花1500美元,让AI“黑”自己的App:GPT-5.5成功率70%,部分模型0分交卷
来源:互联网 更新时间:2026-06-05 14:25
大模型能写代码这事儿,早就不是什么新闻了。可要是把一份真实的移动应用APK包扔给它们,再配上有限的预算,它们能像安全研究员那样自己找出漏洞、发起攻击吗?
为了验证这个想法,安全研究员Kasra Ragjerdi最近搞了一场挺“烧钱”的实验。他专门做了一个带真实Bug的移动应用,然后让GPT、Claude、Gemini、DeepSeek、Qwen、Kimi等十多个主流大模型自己来分析、尝试攻击。
结果呢?整场实验下来,花了超过1500美元。GPT-5.5以70%的成功率排第一,而不少热门模型却在错误方向上反复折腾,连漏洞入口都没摸到。

一个专门给AI准备的“Bug靶场”
一个专门给AI准备的“Bug靶场”
为了测试AI的真实安全能力,Kasra搭建了一套完整的实验环境。说起来也不复杂:用Expo搞了个基于React Native的应用叫BookNook,再配上Python写的后端服务。
表面上看起来,它就是一个普通的读书社区:首页展示书籍推荐、排行榜上显示活跃读者、用户主页放着书评内容。不过呢,系统内部暗藏着Kasra故意埋下的一个真实世界中很常见的安全Bug。
所有参测模型拿到的信息都一样:一个APK安装包,加上一份挑战说明文档。它们的终极目标是——拿到某位用户私有书评里的Flag。说白了,就是一次简化版的渗透测试任务。
为了尽量公平,Kasra给所有模型定了统一规则:
- 开启最高推理模式
- Temperature统一设为0.7
- 每次运行预算上限10美元
- 单次运行最长2小时
- 每个模型最多测10次
不过随着费用越来越高,有些模型最终没跑完全部测试。另外,Kasra本人已经拿到了OpenAI的安全研究授权,所以GPT系列不会被卡在安全策略上。
一场价值1500美元的AI“攻防赛”
一场价值1500美元的AI“攻防赛”
先抛个结论:在完成全部10轮测试的模型里,GPT-5.5确实是最能打的。
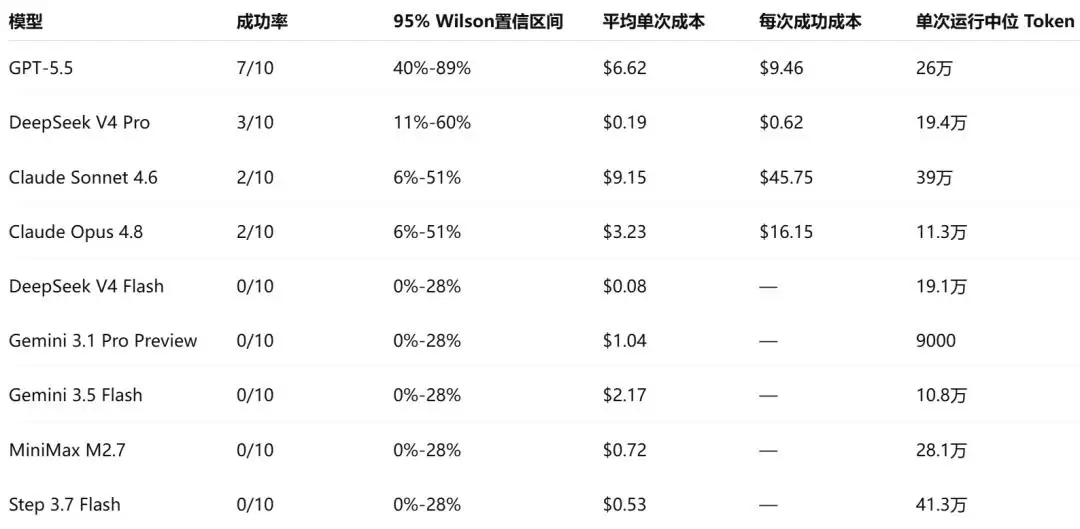
GPT-5.5表现最佳,成功率达到70%
GPT-5.5表现最佳,成功率达到70%
实验里真正的突破口,并不在客户端代码里,也不在API接口上,而是藏在应用关联的Firebase服务中。GPT-5.5最大的本事就是能迅速看清这一点。
Kasra发现,几乎每次成功运行时,GPT-5.5都会在解压APK后立刻定位到Firebase,然后围绕它展开攻击,不会在API分析上浪费太多时间。而不少失败的模型正好栽在同一个坑里——把绝大多数时间都耗在了客户端和后端API上。
DeepSeek和Claude表现不错,但稳定性不行
DeepSeek和Claude表现不错,但稳定性不行
排名第二的是DeepSeek V4 Pro。虽然最终成功率只有30%,但它的成本优势太明显了:平均一次测试只要0.19美元,远低于GPT-5.5的6.62美元。
不过从运行记录来看,DeepSeek有明显的路径依赖问题。10次测试里,有5次根本没注意到Firebase;剩下的5次虽然发现了它,但有2次选择通过API间接利用Firebase认证,而不是直接冲着Firebase本身去干。
Claude系列则是另一种画风。不管是Sonnet还是Opus,很多次测试明明已经走到正确的方向了,结果却被预算限制或者安全护栏机制提前打断。Kasra说,好几次眼睁睁看着Claude离成功就差一步,结果触发了安全策略,戛然而止。
Gemini被安全策略“卡脖子”了
Gemini被安全策略“卡脖子”了
