Anthropic的六步闭环,让漏洞无处遁形
来源:互联网 更新时间:2026-06-11 14:05
安全团队的人手永远不够,代码库却越堆越大。传统的漏洞扫描工具,扫出来的结果经常是“雷声大雨点小”——80%都是误报,工程师看到安全告警早就免疫了,真正要命的漏洞反而被淹没在噪声里。这几乎是每个开发团队都会遇到的困局。
最近,Anthropic的安全团队给出了一个全新的答案,或者说是一套系统性的解法:用AI把代码安全的效率彻底拉满。而且,他们已经用这套方法,在开源代码里挖出了
500多个藏了几十年、传统工具完全没发现的高危漏洞
为了把这个经过验证的经验分享出来,Anthropic把过去一年和上百家企业安全团队合作的经验,总结成了一套可落地的
六步AI安全闭环
0 为什么传统安全工具越来越不够用了?
过去我们常用的静态扫描工具(SAST),本质上还是“规则匹配”:把代码和已知的漏洞模式比对,比如有没有硬编码密钥、有没有用过时的加密库。这套路数,在面对越来越复杂、越来越隐蔽的漏洞时,越来越力不从心。
现在面临的攻击类型,远不止规则能覆盖的那么简单:
- ,比如权限校验漏掉了一个关键接口
跨文件的业务逻辑漏洞
未知的、没有现成规则可以匹配的漏洞
- :用户的输入到底能不能一路流到危险的函数里?传统规则工具很难理清这种长链条
复杂的数据流追踪
而AI的不同在于,它能像人类安全研究员一样,
真正读懂代码、理解逻辑、追踪数据流
不过,直接让大模型扫代码,也并非一劳永逸。Anthropic发现,会迎面撞上三个新问题:
- :AI不了解业务上下文,会把内部可信的配置当成一个高危漏洞
误报依然很高
- :AI一天能找出上百个漏洞,安全团队根本审不完
结果太多,处理不过来
- :扫出漏洞后,没人跟进怎么修,最后还是堆成了技术债
修复环节脱节
于是,他们将AI强大的分析能力与工程化的流程结合起来,搭建了这套六步闭环,把整个安全审计流程标准化、自动化。
1 六步闭环:AI安全审计的标准化流程
这套流程的核心逻辑,用一个词概括就是:
先搭好边界,再让AI批量干活,最后把结果过滤、排序、修复,形成闭环
前两步是搭建环境的一次性工作,后面四步就是可以反复运行的扫描流水线了。
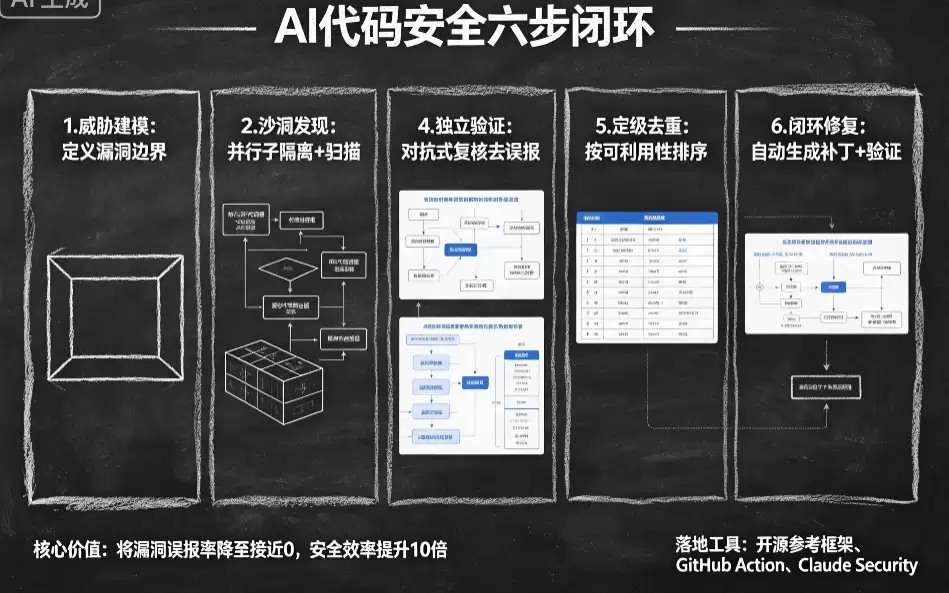
第一步:威胁建模,先搞清楚“什么才是漏洞”
这是整个流程最基础,也最容易跳过的一步。你有没有遇到过这种场景:AI扫完代码,给你报了一堆你根本不在乎的“漏洞”?比如内部服务的配置文件,本来就是可信的,AI却当成了“硬编码密钥”来报警。
问题就在于,AI不知道你的
信任边界
所以第一步,要先给AI建一个威胁模型,告诉它你的系统长什么样:
你的服务,哪些是对外的,哪些是内部的?
