高级工程师最怕的不是被 AI 替代,而是给 AI 擦屁股
来源:互联网 更新时间:2026-06-09 07:27
以前总有人担心AI会抢程序员饭碗,后来才发现,真正让人崩溃的,不是你被替代了,而是你——一个资深架构师、技术负责人,突然发现自己成了AI的清洁工。
一. AI 写代码的问题,不是“不会写”
很多Ja va开发者对AI编码工具的感受很矛盾。
一方面,它确实快。一个接口、一个DTO、一个Mapper、一个SQL、一个页面脚手架,几秒钟就能吐出来。写Demo、补样板代码、生成初稿,效率肉眼可见。
但另一方面,它又经常把真正麻烦的部分留给人。
比如一个Ja va项目里,AI能轻松生成一段“看起来正确”的接口代码,但它可能不知道团队统一响应体是什么,不知道异常应该走全局异常处理,不知道权限校验该放哪一层,不知道这个接口是否需要幂等,不知道数据库字段的真实含义,也不知道已有工具类已经封装过同样逻辑。
结果就是,你得到一种非常拧巴的体验:AI好像帮你省了30分钟编码时间,却额外制造了2小时清理成本。
这才是高级工程师真正反感的地方。不是怕AI强,而是怕AI半吊子。它能写,但只写到“看起来像代码”的程度;它能跑,但离“可以交付”还有一长段距离。
二. 半成品代码,最容易消耗资深工程师
普通AI编码工具最常见的问题,不是完全写错,而是写得太像半成品。
它能根据一句话生成Controller,但可能漏掉入参边界、权限判断、请求日志和错误码。
它能生成Service方法,但事务边界可能放错,批量更新没考虑失败回滚,外部调用没有超时、重试和降级。
