AI视觉创作总差点意思?中科大等综述500+篇文献,系统分析生成一致性
来源:互联网 更新时间:2026-07-02 12:34
扩散模型这两年最大的进步,就是画质越来越能打。从文生图、图像编辑,到个性化生成、视频和三维内容创建,模型产出的视觉结果已经到了真假难辨的地步。有时候一张图片单独摆在面前,你根本说不准它到底是不是来自真实世界。
但当任务复杂度上升,一个比画质更基础的问题便浮出水面:图像看起来正确,并不代表模型真的完成了任务。
你让它生成三只猫,它可能只画出两只;你要求红色方块在蓝色圆球左边,模型可能把颜色和位置关系弄反;你让它在连续图片里保持同一个人物——每一张脸都好看,但彼此之间毫无关联。视频里的问题更明显:每帧单独看都逼真,但衣服不停变、手里的物体会消失、前一秒的场景状态后一秒就没了。多视图生成也一样:每个角度都像一件合理的物体,但合在一起却还原不出同一个三维结构。
这些失败不属于传统的“生成质量差”。更准确地说,它们是另一类问题:模型没有稳定地遵守它应该遵守的关系——我们称之为生成一致性。
中国科学技术大学、火箭军工程大学、清华大学、华中科技大学、剑桥大学等机构的研究者,近期发表了一篇重磅综述,系统梳理了500多篇论文,揭示了扩散模型视觉合成繁荣表象下的“一致性危机”。这篇文章把领域内看似混乱的研究整理得脉络清晰,描绘了一幅关于一致性关系分类、评估方法、优化策略、核心挑战与未来机遇的全景图。

论文地址:https://www.preprints.org/manuscript/202606.0870/v1
开源地址:https://github.com/Shawn-CodeDev/Awesome-Consistency-Diffusion-Visual-Generation