你信任哪些输入?配置文件里的内容能不能信?
你最关心哪些漏洞?哪些可以忽略?
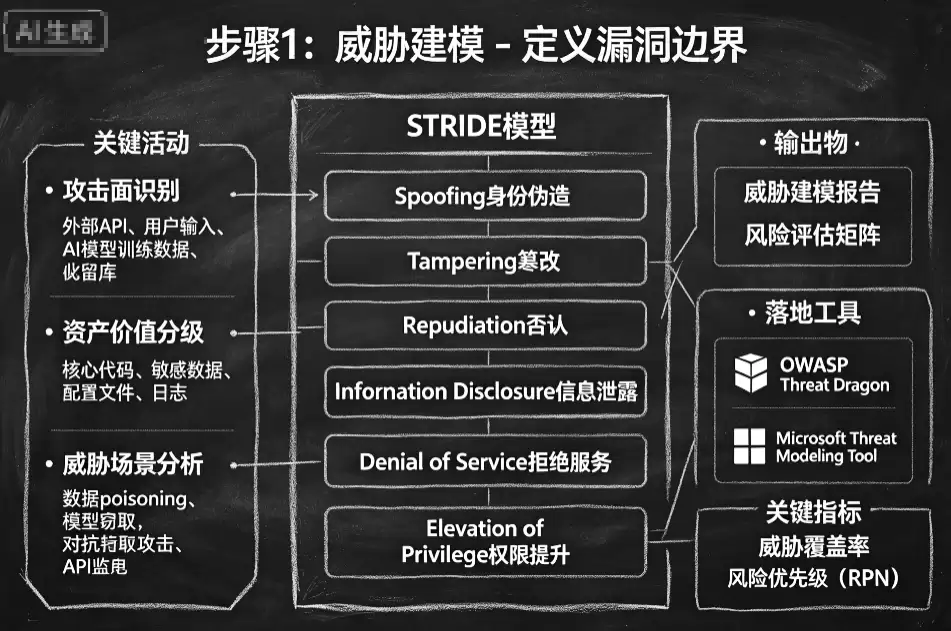
Anthropic甚至为此做了一个小工具,可以自动生成这个威胁模型:它会把你的架构文档、Git历史、过去的漏洞记录都喂给AI,让它自动生成一份THREAT_MODEL.md初稿。然后,AI会拿着这份初稿,用经典的安全四问(你在做什么?可能出什么错?你打算怎么应对?做得好不好?)跟系统负责人反复对齐,把业务逻辑中隐含的信任假设都补全。
做完这一步,AI的误报率会显著下降。有团队测试过,完成威胁建模后,AI发现的漏洞中,
90% 都是真实可利用的
✅ 现成工具:Anthropic的开源参考仓库里,已经有threat-model这个技能。在Claude Code里运行它,就能自动帮你生成威胁模型。
第二步:搭沙箱,既要安全,又能验证漏洞
威胁模型搭完,接下来需要一个沙箱环境。这一步有两个关键目的:
- :AI在扫描时,可能会不小心执行一些危险的命令,沙箱能把它隔离起来,不会影响到你的日常开发环境
保护你的生产环境
- :AI扫描代码时,如果怀疑存在一个漏洞,它能在这个沙箱里跑一个POC,真实测试一下看能否利用。这样就能把那些不可利用的误报直接过滤掉
验证漏洞的可利用性
Anthropic给出的最佳实践是:先将开发环境彻底搭建好——装好依赖、编译代码、跑通测试——然后给整个环境打一个快照。关键点是:
断网
这样一来,AI就能在沙箱里放心地跑POC,而你不会担心它搞乱环境。有团队试用后反馈,加了沙箱验证这一步后,不可利用的发现项直接减少了一大半,误报率降到了传统工具的十分之一。
✅ 现成工具:开源仓库里已经提供了沙箱的配置脚本 setup_sandbox.sh,直接运行就能搭好隔离环境。