它能写Repository或Mapper,但可能不知道当前项目是手写SQL、MyBatis XML、MyBatis Plus,还是团队自定义的数据访问规范。
它能生成单元测试,但测试只验证对象不为空,根本没有覆盖金额计算、状态流转、重复提交、并发更新这些真正会出事故的地方。
它能补项目文档,但文档像模板,不解释关键约束,也无法把需求、接口、表结构和代码实现串起来。
这些问题单个看都不大,叠在一起就会变成技术债。更麻烦的是,半成品代码不像编译错误那样显眼,它经常以“差一点就能用”的状态混进工程里。
于是资深工程师的时间被一点点吃掉:改命名、补异常、查漏洞、重构结构、补测试、对齐规范、解释为什么这段代码不能上线。表面上是人机协作,实际体验却像人类给AI做售后。
三. 真正可怕的是低价值兜底
资深工程师的价值,本应放在更高层次的判断上。需求边界怎么切?接口契约怎么定?数据模型怎么设计?哪些逻辑应该抽象?哪些地方不能为了赶进度留下隐患?哪些安全问题不能放过?哪些测试能真正兜住核心风险?哪些规范必须坚持,哪些历史包袱可以慢慢迁移?这些才是工程能力。
但当一个AI工具只会端到端生成一坨代码时,人就被迫退回到非常低价值的工作里。
你不是在做架构设计,而是在问:“这个类名为什么这么怪?”
你不是在做系统演进,而是在问:“这个事务为什么没包住?”
你不是在控制工程质量,而是在问:“这个测试为什么只断言了 not null?”
你不是在复盘业务风险,而是在检查AI有没有把响应体写成另一个项目的格式。
所以,AI编程最可怕的不是它取代高级工程师,而是它把高级工程师拖回低价值兜底劳动。如果AI提效没有工程质量兜底,本质上只是更快地生产技术债。