与以往按任务分类(文生图、编辑、个性化、视频、三维、安全)不同,这篇综述从更基础的问题出发:生成结果到底需要和什么保持一致?
沿着这个问题,原本分散的研究被重新组织为三种关系:
生成结果与外部条件的一致、不同生成状态之间的一致、生成内容与人类及现实世界标准的一致
基于这一框架,研究者进一步讨论了:一致性可以在生成流程的哪些位置被实现?为什么现有指标经常测不准?当多种要求相互冲突时,下一代模型到底需要解决什么?
生成模型需要维护三种关系
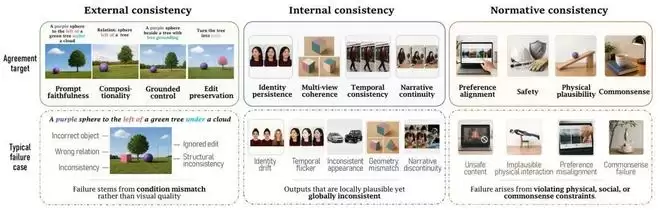
三类一致性关系及其失败模式
第一种关系:结果与用户条件之间的关系
用户输入了一段文本、一个布局、一张参考图或一条编辑指令——模型是否真正实现了这些要求?这被称为
外部一致性
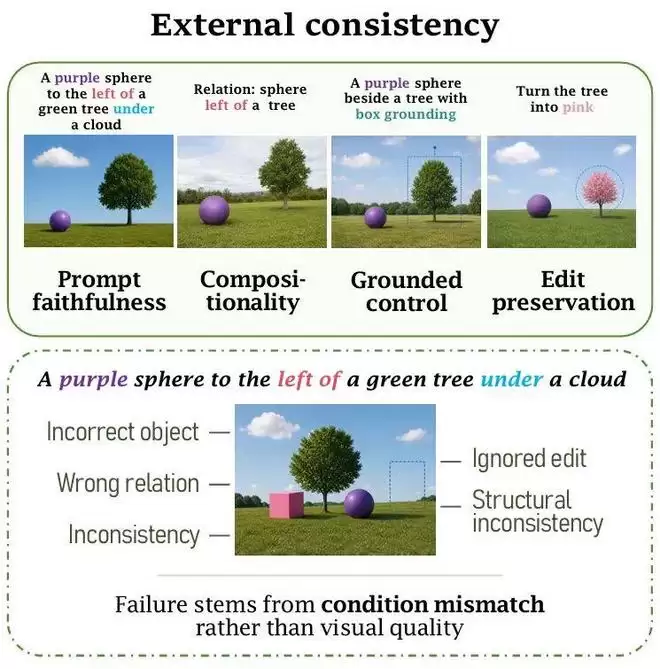
外部一致性
文生图中常见的物体遗漏、属性错绑、数量错误、空间关系混乱,都属于外部一致性失败。模型可能理解了prompt的主题,却没有把文本中的对象、属性和关系准确对应到视觉内容中。
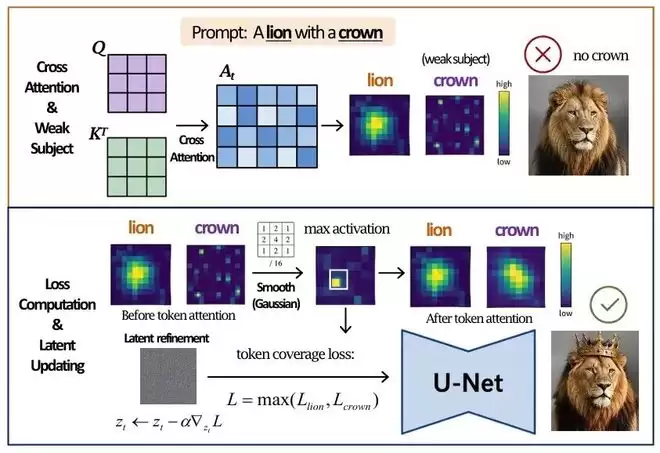
Attend-and-Excite原理
举个例子:“一只戴着皇冠的狮子”——不只要画出狮子和皇冠,还要求皇冠正确绑定到狮子头上。模型如果只画了狮子,或者把皇冠放在旁边,即使图像漂亮,任务也没完成。Attend-and-Excite、BoxDiff、GLIGEN等方法解决的,本质上就是语言条件没有被充分落实的问题。它们通过注意力修正、空间约束或grounding机制,加强文本单元与视觉实体的对应关系。
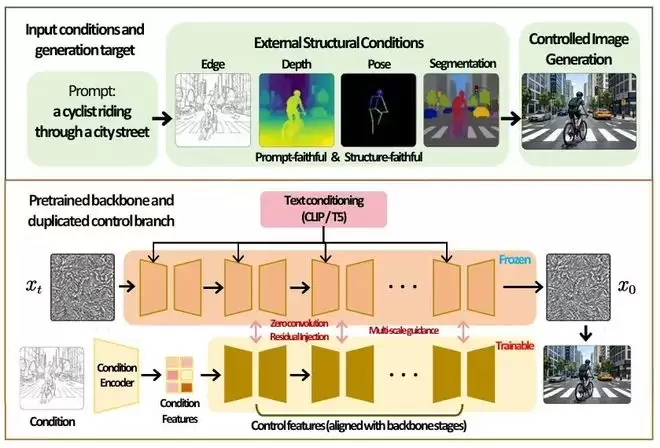
