ConvMixer:Patches are all you need?
来源:互联网 更新时间:2025-07-18 11:31
ConvMixer是基于卷积层进行Mixer操作的模型,结构简单却精度不错。它与MLP Mixer类似,通过交替混合channel和token维度信息提取图像特征,但用卷积替代MLP。其用逐通道卷积提取token信息,1x1卷积提取channel信息,官方提供三个预训练模型,在ImageNet 1k验证集上表现良好,还可从头或微调训练。

引入
- 之前介绍了 MLP-Mixer,【MLP-Mixer:MLP is all you need ?】
- 那么除了 MLP 其他的基础网络层可不可以也进行 Mixer 操作呢?
- 结论当然也是可以的,所以这次就来介绍一个最近新鲜出炉的工作 ConvMixer。
- 顾名思义 ConvMixer 就是使用卷积层进行 Mixer 操作来构建的一个模型
- 结构上也非常简单,但是同样能够实现一个不错的精度表现
相关资料
- 论文:"Patches Are All You Need?"
- 官方代码:tmp-iclr/convmixer
模型架构
ConvMixer 与 MLP Mixer 模型一样模型的结构都十分简单
同样是通过 channel 和 token 两个维度的信息进行交替混合,实现图像特征的有效提取
只不过 ConvMixer 使用的基础网络层为卷积,而 MLP Mixer 使用的是 MLP(多层感知机)
在 ConvMixer 模型中:
使用 Depthwise Convolution(逐通道卷积) 来提取 token 间的相关信息,类似 MLP Mixer 中的 token-mixing MLP
使用 Pointwise Convolution(1x1 卷积) 来提取 channel 间的相关信息,类似 MLP Mixer 中的 channel-mixing MLP
然后将两种卷积交替执行,混合两个维度的信息
模型的大致架构如下图所示:
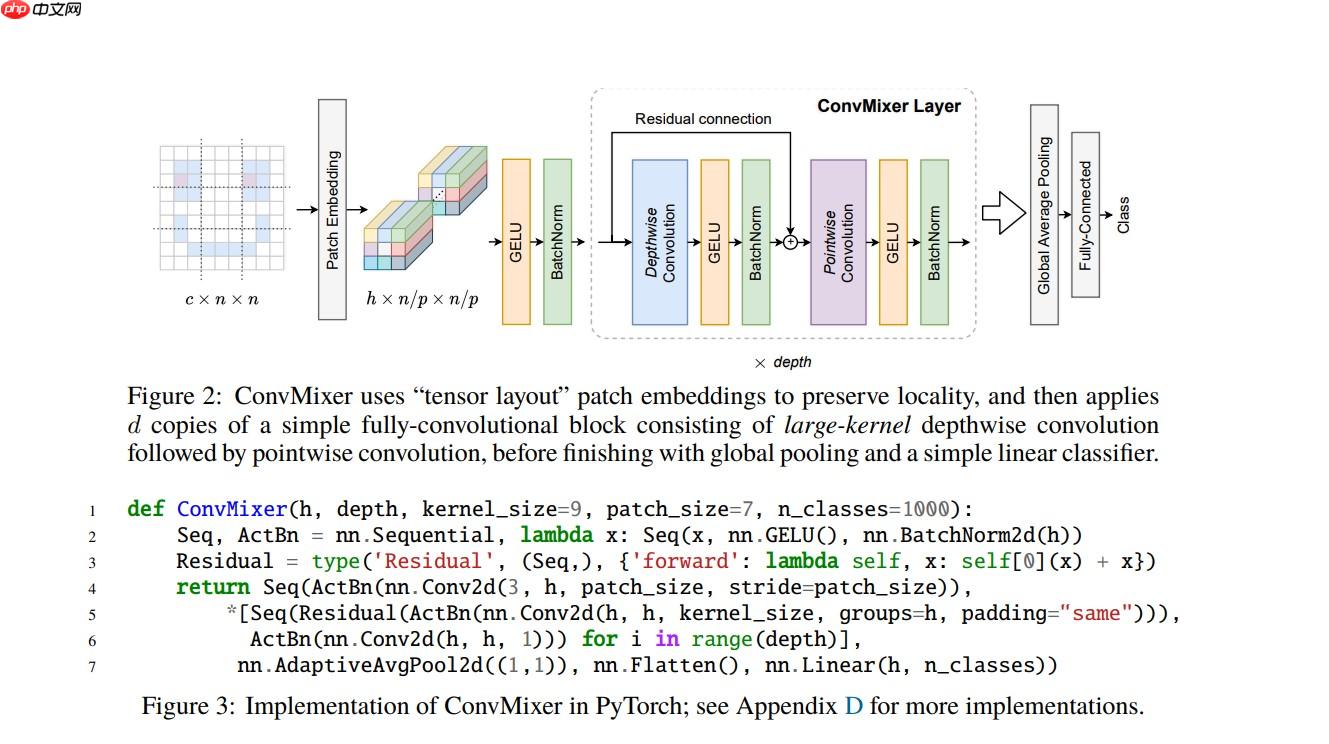
代码实现
- 模型的代码实现其实在上面的结构图中已经有出现了,不过由于过于精简可能比较不好理解
- 下面给出官方代码中的另一种常规一些的实现方式,结构比较清晰,并且手动添加了一些注释,相对比较好理解
模型搭建
In [1]import paddle.nn as nnclass Residual(nn.Layer): # Residual Block(残差层) # y = f(x) + x def __init__(self, fn): super().__init__() self.fn = fn def forward(self, x): return self.fn(x) + xdef ConvMixer(dim, depth, kernel_size=9, patch_size=7, act=nn.GELU, n_classes=1000): # ConvMixer Model # dim: hidden channal dim(ConvMixer 网络的隐藏层通道数) # depth: num of ConvMixer Block(网络层数也是其中 ConvMixer 层的数量) # kernel_size: kernel_size of Convolution in ConvMixer Block(ConvMixer 层中的卷积层的卷积核大小) # patch_size: patch_size in Patch Embedding (Patch Embedding 时 Patch 的大小) # act: activate function(激活函数) # n_classes: num of classes(输出的类别数量) return nn.Sequential( # Patch Embedding # Conv(kernel_size = stride = patch_size) + GELU + BN # 使用一个卷积核大小和步长都等于 Patch 大小的卷积层进行输入图像 Embedding 的操作 # 并连接一个 GELU 激活函数和 BN 批归一化层 nn.Conv2D(3, dim, kernel_size=patch_size, stride=patch_size), act(), nn.BatchNorm2D(dim), # ConvMixer Block x N(depth) # N(depth) 个 ConvMixer 层 *[nn.Sequential( # Residual Block + Depthwise Convolution + GELU + BN # 逐通道卷积提取 Token 之间的信息 # 并连接一个 GELU 激活函数和 BN 批归一化层 # 最后与原输入进行一个残差连接 