5人2周肝出5.1k星,小米 MiMo Code开源但bug不断,开发者炸锅
来源:互联网 更新时间:2026-06-13 14:26
6月11日凌晨,小米MiMo团队悄无声息地放了一个大招——MiMo Code正式发布,并且直接以MIT协议开源。说实话,这个消息在AI编程圈子里还是掀起了不小的波澜。
这个产品基于OpenCode构建,定位很明确:面向长程自动化编程任务的终端编程Agent。翻译成大白话就是,它要解决AI编程Agent在连续执行几十步甚至上百步任务时,如何保持决策质量、状态连续性,以及怎么把跨任务的经验积累下来。目前MiMo Auto限时免费,基于MiMo-V2.5模型,支持100万token上下文。
罗福莉在X上写得很直白:“14天、5个人、一场vibe coding之旅。于是,MiMo Code诞生了。”她还透露了一个小彩蛋:Auto模式下的新用户,可能随机被分配到UltraSpeed模式——MiMo-V2.5-Pro会以1000 tokens/s的速度飞速输出。这个速度确实够惊人。
既然是AI编程工具圈的新玩家,Claude Code这个标杆自然绕不过去。小米直接放出了对比数据:MiMo Code搭配MiMo-V2.5-Pro,在三项离线benchmark中均优于Claude Code搭配Claude Sonnet 4.6的结果。不过团队也很坦诚地指出,这些benchmark主要衡量的是一次性解决单个仓库级问题的能力,而MiMo Code真正打磨的多轮记忆、后台状态维护、完成度验证和跨session进化这些设计,它的核心价值还需要在持续几十轮的真实开发场景中才能体现出来。

更有意思的发现是,当任务复杂度上升时,MiMo Code的优势会愈发明显。小米表示,在同一目标模型下对比MiMo Code与Claude Code的端到端真实开发体验时,任务执行步数在200步以内时,两者胜率接近50%;但一旦超过200步,并且包含多轮用户交互后,MiMo Code的胜率就攀升到了65%以上。这正好印证了它在长程任务上的设计初衷。
已经有尝鲜的用户反馈说,MiMo Code用起来比较顺手,UI体验不错,响应速度似乎比Claude Code还快,而且注入到会话中的冗余内容更少。也有用户提到自己拿到了MiMo-V2.5-Pro UltraSpeed模型访问权限,认为速度确实快,不过成本高于DeepSeek,是否值得长期使用还需要打个问号。
1、5.1k stars 和 229 个 issues
1、5.1k stars 和 229 个 issues
开源产品一旦放到社区里,反馈就像潮水一样涌来。截至目前,MiMo Code已经收获了5.1k的star数。
有意思的是,当用户发现它是基于OpenCode构建时,反应出现了两极分化。一部分人直接说“啊,算了,它只是OpenCode的一个分支”,语气里透着失望。但马上有人反驳:如果之前用OpenCode开发,那MiMo Code就是OpenCode的加强版。
还有开发者提出了更深层的担忧——开源生态里PR太多的问题。“OpenCode可能是目前开源Agent中最成熟的那一个,只是官方看起来也是太忙了,协调不过来5000多个PR没人审核。不知道小米那边会怎么搞,迅速涌入大量的PR来不及审核,可能这就是AI时代的必然结果吧。”
