全球第一! 中国模型登顶榜首,首个可编辑AI语音来了
来源:互联网 更新时间:2026-07-03 12:53
新智元报道
【新智元导读】全球第一!中国AI语音ViiTorVoice首创「局部编辑」神技:配音错字告别重录,像改Word一样修语音。内附姆巴佩、哈兰德爆笑实测,快来见证!
中国AI,登顶全球第一。
最近,全球语音权威评测榜单Seed-TTS上,突然杀出一匹黑马——ViiTorVoice。这个凭空出世的中国模型,把Qwen3-TTS、CosyVoice3、Fish Audio一众主流巨头拉下马,径直登顶综合排名第一。
英文词错率(WER)1.32,中文词错率0.99,数据漂亮得有些吓人。它一举击穿了行业的天花板,成为当前评测体系中,全球首个中文词错率突破1.0大关的里程碑模型。
这个登顶的AI语音大模型,来自国产公司云上曲率。它终结了一个长久以来的行业痛点:语音无法局部编辑。全球首个具备「局部编辑」能力的AI,就这么横空出世了。
Hugging Face Demo: https://huggingface.co/spaces/ZzWater/ViiTorVoice
GitHub: https://github.com/viitor-ai/viitor-voice-nar
模型权重: https://huggingface.co/ZzWater/ViiTorVoice-NAR
实测:怕饿晕找哈兰德
所以,ViiTorVoice的上手效果到底怎么样?不妨看几个实测。
实测一:哈兰德的最新梗——挪威队伙食不够了
昨天,全网都在笑这个梗:挪威队参加世界杯,带了3名主厨去美国,还从本国空运食材,就为了喂饱哈兰德。网友热评:哈兰德一个人吃掉了挪威队的伙食预算。
立刻有人整活——找来最近哈兰德最火的广告,用ViiTorVoice把原广告词变成了:「哈兰德要一头牛,怕饿晕找哈兰德」。

结果让人笑疯。新生成的这几个字,音色跟哈兰德一模一样,还完美保留了他低沉嗓音的特质。前后的呼吸节奏和重音分布做到天衣无缝,新版广告一出,效果绝了。
实测二:姆巴佩的「补水啦」,无缝植入任何正经场景
最近,姆巴佩广告中那句魔性的「补水啦~ 」,已经洗脑了无数网友。

那语调、那尾音上扬的「啦~」,堪称2026年度鬼畜区预备役素材。
直接用ViiTorVoice把其中台词替换成「我驾驭未来,补水啦~ 」。
结果相当搞笑:生成的「补水啦~」三个字,完美继承了原广告里魔性的调调,尾音上扬的程度丝毫不差。最绝的是,它被无缝融合进了汽车广告那种低沉稳重的旁白节奏里,前后语句在呼吸气口和背景底噪上,完全看不出拼接痕迹。
另外,还有「AI会说话的照片」功能。让哈兰德吐露一下心声:为什么在赛场上急得想吃人。
正如开头所说,在真实环境中,更耗费时间的往往不是第一次生成,而是后期修改。短剧已完成配音,上线前发现角色人名需要调整;广告文案临时修改了产品名称;课程内容更新了一个专业术语。重新生成一句新配音并不难,真正耗时耗力的,是如何让修改后的内容与原有音频保持一致——音色、情绪衔接、停顿突兀、时间轴同步,这些细节最让人头疼。
ViiTorVoice推出的片段级编辑能力,恰恰解决了这个难题——你可以任意替换某个词、某句话、某个片段。从此,内容创作、广告营销、短剧配音、有声书制作等全体语音生产工作流,都将被彻底改变。
此外,ViiTor的平台上还有多种实用功能。比如视频配音功能,让鹦鹉小弟给黑道大哥讲冷笑话,直接给它干崩溃了,语音效果自然逗趣,是网上玩梗的好素材。下面是一对猫狗在分享对付人类的秘诀,轻松幽默的场景,非常适合替换台词,创作宠物拟人化的搞笑视频。
权威评测领先,多语种语音达到行业先进水平
为什么ViiTorVoice会有如此惊艳的效果?成绩来说话。在业界最严苛、公认度最高的TTS标准评测Seed-TTS中,它交出一份漂亮的成绩单:英文词错率1.32,中文词错率0.99。特别值得一提的是,中文词错率(WER)指标取得当前公开评测最佳成绩,发音准确性和语义还原能力达到行业领先水平,为实时语音交互、视频配音和Agent场景提供了更可靠的语音基础设施。
至此,它全面超越了包括Qwen3-TTS、CosyVoice3、Fish Audio等在内的主流竞品。错词率降到1.0以下,意味着极度稳定、几乎不存在幻觉。而在如此可怕的稳定性之上,ViiTorVoice还带来了市场上任何一家商业化产品都不具备的独门绝技。