四. 智能引导的价值,是让AI先理解工程流程
Ja va生态有一个很现实的问题:并不是每件事都难,但每件事都很烦。依赖冲突烦,编译报错烦,框架升级烦,安全漏洞修复烦,单元测试补齐烦,项目文档整理烦,代码风格清理也烦。
一个成熟工程师当然能修依赖、能补测试、能看安全问题。但问题是,为什么这些低价值重复劳动一定要占用你的主要时间?
飞算Ja vaAI就是冲着这种Ja va工程化痛点设计的AI开发助手。
很多AI工具都藏着一个隐蔽问题:它懂Ja va语法,却不懂真实项目是怎么一步步做出来的。
这件事不能简单归结为“AI不行”。很多时候,问题出在使用方式上:我们把AI当成一个单点代码生成器,让一个通用模型直接吐代码,然后再让工程师去猜它为什么这么写、漏了什么、哪里不符合项目规范。
这就像让一个刚入职的实习生直接负责完整需求,却不给他需求上下文、接口约束、数据库说明、团队规范、安全边界和测试标准。他当然能写出一些东西,但你很难放心交付。
真实Ja va工程开发不是单点任务,而是一条链路:
需求分析 -> 接口设计 -> 表结构设计 -> 业务逻辑 -> 代码实现 -> 测试验证 -> 安全检查 -> 文档交付
每个环节都有自己的专业判断。需求没拆清楚,后面的代码生成越快越危险;接口契约没定清楚,Service写得再多也会返工;表结构没对齐业务关系,后面一定会在查询、性能和数据一致性上还债;测试和安全不前置,所谓“提效”只是把风险推迟到上线前。
所以真正需要的不是一个更快的AI实习生,而是一组能协同工作的AI专家。
继续拿前面的任务管理功能举例。