事实也确实如此。MiMo Code开源后,开发者的反馈迅速集中到GitHub Issues区,目前已经超过了200条。
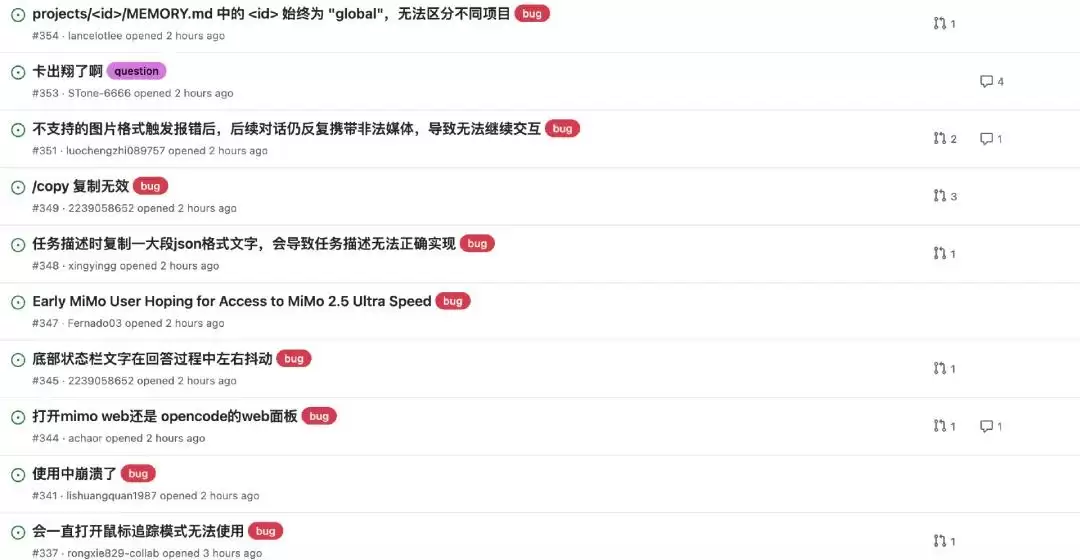
从公开的Issues来看,MiMo Code暴露出了一批典型的早期产品问题:使用非常卡、MiMo Auto免费通道登录后凭证未持久化、从Claude Code导入API Key失败、升级后仍显示OpenCode字样、Termux环境日志暴涨、WSL安装后运行异常、语音与粘贴功能不可用——以及最受关注的,Agent未经用户确认就自动删除了全局npm包。
这个删除事件特别值得拿出来说。有用户反馈,MiMo Code的Agent在执行任务时,自动检测到用户全局npm目录下存在OpenCode相关包(包括opencode-ai、opencode-windows-x64、oh-my-opencode、oh-my-opencode-windows-x64等),自行判断这些包是迁移残留,随后未经用户确认就执行了npm uninstall,导致正在使用的OpenCode开发环境直接被破坏。
用户的愤怒是有道理的。Agent不应该在未经明确确认的情况下执行任何删除操作,尤其是影响范围这么大的全局npm包操作。即使系统判断某些包可能是残留,也应该先问一句。用户的建议很中肯:对于npm uninstall、rm这些删除操作,必须增加确认机制,最好还能提供dry-run模式,先展示将要执行的操作,再由用户确认。
还有用户反馈疑似存在内存泄露:“使用pnpm安装打开后从未输入任何内容,再回来发现内存占用过高。”
更让人哭笑不得的是,有用户反馈MiMo Code思考时陷入了重复螺旋——就像人陷入了死循环一样,翻来覆去想同一个问题。
除此之外,各种各样的bug也开始冒出来,比如Agent执行过程执行了2个dart脚本就卡死2次等等。
其他平台上的反馈也值得关注。有用户指出,MiMo Code默认开启了telemetry,会向tracking.miui.com发送指标信息,包括正在使用的模型。虽然可以通过环境变量MIMOCODE_ENABLE_ANALYSIS=false关闭,但“默认开启且命名为analysis”的设计确实不太理想。也有用户指出,即使关闭了遥测,工具仍会自动检查更新并获取MiMo模型列表,不过这些行为倒是可以禁用。
从战略层面来看,MiMo Code的思路其实很清晰:效仿Claude Code,先快速vibe出一个产品,然后放到真实用户中不断打磨,直到产品逐渐成熟并商业化。但这条路并不好走,需要很强的工程能力持续弥补,需要未来更强模型的加持,还要承担在国内开发者中的口碑流失风险。当然,这些问题不是小米独有的,任何走这条路线的公司都绕不过去。
2、Coding harness 开源,会威胁 Claude Code 们吗?
2、Coding harness 开源,会威胁 Claude Code 们吗?
Claude Code、Codex这些工具正在成为开发者日常工作流的一部分,但一个隐忧也随之浮现:这些工具是否在锁平台?是否会在上下文、工具调用和遥测层面形成新的“黑箱”?
