Arm+AWS实现AI定义汽车 基于Arm KleidiAI优化并由AWS提供支持
来源:互联网 更新时间:2026-05-28 10:32
汽车行业正处在一个激动人心的转折点。人工智能,尤其是生成式AI的浪潮,正在重塑我们对汽车的想象。麦肯锡最近的一项行业调查揭示了一个清晰的趋势:超过40%的汽车与制造业高管,已经在生成式AI研发上投入了高达500万欧元,更有超过10%的受访者投资额突破了2000万欧元。这不仅仅是技术探索,更是一场关乎未来的战略押注。
这股浪潮与另一个大趋势——软件定义汽车(SDV)——交汇在了一起。到2030年,一辆汽车里的代码行数预计将从现在的1亿行激增至3亿行。当生成式AI遇上SDV,会发生什么?答案是为性能和驾乘体验的创新,打开了全新的可能性。
今天,我们就来深入拆解一个由Arm与亚马逊云科技(AWS)联手打造的车载生成式AI实际用例,看看它如何从构想变为现实。
用例介绍
如今的汽车越来越像一台“轮子上的超级计算机”,功能可以通过OTA(空中升级)不断进化。今天买的车,明年可能就“解锁”了新的泊车辅助或车道保持功能。但随之而来的是一个甜蜜的烦恼:车主如何能及时、轻松地了解这些层出不穷的新功能?传统的纸质手册或在线文档更新缓慢、查阅不便,导致许多实用功能被埋没,用户体验大打折扣。
针对这个痛点,AWS联合Arm展示了一个巧妙的解决方案。它本质上是一个部署在车内的“智能汽车向导”,驾驶员只需用自然语言提问,就能立刻获得关于车辆功能的最新、最准确的解答。这个演示应用的核心,是一个在本地运行的小语言模型(SLM)。
它的关键优势在于“离线可用”。无论网络信号如何,驾驶员都能随时获取信息,这对行车安全与体验至关重要。当然,这背后离不开强大的性能优化。该应用集成了经过Arm KleidiAI优化的计算例程,将推理响应时间从原本的8-19秒,大幅缩短至1-3秒。这不仅提升了体验,还将应用开发周期缩短了足足6周——开发者可以更专注于功能本身,而无需深陷底层软件优化的泥潭。
在开发阶段,团队还借助了Arm虚拟硬件。它让开发者能在AWS云上快速获取树莓派等流行物联网开发板的虚拟实例,在全球团队协作或物理设备紧缺时,极大地加速了嵌入式应用的开发和测试流程。同样的KleidiAI优化也能无缝应用于这些虚拟环境。
这个方案的精妙之处还在于其完整的生命周期管理。通过AWS IoT Greengrass Lite(一个仅占用约5MB内存的高效边缘运行时),应用可以接收OTA更新,确保信息常新。更值得一提的是,它内置了一套自动质量监控与反馈循环系统。系统会持续评估AI回答的相关性与准确性,将超出阈值的响应标记出来供审核。整车厂的质保团队可以通过一个近乎实时的AWS仪表板,直观地看到这些反馈,快速定位需要改进的环节,并触发新一轮的模型微调与部署。
