云知声U2模型表现亮眼:登LLM Stats前30,长上下文评测超Claude Opus 4.7
来源:互联网 更新时间:2026-06-11 13:12
先说一个让人眼前一亮的消息:海外知名AI模型评测机构LLM Stats刚刚更新了榜单,咱们国产大模型这次着实争了口气。云知声自研的U2模型,在两项核心评测中顺利跻身全球前列——不仅综合排名杀入前30强,更在长上下文推理这一硬核任务上,成功超越了国际顶尖选手。可以说,这标志着国产大模型在复杂任务处理能力上,又迈出了关键一步。
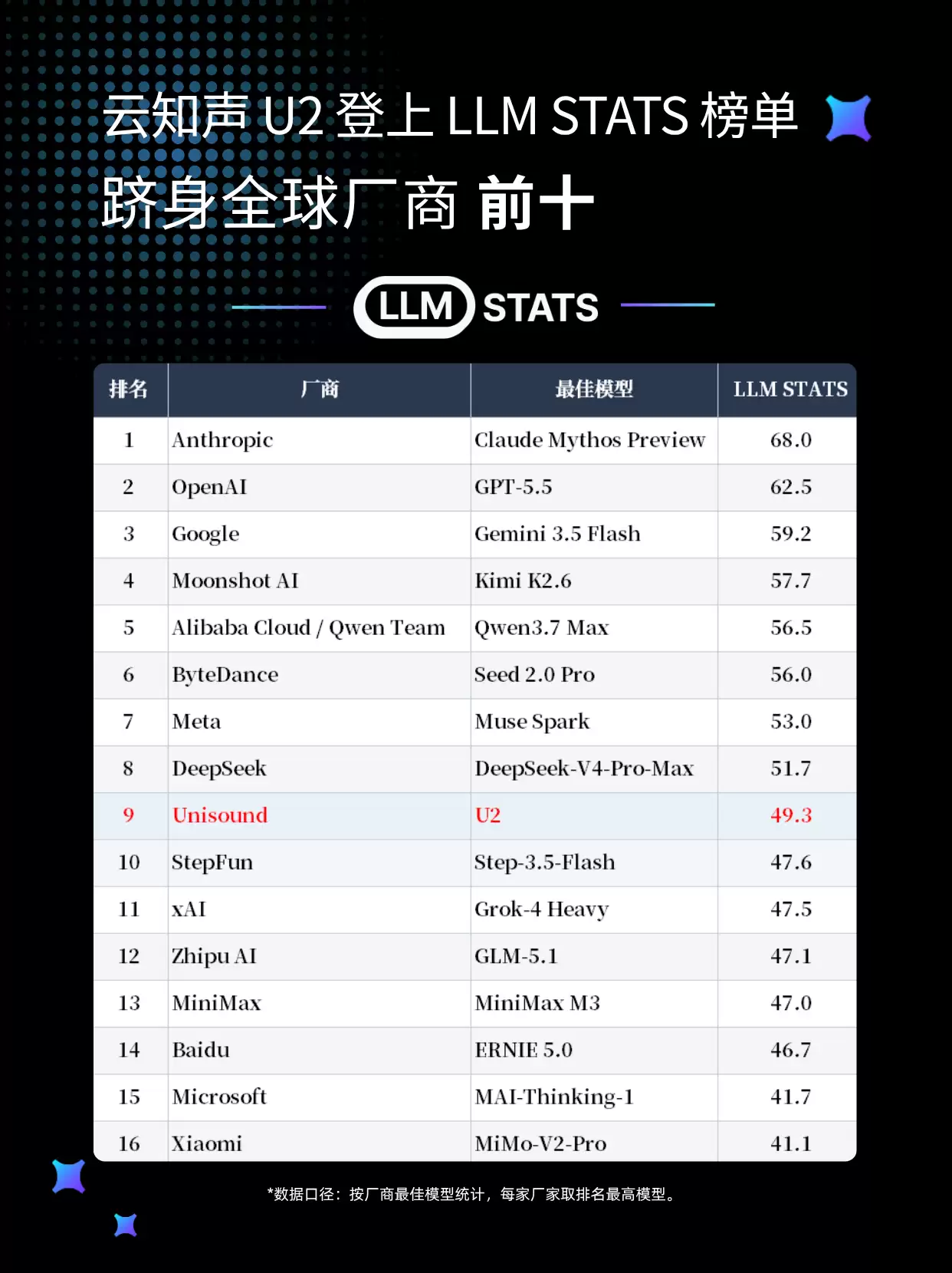
关于这次的评测标准,其实还挺值得聊一聊的。LLM Stats Score这套体系,并不是传统那种“跑一个测试集就出分”的简单模式。它通过整合公开数据、独立采样还加验证性基准测试,构建了一个综合评分模型。说白了,就是把推理运算、代码生成、知识储备、工具调用、智能体协作以及长文本处理这几个维度全部拉通,综合评估模型的实际战斗力。也正因如此,这套标准被业界视为衡量模型实战能力的“试金石”。在这套严苛标准下,云知声U2模型的表现相当均衡,最终在厂商最佳模型排名中不仅位列全球第九,还展现出极强的综合实力。
不过,真正让同行侧目的,还是它在长上下文推理这个细分领域的表现。要知道,长上下文处理能力一直是衡量大模型实用价值的关键指标——毕竟,谁能处理更长的文本、更复杂的逻辑,谁就能在金融、法律、科研等需要处理海量文档的行业里占据先机。这次U2模型基于LongBench-V2基准测试,在包含503道多选题的测试集中取得了54.4%的准确率,直接超越了Claude Opus 4.7这样的国际知名模型。需要补充一点,这项测试的文本跨度从8K单词一直到200万单词,覆盖了短、中、长三种长度区间,专门评估模型在单文档问答、多文档综合、长文本学习、对话历史理解、代码库分析以及结构化数据处理这些复杂任务中的稳定性。能在这样的挑战面前脱颖而出,U2模型的技术功底可见一斑。