有开发者对MiMo Code的开源给出了高度评价:“很好,coding harness就应该开源,而大模型应该被视为商品化能力。这样可以最大限度降低用户的切换成本,也能让人们更清楚地理解自己是如何与上下文以及大模型输出进行交互的。现在整个行业的方向走偏了:Claude Code一直保持闭源,尽管它已经多次泄露过源代码;而开源的Gemini CLI也被逐步弃用,转而让位于闭源的Antigra vity CLI。”
不过也有网友提出了不同的看法:企业为什么要主动开源这些工具、降低用户迁移成本?“这类似于要求云服务商把平台全部开源、取消出口费用,让客户随时离开。”在他看来,开源并不天然等于商业模式,企业没有义务把有价值的产品层变成公共品。
这里说的coding harness,可以理解为把大模型接入真实编程工作流的一整套“运行框架”。大家很自然地就把模型和coding harness分成了两个不同的部分。MiMo Code的开源也引发了一个激烈讨论:coding harness到底有没有护城河?
一派认为,真正完成代码任务的是底层模型,coding harness本身并没有太多神秘之处,更多只是用户体验层面的能力。另一派则指出,不同harness的配置、工具设计、人类审批机制、diff展示、上下文注入方式,都会显著影响最终效果。换句话说,即便模型是核心发动机,运行时和工具层依然会决定Agent能不能稳定进入真实工程流。
有开发者说得更直接:“Claude Code根本就没什么特别之处。我们不需要他们的商业模式,他们才需要。”
有人进一步分析了Anthropic的盘算:通过Claude Code,他们把大量订阅额度与编程使用场景绑定,不只是赚取token收入,更是在获得高价值软件开发数据,并推动开发者围绕其harness概念形成使用习惯。
Anthropic原本只是通过API token获得中等规模的收入,但当他们开始把大量使用额度打包进Claude Max的20/100/200美元订阅套餐后,一切都变了。相对于API token的价格,这些订阅套餐给出的使用额度非常夸张,但前提是你必须使用他们的coding harness。而至少在Claude Code刚开始这么做的时候,作为一个coding harness,它其实还不如很多开源工具。
严格来说,Claude Code是一个免费产品,因为你可以用它接入任何模型。它对“一个coding harness应该如何工作”并没有太多流行的、强主张式的设计,但它却是目前最受欢迎的同类产品,甚至在OpenAI、Meta、Google这些竞争对手的大模型工厂里也被广泛使用。为什么?如果只是因为Anthropic的模型好5%,大多数工作场所应该会优先按token效率(也就是成本效率)来优化。
Anthropic之所以能赢下自家harness、自家token的使用量,同时还能获得可观收入,是因为他们大幅补贴了token消耗。
这给他们带来了很多东西:
第一,关于软件开发如何使用大模型的一手高价值数据。软件开发既是大模型应用中最先受益的行业之一,也是最有钱、最愿意为此花钱的行业之一。
第二,把整个行业引导到围绕他们的harness概念形成事实标准。某种意义上,他们正在把自己变成大模型交互接口领域的W3C,只不过这是一个私营组织。
第三,所有这些数据。
这种判断背后,反映的是AI编程产品商业模式的深刻变化。过去,模型公司主要依靠API token计费;而如今,编程Agent正在成为模型消费的高频入口。MiMo Code的开源,在部分用户看来,就是对Claude Code等闭源工具的一次正面挑战。
3、与 Claude Code 工程重点分化