第三步:批量发现漏洞,几十上百个AI并行干活
前两步完成,就可以开始真正的扫描了。这一步的思路是:不要尝试让一个AI从头到尾扫描整个代码库,那样效率太低。正确的做法是,让AI先把代码库按模块、按接口、按攻击面拆分成小块,然后同时启动
几十上百个并行的子Agent
Anthropic在实践中发现,在这个环节,不要给AI写一堆长长的检查清单,那样反而会限制它的创造力。你只需要给定一个清晰的目标,比如“扫描这个模块,寻找安全漏洞”,剩下的让AI自己探索该怎么做——它会自己用 grep 搜索、自己读文件、自己跑工具,甚至编写新工具来完成扫描任务。
他们自己用这种方式扫描开源代码,一天之内就能扫完几十万行代码,找出大量传统工具遗漏的漏洞。
✅ 现成工具:仓库里的 vuln-scan 技能就是干这个的。它会自动读取你的威胁模型,拆分代码库,并行扫描,最后输出结构化的结果。
第四步:独立验证,让AI自己挑自己的错
扫地完毕,拿到一堆潜在的漏洞清单之后,还不能直接交给开发团队。因为里面依然可能存在误报。
这一步的核心策略是:
负责发现漏洞的AI只管找,验证工作交给另一个完全独立的AI来干
假设这个漏洞是假的,我想尽办法来证伪它

它会仔细检查:
有没有上游的校验,用户的输入是不是已经被过滤过了?
有没有认证机制把关?这个接口是不是只有登录用户才能调用?
这段代码是不是根本跑不到?会不会是死代码?
如果有可用的沙箱,它甚至会自己跑一遍POC,看漏洞能否被真正利用。更关键的是,Anthropic会启动好几个独立的验证AI一起“投票”,如果意见不一致,就再启动一个裁判AI来仲裁。
