JetBrains 官宣: Codex 为默认Agent!
来源:互联网 更新时间:2026-07-03 12:51
2026年6月,JetBrains做了个决定——把OpenAI的Codex设为AI助手的“默认推荐”。这可不是随随便便拍脑袋的合作,背后是实打实的数据验证,以及JetBrains一以贯之的产品哲学在做支撑。
。这背后,其实就是JetBrains一直强调的“开箱即用、体验优先”的设计理念。
的开放基准测试上,把离线基准测试和线上A/B测试结合起来。
,而不是在实验室里刷极限性能。
下面是Codex的数据。
来自线上A/B测试中的这些行为数据。在这些更能反映真实长期价值的指标上,。
从战略层面来看,JetBrains选择Codex作为推荐智能体,是一个集“用户、数据与战略”于一体的决策。
为什么要设置一个“推荐的智能体”?
在Codex被推上C位之前,JetBrains IDE里的AI用户得自己从一堆智能体里挑着用——Junie、Claude Agent,或者自带的ACP兼容智能体。自由度是挺高,但选择本身也成了负担。 JetBrains发现,随着模型能力越来越强,智能体(Agent)能帮用户干的事儿,比单纯聊个天要多得多、复杂得多。所以,直接推荐一个开箱即用、能力又均衡的智能体,能大幅降低新用户的上手门槛,让ta们立刻感受到AI辅助编程的核心价值
如何做出选择?基于“真实世界”的数据
JetBrains选谁,不是靠印象分或者合作关系,而是建立在一个叫开发者生产力AI竞技场(DPAIA)
1. 评估标准:三个核心指标
JetBrains从三个维度给候选智能体打分:- • :智能体在真实代码库里,能不能成功搞定Bug修复、功能开发这些任务,并且通过所有自动化测试。这是衡量能力的关键指标。
解决率
- • :完成一项任务平均要消耗多少token。这能确保推荐的智能体在提供高价值的同时,使用成本对用户来说也算合理。
成本
- • :从发出指令到拿到最终结果,平均要等多久。这直接影响开发者的工作流畅度。
延迟
实用主义平衡
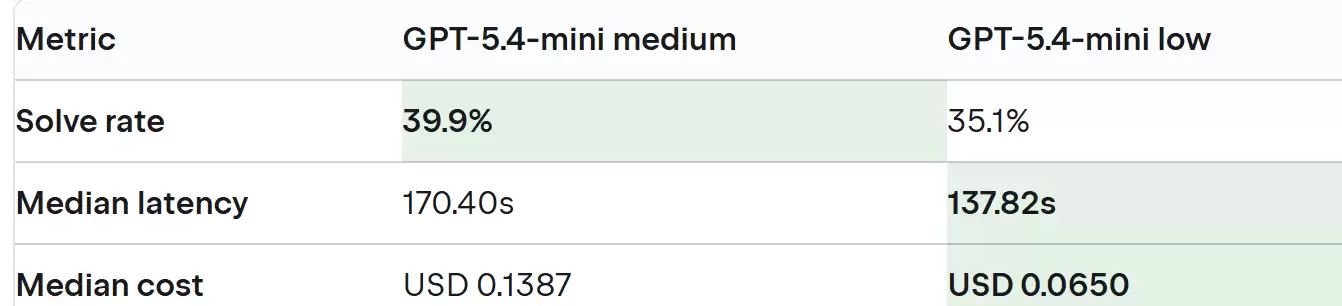
2. 严谨的测试流程
- • :数据集覆盖了
多语言、多场景的基准测试
三大生态,包含几百个来自真实代码库的任务,确保了评估够广、够有代表性。Ja va、C#、Python
- • :离线数据之外,JetBrains还搞了真实用户参与的A/B测试。通过分析用户行为(比如有没有切换智能体、有没有退回纯聊天模式),来验证离线结论,让决策更有说服力。
线上A/B测试验证
数据驱动的选择:Codex vs. Junie
最终候选者Codex(GPT-5.4-mini medium)和Junie(Gemini 3 Flash)之间的数据表现,差距非常小。从侧面也说明,当前AI智能体的竞争已经进入白热化阶段。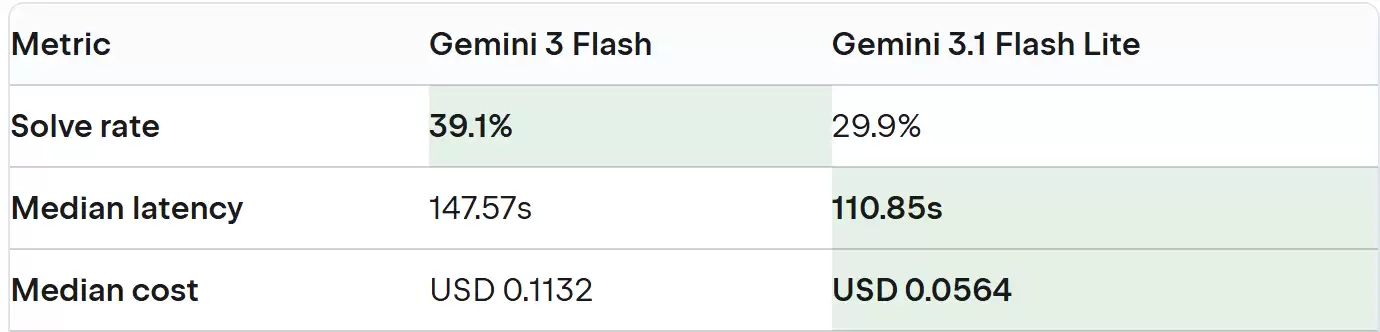 从表格能看出来,Codex在综合解决率上略胜一筹,但Junie在延迟和成本上表现更好。两个智能体在不同语言上各有优势(比如Codex在C#上解决率更高,Junie在Ja va上领先)。
从表格能看出来,Codex在综合解决率上略胜一筹,但Junie在延迟和成本上表现更好。两个智能体在不同语言上各有优势(比如Codex在C#上解决率更高,Junie在Ja va上领先)。
最终决定性的因素
