基于OpenClaw的Flink作业智能运维实践指南
来源:互联网 更新时间:2026-06-04 14:21
导读:Flink 作为实时计算领域的事实标准,其作业运维长期以来面临着链路分散、依赖个人经验、恢复效果难以验证等一系列挑战。实时未来技术团队在服务客户的过程中,屡屡遇到这些痛点,并最终基于 OpenClaw 构建了一套可协同、可追溯、可落地的智能运维平台。本文将结合实践中的经验,对平台的设计思路、关键原则和落地链路进行一次系统性梳理。
Flink 作业运维的现实困境
Flink 发展到现在这个阶段,已经是实时计算领域绕不开的技术底座了。实时数仓、实时风控、实时推荐这些核心场景,底层几乎清一色都跑在 Flink 上。
但现实是,这些实时计算场景的运维,大部分还停留在“人肉”模式。Checkpoint 失败或超时、反压导致的数据延迟、资源争抢与容器重启、状态兼容性问题导致作业恢复失败……这些可以说是值班人员的“家常便饭”。每次故障排查,都得在平台、日志、监控、资源等多个系统之间来回切换,结果好坏严重依赖个人经验,而且很难量化验证问题是否真的解决了。
在运营 Apache StreamPark 社区和服务客户的过程中,我们观察到的一个普遍现象是:很多团队其实并不缺监控、日志、脚本和平台能力,真正缺的,是一条能把“接警 - 判断 - 执行 - 核验”串起来的稳定复用链路。工具很多,但状态、日志、监控、动作执行这些功能分散在不同的入口,值班人员不得不在多个系统间反复切换,信息收集成本高,关键证据也容易遗漏。
OpenClaw 切入点
2024 到 2025 年,AI Agent 技术开始从概念验证走向生产落地。OpenAI Operator、Anthropic Computer Use,以及开源社区里的 OpenClaw 和 AutoGPT,它们都在做同一件事:让 Agent 不仅能理解问题,还能调用工具、执行动作、完成闭环。趋势很明显,已经从“对话式 AI”转向了“行动式 AI”。
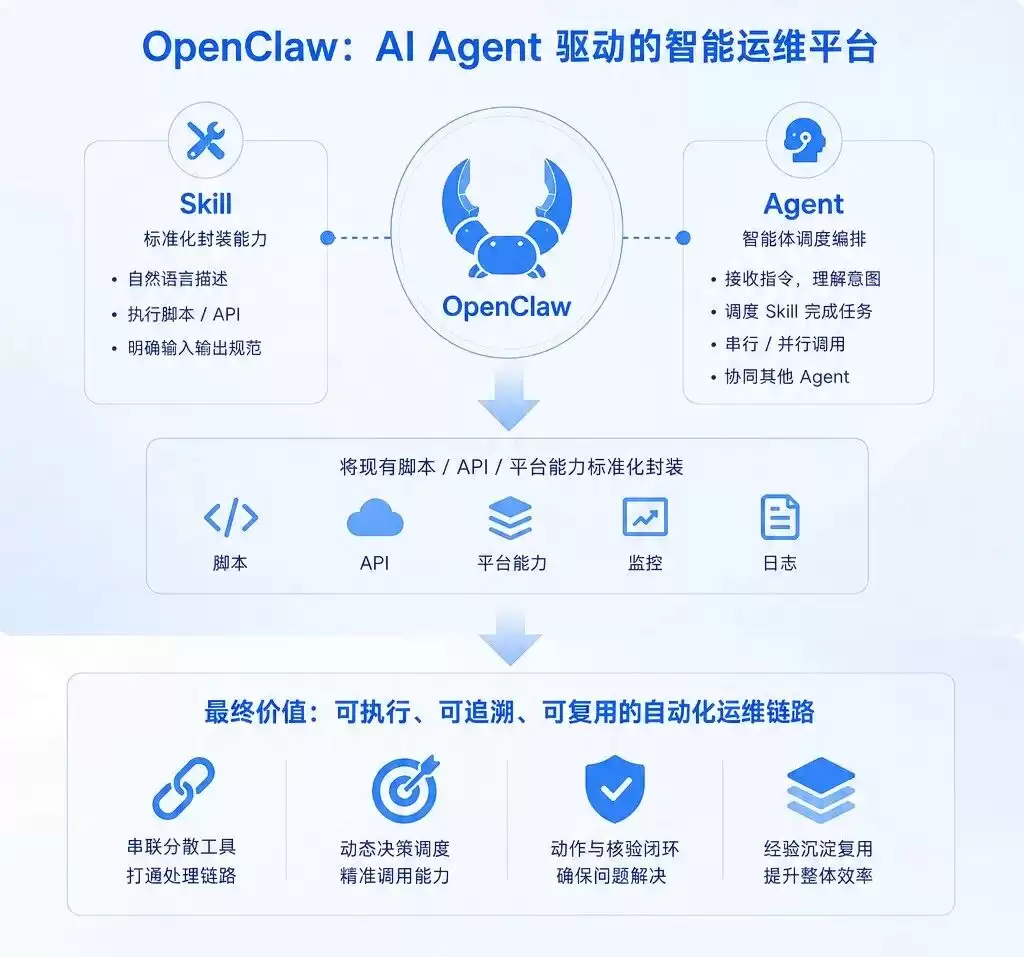
我们最终选中的框架是 OpenClaw。它的定位是 AI Agent 的构建与编排平台,核心概念其实就两个:
- :对某项具体能力的标准化封装。比如查询 Flink 任务状态、检索日志、执行重启动作。每个 Skill 都包含一段自然语言描述(让 Agent 理解什么时候该用它)、具体的执行脚本或 API 调用,以及明确的输入输出规范。
Skill
- :负责接收用户指令、理解意图、调度 Skill 来完成复杂任务的智能体。一个 Agent 可以串行或并行调用多个 Skill,也可以把子任务分发给其他 Agent 协同处理。
Agent
OpenClaw 的思路非常清晰:把企业已有的脚本、API、平台能力,通过 Skill 标准化封装起来,再由 Agent 按需编排调用,最终形成可执行、可追溯、可复用的自动化链路。和传统的静态工作流引擎不同,OpenClaw 更擅长处理需要动态决策的复杂任务:Agent 会根据上下文实时选择调用哪些 Skill,而不是走固定分支。这一点,恰好打中了 Flink 运维的痛点:工具都有,但缺一条能把工具串起来、还能智能调度它们的链路层。