这套机制下来,误报率会被压到接近零——因为AI会自己挑自己的错。有团队反映,加了这一步后,不可利用的发现项直接砍掉了一半,安全团队再也不用整天面对一堆无用的告警。
第五步:定级去重,别让工程师被告警淹没
确认是真漏洞后,还有一个问题:一次扫描可能会产生几十个漏洞,哪个优先级最高?而且AI在扫描时,同一个根因的漏洞可能会被反复报告——比如整个系统都缺失了权限校验,AI可能给每个接口都单独报一遍,最后给你几十个几乎一模一样的告警。
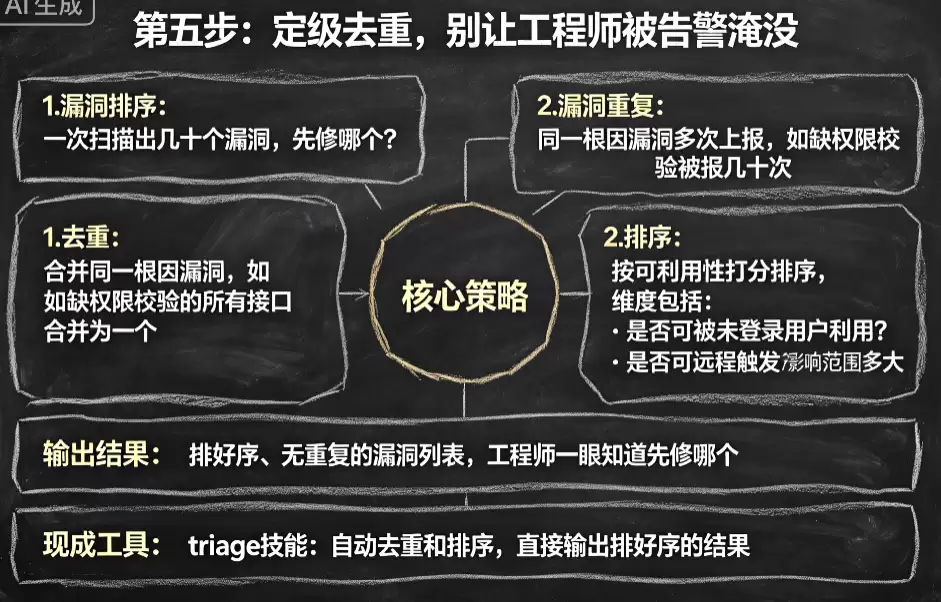
所以这一步的核心是
去重+排序
- :把同一个根因的多个漏洞合并成一条,比如“系统多处接口缺少权限校验”,不管有多少个接口受影响,都合并为一个,让开发团队一次性修复
去重
- :按可利用性和影响范围来打分。不是按漏洞类型排序,而是看:能不能被未登录用户利用?能不能远程触发?影响范围有多大?把最危险的漏洞排在最前面
排序
这样最终交给开发团队的,就是一个排好序、无重复的漏洞优先级列表。工程师一眼就能看出该先修哪个,不会再被海量告警淹没。
✅ 现成工具:triage 技能,自动完成去重和排序,输出可直接使用的顺序列表。
第六步:闭环修复,从发现到改完,一步到位
最后一步,是生成修复方案,并且做到自动化。AI不会只告诉你“这里有个漏洞”,它会直接帮你写好修复的代码,而且会遵循你们团队的代码风格。
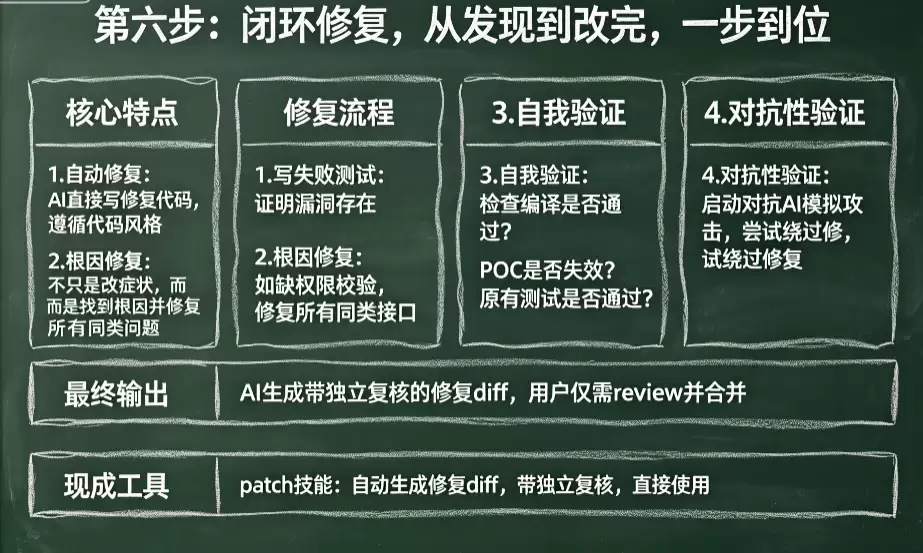
更重要的是,它不是头痛医头、脚痛医脚,而是会做一套完整动作:
先写一个失败的测试用例,证明这个漏洞确实存在
定位根因,不止修复症状。比如发现是某个框架层缺少权限校验,它会把所有同类接口都修掉
修复后,它会自动验证:编译能否通过?之前的POC还能不能成功利用?现有的测试覆盖是否仍然有效?