3、与 Claude Code 工程重点分化
从技术路线看,Claude Code和MiMo Code都属于“模型 + 运行时 + 工具调用循环”的终端编程Agent。模型负责推理和决策,运行时负责管理工具、组装上下文、执行命令、持久化状态,并把工具结果反馈给模型进入下一轮。但二者的工程侧重点,已经开始出现明显的分化。
通过对Claude Code的全面源码级架构分析(覆盖Claude Code v2.1.88版本,约1900个TypeScript文件、约51.2万行代码),同时结合精选社区分析、面向Agent构建者的设计空间指南,以及跨系统对比研究,VILA实验室给出了一个重要发现:
Claude Code代码库中,只有1.6%属于AI决策逻辑,其余98.4%都是确定性的基础设施,包括权限管理、上下文管理、工具路由和恢复逻辑。Agent循环本身只是一个简单的while循环,真正的工程复杂度存在于围绕它构建的外围系统之中。
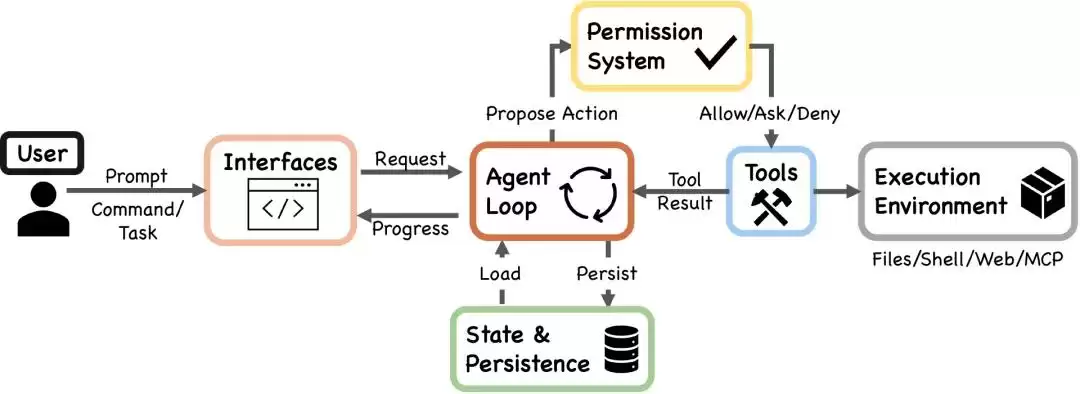
这是Claude Code的架构图。VILA实验室表示,Claude Code的每一项设计选择都可以追溯到人的决策权、安全性、可靠性、能力放大和适应性。系统有7层安全机制,但它们都受到性能约束影响。此外,跨层交织的Harness难以重新实现——循环很容易复制,但hooks、分类器、压缩机制和隔离机制并不容易复制。
相比之下,根据小米的博文,MiMo Code更聚焦长程编程任务,围绕“计算、记忆、进化”三条主线,强化决策质量、多轮状态连续性和跨session的经验沉淀。
小米MiMo团队认为,在短任务中,完整对话历史通常可以作为工作记忆。但当任务进入几十轮甚至上百轮后,上下文窗口、指令遵循率和任务状态管理都会成为瓶颈。随着工具输出、代码片段和报错日志不断累积,上下文窗口终会被填满。简单摘要压缩会强化近处信息、衰减远处信息,无法按需回溯;即使窗口足够大,模型也会因为输入过长而难以提取当前真正应该执行的约束与意图。
为此,MiMo Code将长程编程Agent的瓶颈拆分为三个时间尺度:同一session内的单轮决策质量,主要受限于计算量;同一session内的多轮任务连续性,主要受限于状态管理;跨session的任务改进,主要受限于经验提炼机制。对应到产品设计上,就是“计算、记忆、进化”三条主线。
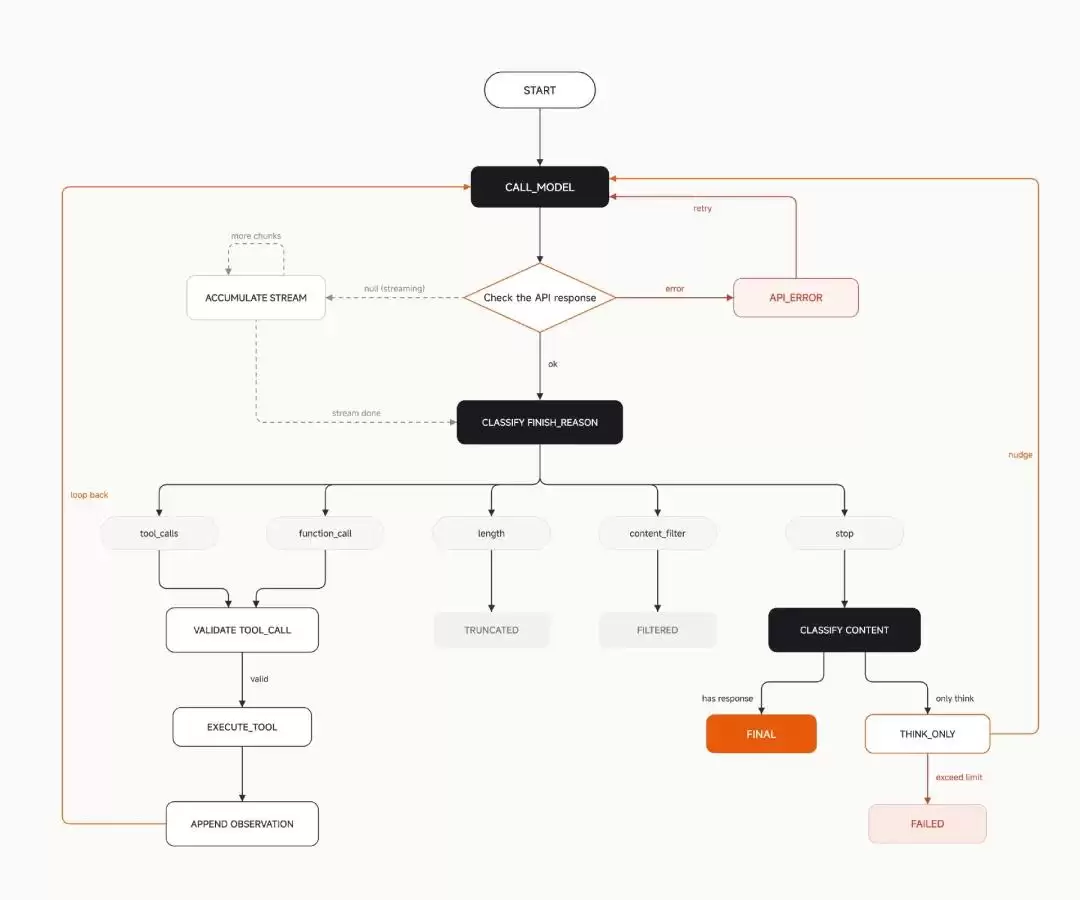
这是MiMo Code Harness主循环的状态机。
在计算层面,MiMo Code引入了Max Mode和Goal。Max Mode是并行采样选优:每一轮并行生成多个候选方案,默认数量为5,候选方案只做推理和工具调用规划,不实际执行,随后由同一个模型作为judge,对比候选方案的推理过程和行动计划,选出最优方案执行。它的目标是降低长任务中单步错误率被累积放大的风险。
小米MiMo团队称,在SWE-Bench Pro上,Max Mode相比单次采样提升了10%到20%,代价是约4到5倍的token消耗。目前该功能仍处于实验阶段,需要手动配置开启。
如果说Max Mode解决的是“做对”,Goal机制则主要解决“做完”。在长任务中,Agent容易在看到已有进展后过早宣称任务完成,尤其在无人值守的自动化运行中,这类提前终止会放大失败风险。Goal允许用户用自然语言设定停止条件,例如“所有测试通过且代码已提交”。每当Agent尝试终止时,系统会自动发起一次独立模型调用,对完整对话历史进行审查,判断停止条件是否真正满足;如果未满足,则将具体差距反馈给Agent并要求其继续。
