一个案例吃透Pipeline
来源:互联网 更新时间:2025-07-18 11:30
Pipeline是一套面向AI开发任务的端到端编排组件,支持任务流程构建、可视化、调试、运行及节点级详情查看,功能覆盖AI开发全流程。Pipeline的目标是让AI开发者在研发过程中,全流程变得更加简单且高效(Simple and Efficient)。

一个案例吃透Pipeline
一、Pipeline 简介
Pipeline是一套面向AI开发任务的端到端编排组件,支持任务流程构建、可视化、调试、运行及节点级详情查看,功能覆盖AI开发全流程。
Pipeline的目标是让AI开发者在研发过程中,全流程变得更加简单且高效(Simple and Efficient)。基于Pipeline构建的AI开发流程,能做到:
-标准化(Standard): 研发流程可标准化沉淀、自动化迭代
-可复用(Reusable): Op节点和Pipeline级别都支持可复用;pipeline 中的每个节点都是一个 Op, 每个 Op 都有自己需要运行的代码逻辑、输入和输出
-可扩展(Scalable): 节点资源可扩展,提供上下游接口对接能力
二、 核心概念
[Pipeline] : 一个完整的训练流程,可以包含一个或者多个节点
[Op] : pipeline 中的每个节点都是一个 Op, 每个 Op 都有自己需要运行的代码逻辑、输入和输出
[Inputs] : 传递给 Op 的 Parameter 或 Artifact
[Outputs] : 由 Pipeline 生成的 Parameter 或 Artifact
[Parameter] : 即 string, list, array 等类型的参数
[Artifact] : 由 Op 生成的文件, 在 Op 运行结束后,将会上传到 Artifact 仓库中
三、Pipeline 编排详解
Pipeline 是包含一系列输入数据和一个或者多个节点的机器学习的处理流程,在 Pipeline 中的每一个节点都是一个 Op, 这里 是平台基于 MNIST 数据集构建的一个示例,其中包含了数据处理、模型训练、模型预测三个步骤, 用户可以自行下载然后解压(tgz格式)。
数字识别是计算机从纸质文档、照片或其他来源接收、理解并识别可读的数字的能力,目前比较受关注的是手写数字识别。手写数字识别是一个典型的图像分类问题,已经被广泛应用于汇款单号识别、手写邮政编码识别等领域, MNIST 是深度学习领域标准、易用的成熟数据集,包含60000条训练样本和10000条测试样本。
解压后的目录结构如下所示:
mnist_cpu├── code # 存放运行代码的目录│ ├── data_reader.py # 定义了数据加载的逻辑│ └── model_train.py # 定义了模型训练和模型预测的逻辑├── data│ └── mnist.json # MNIST 数据集└── mnist.ppl # ppl 文件,定义了需要运行的 pipeline。登录后复制
其中 code/data_reader.py 和 code/model_train.py 就是普通的 python 脚本,包含了模型训练和模型预测的全部逻辑。 而 data/mnist.json 就是 json 格式的 MNIST 数据集。 在 mnist.ppl 这个文件中,我们定义了一个 pipeline, 该文件的完整内容如下:
# 从 pipeline 中 导入 ScriptOp, FuncOp 等from pipeline.dsl import ScriptOpfrom pipeline.dsl import FuncOpfrom pipeline.dsl import OutputResourcefrom pipeline.interface import Run# 通过 FuncOp 定义一个 op, 用于处理数据@FuncOp(basedir=”./data“)def data_process_op(input_data, train_data, predict_data): ”“” data process “”“ import json with open(input_data, 'r') as fp: data = json.load(fp) # 将 处理后的训练数据写入至输出 artifact[train_data] 中 with open(train_data, 'w') as fp: json.dump(data[0], fp) # 将 处理后的预测数据写入至输出 artifact[predict_data] 中 with open(predict_data, 'w') as fp: json.dump(data[1], fp)def mnist_train_op(epoch=1, batch_size=100, mode=”train“, inputs=None): # 直接通过初始化 ScriptOp 来创建一个 op, 用于模型训练, # 