如果只让AI一键生成,它很可能会直接吐出新增任务、修改任务、查询任务列表、删除任务这几个接口。看起来功能齐了,但真正决定这个功能能不能上线的,是另一批问题:任务状态有哪些枚举?负责人能不能为空?谁可以改负责人?逾期提醒按什么规则触发?状态变更要不要写操作日志?删除任务是物理删除还是逻辑删除?这些问题如果没有摊开,生成出来的代码越完整,后面返工越重。
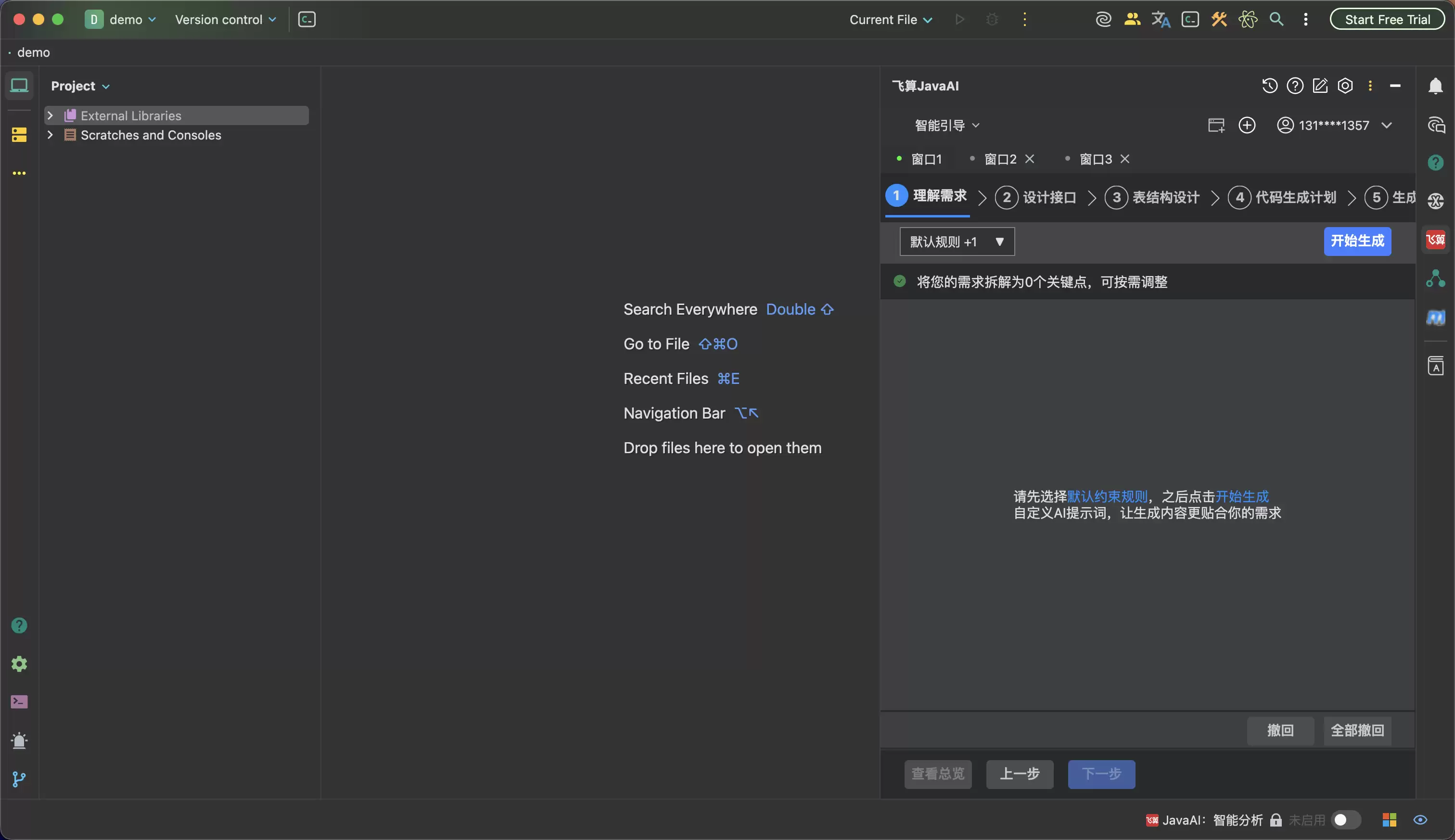
飞算Ja vaAI智能体模式值得聊的地方,就在于它不是让一个通用AI一口气把所有代码吐出来,然后让开发者自己去收拾残局。它更像是把Ja va工程开发拆成多个专家Agent协作的流程:需求规划、接口设计、数据库架构、业务逻辑、源码生成等不同角色分步推进。开发者不是坐在黑箱后面等结果,而是能看到过程,能在关键节点介入,能修改和确认。
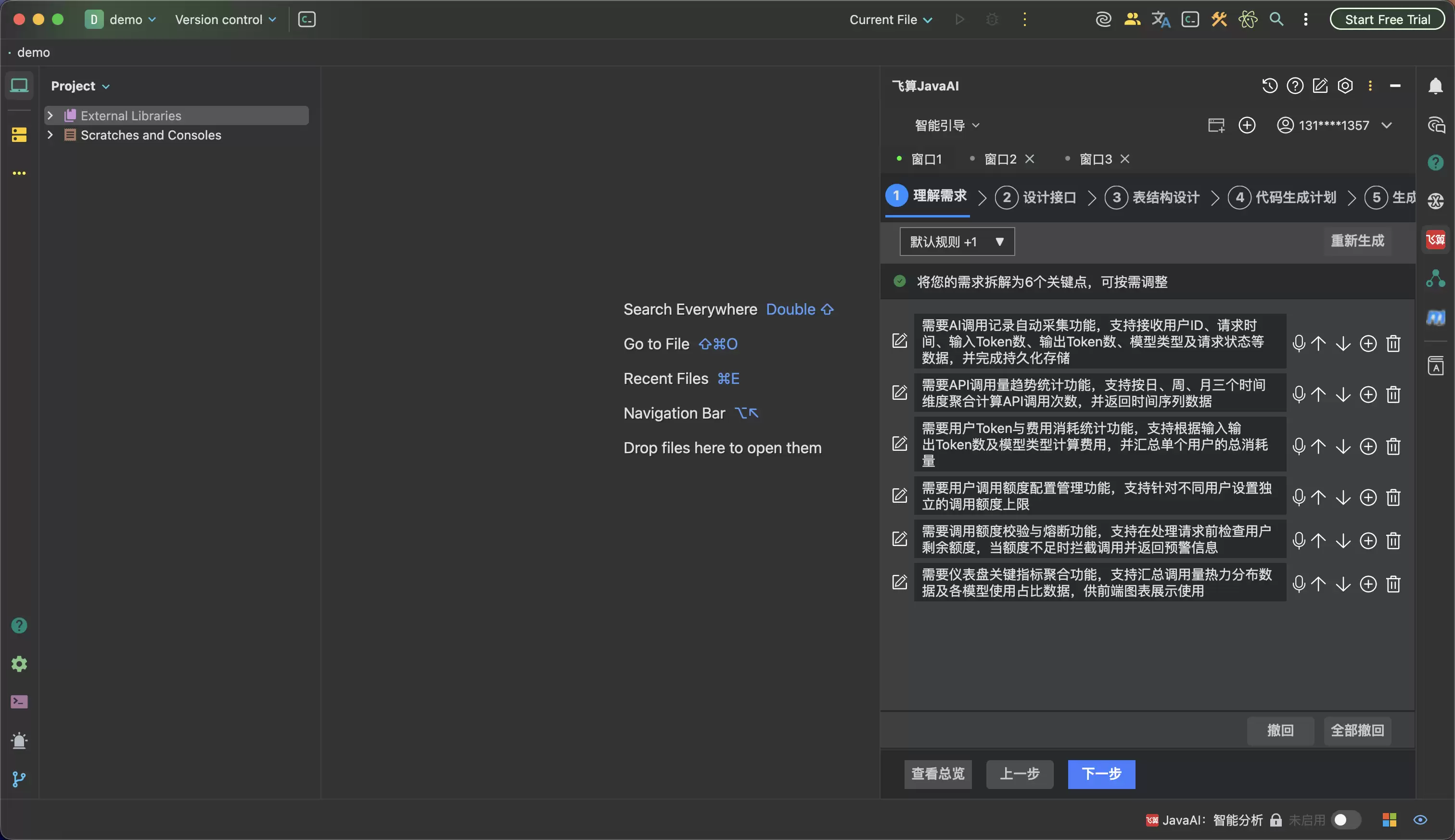
第一步不是写Controller,而是先把需求点拆开。比如任务管理里,AI会先理解“创建任务、分配负责人、设置截止时间、状态流转、超时提醒”这些关键词,再把它们拆成字段、角色、状态、提醒规则和边界条件。开发者可以在这里补充规则,比如“只有创建人和管理员可以改负责人”“已完成任务不能再次进入处理中”“超时提醒只针对未完成任务”。
普通AI编码工具的问题,往往是“快但不可控”。你得到的是一个结果,但你不知道它中间做了哪些判断,也不知道它有没有忽略重要约束。
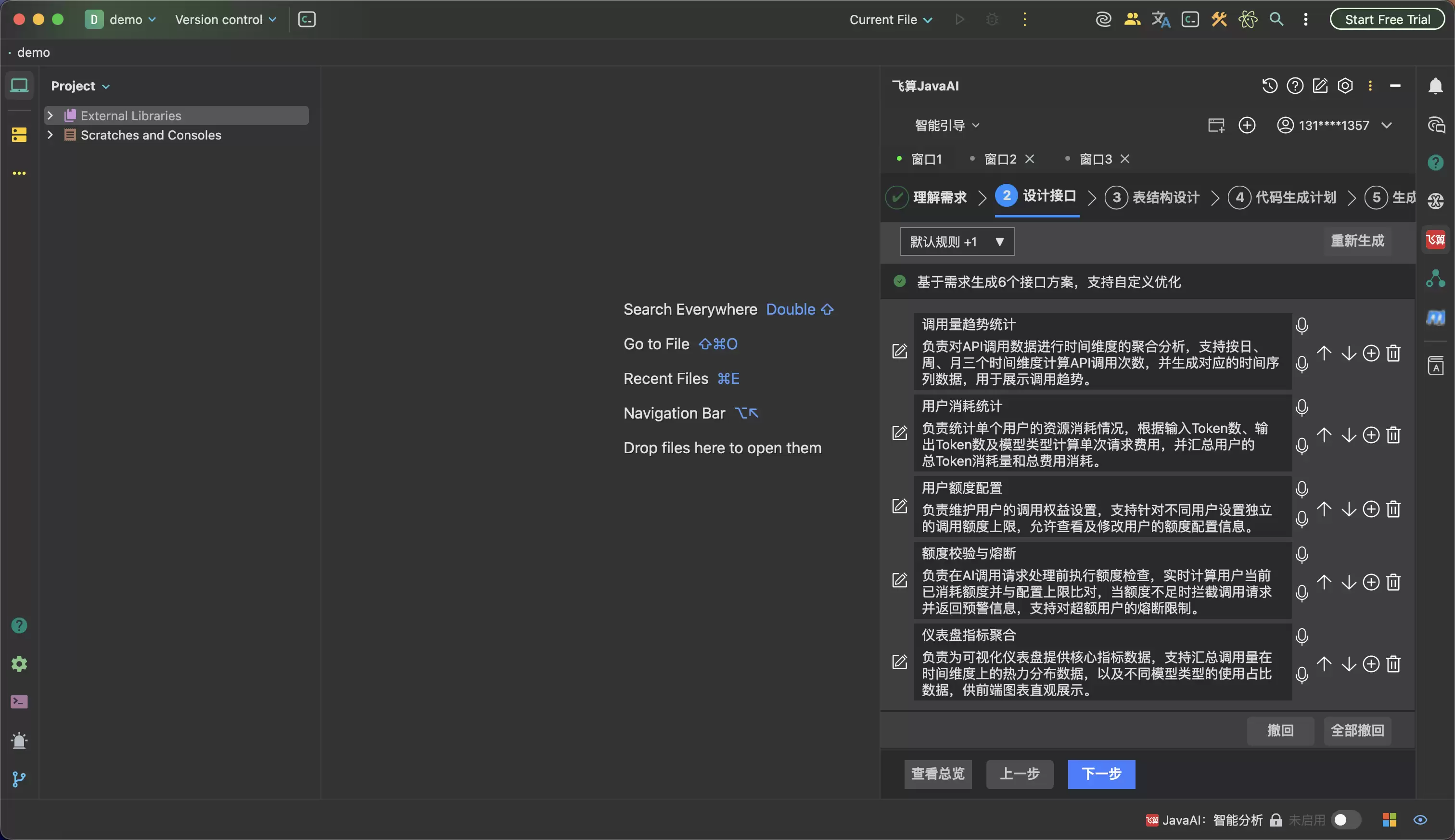