ControlNet原理
ControlNet、T2I-Adapter、IP-Adapter则把外部条件从文本扩展到姿态、深度、边缘、布局和参考图像,确保这些条件不是“提供给模型就完了”,而是真正进入去噪过程并影响最终结果。
图像编辑也属于外部一致性,但多了一层特殊要求:模型不仅要执行指令,还要保护不应该变化的内容。
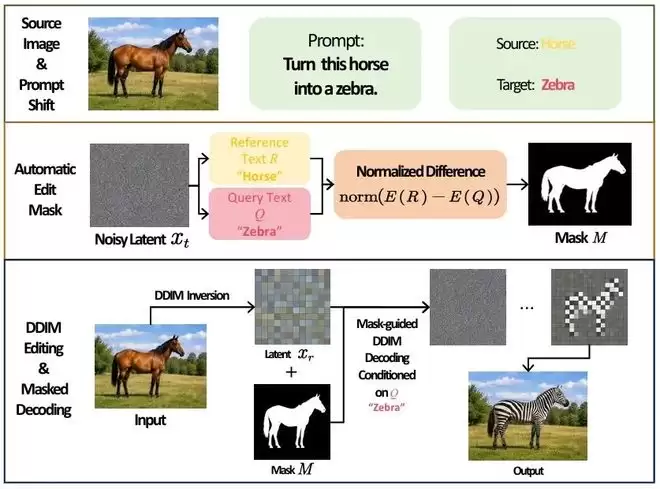
DiffEdit原理
“把马变成斑马”这个指令,并不意味着允许模型重新生成整个画面。合格的结果必须改变目标对象,同时保持原有姿态、构图、背景和其他区域。DiffEdit、Prompt-to-Prompt、InstructPix2Pix等方法的差异,就在于它们如何划定编辑范围,以及如何减少编辑对无关内容的影响。
所以,外部一致性关注的不是模型有没有“接收到”条件,而是这些条件是否能在最终结果中被清楚追踪。
第二种关系:多个生成结果之间的关系
当同一个主体出现在不同图片、不同视角或不同时间中时,模型是否仍然维护着同一个对象和同一个世界?这被称为
内部一致性
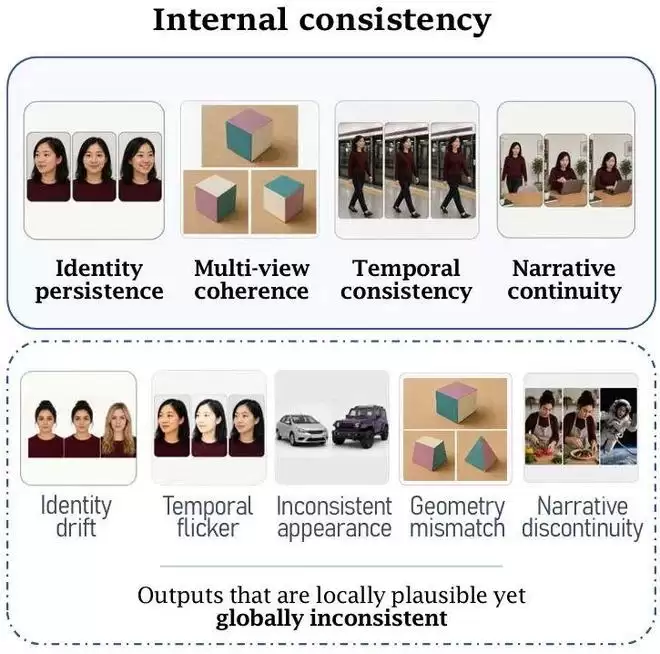
内部一致性
个性化生成是最直观的例子。
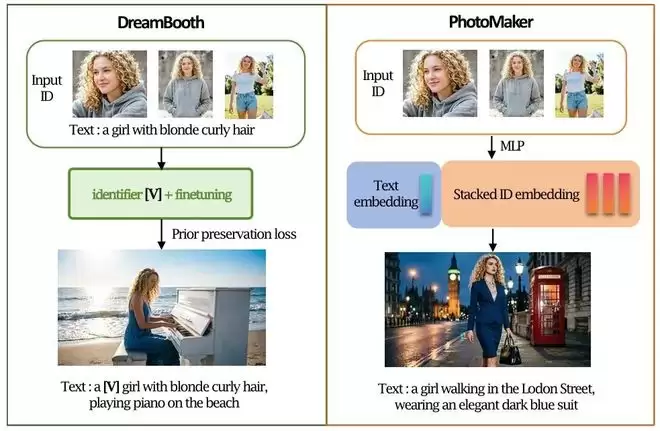
Dreambooth和PhotoMaker原理
DreamBooth把人物身份写入模型参数,PhotoMaker和InstantID则把参考图片编码成身份特征,在推理时注入生成过程。两条路线技术不同,但解决的是同一个问题:当背景、姿态、动作和风格变化时,哪些信息必须保持稳定,才能让人仍然认为这是同一个主体?