定义了一个输出 artifact[model], 在 command 执行结束后,会将 # 输出 artifact[model] 的本地存储路径下的所有文件打包上传至 artifact 仓库中 return ScriptOp(name=”mnist train op“, command=[”python3“, ”model_train.py“], arguments=[ ”--epoch“, epoch, ”--batch_size“, batch_size, ”--mode“, mode, ”--model_path“, ”output/mnist_cpu“, ”--datafile“, ”train_data.json“ ], inputs=inputs, outputs={”model“: ”output“}, basedir=”./code“, image=”registry.baidubce.com/paddlepaddle/paddle:2.1.1“ )def mnist_predict_op(epoch=1, batch_size=100, mode=”predict“, inputs=None): # 直接通过初始化 ScriptOp 来创建一个 op, 用于模型预测 return ScriptOp(name=”mnist predit op“, command=[”python3“, ”model_train.py“], arguments=[ ”--epoch“, epoch, ”--batch_size“, batch_size, ”--mode“, mode, ”--model_path“, ”init_model/mnist_cpu“, ”--datafile“, ”predict_data.json“ ], inputs=inputs, basedir=”./code“, image=”registry.baidubce.com/paddlepaddle/paddle:2.1.1“ ) def pipeline_func(epoch=1, batch_size=100): # 通过将 data_process_op 的参数 train_data 和 predict_data 赋值为 OutputResource(), 为该 op 声明了两个输出 artifact[train_data, predict_data] op1 = data_process_op(input_data=”mnist.json“, train_data=OutputResource(), predict_data=OutputResource() ) # 通过 inputs={”train_data“: (op1.outputs[”train_data“], ”./train_data.json“)}, 将 op1 的输出 artifact[train_data] 作为 op2 的输入artifact[train_data] op2 = mnist_train_op(epoch=epoch, batch_size=batch_size, inputs={ ”train_data“: (op1.outputs[”train_data“], ”./train_data.json“) } ) # 通过 inputs={”predict_data“: (op1.outputs[”predict_data“], ”./predict_data.json“), ”init_model“: op2.outputs[”model“]}, # 为 op3 声明了两个输入 artifact, 分别为 predict_data 和 init_model, 其分别来源于 op1 的输出 artifact [predict_data] 和 op2 的 输出 artifact [model] op3 = mnist_predict_op(epoch=epoch, batch_size=batch_size, inputs={ ”predict_data“: (op1.outputs[”predict_data“], ”./predict_data.json“), ”init_model“: op2.outputs[”model“] } )# 调用 Run().create() 接口,以运行 pipelineRun().create(pipeline_func)登录后复制
在 mnist.ppl 文件中,我们依次定义了三个 Op,分别是用于处理训练数据的 data_process_op,用于模型训练的 mnist_train_op, 和用于模型预测的 mnist_predict_op,并在函数 pipeline_func 中完成了对于这三个 Op 的编排工作。接下来将依次讲解 Op 的定义以及 Op 的编排等内容。
如何创建 ppl 文件,请参考这里
3.1、定义Op