“用户留存、切换率和失败率”
Codex最终胜出
-
- :通过数据驱动,为用户选出了当下综合体验最好的智能体,降低了用户的选择成本,提升了即时满足感。
用户价值优先
-
- :通过建立DPAIA基准测试,JetBrains向整个行业展示了一套
确立平台标准
。这增强了JetBrains AI平台的可信度,也为未来持续、客观地评估新模型/智能体打下了基础。科学、透明、可复现的AI编码工具评估标准
-
- :关键点在于,推荐是“动态”的。JetBrains明确表示,这不是永久决定,未来会基于新数据更新推荐。而且,用户始终可以自由切换到其他智能体。这种**“推荐但不强制”**的姿态,既尊重了高级用户的选择权,也维护了JetBrains作为开放平台的形象。
保持开放,而非锁定
总结
JetBrains把Codex设为推荐AI智能体,本质上是一次产品、数据与战略的完美结合。它基于严谨的测试,做出了一个对当前用户最友好的选择,同时通过公开的基准测试和开放的切换机制,展现了作为平台构建者的成熟心态。对开发者来说,这意味着在JetBrains IDE里,可以以一个更低的起点,体验到当前最优秀的AI辅助编程能力,同时还拥有不被锁定的自由。
-
archiveofourown 实战指南:常见用法整理
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
电视剧《小欢喜》剧情介绍
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
俄罗斯最大yandex入口外贸日报直达链接
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
美好的简约网名男生(精选100个)
-
植物娘大战僵尸电脑端与手机端存档转移的方法
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
盖乐世社区怎么删除帖子?盖乐世社区个人发布内容撤回步骤
-
腾讯元宝怎么用来分析股票基金的基本面信息?
-
二次元男生网名可爱(精选100个)
-
wallpaper壁纸声音怎么开启
-
国际贵金属走低,现货黄金价格跌0.49%
-
问题:CIA币好不?Cia Protocol币今日上线:价格预测、代币经济学和未来潜力
-
独家/李宰旭入伍前「登上孤岛服役」 惊见前辈裸体:忍不住笑了
-
短剧《嫡女她是山大王》剧情介绍
-
新浪人工智能热点小时报丨2026年06月20日02时_今日实时人工智能热点速递
-
Bubbly无法连接服务器修复方法
-
免费观看国外短视频的app有哪些 观看国外短视频的软件下载
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
1 AI Agent应用--问数--数据分析师 07-03
-
2 大家平时都是怎么用AI的? 07-03
-
3 从写代码到写Prompt,我们失去了什么? 07-03
-
5 低代码邂逅AI:中小企业创新的新引擎与边界探索 07-03
-
6 GEO 如何帮助企业获客 07-03
-
8 AI 陪伴,你到底是在说什么? 07-03
-
9 Agent客服全面接管排障任务,智能锁品牌服务效率翻倍提升 07-03
-
10 AI 行情带动股市走强,瑞银报告:2025 年全球新增近百万美元富翁 07-03



