给文档中心装个 AI 大脑:轻量RAG智能问答助手的设计与取舍(开源)
来源:互联网 更新时间:2026-06-28 07:32
我们先从每天都会遇到的一个场景说起。
无论是企业内部的Wiki,还是对外官网的帮助中心,亦或是云厂商的产品文档,我们想找一个具体答案时,迎接我们的,绝大多数时候都是一个搜索框。

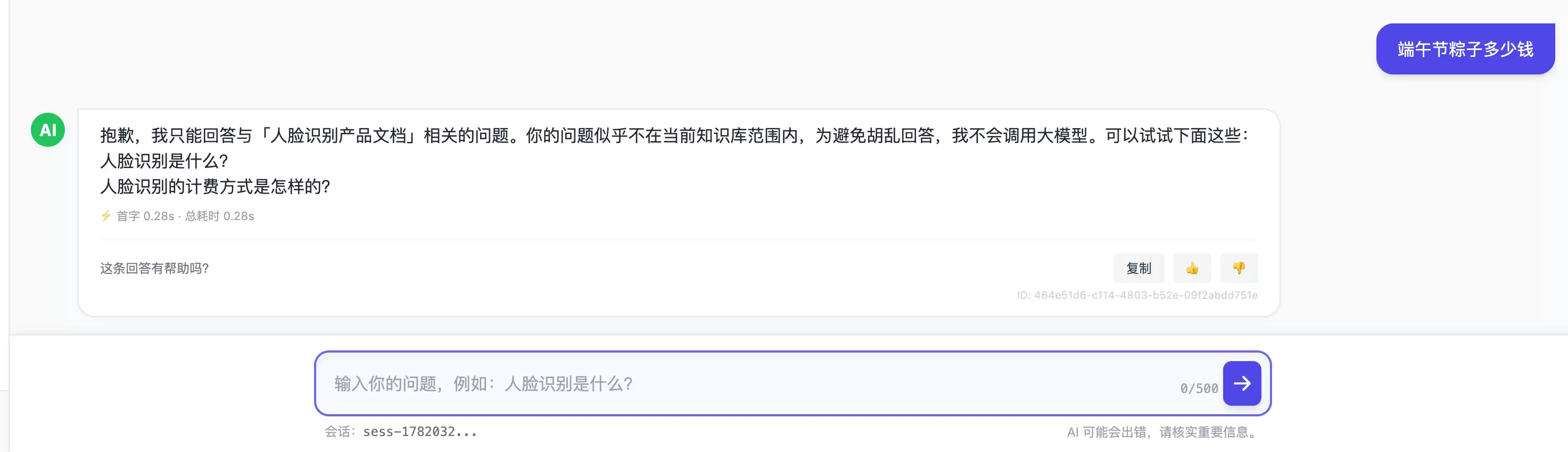
这个搜索框的本质,其实是“找页面”,而不是直接“给答案”。你搜“人脸识别计费方式”,它返回十几篇标题里带“人脸识别”和“计费”关键词的文档。至于哪一篇、哪一段才是你要的,你得自己一篇篇点开读,再在脑子里拼凑答案。