第二步进入接口设计。任务管理不是简单的CRUD,至少要区分创建任务、修改任务、指派负责人、变更状态、查询我的任务、查询逾期任务等接口。这里最有价值的不是AI帮你写出路径,而是它能把接口职责拆清楚,避免一个 updateTask 承包所有动作,最后权限、状态机和日志全混在一起。
一个可交付的Ja va需求,不是从一句话直接跳到代码。它中间至少要经过需求澄清、模块拆分、接口设计、数据结构设计、业务规则确认、源码生成和结果检查。如果这些步骤都没有展开,AI生成得越快,后面返工的概率越高。因为它可能连需求边界都没问清楚,就已经开始写Controller;接口契约还没定,就开始补Service;表结构关系还没确认,就开始猜字段和查询逻辑。
智能引导要解决的正是这个问题。
它不是让开发者把一句模糊需求扔给AI,然后被动等待一个黑箱结果,而是把工程过程拆开:先引导你补充需求背景,再进入接口、数据库、业务逻辑和源码生成等环节。开发者可以在每一步看到AI的理解,也可以及时修正方向。
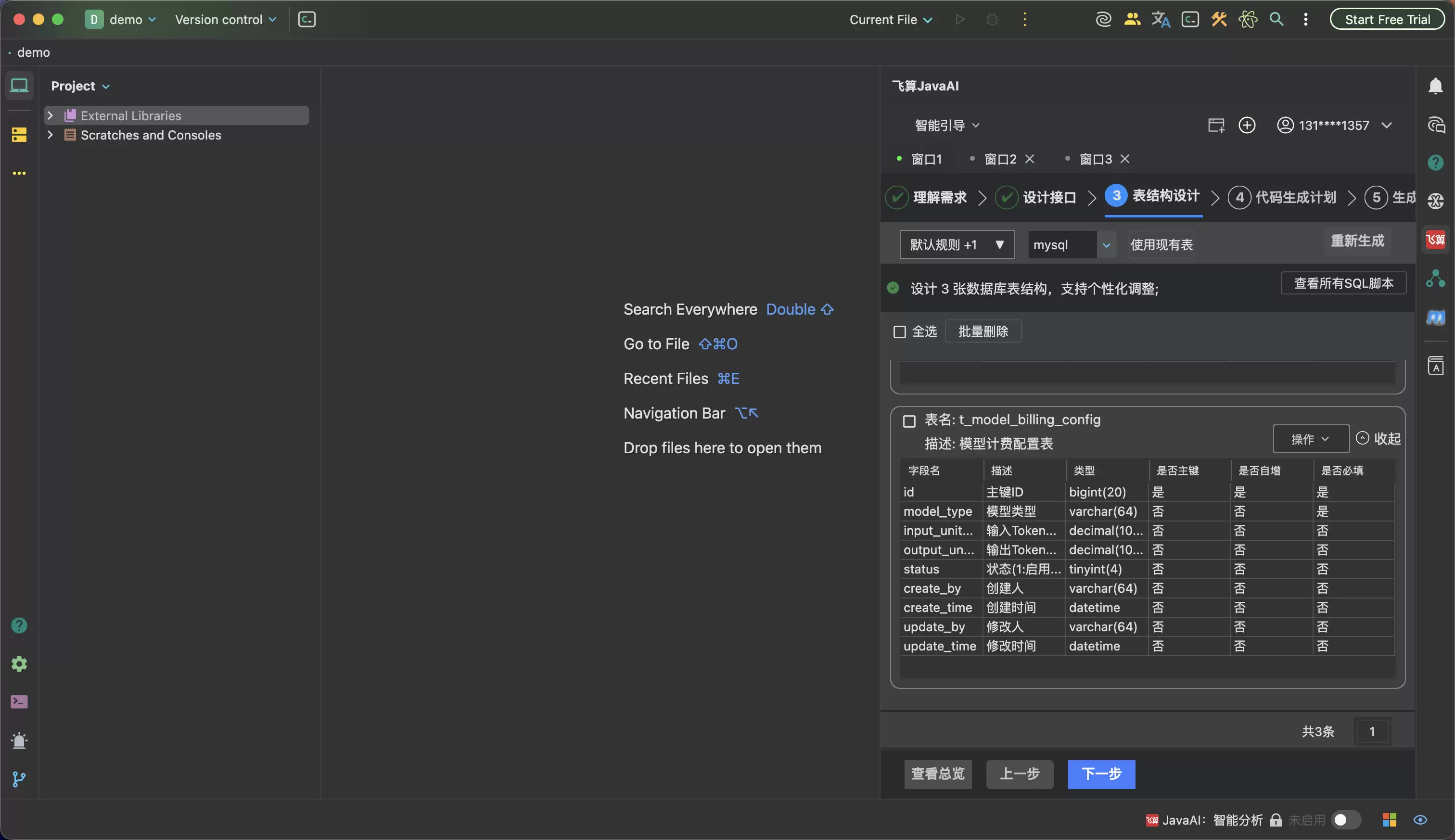
第三步是表结构和业务逻辑。任务管理至少会涉及任务主表、状态字段、负责人字段、截止时间、创建人、更新时间,有些团队还会单独做任务操作日志表和提醒记录表。AI如果先看到这些结构,再去生成业务逻辑,就更容易把状态流转、权限校验、日志记录和提醒规则放到正确的位置。
这个过程看起来比“一键生成”慢一点,但工程上更可靠。因为真正影响交付质量的,往往不是代码能不能生成,而是AI有没有在正确的上下文里生成代码。
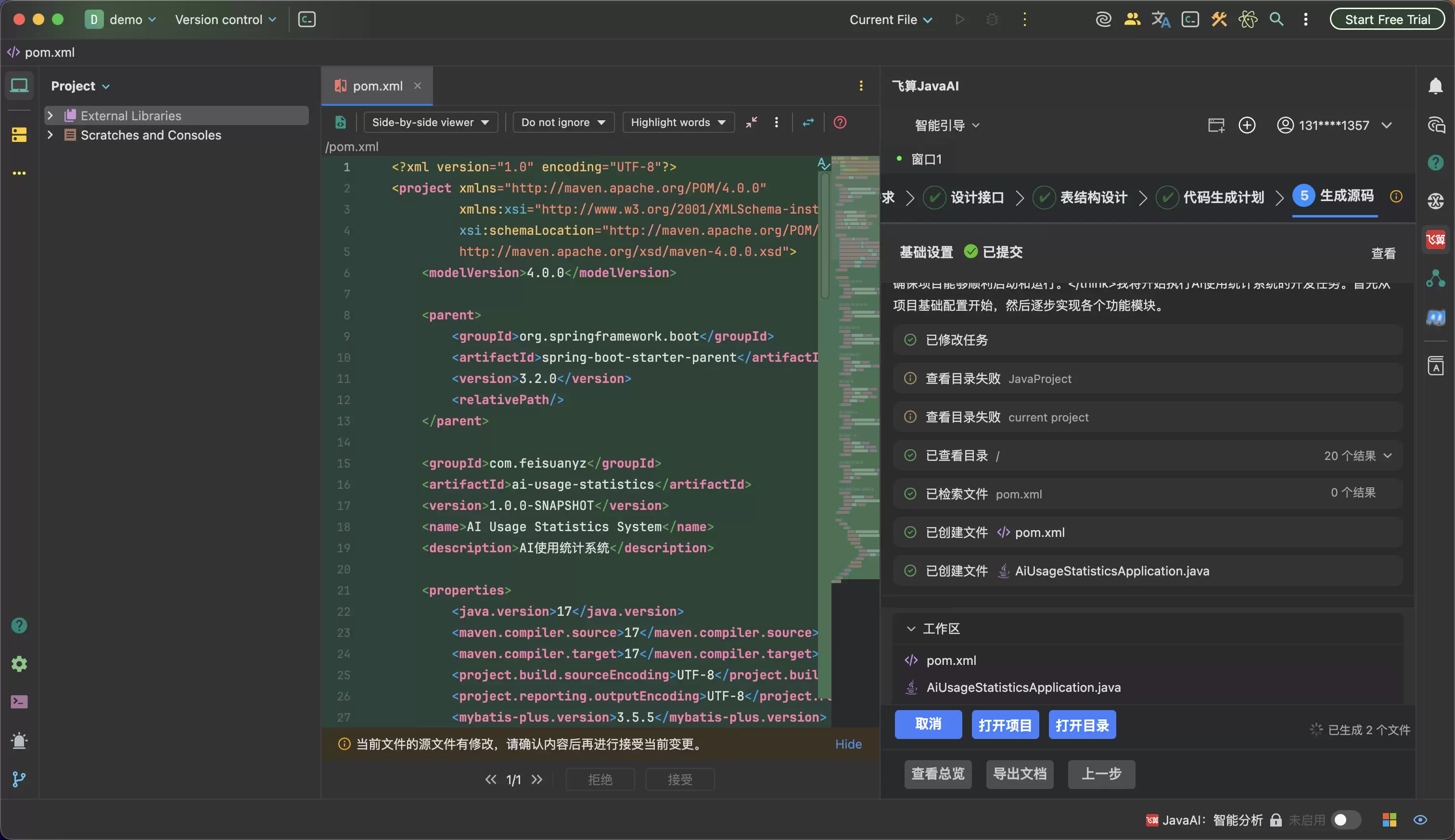