Op 是 Pipeline 运行时的基本调度单位, Pipeline 中的每一个节点都需要是一个 Op。 Op 是一个容器化的应用,每个 Op 都有自己独立的运行环境,运行逻辑,以及的输入与输出,Pipeline 为用户提供了多种定义 Op 的方式。
3.1.1 FuncOp
如果你的 Op 只需要执行一段简单的 python 函数,此时可以使用 FuncOp 来构建你的 Op。FuncOp 是一个函数装饰器,使用该装饰器来装饰你需要的执行的 python 函数即可,如 mnist.ppl 中的 data_process_op 所示:
@FuncOp(basedir=”./data“)def data_process_op(input_data, train_data, predict_data): ”“” data process “”“ import json with open(input_data, 'r') as fp: data = json.load(fp) # 将 处理后的训练数据数据写入至输出 artifact[train_data] 中 with open(train_data, 'w') as fp: json.dump(data[0], fp) # 将 处理后的训练数据数据写入至输出 artifact[predict_data] 中 with open(predict_data, 'w') as fp: json.dump(data[1], fp)登录后复制
注意:被装饰的函数需要是 standalone 的,即该函数不能依赖任何该函数体外的代码,否则运行会失败
输出 Artifact
由于每个 Op 都有自己独立的运行环境, 因此,如果 Op 有数据需要保存,或者需要传递给其余的 Op 使用,必须将该数据落盘为文件,并且通过定义输出 Artifact 的方式来通知 Pipeline,这样在 Op 运行完成后,Pipeline 会将输出 Artifact 上传至 Artifact 仓库中。
FuncOp 定义输出 Aritfact 的方式为在初始化 Op 时,将相关的参数赋值为 OutputResource() 即可,如 mnist.ppl 中的 op1 的初始化所示:
op1 = data_process_op(input_data=”mnist.json“, train_data=OutputResource(), predict_data=OutputResource() )登录后复制
在上例中,创建 op1 时,给函数 data_process_op 的参数 train_data,predict_data 赋值为 OutputResource(), 因此,在 op1 运行时,传递给函数 data_process_op 的参数 train_data,predict_data 均为一个本地路径,用户需要将保存或者传递给其余节点的数据写至相应的路径下,在 op1 运行结束时,Pipeline 将会把路径 train_data 和 predict_data 下的所有文件上传至 Artifact 仓库中。
输入 Artifact
如果在初始化 FuncOp 时,某个参数的值表示的是其余 Op 的输出 Artifact,此时会将该参数解析为输入 Artifact。在被 FuncOp 装饰的函数正式执行前,平台会将其从 Artifact 仓库中下载至本地文件系统中。 并且在调用被装饰的函数时,会将该 Artifact 的本地路径传递给对应的参数。 如下例中的 op2 所示:
from pipeline.dsl import FuncOpfrom pipeline.dsl import OutputResourcefrom pipeline.cli import Client @FuncOp()def save_msg(num, msg): with open(msg, 'w') as fp: fp.write(”num is “ + num)@FuncOp()def write_msg(up_msg): with open(up_msg, ”r“) as fp: print(fp.read())def pipe_func(num=10): op1 = save_msg(num, msg=OutputResource()) op2 = write_msg(up_msg=op1.outputs[”msg“])登录后复制
在上例中,在创建 op2 时,函数 write_msg 的参数 up_msg 被赋值为op1.otuputs["msg"] (op1 的输出 artifact[msg] 的引用), 因此,在 op2 运行时,会将 op1 的输出 artifact[msg] 下载至本地,并且在执行 op2 时,传递给函数 save_msg 的参数 up_msg 的值即为输入 artifact["up_msg"] 的本地存储路径。
3.1.2 ScriptOp
如果你的 Op 只需要运行一条件简单的 shell 命令,或者已经有现成的镜像,又或者说需要运行一段已经编译好的程序,此时建议使用 ScripOp 来构建 Op,如果 mnist.ppl 中的 mnist_train_op 所示:
def mnist_train_op(epoch=1, batch_size=100, mode=”train“, inputs=None): # 直接通过初始化 ScriptOp 来创建一个 op, 用于模型训练, # 定义了一个输出 artifact[model], 在 command 执行结束后,会将 # 输出 artifact[model] 的本地存储路径下的所有文件打包上传至 artifact 仓库中 return ScriptOp(name=”mnist train op“, command=[”python3“, ”model_train.py“], arguments=[ ”--epoch“, epoch, ”--batch_size“, batch_size, ”--mode“, mode, ”--model_path“, ”output/mnist_cpu“, ”--datafile“, ”train_data.json“ ], inputs=inputs, outputs={”model“: ”output“}, basedir=”./code“, image=”registry.baidubce.com/paddlepaddle/paddle:2.1.1“ )登录后复制
输出 Artifact
在初始化 ScriptOp 时,可以通过 outputs 参数来定义该 Op 的输出 Artifact。outputs 是一个字典, 其中 key 将作为输出 Artifact 的名字, value 则为输出 Artifact 在 Op 运行时的本地存储路径。
- 如果 value 为空字符串,Pipeline 会默认为该输出 Artifact 生成一个本地存储路径
- 在示例 mnist.ppl 中,节点 op2(mnist_train_op) 定义了一个输出 artifact[model], 在 op2 运行完成时,Pipeline 会将输出 artifact[model] 所表示的本地存储路径下的所有文件上传至 Artifact 仓库中
注意: 如果用户定义了输出 Artifact, 但是在输出 Artifact 的本地存储路径下没有任何文件,则 Op 会运行失败
关于在程序中获取如何获取输出 Artifact 的本地存储路径请参考这里
输入 Artifact
在初始化 ScriptOp 时,可以通过 inputs 参数来定义本节点的输入 Artifact。inputs 是一个字典,其中 key 将作为输入 Artifact 的名字,value 则需要指明输入 Artifact 的内容和该 Artifact 在 Op 运行时的本地存储路径:
- 如果 value 是一个 tuple, 则要求其为一个 二元的 tuple, 且该 tuple 中的第一个元素指明输入 Artifact 的内容,第二个元素指明该输入 Artifact 在 op 运行时的本地存储路径
- 否则 value 会作为输入 Artifact 的内容,其在 op 运行时的本地存储路径将会由 Pipeline 自动生成
- 在示例 mnist.ppl 中,节点 op2 定义了一个输入artifact['train_data'], 其内容为 op1 的输出 artifact['train_data'] 的引用(op1.outputs['train_data']),在 op2 的运行时,平台会将 op1 的输出 artifact['train_data'] 从 artifact 仓库中下载至本地
关于在程序中获取如何获取输入 Artifact 的本地存储路径请参考这里
3.2 获取 Artifact 的本地存储路径
3.2.1 通过环境变量获取
不管是 FuncOp 还是 ScriptOp, 输入/输出 Artifact 在 Op 运行时的本地存储路径都可以通过环境变量(Artifact的名字)来获取,如对于 mnist.ppl 中的 op2, 如果我们想要获取输入 artifact[train_data]的 本地存储路径,可以通过如下的代码获取:
- python 脚本
import ostain_data_path = os.getenv(”train_data“)登录后复制
- shell 脚本
echo ”输入artifact[train_data] 的本地存储路径为: $train_data“登录后复制
3.2.2 通过定义获取
如果在定义 Artifact 时, 为 Artifact 指定了一个绝对路径,则在 Op 运行时,Artifact 的本地存储路径即为该绝对路径, 否则请通过环境变量来获取。
3.3 指定 Op 的工作路径
请参考这里
3.4、编排 Op
在学习了如何定义 Op 后,接下来就要学习如何完成 Op 的编排,以构成一个完整的 Pipeline。