这与Claude Code的停止机制不同。Claude Code主要由主Agent自己判断是否不再需要工具调用,外加max turns、context overflow、hooks、abort等系统条件;MiMo Code则显式引入独立verifier,把“做事的Agent”和“验收的Agent”分开了。
MiMo Code还尝试优化工具调用的语法。团队认为,模型通过何种格式发出工具调用,会直接影响准确率和token效率。部分模型在输出结构化JSON时格式错误率较高,XML相比JSON略好,而受限命令行语法在表达相同调用意图时token更少、格式错误率更低。
编排:从自然语言流程到代码化 workflow
两者的差异在任务编排上体现得尤为明显。
Claude Code的编排方式更偏模型逐步决策。模型看到上下文后决定下一步工具调用,工具结果返回后再决定下一步。它可以通过AgentTool委派子Agent,也可以通过MCP、skills、hooks等机制扩展能力,但核心仍然是模型在循环中动态选择动作。
MiMo Code则提出了Dynamic Workflow,把复杂流程编排从prompt迁移到代码。小米认为,当任务规模扩大到整个项目迁移等场景,需要同时协调几十甚至上百个并行工作单元时,传统“把流程写进自然语言prompt或SKILL.md”的方式会系统性失效。因为自然语言流程容易被上下文压缩吞掉,模型也可能跳过步骤,分支和重试逻辑依赖模型判断而非代码保证,导致同一流程多次执行路径不一致。
Dynamic Workflow的核心变化是将编排逻辑从prompt转为代码。主Agent会生成Ja vaScript脚本,在隔离沙箱中确定性执行,并通过agent()派出子Agent,通过parallel()和pipeline()控制并发。小米表示,这样可以让模型的判断力集中用于理解代码和生成代码,而不是承担流程控制本身。MiMo Code的实现兼容Anthropic Dynamic Workflow的核心语义,并扩展了workflow()原语、日志恢复和沙箱内文件读写等能力。
记忆机制:从上下文压缩到 rebuild
Claude Code的记忆体系主要包括CLAUDE.md、auto memory、JSONL session transcript和子Agent sidechain transcript。CLAUDE.md用于存放项目级规则、编码约定、构建方式、测试方式等可版本化信息;auto memory存放对话过程中沉淀的自动记忆;session transcript以JSONL形式记录会话;子Agent的完整轨迹则写入独立sidechain,父Agent只接收摘要,避免子任务过程污染主上下文。
这套设计强调透明、可审计、可恢复,但本质上仍是在有限上下文窗口内做“压缩与管理”。
MiMo Code的目标则不同——让一个逻辑会话可以无限延伸,而每个上下文窗口仍保持有界。其基本机制是Cycle:当会话接近窗口上限前,运行时会在固定位置触发checkpoint,并派出独立的writer subagent读取已有对话,将结构化状态写入磁盘;主Agent继续工作,writer并发执行。当窗口接近真正上限时,运行时执行rebuild,切断当前窗口并开启新窗口,用已经持久化的文件作为种子重建上下文。
小米特别强调,checkpoint不应等到窗口快满时才触发。原因在于模型在高上下文利用率下能力会衰减,长输入中段材料更容易被忽略(也就是常说的“lost in the middle”);同时,提取和压缩本身也需要上下文空间。MiMo Code因此选择在相对早期触发checkpoint,大致位于已配置预算的20%、45%、70%处,每次进行增量更新,避免最后一次仓促压缩。