评估了一圈下来,发现 OpenClaw 这套机制和 Flink 运维场景的匹配度非常高,于是决定基于它构建实时计算智能运维能力。这里并没有去造什么新轮子,做的事情就是把现有能力重新组织起来,从一堆零散的工具升级为一套协同运维系统。
确定可执行的核心链路
先看看大家普遍面临的运维现状。报警一来,值班人员的操作路径大概是这样:切换到平台看任务状态 → 切换到日志系统翻异常栈 → 切换到监控面板看 Lag 和 Checkpoint 指标 → 切换到资源侧确认队列和节点状态 → 必要时再切换到发布平台执行重启 → 最后人工核验恢复情况。
每一步单独看都不复杂,但连在一起就暴露了三个核心问题:
第一,链路是散的。
第二,经验依赖重。
第三,恢复不可证。
这三个问题的根因其实都一样:缺少一条能把分散能力串成闭环的链路层。这就是我们用 OpenClaw 改造 Flink 运维的出发点。
问题明确之后,下一步是定边界。策略很简单:先把最核心的处理闭环收拢,功能可以后续再堆,但闭环必须先跑通。
核心需要覆盖的五个能力:

目标很明确,要的是“链路闭环”,不是“功能多”。五条核心链路跑通了,后面加能力就是顺水推舟的事。反过来,如果闭环本身不稳,功能堆得越多,系统反而越脆弱。
架构设计:资产盘点、角色拆分与 Skill 组织
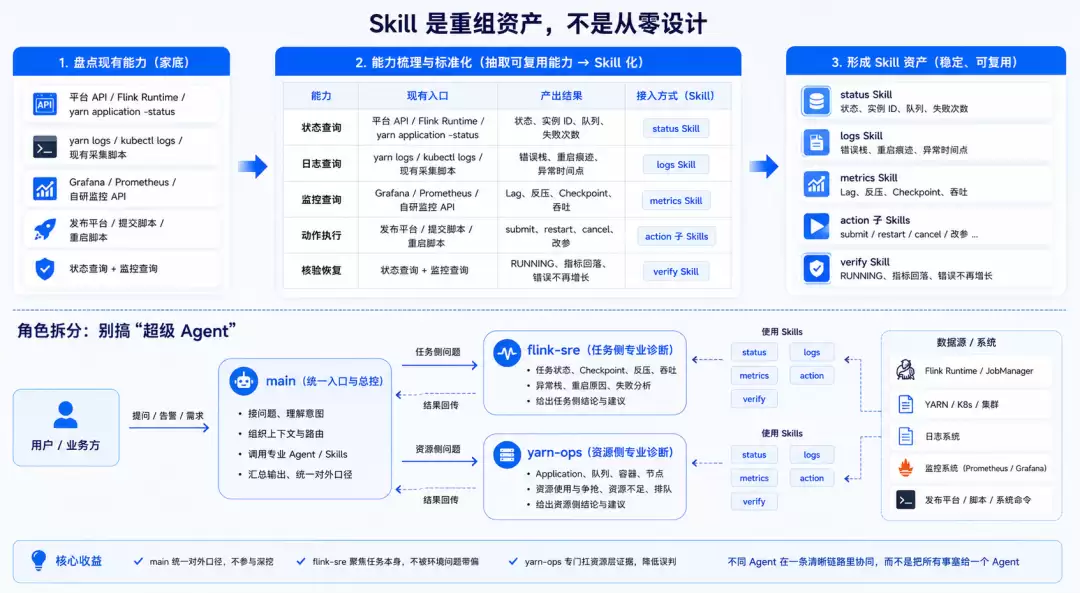
边界定了,下一步是盘点家底。
很多团队上来就先设计 Skill、定义 Agent、搭架构。但更务实的顺序应该是倒过来的:先搞清楚手上有什么。Skill 不是凭空创造能力,它的本质是把原本散落在平台、脚本、监控和系统命令里的能力,重新编排成一套稳定的流程。
Skill 是重组资产,不是从零设计
我们梳理出来的能力矩阵大概是这个样子:
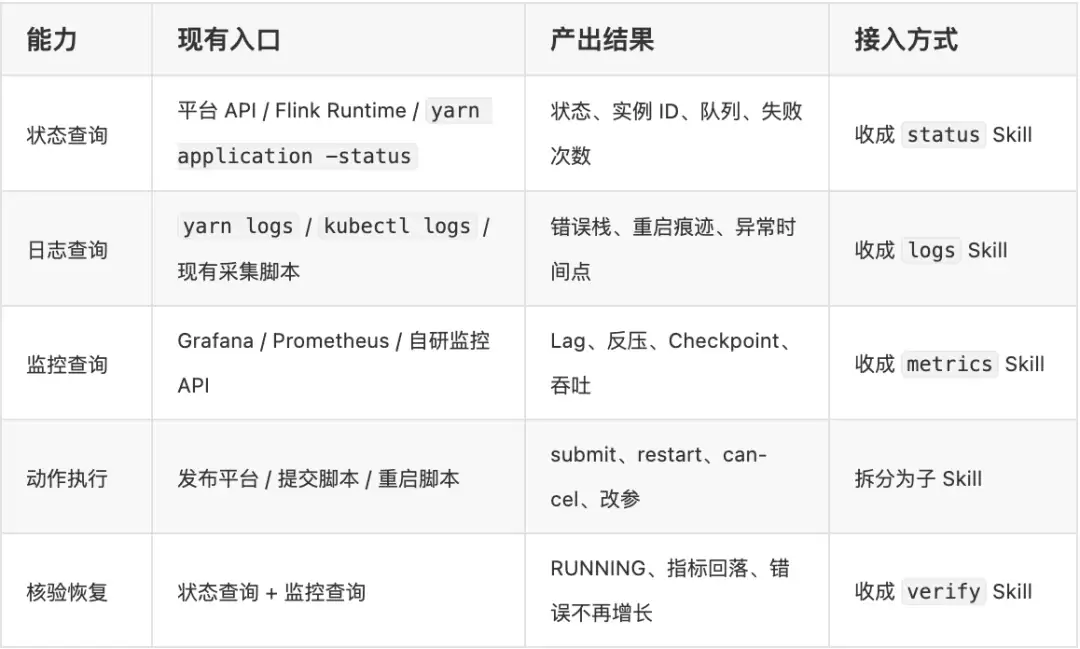
这一步看着朴素,但它决定了平台能不能真正落地。如果现有能力本身字段不统一、输出格式不稳定、接口契约不清晰,那么 Skill 设计得再漂亮也只是另一层脆弱的封装。所以接入前的标准化——字段统一、输出格式化、超时和重试策略——往往比 Skill 开发本身更关键。
角色拆分:别搞“超级 Agent”
Skill 盘点清楚了,下一个问题:谁来调用它们?我们踩的第一个坑,就是把所有能力塞进一个 main 入口,既要又要还要。短期看着省事,但日志、监控、动作执行、审批、资源排查一接入,主入口迅速膨胀,最后变成一个什么都做、什么都不稳的“超级 Agent”。
调整后的做法很简单:从第一天就拆角色。最小配置两个:
- :统一入口与总控
main
- :任务侧专业诊断
flink-sre
- :资源侧专业诊断
yarn-ops
推荐的分工如下:
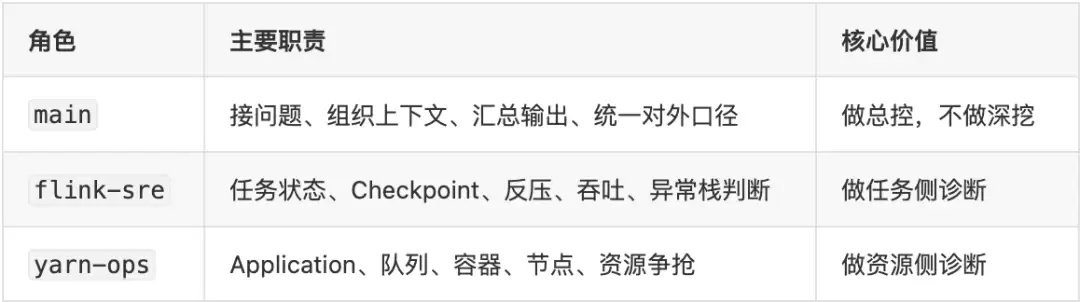