Residual(nn.Sequential( nn.Conv2D(dim, dim, kernel_size, groups=dim, padding=”same“), act(), nn.BatchNorm2D(dim) )), # Pointwise Convolution + GELU + BN # 1x1 卷积提取 Channel 之间的信息 # 并连接一个 GELU 激活函数和 BN 批归一化层 nn.Conv2D(dim, dim, kernel_size=1), act(), nn.BatchNorm2D(dim) ) for i in range(depth)], # Output Layers nn.AdaptiveAvgPool2D((1,1)), nn.Flatten(), nn.Linear(dim, n_classes) )登录后复制
预设模型
- 目前官方提供了如下三个预训练模型的参数文件
import paddledef convmixer_1536_20(pretrained=False, **kwargs): model = ConvMixer(1536, 20, kernel_size=9, patch_size=7, **kwargs) if pretrained: params = paddle.load('/home/aistudio/data/data111600/convmixer_1536_20_ks9_p7.pdparams') model.set_dict(params) return modeldef convmixer_1024_20(pretrained=False, **kwargs): model = ConvMixer(1024, 20, kernel_size=9, patch_size=14, **kwargs) if pretrained: params = paddle.load('/home/aistudio/data/data111600/convmixer_1024_20_ks9_p14.pdparams') model.set_dict(params) return modeldef convmixer_768_32(pretrained=False, **kwargs): model = ConvMixer(768, 32, kernel_size=7, patch_size=7, act=nn.ReLU, **kwargs) if pretrained: params = paddle.load('/home/aistudio/data/data111600/convmixer_768_32_ks7_p7_relu.pdparams') model.set_dict(params) return model登录后复制
模型测试
In [3]model = convmixer_768_32(pretrained=True)x = paddle.randn((1, 3, 224, 224))out = model(x)print(out.shape)model.eval()out = model(x)print(out.shape)登录后复制
精度测试
标称精度
ConvMixer 与其他一些先进模型的精度对比:
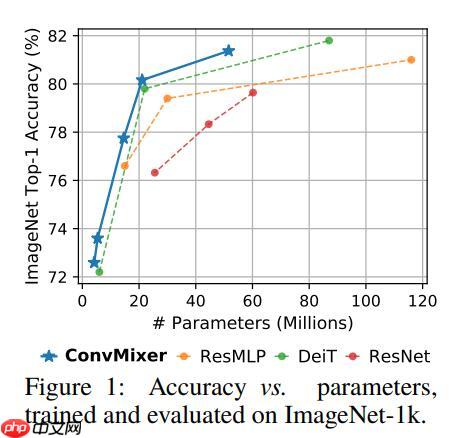
具体的精度表现如下表:
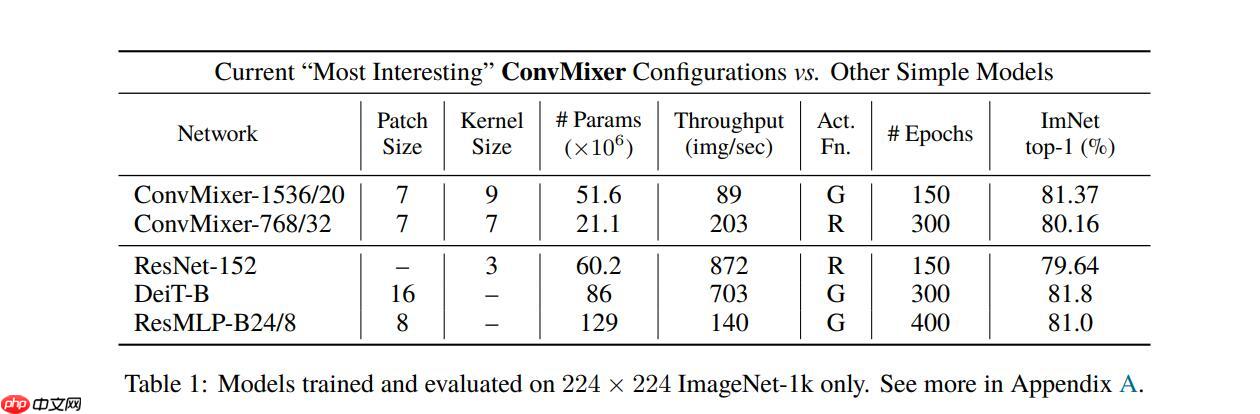
解压数据集
- 解压 ImageNet 1k 验证集
!mkdir data/ILSVRC2012登录后复制In [9]
!tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012登录后复制
精度验证
- 使用 ImageNet 1k 验证集对模型进行精度验证
- 可以看到结果与官方给出的基本一致
import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset): def __init__(self, root, label_list, transform, backend='pil'): self.transform = transform self.root = root self.label_list = label_list self.backend = backend self.load_datas() def load_datas(self): self.imgs = [] self.labels = [] with open(self.label_list, 'r') as f: for line in f: img, label = line[:-1].split(' ') self.imgs.append(os.path.join(self.root, img)) self.labels.append(int(label)) def __getitem__(self, idx): label = self.labels[idx] image = self.imgs[idx] if self.backend=='cv2': image = cv2.imread(image) else: image = Image.open(image).convert('RGB') image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self): return len(self.imgs)val_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.CenterCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 配置模型model = convmixer_1536_20(pretrained=True)model = paddle.Model(model)model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt', backend='pil')# 模型验证acc = model.evaluate(val_dataset, batch_size=128, num_workers=0, verbose=1)print(acc)登录后复制
Eval begin...step 391/391 [==============================] - acc_top1: 0.8137 - acc_top5: 0.9562 - 3s/step Eval samples: 50000{'acc_top1': 0.81366, 'acc_top5': 0.95616}登录后复制
模型训练
从头训练
根据论文的模型配置训练一下 CIFAR-10 数据集的 BaseLine:
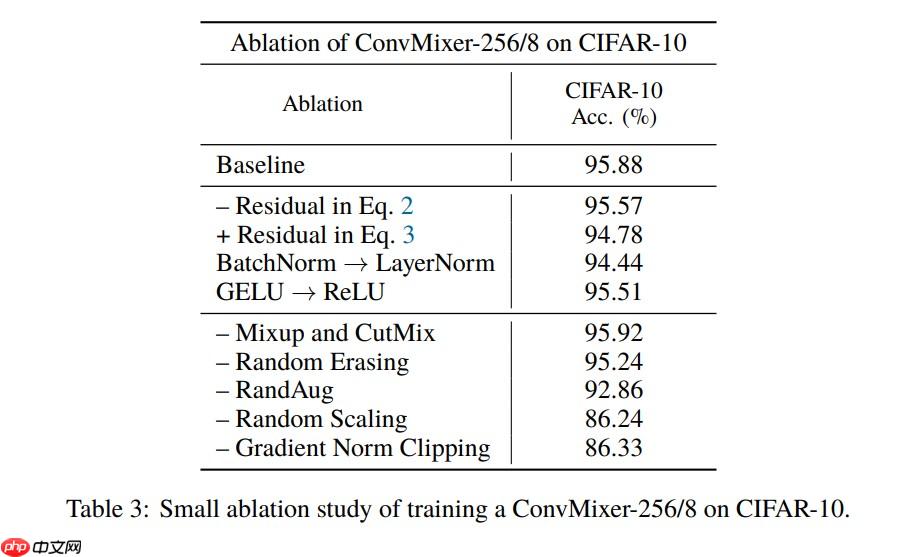
由于没有严格对齐各项训练参数,所以训练结果可能应该会有差异
import osimport cv2import numpy as npimport paddleimport paddle.nn as nnimport paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10from PIL import Imagefrom paddle.callbacks import EarlyStopping, VisualDL, ModelCheckpointtrain_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.RandomCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])val_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.CenterCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])model = ConvMixer(256, 8)opt = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.parameters())model = paddle.Model(model)model.prepare(optimizer=opt, loss=nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy(topk=(1, 5)))train_dataset = Cifar10(transform=train_transforms, backend='pil', mode='train')val_dataset = Cifar10(transform=val_transforms, backend='pil', mode='test')checkpoint = ModelCheckpoint(save_dir='save')earlystopping = EarlyStopping(monitor='acc_top1', mode='max', patience=3, verbose=1, min_delta=0, baseline=None, save_best_model=True)vdl = VisualDL('log')model.fit(train_dataset, val_dataset, batch_size=32, num_workers=0, epochs=10, save_dir='save', callbacks=[checkpoint, earlystopping, vdl], verbose=1)登录后复制
微调训练
- 基于预训练模型在 Cifar10 数据集上进行微调训练
