:用小尺寸的语义解析模型处理清晰语义,LLM只处理模糊语义。这样清晰语义返回平均0.2秒,模糊语义平均2秒,基本够用。
3. 可信性
ChatBI在实际应用中难免出错。两个问题绕不开:怎么排查结果对错?答案错了怎么办?只有解决了这两点,产品才算有可信性。Text2SQL路线的常见思路是给用户看一段SQL,很多IT人员觉得这样清晰、好调试。可业务用户看得懂SQL吗?他们需要看SQL吗?更现实的问题是,SQL的调试难度与复杂度正相关,尤其多表关联查询,如果测试时没有探到边界,上线后的排查和修复会非常头疼。相比之下,另一种做法是给用户一段清晰可读的图表生成规则,用户可以直接调整维度、指标、枚举值、分组条件等,再按自己的设想二次点选生成新图表。再加上BI底座对快速计算的原生支持,很多SQL难以处理的问法也能轻松搞定。

ChatBI怎么落地?
第二个核心观点:ChatBI不能开箱即用。一个项目要成功落地,得讲究天时、地利、人和。
- ——公司内能找到真场景,业务真的有需求;
天时
- ——落地团队具备成熟的数据和知识底层;
地利
- ——有配套的组织驱动力,能链接业务调研到真实需求,有明确的责任人往前推进。
人和
1. 真场景
2024年的ChatBI,就像一个创新药上市前需要做临床试验。在与客户共创的过程中,最大的挑战恰恰是:有些客户并没有找到自己的痛点,硬把ChatBI当解决方案套进去,最后发现没效果。建议还是多和业务团队对话,了解他们日常取数场景是怎样的,遇到了哪些痛苦,然后对症下药。如果客观条件有限,不得不先尝试,那最好基于成熟数据去开发demo,给用户中的积极分子先用起来,通过这个过程去找场景。但坦率地说,这种做法的成功率恐怕很低,需要有心理准备。