为了完成对 Op 的编排,我们需要创建一个函数,在该函数中我们需要完成一下几个步骤: 1、创建 Op, 2、定义参数依赖 3、定义节点依赖。如 mnist.ppl 中的 pipeline_func 函数所示:
def pipeline_func(epoch=1, batch_size=100): op1 = data_process_op(input_data=”mnist.json“, train_data=OutputResource(), predict_data=OutputResource() ) op2 = mnist_train_op(epoch=epoch, batch_size=batch_size, inputs={ "train_data": (op1.outputs["train_data"], "./train_data.json") } ) op3 = mnist_predict_op(epoch=epoch, batch_size=batch_size, inputs={ "predict_data": (op1.outputs["predict_data"], "./predict_data.json"), "init_model": op2.outputs["model"] } )登录后复制
其中,第 1 步创建 Op 在前文中有过详细的介绍了,这里不在赘述。接下来将会介绍定义 Op 间的参数依赖 和 Op 间的节点依赖。
3.4.1 定义参数依赖
一般而言,一个 Pipeline 会有多个 Op,而这些 Op 间一般会进行一些参数的传递,即某个 Op 使用其余 Op 的输出来作为输入,这就是参数依赖。
以 Parameter 的方式传递
在实例化 ScriptOp 时,在参数 command 和 arguments 中,都可以使用其余节点的输出,此时其余 Op 的输出将会以 Parameter 的形式传递给该 Op, 如下例中的 op2 所示:
def pipe_func(num=100): op1 = ScriptOp(name=”op1“, image=”1234:556“, outputs={”out1“: ”“}) op2 = ScriptOp(name=”op2“, image=”2345:6789“, command=[”echo“, op1.outputs[”out1“]])登录后复制
在上面的例子中,op1 会产生一个输出 artifact[out1],假设该输出 artifact 是一个文件,且文件内容为 “12345”,而在op2 的参数 command 中使用了 op1 的输出 artifact[out1], 则在运行 op2 的 command 前,Pipeline 会读取 op1 的输出 artifact[out1] 的内容,并使用该内容替换 command 中的 op1.outputs["out1"], 即 op2 的 command 会在 op2 运行前被替换为 ["echo", "12345"]。
此时的输出 Artifact 需要是一个小文件
以 Artifact 的方式传递
如果某个 Op 在其输入 Aritfact 中引用了其余节点的输出,则此时会在 Op 运行前,将对应的 Artifact 下载至本地的, 供 Op 运行时访问。关于如何定义输入 Artifact 在前文已经有详细的介绍, 因此这里不在赘述。
3.4.2 定义节点依赖
在同一个 Pipeline 中有多个 Op,那么如何指定这些 Op 的先后执行顺序呢? 这就是现在需要介绍的节点依赖了。
所有的 Op 都有一个 after 函数,通过调用该函数,可以指定当前 Op 所依赖的节点,即需要在哪些 Op 运行结束后,才能运行当前 Op,如下所示:
downstream.after(upstream)登录后复制
在上例中,downstream 依赖于 upstream,则节点 downstream 需要等到 upstream 运行完成后,才会运行。
如果两个 Op 存在了参数依赖,则平台会默认为这两个 Op 添加节点依赖, 如对于 mnist.ppl 中的 op1 和 op2,由于 Op2 需要使用 Op1 的输出 Artifact,因此会默认添加依赖关系:Op2 依赖于 Op1
四、运行Pipeline
在完成了对 Pipeline 的编排后,便可以进行可视化,发起调试任务,单次任务以及周期任务等操作。在进行这些操作前,我们还需要调用 Run().Create() 函数来通知 Pipeline 哪一个函数完成了对 Op 的编排工作。 如在 mnist.ppl 文件中,我们可以看到如下所示的代码:
Run().create(pipeline_func)登录后复制
关于 Pipeline 的可视化,发起调试任务,发起单次任务等操作可以参考这里
4.1 Pipeline 运行环境说明
目前Pipeline支持调试任务与单次任务,二者区别在于:
由于任务场景的不同,调试任务和单次任务会有部分不同,因此本章节做特别解释。
4.1.1 Op 的工作目录