最后再进入源码生成,输出的就不再是一份“看起来像任务管理”的草稿,而是沿着需求、接口、数据结构和业务规则一路推下来的工程结果。开发者Review的重点也从“帮AI补洞”变成“确认这些工程决策是否符合团队要求”。
对团队来说,智能引导还有另一层价值:它可以把团队自己的技术栈选择、业务规则和代码规范沉淀到智能体里。这样AI不只是“会写Ja va”,而是更接近“理解这个团队怎么做Ja va项目”。
五. SQL Chat:让AI理解数据库上下文,而不是只会写SQL
SQL Chat解决的是另一个典型痛点。
很多通用大模型都可以写SQL,但它写出来的SQL往往只是在语法上像那么回事。
它不知道你的本地数据库里有哪些库,哪些表可以查,哪些表不能碰;不知道字段真实含义,不知道主外键关系,不知道哪些字段有索引,也不知道哪些查询会带来性能风险。
更麻烦的是,SQL不是单纯的文本生成问题。
同样一句“查一下最近30天的活跃用户”,不同系统里的口径可能完全不同:活跃是登录算活跃,还是下单算活跃?用户状态要不要过滤?测试账号要不要排除?时间字段用创建时间、更新时间,还是业务发生时间?
如果AI不理解数据库上下文,它只能猜。猜对了是运气,猜错了就可能变成脏数据、慢查询,甚至线上事故。
所以SQL Chat的第一步,不应该是让AI直接写SQL,而是先把它带到正确的数据上下文里。
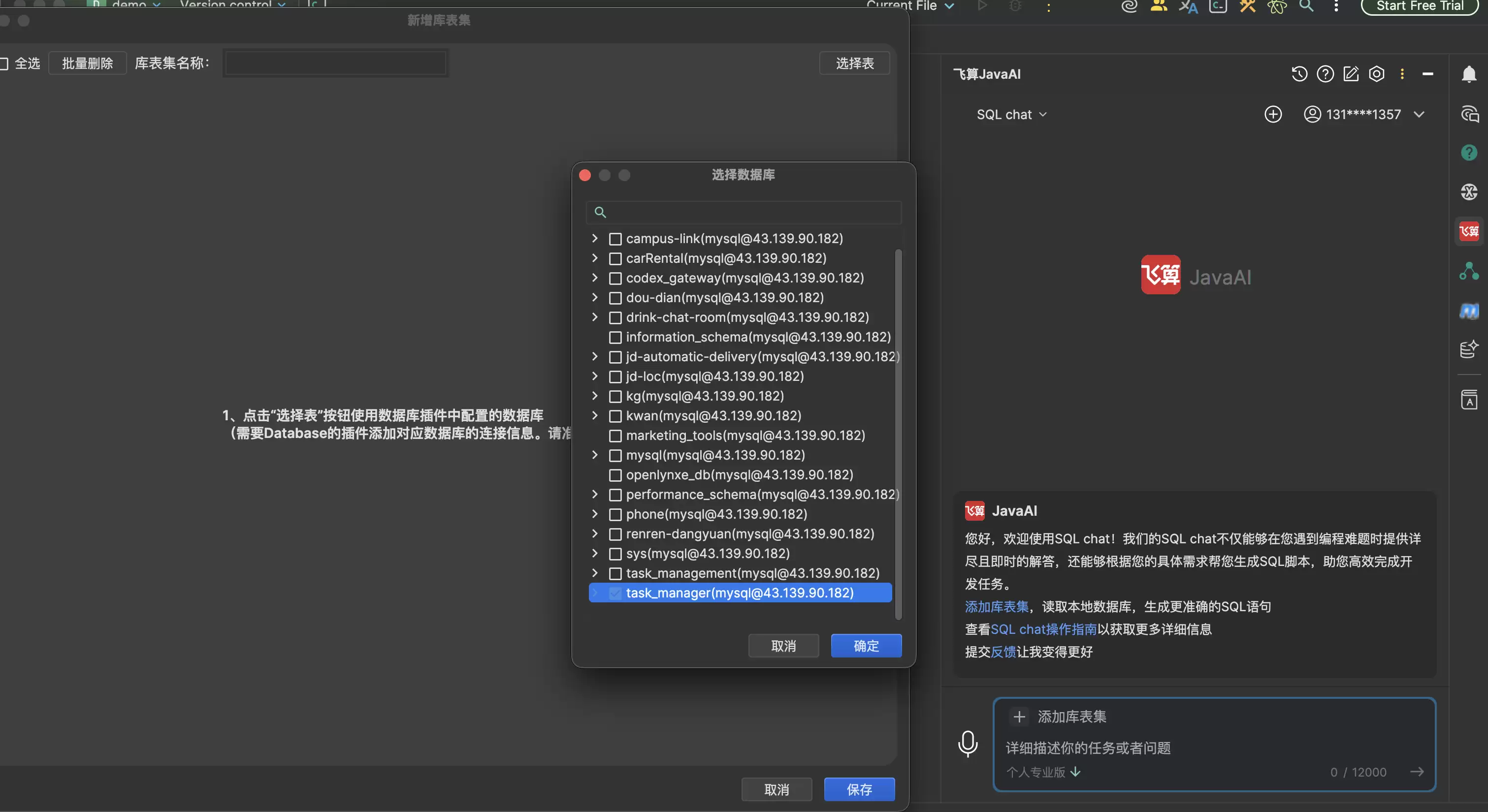
飞算Ja vaAI的SQL Chat通过“库表集”把可查询范围先框出来。开发者可以从本地数据库连接里选择具体数据库和表,把这次会话需要理解的数据对象交给AI。