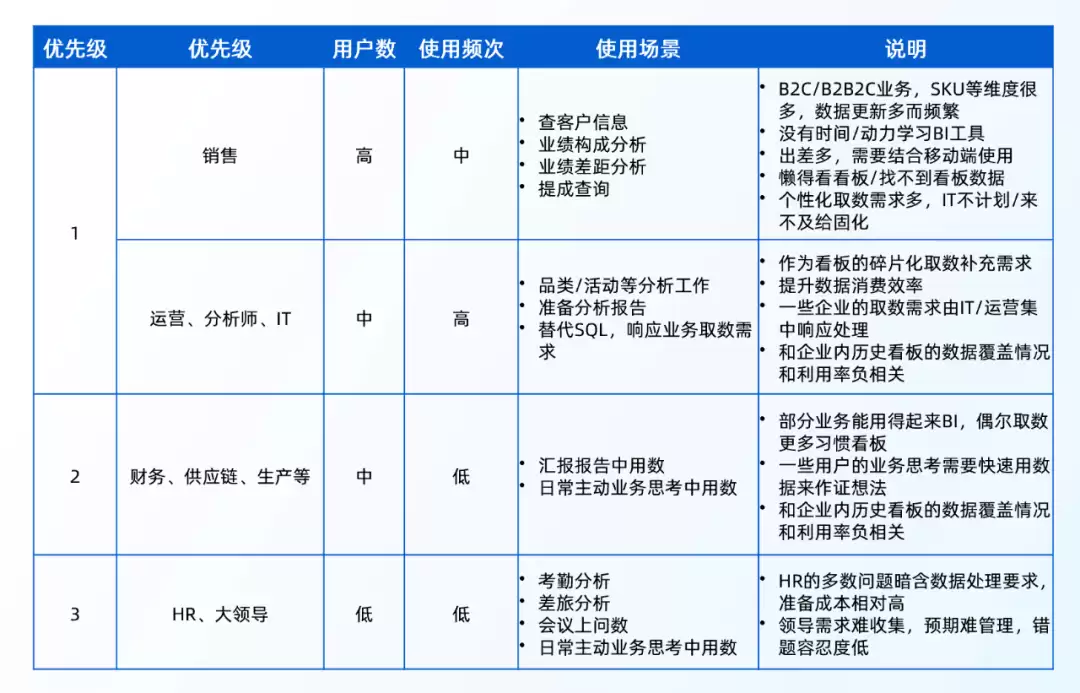
那么,ChatBI的用户到底是谁?从用户数、使用频次、使用场景来看,适合的目标用户群体大致如下。
2. 底层准备
数据侧:
知识侧:
同义词
企业独有的其他知识
3. 组织驱动力
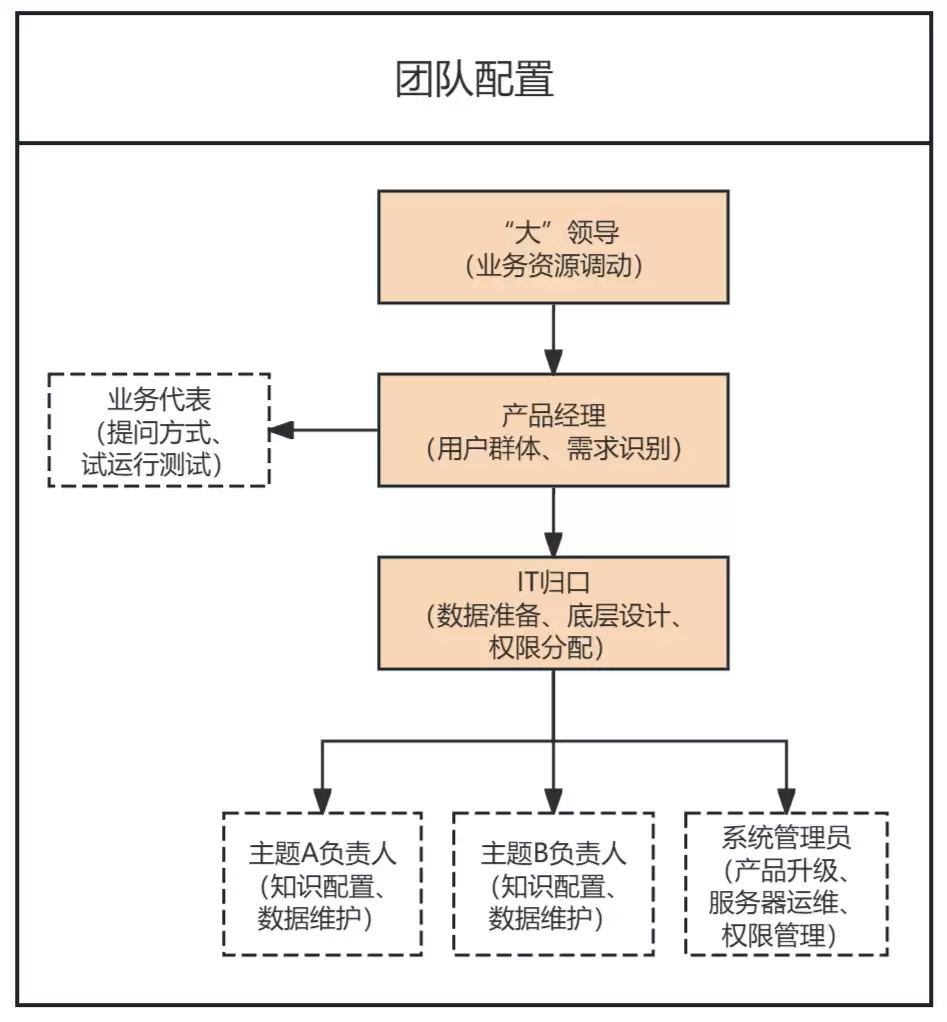
第三个观点:ChatBI不适合先给领导用。一个项目要成功,企业内部至少需要三个角色——领导、产品经理和IT。这三个角色可能是两个人,也可能不止三个人。
- :最核心的角色,承担整个项目成败的KPI,负责整体节奏规划、用户群确定、需求收集和识别、内部推广、运营拓展等。ChatBI上线是循序渐进的过程,大体流程是:项目团队组建 → 职责拉通 → 需求调研 → 需求评估 → 选定目标业务域1 → 数据准备 → 知识配置 → 权限配置 → 内部测试 → 试点运行 → 后台分析 → 用户回访 → 用户培训 → 系统上线 → 错题修复 → 成果汇报 → 选定目标业务域2……不难看出,项目之初产品经理经验不足,领导还没有充分信任之前,很难做好对领导的需求收集和预期管理。所以,ChatBI不适合一开始就给大领导用,也不适合大规模并行推广,而应该线性推进,干成一件事,夯实一块,再拓展。
产品经理
- :拍板决策投入,保障产品经理获得必要的业务支持,参加项目启动仪式,明确项目范围、成功标准、时间节奏。
领导
- :负责数据准备、底层设计、IT配置。
IT
另外还有两个角色很重要:
业务代表
业务团队中的ITBP
对于第一个完整业务闭环,一些团队已经推出了场景陪跑服务,帮助客户把第一个场景真正用起来。

正式上线还有哪些要关注的?