语音编辑:哪里不对改哪里
ViiTorVoice最具碘伏性的核心能力,就是片段级定向编辑。行业内现有的TTS方案,无论是开源还是闭源,基本范式都是「整段重新生成」。但ViiTorVoice实现了真正的局部修改:你可以指定某一个词、某一个短语进行独立重新生成,而音频的其他所有部分——包括音色、节奏、背景底噪、前后文的情感连贯性——全部保持绝对稳定。
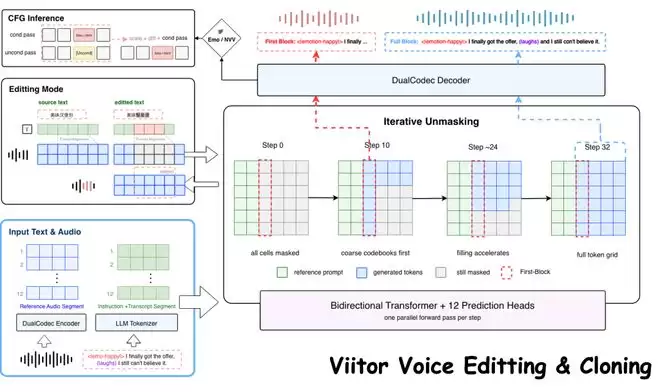
举个直观的例子。在ViiTor最新提供的Demo中,一段英文演讲音频,如果你把其中的部分词句改成其他词,重新生成后,那股特有的拖音、演讲时的呼吸节奏、独特的情绪起伏,完全一模一样,只有那个单词被「无缝替换」了。
影视制作、有声书录制、短剧出海,再也不需要因为改了一句台词而重录整集。对于影视后期而言,这尤其具有革命性意义——它第一次将对白调整从「重资产、长周期的补录流程」解放为「非线性时间线上的实时编辑」,让导演的创作意图得以实现。在有声书录制中,如果录错专有名词或口误,无需重录整章,只需定向修改那一两秒的音频。几十小时的有声剧,后期修音时间能从几天压缩到几十分钟,且音色与呼吸节奏始终保持一致。对于短剧出海,这个功能更是意义重大,它解决了多语言版本「重录成本高、周期长」的痛点,无需重新召集配音演员进棚。制作方只需在原始录音上替换特定用词,即可产出多个语言版本,每版听感都像原生表演。
这种能力是如何实现的?这归功于ViiTor团队在底层架构上做出的一种「反常识」的选择。
为什么只有它,能做到局部编辑?
当今市面上最火的语音模型(比如CosyVoice等),大多采用AR(自回归)架构。自回归模型的特点是「逐帧生成」,也就是预测下一个Token是什么。这种模式的好处是顺理成章,但致命弱点在于:它无法做到局部编辑。因为当你改变中间的一个词时,由于自回归的链式反应,后续所有的Token都会发生改变。此外,逐帧生成也导致推理延迟偏高,且容易在长文本中间出现瑕疵。
为了攻克这个壁垒,ViiTor团队毅然选择了难度极高的NAR(非自回归)架构。研发团队用了一个精妙比喻来解释他们的技术路径——「完形填空」。ViiTor使用类似于Masked LM的方式:当用户需要修改音频中间的2-3秒时,系统不需要从头算起。它会将这需要修改的部分「挖空」,然后模型根据这段音频前面和后面的上下文,精准填补空缺。正因为模型能够「同时看到前后文」,它填进去的这个词,不仅音色绝对一致,连前后情绪的衔接也天衣无缝。
同时,非自回归架构带来了另一个巨大的红利:极速的推理效率。由于可以同时生成所有时间点的Token,ViiTorVoice的首帧延迟被极大压缩。在同等体量下,其他模型的延迟往往在150ms-200ms左右,而ViiTor的端到端首帧生成时间做到了60毫秒以内。结合团队在推理结构和算子层面的深度定制优化,以及一致性蒸馏(将推理步数从32步大幅压缩至4步或8步),使得该模型在海量高并发环境下,依然能保持极低的计算成本。
告别「AI味」:精准情绪控制
很多人在刷短视频时都有一个痛点:只要一听到那种千篇一律、缺乏生气的AI机器音,就会立刻划走,甚至产生生理性恶心。人类的语言之所以生动,不仅仅是因为说了什么字,更因为包含了大量的副语言信息——呼吸、气口、笑声、叹气、犹豫、甚至是微弱的哭腔。现有的TTS模型大多只能解决「说什么」的问题,而ViiTor却着重解决了「怎么说」的问题,实现了令人惊叹的副语言感知与控制能力。
它不需要你在提示词里写上长篇大论的情感描述,而是可以通过插入特殊Token(比如笑声、叹气),实现词级别的精准控制。甚至同样是生气,模型未来还能区分是暴怒还是隐忍的愤怒,还能精准控制重音、弱读。为了做到如此细腻的控制,ViiTor引入了在图像生成领域大放异彩的CFG技术应用到音频推理中。在生成特定情绪或笑声时,模型在推理时会同时走两条路径——条件路径必须生成笑声,非条件路径正常生成。通过将这两条路径的Logits做差值,模型能够极大强化笑声这个条件的权重。实测发现,这种机制的成功率和自然度,远远高于传统模型仅靠自然语言去控制的效果。这正是ViiTor在技术路线上与ElevenLabs等主流方案的根本差异,也是当前竞争格局下难以快速复制的核心壁垒。