它把“理解问题、定位答案、归纳表述”这三件最费神的事,全留给了用户。
这两年,很多文档中心开始接入AI智能客服,方向是对的。但在实际体验中,我反复遇到两个工程层面的硬伤:
最让人头疼的,一是
响应慢
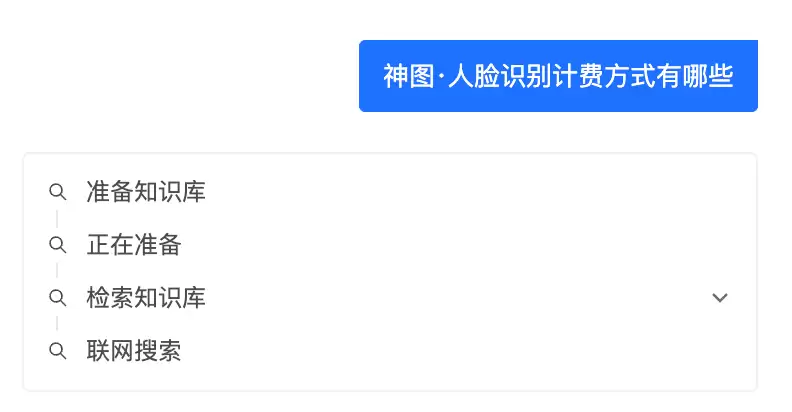
二是
重复问题重复算
之前在公司内部做过一版“官网文档中心智能问答助手”的技术架构,踩过检索质量、并发和成本控制上的不少坑。最近把那套思路从业务中抽离出来,并对技术架构做了精简,重写开源了一个轻量版本,取名DocMind,供有同样诉求的团队参考。