最后,会再启动一个对抗性的AI,假装攻击者,尝试绕过这次修复
整个流程几乎不需要人工介入,你只需要在最后 review 一下AI生成的补丁,确认合并即可。
✅ 现成工具:patch 技能,自动生成修复的 diff,并附带独立的复核验证,可以直接使用。
2 这些工具,今天就能拿来用
Anthropic不止贡献了一套理论,而是把整个流程所需的工具都开放出来了。
1. 开源参考框架:defending-code-reference-harness
这就是把整个六步闭环的代码都开源出来的仓库。里面包含了:
所有环节的技能模块:威胁建模、扫描、验证、定级、修复
沙箱的配置脚本,开箱即用
演示示例,clone下来后,运行
/quickstart,就能在demo项目上完整跑一遍流程,五分钟就能看到效果
如果你想自己搭建,直接拿这个仓库改就行,不用从零开始。
2. 自动化PR审查:claude-code-security-review
这是Anthropic官方的GitHub Action。你只要把它添加到CI流程中,
每次有人提PR,它就会自动扫描改动过的代码,寻找安全漏洞
它的优势在于:
能理解代码语义,跨文件追踪数据流,发现业务逻辑漏洞
自动过滤误报,不会乱发无关告警
支持所有主流编程语言,无论是 Python、Rust、Go 还是 Ja va
而且成本极低。一个普通的PR,用Sonnet模型来跑,成本只要几分钱到一毛钱。一个团队一个月下来可能也就几十块钱,比请一个专职安全工程师划算得多。
3. 企业托管服务:Claude Security
对于不想自己搭建基础设施的企业用户,Anthropic提供了现成的SaaS服务——Claude Security。你只需要授权GitHub仓库,它就能:
自动定期扫描代码库,寻找漏洞
提供一个Dashboard,展示所有漏洞及其优先级
自动生成修复PR,你只需点一下合并
支持SOC2、HIPAA等合规审计需求
他们已经用这个服务,帮助客户找出了超过500个传统工具未能发现的漏洞,其中不少是在系统里隐藏了十几年的老问题。
4. 自定义安全Agent:搭建专属扫描器
如果你希望定制化——比如公司有特殊的安全规则——Claude Code还支持通过编写一个简单的Markdown文件,来构建你自己的安全扫描器。你可以做一个专门扫描OWASP Top 10漏洞的Agent,或者扫描支付模块的专用Agent。以后直接调用它,它就会按你的规则自动扫描,不需要每次都重复写提示词。
3 不同团队,怎么快速上手?
了解了这么多,可能最关心的是:从哪里开始?这里给出针对不同团队的建议:
- :直接用GitHub Action,加到你的项目里。每次提交PR自动扫描,五分钟就能完成配置,成本几乎为零。
个人开发者
- :clone那个开源参考仓库,把六步流程跑起来。每周自动扫描一次代码库,就能覆盖大部分安全风险。
中小团队
- :直接使用Claude Security托管服务,省去基础架构的维护工作。安全团队只需专注处理AI筛选出的高危漏洞,效率提升可达10倍。
大企业
4 最后:AI安全的时代,防御者终于能追上攻击者了
当前的安全行业,面临一个令人尴尬的局面:攻击者早已在用AI寻找漏洞,一天能挖出几十个零日漏洞;而防御者还在依赖几年前的老工具,一个月才能修复几个。
Anthropic的这套方案,正是将同样的AI能力交到了防御者手中——你能用AI比攻击者更快地发现漏洞、完成修复,在攻击者利用之前就把坑填平。
这或许就是AI安全的未来:不是要换掉安全专家,而是给他们装上“喷气背包”,让他们能跟上这个越来越快的世界。

-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
下载浏览器app下载安装选择推荐
-
免费影视剧APP推荐
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
抖音最火沙雕男生网名(精选100个)
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
网络热词聊污是什么意思
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
帅气继父网名女生可爱英文(精选100个)
-
短剧《情绪超市》剧情介绍
-
免费看片软件下载地址推荐
-
洛克王国世界S2赛季狂欢怪谈介绍
-
免费看电影的软件推荐
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
3 神话模型Fable 5被曝降智,只为防蒸馏?AI大佬抗议 06-11
-
4 华纳音乐正式收购Sureel AI:为音乐人构筑版权防火墙 06-11
-
7 只会说漂亮话的AI,办不了“填志愿”这件人生大事 06-11
-
8 专家发声:暂无证据显示AI引发大规模裁员 企业勿盲目跟风 06-11
-
9 百度高考服务升级:推出“AI志愿报告”并引入真人专家审核机制 06-11
-
10 最强Fable 5跨越神话时刻,但AI学会了自相残杀 06-11