这不仅仅是给汽车装了个“语音说明书”。它代表了SDV时代一种全新的产品运营范式:整车厂可以根据真实的用户交互数据,持续迭代产品,甚至主动向用户介绍和引导新特性或增值服务。通过将生成式AI、物联网和边缘计算的能力深度融合,未来的汽车将变得更连接、更智能,也更懂它的主人。
端到端的上层实现方案
那么,这样一个系统是如何构建起来的呢?下图清晰地勾勒出了从模型训练到边缘部署,再到质量监控的完整闭环架构。
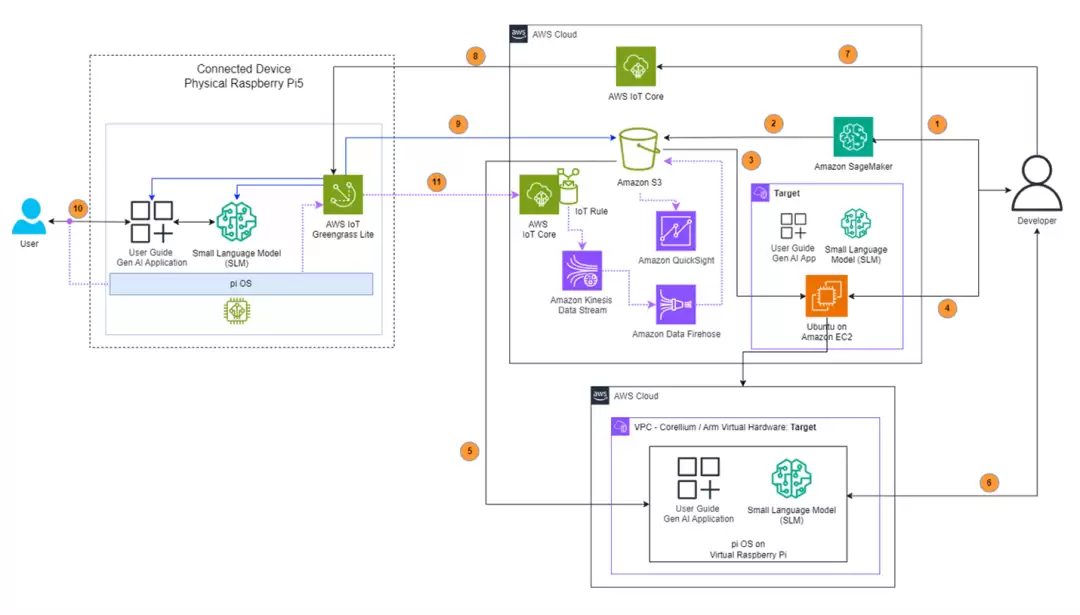
图:基于生成式 AI 的汽车用户向导的解决方案架构图
整个流程可以拆解为以下几个关键步骤:
1. 模型微调:
2. 存储与初始部署:
3. 开发与优化:
4. 虚拟测试与验证:
5. 边缘侧部署与编排:
6. 用户交互与质量监控:
接下来,我们聚焦于这个演示中两个至关重要的技术细节:Arm KleidiAI和它所加速的量化方案。
Arm KleidiAI
Arm KleidiAI是一个面向AI框架开发者的开源库。它的使命很明确:为Arm CPU提供一系列经过极致优化的核心计算例程。自2024年5月发布以来,它已经支持了包括32位浮点、Bfloat16以及4位定点在内的多种数据格式的矩阵乘法优化。
这些优化充分释放了Arm CPU的硬件潜能,例如利用SDOT和i8mm指令加速8位计算,以及利用MLA指令提升32位浮点运算性能。在本演示使用的树莓派5(搭载四核Cortex-A76)上,KleidiAI就发挥了SDOT指令的优势。SDOT指令是Arm在AI计算领域持续投入的一个缩影,它早在2016年的Armv8.2-A架构中就已引入,后续又陆续推出了i8mm、Bfloat16等更多指令,不断提升CPU处理AI工作负载的效率和性能。
llama.cpp 中的 Q4_0 量化格式
在这个演示中,模型通过llama.cpp的Q4_0格式进行量化来提升效率。简单来说,这种格式在计算矩阵乘法时:
- 以32位浮点数格式存储。
左侧矩阵(LHS,激活值)
- 则被压缩成4位定点格式。具体来说,每32个连续的4位权重值共享一个16位浮点数表示的缩放因子。
右侧矩阵(RHS,权重)
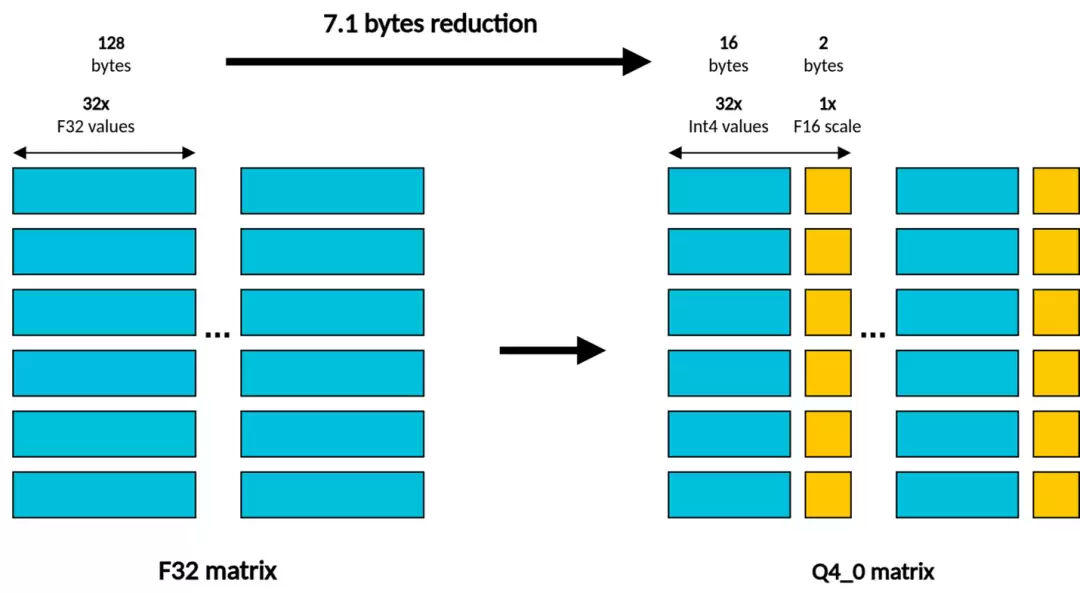
这里有个有趣的问题:KleidiAI的SDOT指令是为8位整数点积设计的,而我们的权重是4位,激活值准备时是32位浮点,它们是如何协作的?
答案是“动态量化”和“即时转换”。对于LHS矩阵,在计算前会实时将其量化为8位定点格式(同样采用分块量化)。对于RHS矩阵,那些4位权重在参与计算前,会先被高效地“解压”成8位值。既然最终都要用8位算,为什么不一开始就用8位呢?