这里需要区分“外观复制”和“身份持续”。复制一张参考图中的脸相对容易,困难的是在视角、姿态和场景改变后,仍保持人物的脸部结构、发型、服装、配饰和角色特征。
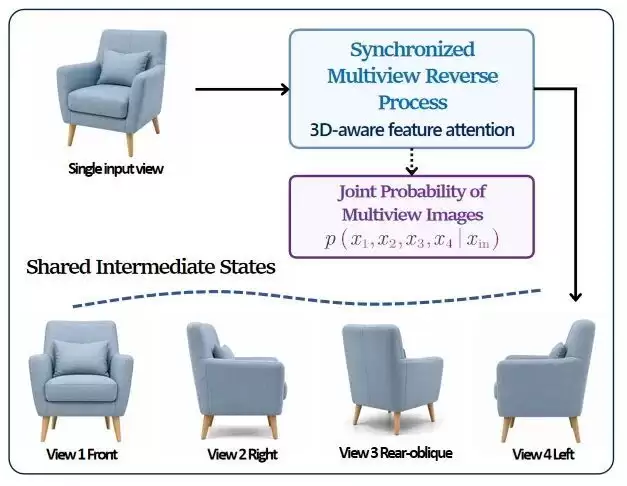
SyncDreamer原理
多视图生成把同一个问题推到了三维层面。模型不能只生成若干张彼此相似的图片,而必须让这些图片能够由一个共同的几何结构解释。Zero-1-to-3通过参考图和相机变化预测新视角,SyncDreamer和MVDream则在过程中联合多个视角,使它们共享中间状态。
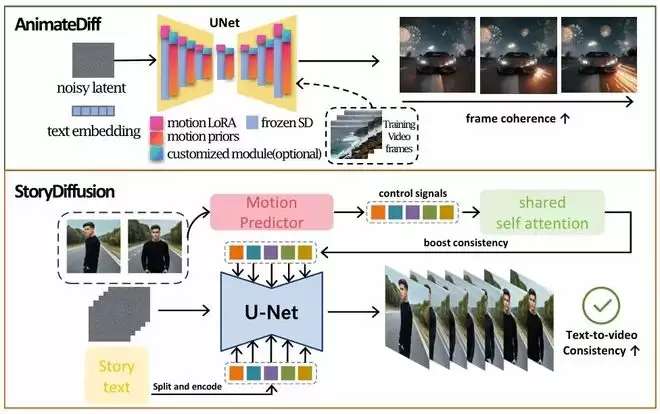
AnimateDiff和StoryDiffusion原理
视频和故事生成面对的也是类似问题,只是共享状态沿时间延伸。AnimateDiff通过运动模块建立短程帧间联系,StoryDiffusion、TaleCrafter等方法进一步尝试维护角色、服装、场景和事件状态。
从这个角度看,视频生成并不是“连续生成很多张图片”,而是在不断回答一个状态问题:前面已经发生了什么?接下来允许发生什么?只要模型缺乏持久状态,即使每一帧都足够真实,长序列仍然会出现身份漂移、物体消失、动作断裂、事件矛盾。
第三种关系
不来自当前prompt,也不只存在于不同生成结果之间,而来自系统默认应该遵守的评价标准——这称为
规范一致性

规范一致性
一张图可以完全符合prompt,也可以在不同场景中保持人物身份,但它仍然可能不符合人类偏好、包含不安全内容,或者违反基本的物理和因果规律。偏好优化、安全生成、物理世界建模,表面上属于不同研究方向,但它们共享一个结构:模型需要与某种长期生效的标准保持一致。
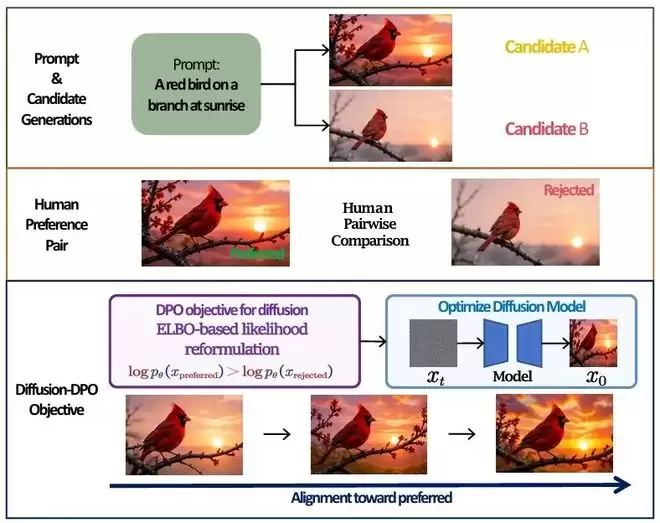
Diffusion-DPO原理
ImageReward、HPS、VisionReward等方法尝试从人类选择中学习“什么样的结果更好”;Diffusion-DPO、FlowGRPO、DiffusionNFT等进一步利用这些信号优化生成模型。安全方法则通过训练目标、参数编辑、采样引导或输出过滤,降低危险内容的生成概率。
物理和因果一致性关注的是另一类标准。一个视频可能运动平滑、画面逼真,却出现物体穿透、重力失效、状态跳变或因果倒置。PhyBench、VideoPhy、PhyGenBench等基准正是为了暴露这类传统图像质量指标无法发现的问题。
小结:三种关系并不是互相排斥的任务标签
一个个性化编辑系统通常同时需要遵守编辑指令、保持人物身份、满足安全和审美标准。一个长视频系统既要按文本脚本生成内容,也要维护人物和场景状态,还要保证事件演化符合基本物理规律。
所以,三种一致性更像三个观察角度:
- 回答模型是否遵守条件;
外部一致性
- 回答模型是否维护已经建立的状态;
内部一致性
- 回答模型是否符合默认生效的评价标准。
规范一致性
一致性写入生成流程的不同位置
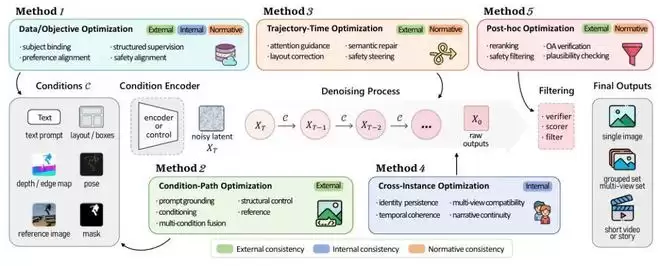
优化扩散模型生成一致性的几个位置
知道了模型要维护什么关系,下一步的问题是:这些关系应该在哪里被加强?
现有方法虽数量庞大,但大体可以放进一条扩散生成流水线中理解。
- :改变数据和目标函数,将身份、偏好、安全或结构约束直接写入模型参数。优点是一致性持续性较强,但需要额外训练,也可能影响模型的其他能力。