这个动作很关键。
没有库表集时,AI面对的是一句自然语言问题,只能猜测表名、字段名和业务关系。有了库表集之后,AI面对的是一个明确的数据工作区:哪些表可用、字段是什么、字段类型是什么、哪些字段可能是主键或关联键,都会成为后续生成SQL的上下文。
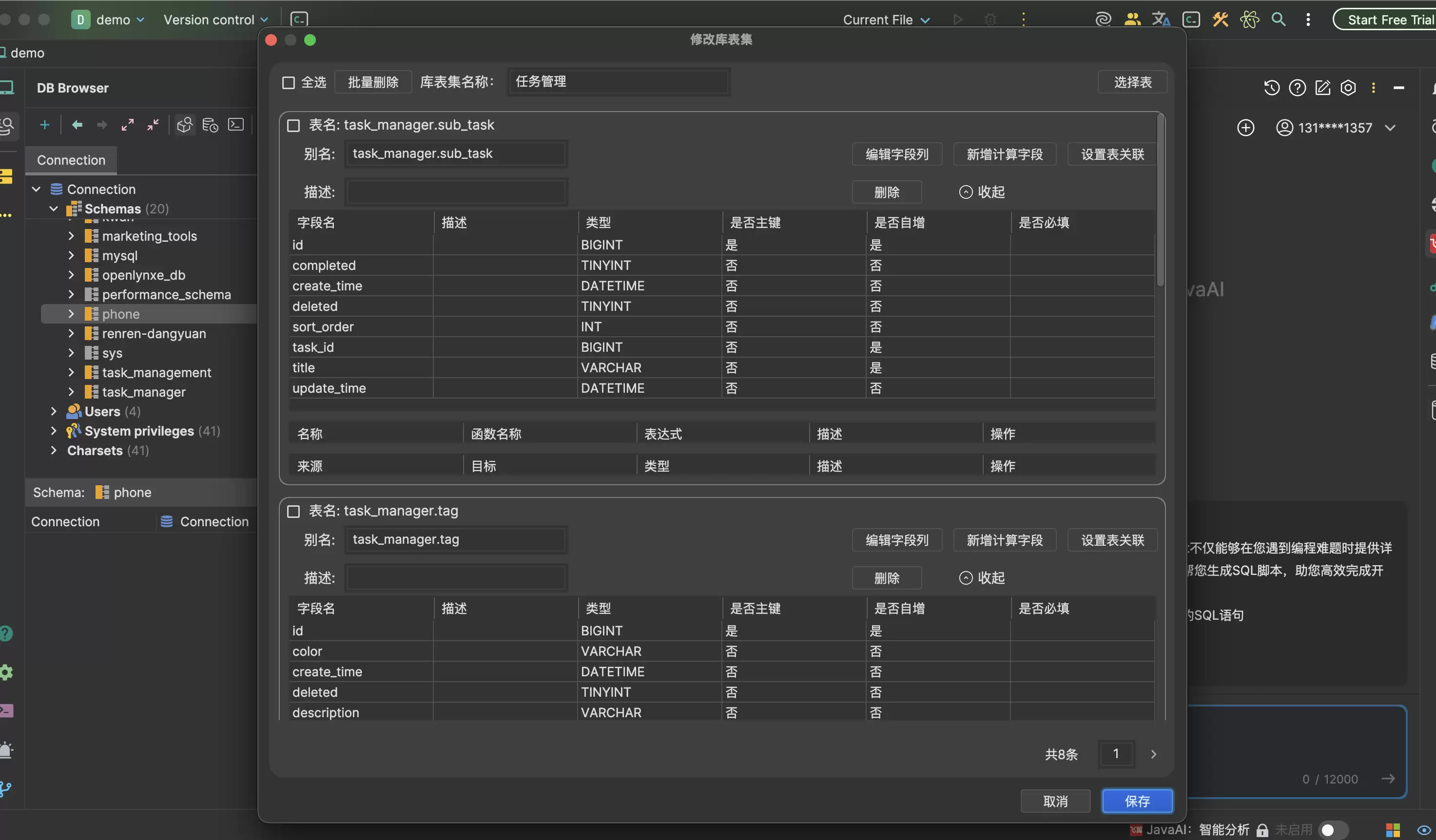
这就把SQL Chat和普通“帮我写一条SQL”的提示词区分开了。
普通大模型写SQL,很多时候是在“凭经验补全”。它可能觉得用户表应该叫 user,订单表应该叫 orders,状态字段应该叫 status。但真实项目里,表名可能带业务前缀,字段名可能来自历史系统,逻辑删除字段可能叫 deleted、is_deleted、del_flag,时间字段也可能分成创建时间、更新时间、业务发生时间。
这些差异不是语法问题,而是项目上下文问题。
SQL Chat的价值,是让AI先读到这些上下文,再回答问题。
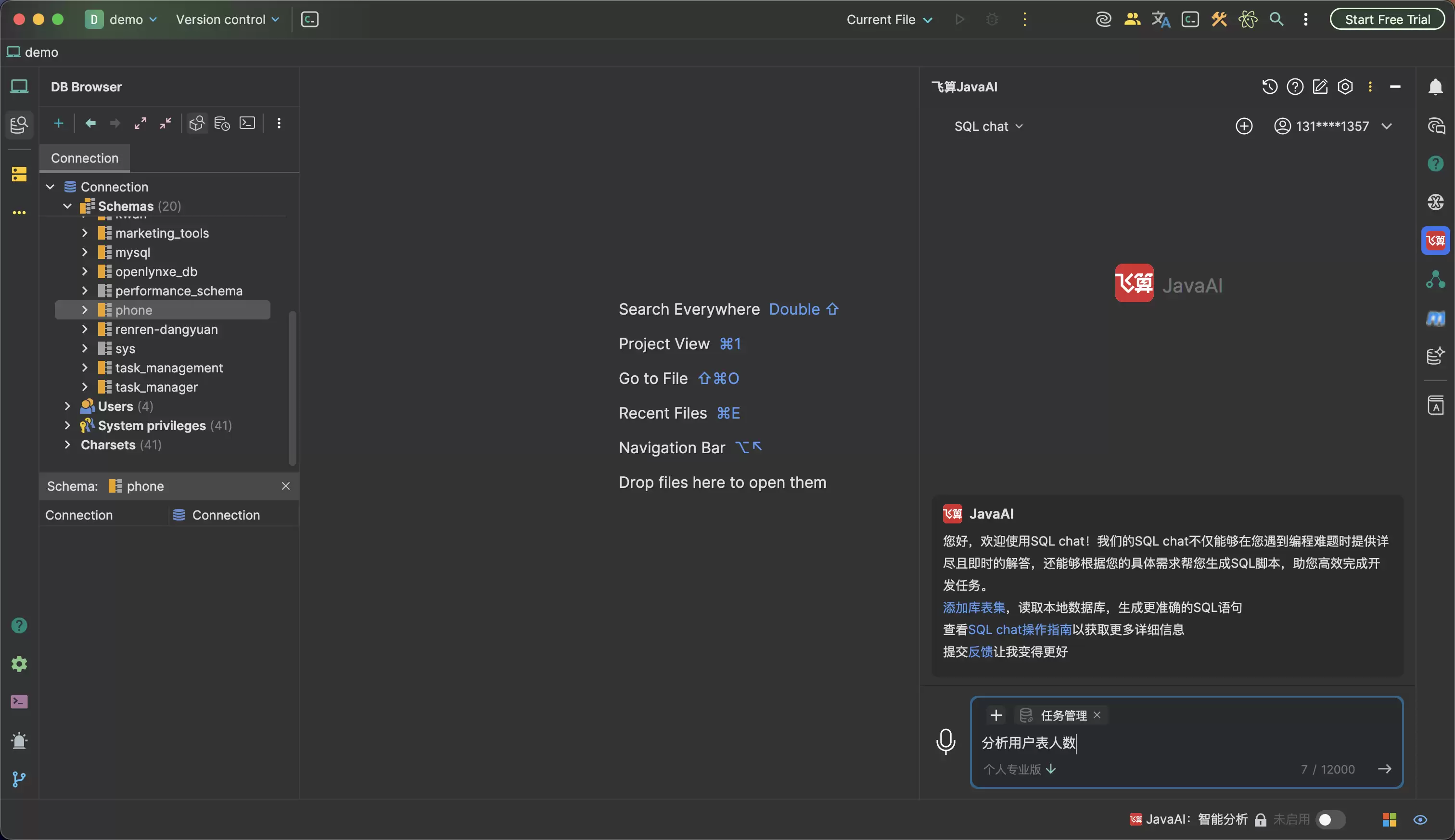
开发者可以直接用自然语言描述目标,比如“分析用户表人数”“统计某张表的行数”“按时间维度看趋势”。真正有价值的地方不只是把这句话翻译成 SELECT,而是AI要能判断这个问题对应哪张表、该用什么聚合方式、是否需要过滤条件,以及生成的SQL是否和用户意图一致。
比如统计用户数量,看起来是一句很简单的查询。
但工程里仍然有很多细节:是不是只统计未删除用户?要不要排除测试账号?是否只统计启用状态?如果用户只问“总人数”,是否应该先返回全量 COUNT(*),还是按照业务习惯追加过滤条件?