在确定场景、底层准备、组织驱动力三个条件都具备的前提下,ChatBI的落地成功率会很高。如果要正式上线,安全性、算力成本、持续运营投入,是必须关注的重点。
1. 安全性
是否具备企业级权限控制能力?LLM是否支持本地化部署?这两点直接决定了能否安全落地。
2. 算力成本
理论上,LLM尺寸越大效果越好,但更大尺寸意味着更高昂的硬件资源成本。另一种思路是基于小尺寸开源LLM做多任务精调,这样资源成本可以大幅降低。
3. 持续运营投入
我们常常惊叹模型日新月异的能力,却容易忽略效果背后的迭代频率。同理,一个ChatBI产品的精度,是在1个人使用下测出来的,还是在10个维度指标自由组合下测出来的?是上线两天内的平均精度,还是长期运营后的真实水平?当用户数扩大、数据范围扩大、时间线拉长,对精度的影响是立竿见影的,迭代频率也会非常高。企业内部ChatBI受众肯定是逐步增大的,团队需要认真考虑:是否准备了单独的资源来承接运营调优?是否有方法论指导优化?产品是否有相关功能支撑范围扩大后的问答效果提升?

最后:对LLM的祛魅
常对客户说,ChatBI首先是一个严肃的企业级应用,其次才是AI。而LLM是AI的一部分,并不等于AI。一个企业级应用,不管有没有AI、不管用了什么技术,核心目的始终是帮助客户安全、稳定、低成本地解决业务问题,进而创造价值。在设计过程中,必须综合考虑稳定性、性能、客户成本等诸多因素,对LLM的使用始终保持谨慎乐观的态度。有些能力,比如模糊检索,LLM能做,成熟算法也能实现,但用算法实现客户成本更低,那未必非要用LLM。有些配置工作,比如知识配置,交给LLM去做,客户综合成本可能是人工配置的几十倍,效果还不稳定,显然不推荐。至于预测、离群点识别等能力,LLM原本就不擅长,更适合用其他AI能力来实现。而可视化等AI之外的功能,更不是LLM的强项。
商业化的ChatBI,非常考验厂商的态度、研发投入和能力。做这件事是为了炫技,还是为了真正落地,背后的难度和投入不是一个数量级的。本文主要分享了当前业内普遍把“快速问数”作为ChatBI第一阶段落地的一些经验。实际上,ChatBI不只是查数,它希望帮助广大没有专业分析背景的业务用户,自主完成一些个性化的分析工作,比如思路拆解、异常检测、归因分析、趋势预测、报告生成等。挑战当然重重,但方向是清晰而正确的。总有一天,ChatBI能真正帮助100%的业务用户用好数据。

-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
网络热词聊污是什么意思
-
帅气继父网名女生可爱英文(精选100个)
-
抖音最火沙雕男生网名(精选100个)
-
蒙古上单是什么梗
-
帅到极致的网名女生霸气(精选100个)
-
韦一敏是什么梗
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
免费看电影的软件推荐
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
因空难被判“过失杀人罪” 空客、法航均被顶格处罚22.5万欧元
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
有寓意的易经网名男生(精选100个)
-
韩漫小少爷网名大全女生(精选100个)
-
1 无法分类的AI专利 06-16
-
2 腾讯混元3D AI创作引擎:开启3D内容创作的新纪元 06-16
-
3 预测:生成式 AI 时代下的网络安全未来 06-16
-
6 谷歌CEO斯坦福再被嘘,竟被逼不敢提AI 06-16
-
7 皮肤问题心中没底?“AI问诊+医生复核”新模式上线 06-16
-
8 思想市场的价格发现:当AI决定什么思想被调用 06-16
-
9 拥抱 AI 的无限可能 06-16
-
10 AI音乐视频创作新风向:立刻MV 1. 1 版本实现“一键成片”跨越 06-16