拆完之后收益很直接:main 统一对外口径,不参与深挖;flink-sre 聚焦任务本身,不被环境问题带偏;yarn-ops 专门扛资源层证据,降低误判。一句话:不同 Agent 在一条清晰链路里协同,而不是把所有事塞给一个 Agent。
Skill 组织原则:边界比完整更重要
角色定了,每个角色下面的 Skill 怎么组织?一个能长期维护的 Skill 体系,不是一个大而全的目录,而是一组有边界、有层次的能力包。
我们实际落地的目录结构如下:
skills/
├── flink-ops/ ← 主 Skill:只读诊断
│ ├── SKILL.md ← Skill 定义入口(触发条件、处理顺序、禁止动作)
│ ├── scripts/
│ │ ├── status.sh ← 状态查询
│ │ ├── logs.sh ← 日志检索
│ │ ├── metrics.sh ← 监控查询
│ │ └── verify.sh ← 恢复核验
│ └── references/
│ ├── sop.md ← 标准处理流程
│ └── error-codes.md ← 常见错误码对照
├── flink-ops-submit/ ← 子 Skill:提交与取消
│ ├── SKILL.md
│ └── scripts/
│ ├── submit.sh
│ └── cancel.sh
├── flink-ops-restart/ ← 子 Skill:重启与改参
│ ├── SKILL.md
│ └── scripts/
│ ├── restart.sh
│ └── modify_and_restart.sh
└── yarn-ops/ ← 侧边 Skill:YARN 资源诊断
├── SKILL.md
└── scripts/
├── app_status.sh
├── logs.sh
└── queue_status.sh
这套结构背后的设计原则只有一个:
只读能力归主 Skill,变更能力拆成子 Skill,环境能力独立成侧边 Skill
逻辑很简单:status、logs、metrics、verify 是高频、稳定、可复用的只读能力,放主 Skill 统一维护没问题;submit、restart、cancel 带风险,涉及审批、回滚、责任界定,不能跟只读的混一起;YARN 资源问题和 Flink 作业问题根本不在一个层面,强耦合只会让判断失焦。
要不要拆一个 Skill,标准就一句话:
输入不同、风险不同、验收不同,就别硬塞进同一个 Skill
落地标准:SKILL.md 和脚本契约
目录定了,Skill 内容怎么写?
前期我们也花了不少精力罗列命令、补背景、写说明。跑了一段时间后才意识到,运维场景下 SKILL.md 最核心的价值是
定序
SKILL.md 最重要的是确定顺序
一个能落地的 Skill,至少需要写清楚六件事:
- :什么场景下激活该 Skill
触发条件
- :处理前必须收集的上下文
接单最小信息
- :步骤之间的先后依赖关系
固定处理顺序
- :该 Skill 有权直接使用的子能力
默认可调用能力
- :未经确认不得执行的高风险操作
默认禁止动作