import osimport cv2import numpy as npimport paddleimport paddle.nn as nnimport paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10from PIL import Imagefrom paddle.callbacks import EarlyStopping, VisualDL, ModelCheckpointtrain_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.RandomCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])val_transforms = T.Compose([ T.Resize(int(224 / 0.96), interpolation='bicubic'), T.CenterCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])model = convmixer_768_32(n_classes=10, pretrained=True)opt = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.parameters())model = paddle.Model(model)model.prepare(optimizer=opt, loss=nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy(topk=(1, 5)))train_dataset = Cifar10(transform=train_transforms, backend='pil', mode='train')val_dataset = Cifar10(transform=val_transforms, backend='pil', mode='test')checkpoint = ModelCheckpoint(save_dir='save')earlystopping = EarlyStopping(monitor='acc_top1', mode='max', patience=3, verbose=1, min_delta=0, baseline=None, save_best_model=True)vdl = VisualDL('log')model.fit(train_dataset, val_dataset, batch_size=32, num_workers=0, epochs=1, save_dir='save', callbacks=[checkpoint, earlystopping, vdl], verbose=1)登录后复制
-
ao3官方官网链接入口中文
-
悟空浏览器网页版:免费畅游网络世界的极速入口
-
豆包AI安装需要哪些运行时库 豆包AI系统依赖项完整清单
-
2025迷你世界雨薇免费激活码
-
2025崩坏星穹铁道7月3日兑换码
-
Perplexity AI比Google好吗 与传统搜索引擎对比
-
ChatGPT如何生成产品原型 ChatGPT产品设计辅助功能
-
哔哩哔哩教程哪里找
-
蚂蚁庄园今日最新答案7.10
-
《伊苏X -诺曼荣光-》加长版预告公开 8月21日发售!
-
小米在全球范围推送澎湃OS 2.2 这几款机型现可升级
-
真我手机如何开启 GT 模式?游戏性能一键拉满技巧!
-
iPhone11promax升级iOS 17.2之后怎么样
-
iPhone15pro怎么拍动态照片?
-
2025原神7月2日兑换码分享
-
如何轻松在iPhone上安装DeepSeek
-
华为手机怎么连接电脑 华为手机连接电脑的3种实用技巧
-
光遇7.8免费魔法是什么
-
剪映人像虚化怎么使用 剪映人像虚化使用方法
-
iPhone15 Pro Max屏幕一直亮着是什么原因
-
1

- 菜鸡冒险家官方下载
- 益智休闲 | 7.74MB
-
2

- 天启的狂怒手游下载
- 策略战棋 | 116.22MB
-
3

- 真实炮兵模拟手游下载
- 冒险游戏 | 93.07MB
-
4

- 火影战记1游戏下载
- 角色扮演 | 46.70M
-
5

- 快玩消星星下载最新版
- 益智休闲 | 19.7M
-
2 如何备份企业邮箱的所有数据? 07-29
-
4 Claude如何优化医疗问答 Claude医学知识库集成方法 07-29
-
5 通义万相2.2— 阿里开源的AI视频生成模型 07-29
-
6 Intern-S1— 上海AI Lab推出的科学多模态大模型 07-29
-
7 tga 格式图片支持 alpha 通道吗 视频后期中常用吗 07-29
-
8 arw 格式图片怎么处理 索尼相机拍摄的该格式有何特点 07-29
-
10 ChatGPT怎么接入浏览器扩展 ChatGPT插件功能如何启用 07-29