调试任务
调试任务运行时,每个 Op 会在指定的运行目录下运行。
不管是 FuncOp 还是 ScriptOp, 用户都可以通过 basedir 参数来指定 Op 的工作目录,basedir 与 Op 工作目录的对应关系如下:
其中, $basedir 表示表示参数 basedir 的值
如 mnist.ppl 文件所示, op1 的工作目录为 /home/aistudio/mnist_cpu/./data, op2 和 op3 的工作目录为 /home/aistudio/mnist_cpu/./code, 其中 /home/aistudio/mnist_cpu 为 mnist.ppl 文件所在目录。
若两个节点指定相同的运行目录,一致性需要用户自行保证
单次任务
单次任务的 每个 Op 运行前,basedir 指定目录下的内容,会被 copy 到新的目录下,同时新的目录会被指定为节点的运行目录
单次任务未来支持多pipeline任务同时运行,需要保证运行环境的隔离性,因此需要将工作目录下的内容拷贝到一个独立目录下,避免多节点同时修改目录下内容
查看运行目录,可通过查看命令行-单次任务页面,学习单次任务的查询命令。
4.1.2 输入 Artifact 与输出 Artifact
调试任务
每个 Op 的 command 运行前,Pipeline组件会将 Op 的输入 Aritfact 保存到指定目录下。 在 command 执行成功后,Op 的输出 Artifact 则会保留在文件系统中。
以上面的 mnist.ppl 的 op1 和 op2 为例:
- 在 op1 运行后,会产生两个输出 artifact, 存储路径分别为 /home/aistudio/mnist_cpu/data/predict_data 和 /home/aistudio/mnist_cpu/data/train_data, 如下图所示:
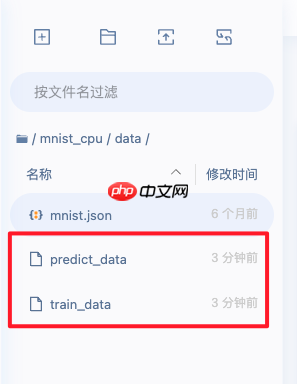
- 在 op2 运行前,将会为其准备一个输入 artifact, 其本地存储路径为 /home/aistudio/mnist_cpu/code/train_data.json, 在 op2 运行结束后,会产生一个输出 artifact, 其本地存储路径为 /home/aistudio/mnist_cpu/code/train_data.json, 如下图所示:

单次任务
与调试任务不同,单次任务会将每个节点的输出Artifact,保存到一个特定目录下(该目录为Pipeline组件自动生成)。
每个节点的输出Artifact,可通过查看命令行-单次任务页面,学习单次任务的查询命令查看。
请点击此处查看本环境基本用法. Please click here for more detailed instructions.
-
ao3官方官网链接入口中文
-
悟空浏览器网页版:免费畅游网络世界的极速入口
-
豆包AI安装需要哪些运行时库 豆包AI系统依赖项完整清单
-
2025迷你世界雨薇免费激活码
-
2025崩坏星穹铁道7月3日兑换码
-
Perplexity AI比Google好吗 与传统搜索引擎对比
-
ChatGPT如何生成产品原型 ChatGPT产品设计辅助功能
-
哔哩哔哩教程哪里找
-
蚂蚁庄园今日最新答案7.10
-
《伊苏X -诺曼荣光-》加长版预告公开 8月21日发售!
-
小米在全球范围推送澎湃OS 2.2 这几款机型现可升级
-
真我手机如何开启 GT 模式?游戏性能一键拉满技巧!
-
iPhone11promax升级iOS 17.2之后怎么样
-
iPhone15pro怎么拍动态照片?
-
2025原神7月2日兑换码分享
-
如何轻松在iPhone上安装DeepSeek
-
华为手机怎么连接电脑 华为手机连接电脑的3种实用技巧
-
光遇7.8免费魔法是什么
-
剪映人像虚化怎么使用 剪映人像虚化使用方法
-
iPhone15 Pro Max屏幕一直亮着是什么原因
-
1

- 菜鸡冒险家官方下载
- 益智休闲 | 7.74MB
-
2

- 天启的狂怒手游下载
- 策略战棋 | 116.22MB
-
3

- 真实炮兵模拟手游下载
- 冒险游戏 | 93.07MB
-
4

- 火影战记1游戏下载
- 角色扮演 | 46.70M
-
5

- 快玩消星星下载最新版
- 益智休闲 | 19.7M
-
2 如何备份企业邮箱的所有数据? 07-29
-
4 Claude如何优化医疗问答 Claude医学知识库集成方法 07-29
-
5 通义万相2.2— 阿里开源的AI视频生成模型 07-29
-
6 Intern-S1— 上海AI Lab推出的科学多模态大模型 07-29
-
7 tga 格式图片支持 alpha 通道吗 视频后期中常用吗 07-29
-
8 arw 格式图片怎么处理 索尼相机拍摄的该格式有何特点 07-29
-
10 ChatGPT怎么接入浏览器扩展 ChatGPT插件功能如何启用 07-29