与Claude Code不同,MiMo Code没有让主Agent自己维护记忆,而是将记忆提取交给独立writer subagent,它不与主Agent共享注意力或token预算。小米认为,要求一个正在调试复杂问题的模型同时维护结构化日志,往往会让两件事都做不好。因此,会让writer写入一份固定结构的checkpoint文件,包括当前意图、下一步动作、工作约束、任务树等11个字段。为了避免并发写入导致状态不一致,每个结构化文件只允许一个actor写入。
在长期记忆体系上,MiMo Code设计了四层记忆:Session记忆用于当前逻辑会话,Project记忆用于保存项目级持久知识,Global记忆用于跨项目生效的用户偏好,History则以SQLite形式保存每个会话的完整轨迹,包括每条消息和每次工具调用原文。当结构化记忆无法找到细节时,Agent可以通过history工具回溯原始记录。
进化:从项目记忆到流程资产
在进化层面,MiMo Code试图让Agent从跨session的经验中持续改进。其项目级记忆文件采用Markdown格式,保存项目背景、用户明确要求的规则、架构决定及其理由、反复验证过的技术事实。
小米MiMo团队选择文件而非纯向量数据库,主要原因是可审查性:当记忆会影响Agent后续行为时,用户需要能够看到系统记住了什么,并删除错误条目或修改过时知识。
为了维护项目记忆质量,MiMo Code还设计了Dream与Distill两类整理机制。Dream每7天自动触发,由独立Agent读取历史session对话和现有记忆文件,执行合并、去重、路径有效性验证和压缩,并更新全局记忆;Distill每30天自动触发,重点不是整理知识,而是识别反复出现的工作模式,并将其固化为可复用的skill、CLI命令、自定义Agent或SOP文档。
参考链接:
https://arxiv.org/abs/2604.14228?utm_source=chatgpt.com
https://mimo.xiaomi.com/zh/blog/mimo-code-long-horizon
https://github.com/XiaomiMiMo/MiMo-Code/issues
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
免费影视剧APP推荐
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
抖音最火沙雕男生网名(精选100个)
-
网络热词聊污是什么意思
-
帅气继父网名女生可爱英文(精选100个)
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
我的末日校园海斗手游上线时间是哪天
-
蒙古上单是什么梗
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
免费看电影的软件推荐
-
韦一敏是什么梗
-
晨字沙雕网名大全女生(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
短剧《情绪超市》剧情介绍
-
3 去掉 VAE 之后,商汤用 8B 参数重新定义了开源生图的上限 05-31
-
4 ControlFoley - 小米开源的可控视频音效生成模型 06-01
-
5 智元开源行业首个聚焦物理交互的具身数据集 06-03
-
8 字节开源统一框架Bernini 06-04
-
10 沐曦GPU与InfiniCCL开源框架完成首发适配 06-05