训练阶段
- :ControlNet、T2I-Adapter、GLIGEN、IP-Adapter关心的是文本、布局、姿态、深度和参考图如何被编码,以及这些信号如何进入扩散模型。核心目标是让外部条件成为生成过程中的有效约束,而不只是一个弱提示。
条件接口
- :Attend-and-Excite检查哪些文本概念在注意力中被忽略,Prompt-to-Prompt控制编辑过程中的注意力变化,BoxDiff通过空间目标修正中间latent。这类方法不一定需要重新训练模型,但干预过强时可能降低视觉质量、多样性或采样效率。
去噪轨迹干预
- :对于身份、多视图和视频任务,仅仅修正单条生成轨迹往往不够。模型需要让多张图片、多个相机视角或多个视频帧共享特征、注意力、中间状态或外部记忆。此时,一致性不再属于单个样本,而属于整个联合生成过程。
跨实例共享状态
- :不修改生成器本身,而是在生成完成后使用奖励模型、安全过滤器、重排序器或物理验证器筛选结果。这种方式容易接入现有系统,但主要处理已经产生的错误,不能从根本上改变模型生成不一致内容的倾向。
事后验证
这五类位置说明:一致性并不对应某个万能模块。它可以被写入参数、通过条件注入、在去噪过程中修正,也可以通过多个样本的联合生成或事后验证来维持。不同位置之间可以组合,但组合越多,新的问题就越明显:不同模块可能同时修改同一组特征,甚至提出相互矛盾的要求。
为什么现有评价经常测不清一致性
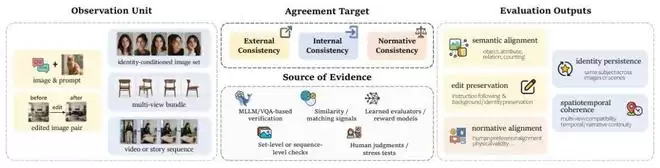
一致性的评估方法
一致性研究中的一个常见误区,是试图找到一个能够概括全部能力的总分。但prompt忠实度、身份保持、时间连续性、安全、物理合理性,并不是同一种属性。更关键的是,它们甚至不能在同一种观察对象上被测量。
- Prompt一致性通常比较一张图片和一段文本。
- 图像编辑需要比较编辑前后的图像。
- 身份一致性需观察由同一主体生成的多张结果。
- 多视图一致性必须同时检查多个视角。
- 视频和故事一致性则需要沿时间追踪人物、物体和事件状态。
因此,很多评价失败并不是因为指标不够先进,而是因为观察单位选择错误。单张图片中不存在“跨帧身份漂移”这个问题;两张相邻视频帧看起来平滑,也不能证明几十秒后的角色和场景仍然一致;人脸相似度很高,不代表服装、配饰和角色属性没有变化;图文相似度很高,也不代表对象数量和空间关系正确。
评价一种一致性,至少需要明确四件事:
- 观察的是单张图、图像对、图像集合、多视图还是序列;
- 检查的是语义、结构、身份、几何、时间状态还是规范标准;
- 使用的是VQA、特征相似度、几何信号、奖励模型、安全分类器还是人工判断;
- 输出的是正确率、保持度、兼容性、偏好分数还是风险诊断。
所以,一致性评价不是寻找一个万能指标,而是建立一个覆盖不同关系的评价组合。一个可信的生成系统不应该只报告“整体表现更好”,而应该说明它在哪些约束上得到提升,又在哪些能力上付出了代价。
一致性并不是越强越好
如果三种一致性都很重要,自然会想“把它们同时加强”。真实情况是,不同一致性之间经常发生冲突。