使用4位量化有两个压倒性的优势:
第一,模型尺寸减半。
第二,显著提升文本生成速度。
如何结合使用 KleidiAI 与 llama.cpp?
对于开发者来说,集成过程异常简单。KleidiAI的优化已经内置在llama.cpp之中。这意味着,开发者在基于Arm架构的移动设备、嵌入式平台或服务器上部署llama.cpp时,无需额外操作,就能自动享受到针对Arm CPU的极致性能提升。
除了 llama.cpp,还有其他选择吗?
当然。llama.cpp是在Arm CPU上运行大语言模型的优秀选择之一,但生态远不止于此。目前,包括ExecuTorch、MediaPipe、MNN和PyTorch在内的多个主流生成式AI框架,都已集成了KleidiAI的优化。开发者只需确保使用的是这些框架的最新版本,就能为Arm平台上的AI应用注入更强的动力。
总结
软件定义汽车与生成式AI的融合,正在开启一个汽车智能化与个性化的新时代。本文探讨的由Arm KleidiAI优化、AWS云服务支撑的车载AI助手演示,不仅仅是一个技术原型,它清晰地展示了如何用现有技术解决真实的行业痛点——将响应时间压缩到1-3秒,并将开发周期缩短数周,证明了高效、离线可用的生成式AI应用在车载场景下不仅是可行的,更是理想的。
未来的汽车技术,必然是边缘计算、物联网与人工智能无缝融合的产物。随着汽车变得越来越复杂,像文中这样的解决方案,将成为连接尖端汽车功能与普通用户认知之间那座不可或缺的桥梁。这场变革,才刚刚开始。

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
无尽花界时装合辑
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
免费影视剧APP推荐
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
1 多稿合并:从手动比稿到一键 Skill 05-28
-
2 零帧起手 Codex × Figma 双向工作流实操 05-28
-
3 NoteAI - AI 一站式知识提取工具,支持视频、网页、音频 05-28
-
4 如何高效撰写学校工作总结?AI 助手为您提供详细范文与提示词! 05-28
-
5 如何撰写幼儿园年终总结报告?一份详细的范文与提示词供您参考! 05-28
-
6 如何快速实现人脸识别通道?一文了解具体技巧 05-28
-
7 中环混改尚存变数 高调的TCL要上演“资本魔输”? 05-28
-
9 AI框架不牢,模型地动山摇 05-28
-
10 小龙虾很好,可是如何在企业场景中落地? 05-28