- :对外输出结论时的统一格式和规范
输出口径
以下是一个简化版的 flink-ops 骨架:
---
name: flink-ops
description: Flink 实时任务值班技能
triggers:
- flink
- 实时任务失败
- 延迟高
- checkpoint 失败
- 重启任务
---
## 接单最小信息
- jobName
- 运行环境
- 现象描述
- 时间窗
## 固定处理顺序
1. 先确认任务存在
2. 再查运行实例或 applicationId
3. 再查监控和日志
4. 先给证据,再给判断
5. 需要动作时调用子 Skill
6. 动作后必须 verify
## 默认可调用
- status
- logs
- metrics
- verify
## 默认禁止
- 未确认对象就提交或取消作业
- 没有核验就宣称恢复
- 用猜测替代证据
这段内容最关键的作用:把处理链路固化了。以后底层实现可以变、API 可以换、脚本可以重写,但平台的工作方式不会乱。
执行脚本的统一契约
Skill 管流程编排,真正的动作实现下沉到脚本层。为了长期可维护,脚本层最好统一约定输入、输出和退出码。
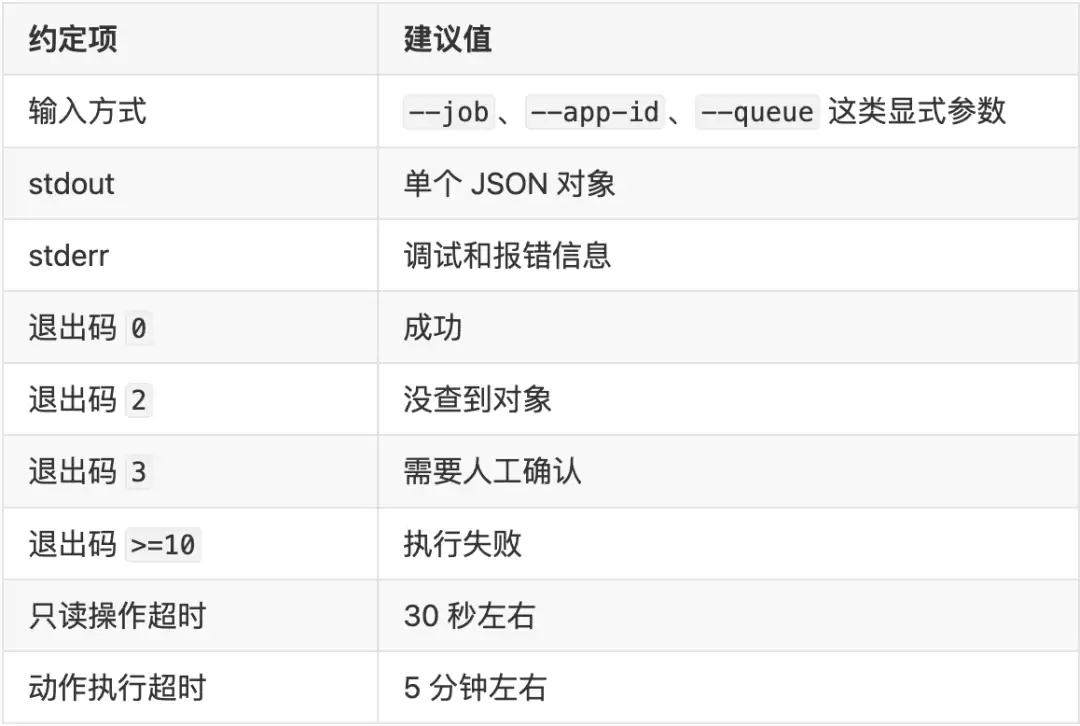
对 Agent 来说,最怕的不是脚本复杂,而是输出不稳定。只要输入输出契约固定了,底层不管是走平台 API、Flink Runtime、Prometheus 还是 yarn 命令,Skill 都能稳定复用。
举个例子,status.sh 别只返回一句“任务正常”,要直接吐出后续链路需要的关键字段:
{
"job_name": "order_dw_realtime",
"application_id": "application_1234_1024",
"flink_job_id": "5d8a4c2f...",
"state": "RUNNING",
"queue": "realfuture",
"tracking_url": "http://rm:8088/proxy/application_1234_1024/",
"restart_count": 1,
"observed_at": "2026-04-03T10:21+08:00"
}
这关系到链路能不能串起来,不是格式好不好看的问题。
真正的难点:把分散的能力组成证据链
脚本契约定了,但平台搭建最难的环节是:怎么把现有的状态查询、日志查询、监控查询、动作执行和核验能力,稳定接成一条完整的证据链。多个客户现场跑下来,最大阻力就在这一步。
第一步:把状态查询独立出来
最稳的做法,是单独提供一个入口:
scripts/status.sh --job
它内部可以查:任务平台 API、Flink Runtime、History Server、或者 yarn application-status。但无论内部实现怎么变,最终都应该统一吐出这些字段:job_name、application_id、state、queue、submit_time、restart_count。一旦这些字段固定下来,后面的日志、监控和核验就容易串起来了。