无参考文本克隆:短剧出海的降维打击
除了编辑和情绪控制,ViiTorVoice还有一项绝杀技:首个可编辑、无参考文本(Zero-Shot)的跨语种语音克隆。传统的语音克隆,你需要提供一段说话人的音频,以及对应的准确文字内容。模型本质上是在做「续写」。但在真实的商业场景中,这会遇到巨大的阻碍。比如短剧出海到巴西、中东,这些小语种(如葡萄牙语、阿拉伯语)的语音转文字模型准确率较低,让传统克隆直接失败。
ViiTorVoice的选择是,直接甩开了文本的拐杖!在训练阶段,团队刻意丢弃了文本信息,逼迫模型直接从音频的声学特征中去学习说话人的发音习惯、音色和口癖。结果:你只需要上传一段纯音频,模型就能自动提取音色,并用这个音色生成中、英、日、韩等多个语种的内容。对于当前火爆的短剧出海、游戏配音、电影解说来说,这无疑是降维打击。
不少国内头部企业,已经成为这家公司的合作客户。目前,在真实的付费生产环境中,ViiTor每天已稳定处理数十万小时音频,形成成熟的商业模式。
开源与商业化并进,拥抱开发者生态
非常可贵的是,面对如此强大的技术壁垒,ViiTor团队展现了极大的开放格局。目前,ViiTorVoice-NAR已经正式开源了其1B左右参数量的模型,开发者可以直接在GitHub和Hugging Face上获取包含Qwen3 Forced Aligner、W2V-BERT 2.0在内的完整本地模型组件,自由探索语音克隆、局部编辑和情感控制的无限可能。
AI语音的发展,正在从能说话到说得像人,再到今天可以像剪辑文字一样剪辑声音。ViiTorVoice的出现,不仅是中国AI团队在技术创新上的一次重大胜利,更是内容创作工作流的一次革命。当声音不再是一次性渲染的消耗品,而是可以被无缝编辑、注入灵魂的数字资产时,创作者的想象力,将不再受限于眼前的录音设备。在这个AI日新月异的时代,ViiTor已经替所有创作者,推开了下一个时代的大门。



-
archiveofourown 实战指南:常见用法整理
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
电视剧《小欢喜》剧情介绍
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
俄罗斯最大yandex入口外贸日报直达链接
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
美好的简约网名男生(精选100个)
-
植物娘大战僵尸电脑端与手机端存档转移的方法
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
盖乐世社区怎么删除帖子?盖乐世社区个人发布内容撤回步骤
-
腾讯元宝怎么用来分析股票基金的基本面信息?
-
二次元男生网名可爱(精选100个)
-
wallpaper壁纸声音怎么开启
-
国际贵金属走低,现货黄金价格跌0.49%
-
问题:CIA币好不?Cia Protocol币今日上线:价格预测、代币经济学和未来潜力
-
独家/李宰旭入伍前「登上孤岛服役」 惊见前辈裸体:忍不住笑了
-
短剧《嫡女她是山大王》剧情介绍
-
新浪人工智能热点小时报丨2026年06月20日02时_今日实时人工智能热点速递
-
Bubbly无法连接服务器修复方法
-
免费观看国外短视频的app有哪些 观看国外短视频的软件下载
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
1 AI Agent应用--问数--数据分析师 07-03
-
2 大家平时都是怎么用AI的? 07-03
-
3 从写代码到写Prompt,我们失去了什么? 07-03
-
5 低代码邂逅AI:中小企业创新的新引擎与边界探索 07-03
-
6 GEO 如何帮助企业获客 07-03
-
8 AI 陪伴,你到底是在说什么? 07-03
-
9 Agent客服全面接管排障任务,智能锁品牌服务效率翻倍提升 07-03
-
10 AI 行情带动股市走强,瑞银报告:2025 年全球新增近百万美元富翁 07-03