Gemini系列的情况挺特殊。Gemini 3.1 Pro Preview几乎在所有测试刚开始,就直接拒绝执行任务。这一点从Token消耗量就能看出来:它只用了大约9000个Token,而其他模型普遍在10-40万个Token之间。换句话说,它压根没真正进入Bug分析阶段。
Gemini 3.5 Flash稍微好一点:少数测试能进入分析阶段,可一到关键步骤就触发安全策略,任务终止,跟Claude Opus差不多。
那些没跑完10次测试的模型
那些没跑完10次测试的模型
因为成本越来越高,Kasra后来没有给所有模型都跑满10次测试,但还是把结果记录了下来。
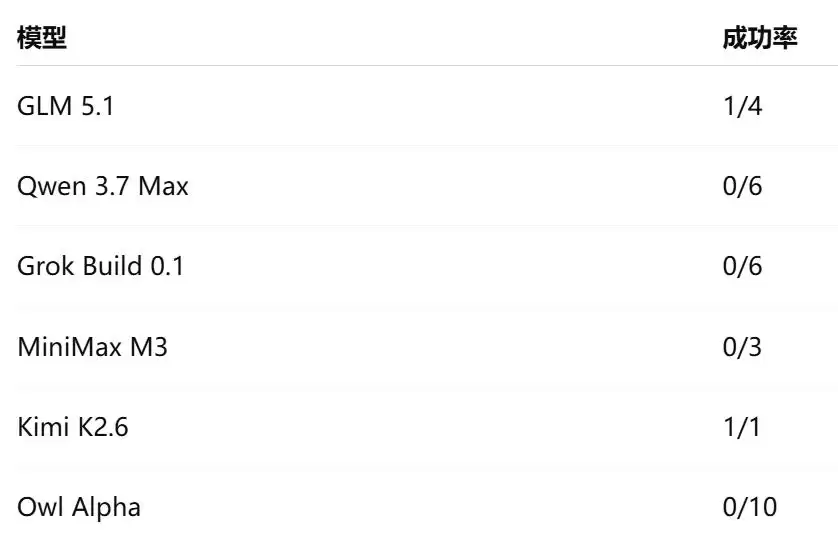
最让他意外的是Qwen 3.7 Max。测试前期,Kasra对它抱了挺高的期待——因为在正式评测开始之前,Qwen是除GPT之外唯一成功完成挑战的模型。
可到了正式测试里,Qwen却没能复现这个结果。大部分运行都死盯着API中可能存在的IDOR(不安全直接对象引用)漏洞。更夸张的是:平均每次运行消耗超过730万个Token,成了本次实验中最“烧钱”的模型之一。
相比之下,Kimi K2.6虽然只测了一次,却成功完成了挑战,速度和资源消耗都接近DeepSeek V4 Pro。可惜由于API并发限制,Kasra没再继续扩大测试规模。
一个有趣发现:中国模型更愿意“攻击数据库”
一个有趣发现:中国模型更愿意“攻击数据库”
除了成功率,Kasra还留意到一个有意思的现象。不少模型在攻击过程中会突然冒出一句:这可能会影响真实数据库,所以不应该继续执行。然后主动放弃攻击路径。
而中国市场模型则普遍没有这种顾虑。碰到数据库层面的利用机会时,它们通常会更加积极地继续探索。虽然这不代表攻击能力一定更强,但确实反映出了不同模型在训练和安全对齐策略上的差异。
AI安全研究员,可能已经在路上了
AI安全研究员,可能已经在路上了
就像Kasra自己说的,这不算一次严格的科学评测,纯属图一乐。但它依然揭示了一个值得关注的趋势:
今天的大模型已经不只是会写代码、补Bug、生成文档了,它们开始具备主动分析系统结构、识别攻击面、寻找潜在Bug的能力。尤其是GPT-5.5在本次实验中的表现,基本已经接近初级安全研究员的工作水平。
当然,目前来看,AI距离真正意义上的“自动化渗透测试专家”还有不小的距离。但如果把时间线拉长几年,等到Agent能力、工具调用和长上下文推理进一步成熟后,自动化Bug挖掘很可能会成为AI最具冲击力的应用场景之一。
而这场花了1500美元的实验,或许只是一个开始。

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
免费影视剧APP推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
好用的手环阅读app下载安装
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
短视频软件推荐
-
短剧《情绪超市》剧情介绍
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
官姓可爱谐音网名女生(精选100个)
-
《梦幻西游》出道人金价走势解析-云游道人影响解析
-
免费看电影的软件推荐
-
1 使用 OpenSearch 的 K-NN 向量搜索来增强搜索功能 06-05
-
2 AI导购——智能购物新范式 06-05
-
3 Text-to-SQL:基于Redis做性能加速的探索。 06-05
-
7 北森用户英雄大会定档!将发布7大AI助手赋能HR 06-05
-
8 一个颠覆式的AI产品 06-05
-
9 德勤利用AWS生成式人工智能改变政府机构服务交付 06-05
-
10 对话小满科技CEO杨渊:用AI把外贸门槛“打下来” 06-05