第二步:把跨层 ID 映射想清楚
很多方案看起来“能力都有”,但真连起来就是断的,问题十有八九出在 ID 映射上。

真正能跑起来的证据链,是下面这样的:
jobName -> applicationId -> flink_job_id -> attempt/containerId -> logs/metrics/runtime
这一步不打通,平台再智能也只能是表面智能。
Flink on YARN:把环境侧能力独立出来
证据链打通后,还有一个架构决策:环境侧能力要不要独立?如果客户大批量作业跑在 YARN 上,一个很实际的做法是单独做一个 yarn-ops。原因很实际:大量 Flink 任务异常,根因并不在作业本身,而在 YARN 资源层。任务长时间卡在 ACCEPTED、ApplicationMaster 起不来、容器反复被杀、队列满了、节点资源不足……这些都不是光看 Flink Runtime 或业务日志能得出结论的。
yarn-ops 至少要覆盖四件事:查 Application 状态、查 YARN 日志、查队列和资源、把资源侧证据结构化返回给主链路。重点是把任务侧和资源侧拆开,别把环境侧能力塞进主链路。任务诊断和资源诊断边界一模糊,平台一定会出现两类问题:证据混在一起,判断失焦;谁都能给结论,但没人对结论负责。
确认执行动作和核验流程
链路理顺了,动作执行怎么管就成了关键问题。上线后最深的一个体会是:所有能力里,最容易让平台失控的是执行动作。
执行动作必须和只读能力分层
执行动作里的 submit、restart、cancel、modify-and-restart 这几类能力,不能混进主 Skill。不是因为它们不重要,而是因为太重要了。它们天然带着风险:前置确认、审批要求、回滚条件,还有动作后的核验责任。稳一点的做法是把动作边界直接拉成矩阵:
| 动作 | 默认级别 | 前置条件 | 验收条件 |
|---|---|---|---|
| status / logs / metrics | 可自动执行 | 有 jobName | 返回结构化结果 |
| submit | 需确认 | 发布入口可用,参数齐全 | 产出新 applicationId 或发布单号 |
| restart | 需确认 | 已确认对象,已说明模式 | 新实例拉起,verify 通过 |
| cancel | 需确认 | 已确认影响面 | 任务停止且记录审计 |
| modify-and-restart | 强确认 | 参数变更明确,回滚条件明确 | 新参数生效,状态和指标恢复 |
动作执行本身不难,难的是执行之后能不能证明这次动作是对的。所以动作能力必须和 verify 强绑定。
真正有价值的:从“做了”到“做好”
动作能执行了,但怎么证明问题解决了?很多运维系统做到了发起动作、返回成功、留下记录。但离真正有价值的智能运维平台,还差最后一步:
恢复核验
- 新实例是不是已经拉起来
- YARN 是不是进入 RUNNING