更严格地执行prompt,可能迫使模型生成不自然的构图,降低审美质量。更强的身份绑定可以减少人物漂移,却也可能把服装、背景和姿态一起锁死,使人物难以编辑。更强的跨帧共享能够减少视频闪烁,但可能限制运动幅度,让结果显得僵硬。更激进的安全擦除可以降低危险内容,却可能误伤正常概念和无害请求。严格物理约束适合机器人和仿真,未必适合超现实主义和开放式艺术生成。
因此,一致性真正困难的部分,并不是把某个单独指标做到最高,而是在多个目标同时出现时处理它们之间的关系。系统需要知道哪些条件是必须满足的硬约束,哪些只是可以调整的软偏好;需要检测不同条件是否发生冲突,并说明为了提升一个目标牺牲了什么。
目前多数方法仍然围绕单个目标设计。一个模块负责身份,一个模块负责姿态,一个模块负责安全,另一个奖励模型负责美学。把这些模块接到同一个系统上,并不会自动产生协调。这也是一致性研究下一阶段最关键的问题:从分别强化不同约束,走向能够理解、解释和处理约束冲突的生成系统。
从“高质量生成”走向“可靠生成”
过去几年,视觉生成的主要目标是让模型产生更真实、更清晰、更美观的内容。但当生成模型走向编辑、个性化、长视频、三维资产、仿真和具身智能时,视觉质量已经不再足够。
模型必须学会维护三类关系:遵守用户给出的条件,记住自己已经建立的主体和世界状态,以及在用户没有逐条说明时,仍然符合安全、偏好、物理和因果标准。
这要求未来的生成模型具备几种今天仍然不足的能力:
- :模型不能只接收多个条件,还需要理解这些条件何时互相矛盾,以及应该如何确定优先级。
冲突感知
- :人物身份、场景结构和故事历史需要被稳定保存,但这些状态又不能僵化到无法被新指令修改。
持久但可编辑的状态
- :系统不应该只输出一个总分,而要能够说明自己在哪种一致性上成功或失败。
可解释评价
- :对于视频、世界模型和具身智能,仅仅生成连续像素并不够,模型还需要维护对象、状态、动作、物理关系和因果演化。
从视觉相关性走向世界结构
因此,一致性并不是生成质量之外的附加要求。它更接近一条分界线:一侧是能够产生漂亮样本的生成模型,另一侧是能够在复杂条件下长期、稳定、可控地工作的生成系统。
结语:从“美观”到“可靠”
回看扩散视觉生成的发展,过去几年的核心进步主要体现在一个维度上:模型越来越擅长生成局部真实、视觉精致的内容。但当任务从单张图像扩展到复杂提示词、图像编辑、个性化、多视图、长视频和世界建模时,视觉质量不再足以判断一个系统是否真正完成了任务。
一个结果可以在像素层面几乎无可挑剔,却在语义、身份、时间、空间或物理关系上完全错误。生成模型面临的关键问题,正在从“能不能生成”转向“能不能持续维护正确的关系”。
这也是本文提出一致性视角的根本意义。外部一致性要求模型对用户条件负责;内部一致性要求模型对自身已经建立的状态负责;规范一致性要求模型对更广泛的评价标准负责。三者分别对应生成系统的控制能力、记忆能力和世界约束能力,也共同构成了生成模型从视觉工具走向可靠系统的基础。
从这个角度看,一致性并不是附加在图像质量之外的又一个指标,而是一种重新理解生成任务的方式。它提醒我们,生成质量本质上不是单个样本的孤立属性,而是输出与条件、输出与输出、输出与评价标准之间的一组关系。
很多过去被分散讨论的问题——提示词遗漏、身份漂移、视频闪烁、多视图矛盾、安全失效和物理错误——并非彼此独立,而是在不同尺度上暴露了同一个缺陷:模型能够产生合理的局部表象,却缺乏稳定维护全局约束的能力。