一个合格的SQL Chat,不应该悄悄替开发者做不可见的业务假设。它更应该把自己的判断摊开:我理解你的需求是什么,我选择了哪张表,为什么用这个聚合函数,是否需要过滤条件,最终生成的SQL是什么。
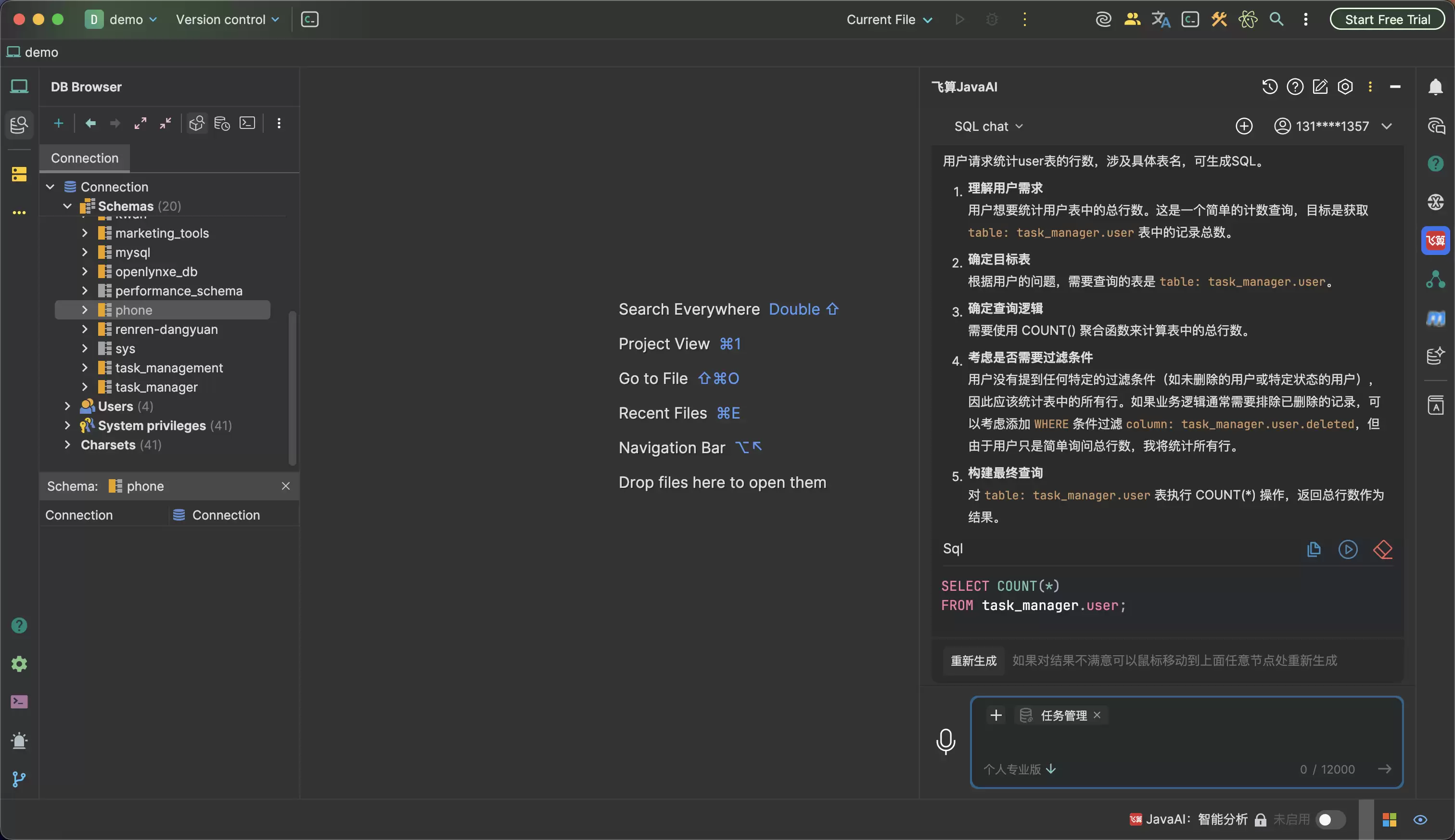
这也是为什么“解释”比“生成”更重要。
如果AI只给一条SQL,开发者还要反过来检查它有没有查错表、漏掉条件、误用字段。这样SQL Chat只是把手写SQL的工作换成了审核SQL的工作,效率提升有限。
但如果AI能同时给出需求理解、目标表、查询逻辑、过滤条件判断和最终SQL,开发者就可以快速判断这条SQL是否可信。
对于日常Ja va开发来说,这类能力会覆盖很多高频场景:
- 临时查数:快速统计用户量、订单量、任务量、调用量。
- 口径验证:确认某个指标到底来自哪张表、哪个字段、哪种过滤条件。
- 问题排查:根据异常现象快速定位相关数据,而不是在几十张表里手动翻。
- 报表辅助:把自然语言统计需求转成聚合查询,再由开发者确认口径。
- 风险提醒:在生成SQL时提示全表扫描、字段缺索引、模糊查询和注入风险。
这类场景单个看都不复杂,但它们会大量消耗开发者时间。尤其是在陌生系统、历史项目、多表关系复杂的场景里,真正耗时的不是写出 SELECT,而是搞清楚“应该查什么、从哪里查、按什么口径查”。
所以SQL Chat的关键不只是“把自然语言转成SQL”,而是结合本地数据库上下文来生成可执行、可解释、可检查的SQL。
当AI能看懂表结构、字段含义、表关系和索引情况,再把自然语言转成查询语句,并附带逻辑解释、索引建议和防注入提醒时,它才真正从“SQL语法助手”往“数据库工程助手”靠近。
六. AI编程的分水岭,是从“生成代码”走向“交付工程”
现在,评价AI编程工具的标准越来越清晰,不能只看它能不能生成代码。
真正应该问的是:
- 它生成的东西能不能进入团队Review?
- 它能不能理解项目上下文,而不是只理解语法?
- 它有没有把需求、接口、数据库、业务逻辑、安全、测试和文档串起来?
- 它能不能暴露过程,而不是只给一个黑箱结果?
- 它能不能适配团队规范,而不是每次都生成一套“通用但水土不服”的代码?
- 它能不能减少人工兜底,而不是制造更多清理工作?
如果一个AI工具只是快,那它可能只是更快地制造混乱。
如果一个AI工具能把复杂Ja va工程拆成透明、可介入、可Review的协作流程,那它才真正有机会成为开发团队的生产力。
高级工程师真正需要的不是一个永远需要人收拾残局的AI实习生,而是一组能协同工作的AI专家。

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
免费影视剧APP推荐
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
抖音最火沙雕男生网名(精选100个)
-
短剧《情绪超市》剧情介绍
-
短视频软件推荐
-
免费看电影的软件推荐
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
网络热词聊污是什么意思
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
KuCoin基本面分析
-
洛克王国世界S2赛季狂欢怪谈介绍
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
2 谷歌警告:黑客首次利用 AI 开发 “零日” 漏洞攻击工具 06-08
-
3 AI狂欢要散场了吗 06-09
-
4 阿里通义千问1.8B超迷你大模型,5年前的老电脑也可以玩 06-09
-
5 2024年AI 生成内容(AIGC)综合指南 06-09
-
6 OpenAI视频大模型Sora原理解读 06-09
-
7 OpenClaw 从新手到中级完整教程 06-09
-
8 Docker安装OpenClaw大龙虾的详细步骤 06-09
-
10 AI Agent 沙箱选型指南:五种隔离架构,你的场景该选哪个? 06-09