- Flink job 是不是进入 RUNNING
- Checkpoint 是否连续成功
- Lag 是否开始回落
stderr是否还在持续增长同类异常
这些条件全满足了,平台才该给出“已恢复”的结论。否则最多只能说:动作执行完成,恢复待确认。
智能运维平台和自动化脚本的差异就在这里:
- 自动化脚本关注“我做没做”
- 智能运维平台关注
“问题到底解决了没有”
固化方案 & 跑通流程
固化确定的主流程
核验标准定了,整条链路固化下来长什么样?我们把方案收成了一条最小可落地链路:
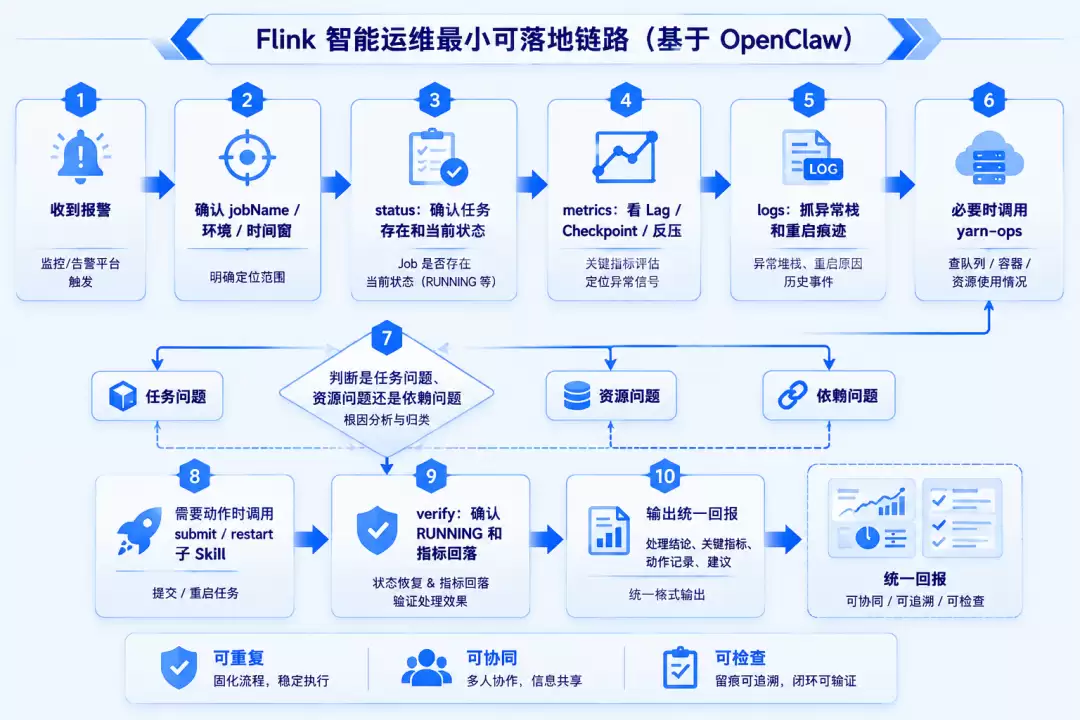
收到报警
-> 确认 jobName / 环境 / 时间窗
-> status:确认任务存在和当前状态
-> metrics:看 Lag / Checkpoint / 反压
-> logs:抓异常栈和重启痕迹
-> 必要时调用 yarn-ops:查队列 / 容器 / 资源
-> 判断是任务问题、资源问题还是依赖问题
-> 需要动作时调用 submit / restart 子 Skill
-> verify:确认 RUNNING 和指标回落
-> 输出统一回报
这条链路不复杂,但足够稳定。它把原来靠人肉切换的步骤,变成了可重复、可协同、可检查的工作流。
案例:把排障流程跑通
下面是一个生产实际跑过的案例。报警就一句话:order_dwd 延迟高,怀疑 Flink 卡住了。
处理过程如下:
main接住问题,整理最小上下文flink-sre根据jobName、时间窗和环境,先查status.sh- 拿到
applicationId后,再查metrics.sh,确认 Lag、Checkpoint、反压情况 - 同时通过
logs.sh查 JobManager / TaskManager 异常栈 - 如果发现任务本身没挂,但长时间卡在资源状态,就切到
yarn-ops yarn-ops去查yarn application-status、yarn queue-status、yarn logs,返回资源侧证据- 回到主链路后,由
flink-sre汇总判断:这是任务问题,还是资源问题 - 如果需要动作,再明确重启模式:是平台托管重启、checkpoint 重提,还是 sa vepoint 重提
- 动作执行后,先确认拿到了新的
applicationId - 再进入
verify.sh,确认 YARN 和 Flink 都已 RUNNING,Checkpoint 连续成功,Lag 开始回落 - 如果
stderr仍在持续新增同类异常,就不能宣称恢复 - 最后由
main用统一口径对外输出结论、证据、动作和结果
这条链路解决了值班场景里最要命的问题:判断、执行、核验是一个闭环,不是光把动作自动化就完事了。
从 Flink 到大数据生态栈:这套方案的可复制性
本文从头到尾都在聊 Flink,但有一个点值得单独拿出来说:这套方法论并不绑定 Flink。