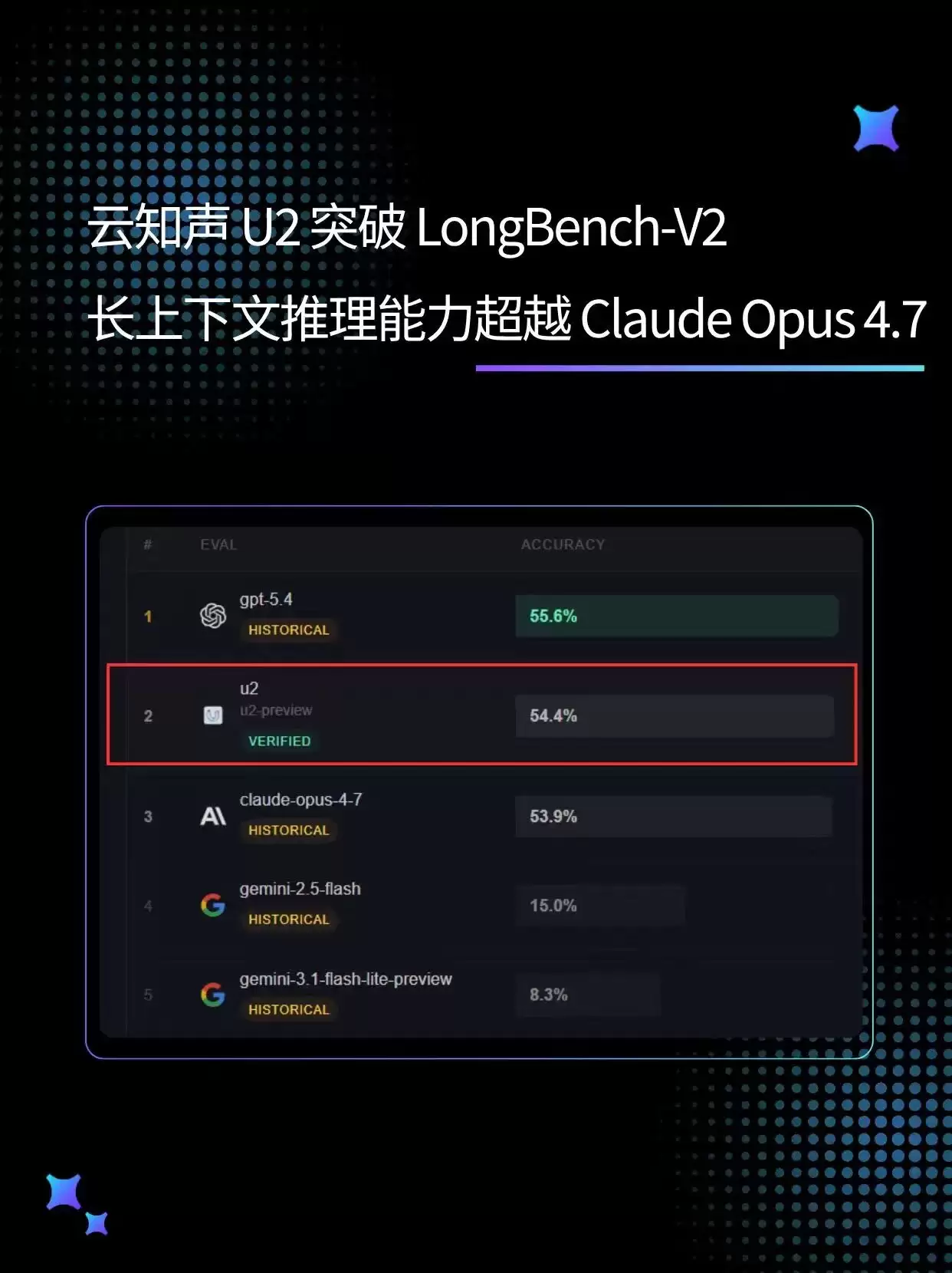
从技术专家透露的信息来看,云知声U2模型之所以能在长上下文处理上取得突破,关键还是架构设计上的创新。它在保持低延迟响应的同时,大幅提升了对超长文本的语义理解与逻辑推理能力。这意味着什么?意味着在需要通读数十页合同、分析密集的法律条文、或者处理超长科研论文的场景下,U2模型都能派上用场。这不仅是榜单上的数字,更是技术落地的底气。从行业视角来看,国产模型在核心技术领域的竞争力已经不只是“追赶”,而是实实在在地在部分领域实现了引领。对于金融、法律、科研等需要处理海量文档的行业来说,这次评测结果无疑提供了更具说服力的技术选项。
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
免费影视剧APP推荐
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
抖音最火沙雕男生网名(精选100个)
-
网络热词聊污是什么意思
-
帅气继父网名女生可爱英文(精选100个)
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
我的末日校园海斗手游上线时间是哪天
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
免费看电影的软件推荐
-
蒙古上单是什么梗
-
韦一敏是什么梗
-
晨字沙雕网名大全女生(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
短剧《情绪超市》剧情介绍
-
2 Codex撞脸Claude_Code,新功能只领先11天 06-09
-
3 别人还在入门,你已经精通!Claude Code进阶必备14招 06-10
-
7 Claude写前端组件提示词从普通版到进阶版怎么写 06-10
-
10 公开版Mythos上线,Claude 最强模型开始分层发售 06-11