这也解释了为什么一致性无法依靠一个统一模块或一个总分解决。不同关系需要在训练目标、条件接口、去噪轨迹、跨实例状态和输出验证等不同位置被约束,也需要单图、图像对、集合、视角组和长序列等不同观察单位来评价。未来真正可信的评估体系,不应只告诉我们模型“整体更好”,而应明确指出它遵守了哪些关系、在哪些关系上失败,以及为提升一种一致性牺牲了哪些其他能力。
更深层的挑战在于,不同一致性目标并不总是方向一致。更强的提示词约束可能损害美感,更稳定的身份绑定可能降低可编辑性,更紧密的时间耦合可能压缩运动多样性,更严格的安全或物理约束也可能限制正常能力与开放式创造。
因此,下一阶段的研究重点不应只是继续强化单个约束,而应让模型能够识别冲突、表示优先级、保留长期状态,并在不同任务和用户需求下进行可解释的权衡。
如果说过去的生成模型主要学习“怎样产生一幅看起来合理的画面”,那么未来的生成系统还必须进一步学习:什么必须保持不变,什么可以被修改,哪些状态需要长期记住,哪些约束在冲突时应当优先,以及一次生成行为会对后续世界产生什么影响。
只有当模型能够稳定回答这些问题,视觉生成才会真正从高质量内容合成,迈向可控制、可持续、可验证的智能生成。
参考资料:
https://www.preprints.org/manuscript/202606.0870/v1



-
archiveofourown 实战指南:常见用法整理
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
电视剧《小欢喜》剧情介绍
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
俄罗斯最大yandex入口外贸日报直达链接
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
美好的简约网名男生(精选100个)
-
植物娘大战僵尸电脑端与手机端存档转移的方法
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
盖乐世社区怎么删除帖子?盖乐世社区个人发布内容撤回步骤
-
腾讯元宝怎么用来分析股票基金的基本面信息?
-
二次元男生网名可爱(精选100个)
-
wallpaper壁纸声音怎么开启
-
国际贵金属走低,现货黄金价格跌0.49%
-
问题:CIA币好不?Cia Protocol币今日上线:价格预测、代币经济学和未来潜力
-
独家/李宰旭入伍前「登上孤岛服役」 惊见前辈裸体:忍不住笑了
-
短剧《嫡女她是山大王》剧情介绍
-
新浪人工智能热点小时报丨2026年06月20日02时_今日实时人工智能热点速递
-
Bubbly无法连接服务器修复方法
-
免费观看国外短视频的app有哪些 观看国外短视频的软件下载
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
1 大家平时都是怎么用AI的? 07-03
-
2 从写代码到写Prompt,我们失去了什么? 07-03
-
4 低代码邂逅AI:中小企业创新的新引擎与边界探索 07-03
-
5 GEO 如何帮助企业获客 07-03
-
7 AI 陪伴,你到底是在说什么? 07-03
-
8 Agent客服全面接管排障任务,智能锁品牌服务效率翻倍提升 07-03
-
10 Token账单失控?拆解AI规模化部署的“三重成本黑洞” 07-03