回头看我们梳理的几个核心原则:Skill 做标准化封装、Agent 按职责拆分、只读与变更分离、证据链跨层串联、动作与核验强绑定——没有一条是 Flink 特有的。它们解决的是通用问题:分散的工具怎么编排、复杂的诊断怎么分工、高风险动作怎么管控、恢复结果怎么验证。
扩展路径:横向复制,纵向叠加
Spark 作业失败排查、Kafka 消费 Lag 诊断、HDFS DataNode 异常处理、HBase RegionServer 宕机恢复——这些场景的运维痛点跟 Flink 高度类似:链路散、经验依赖重、恢复不可证。把前面那套架构平移过去,无非是换一层 Skill 封装。
扩展方式很自然,不需要重新设计架构,只需要在现有框架上增加新的角色和 Skill:
skills/
├── flink-ops/ ← 已有
├── flink-ops-submit/ ← 已有
├── flink-ops-restart/ ← 已有
├── yarn-ops/ ← 已有(资源层,Spark/Hive 等共用)
├── spark-ops/ ← 新增:Spark 任务诊断
│ ├── SKILL.md
│ └── scripts/
│ ├── status.sh
│ ├── logs.sh
│ └── metrics.sh
├── kafka-ops/ ← 新增:Kafka 消费诊断
│ ├── SKILL.md
│ └── scripts/
│ ├── consumer_group_status.sh
│ ├── topic_metrics.sh
│ └── lag_analyzer.sh
└── hdfs-ops/ ← 新增:HDFS 存储诊断
├── SKILL.md
└── scripts/
├── namenode_status.sh
├── datanode_status.sh
└── block_report.sh
Agent 角色也跟着横向扩展,原则不变:每个组件一个专业 Agent,main 继续做总控:
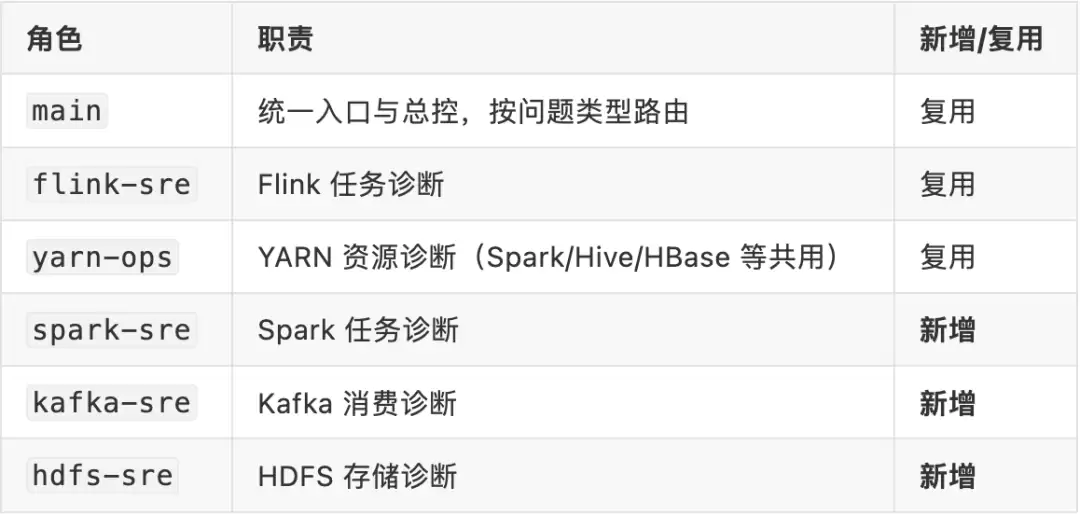
关键是,共用的能力不要重复造轮子。yarn-ops 就是一个典型例子:它查的是 YARN 层面的 Application、队列和容器状态,无论是 Flink on YARN、Spark on YARN 还是 Hive on YARN,诊断逻辑完全一致,一个 Agent 就够了。同样,Prometheus 指标查询、Grafana 面板数据、企业通知通道这些横向能力,也应该做成公共 Skill 供所有 Agent 共用,而不是每个组件的 Skill 里各写一套。
统一证据链:从组件视角到平台视角
单看 Flink 时,证据链是 jobName → applicationId → flink_job_id → logs/metrics。扩展到全域后,证据链变成了跨组件的关联网络:一个 Kafka 消费 Lag 告警,根因可能是下游 Flink 任务反压导致消费停滞,而 Flink 反压的根因又可能是 HDFS DataNode 写入慢。如果每个组件各自为战,三个 Agent 分别给出三个“组件级”结论,值班人员还是得在脑子里拼凑全貌。
所以扩展到多组件时,main 的角色会变得更重:它不仅要路由问题,还要在多个专业 Agent 的结论之间做关联推断。这就要求 main 的 SKILL.md 里定义清楚跨组件的排查优先级:比如先排除资源层、再排除上游依赖、最后定位到具体组件。
落地节奏建议
从实践来看,不建议一口气把所有组件全接进来。更稳妥的节奏是:
- 先跑通一个组件(比如 Flink),把角色拆分、Skill 组织、证据链、动作矩阵、核验闭环这套骨架搭稳
- 再接入共用层(YARN、Prometheus、通知通道),验证跨组件复用的可行性
- 横向扩展第二个组件(比如 Spark),复用已有的架构模式和共用层能力,验证扩展成本
- 批量接入其余组件,此时框架已成熟,边际成本递减
多数大数据平台的生产环境,YARN + Flink + Spark + Kafka 这四个一接,基本上就覆盖了日常值班 80% 以上的排查工作量。
总结:从工具集合到协同运维系统
回过头看,OpenClaw 给我们的价值不只是一个会调命令、调接口的 Agent。更大的意义在于:把分散能力收成统一链路,把不同角色组织成协同体系,把动作和核验绑定成闭环,把经验驱动的值班过程沉淀成可复用流程。一句话,让平台从工具集合升级为协同运维系统。
一个真正好的智能运维平台,最终靠的是链路稳定、角色清晰、证据充分、核验闭环,而不是靠堆砌功能。
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
免费影视剧APP推荐
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
抖音最火沙雕男生网名(精选100个)
-
网络热词聊污是什么意思
-
蒙古上单是什么梗
-
帅气继父网名女生可爱英文(精选100个)
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
免费看片软件下载地址推荐
-
免费看电影的软件推荐
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
韦一敏是什么梗
-
三角洲行动卡战备怎么弄 三角洲行动卡战备攻略
-
晨字沙雕网名大全女生(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
2 OpenClaw使用Ollama本地模型的实现(支持工具调用)) 06-02
-
3 OpenClaw接入阿里云永久免费模型解决方案 06-02
-
4 QQ怎么接入OpenClaw OpenClaw快速接入QQ指南 06-02
-
6 OpenClaw千帆模型切换:精准配置步骤与关键命令详解 06-02
-
7 更新服务器OpenClaw版本的方法大全 06-02
-
8 OpenClaw Skills四种安装方法详解 06-02
-
9 本地部署中文OpenClaw的详细教程 06-02
-
10 OpenClaw Gateway设备Token不匹配问题排查与解决全指南 06-02