这篇是系列开篇,我想把它的设计目标、整体架构和几个关键工程取舍讲清楚——重点不在于“它能跑”,而在于“为什么要这么设计”。
二、它是什么:一句话与三条设计原则
先给一句话定义:
在重写和开源之前,定了三条设计原则,后面所有的取舍都围绕它们来展开:
轻量可落地
敢对外开放
跨语言
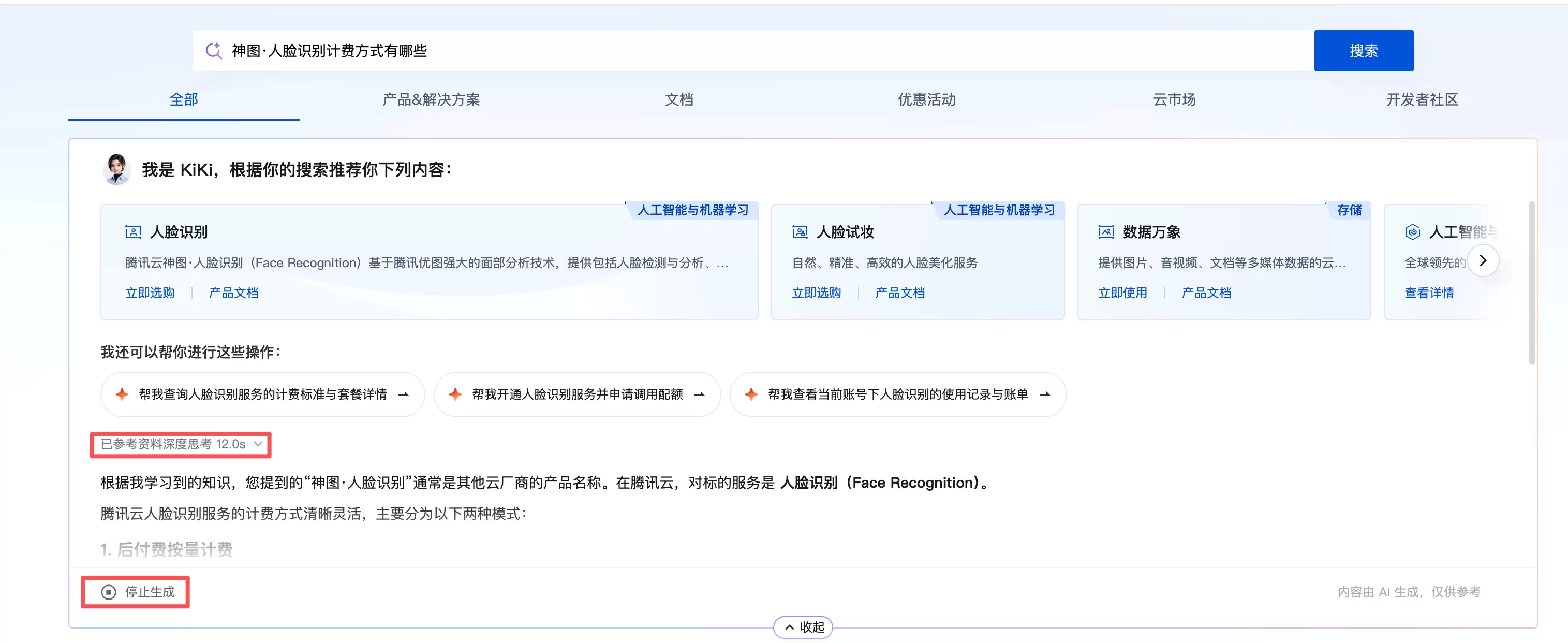
它实际跑起来的样子(Demo用一份公开产品文档作为知识源):
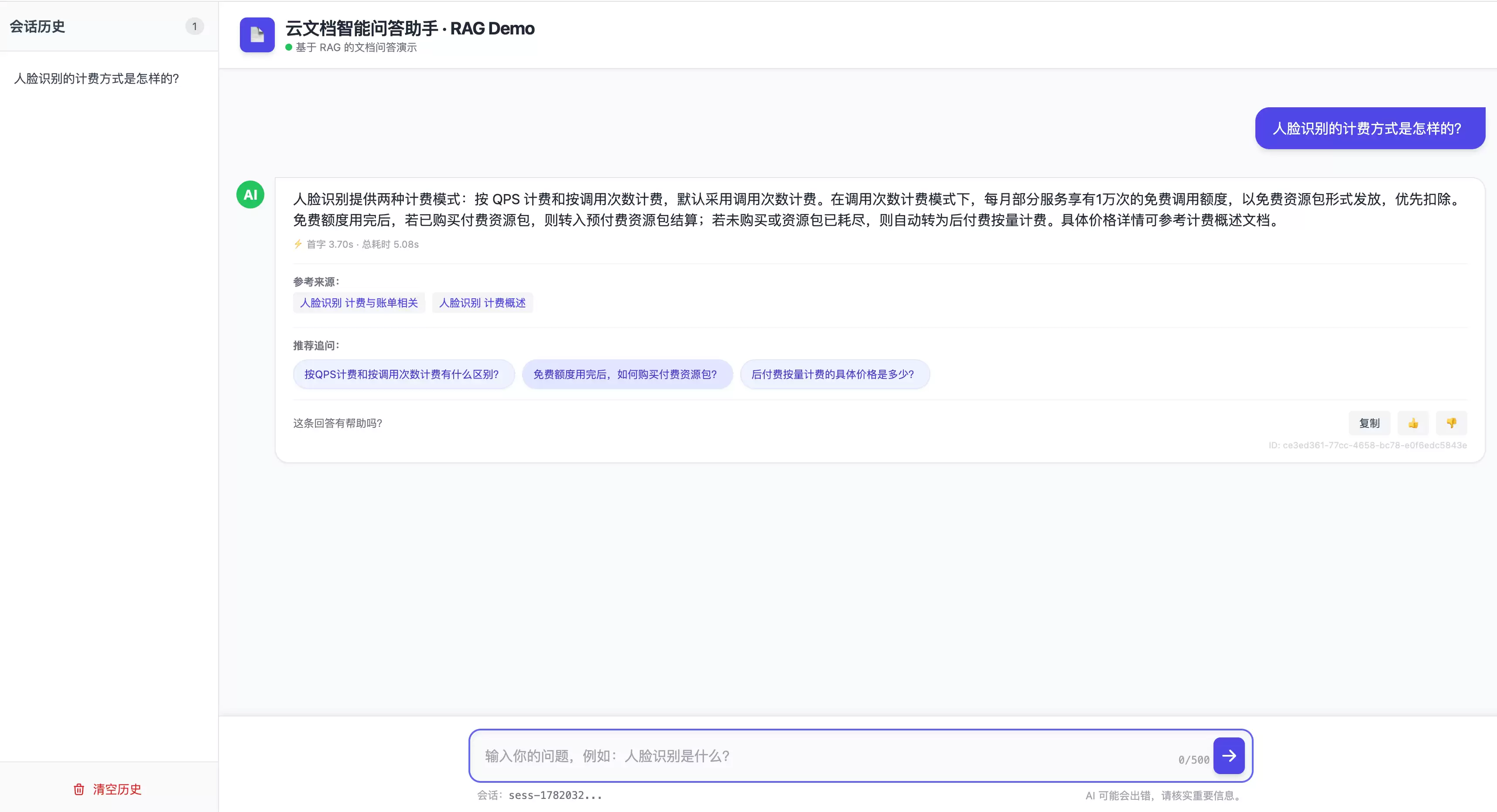
留意答案下方两个细节:响应耗时是明着标出来的,参考来源点开就是原文。这两个看似不起眼的设计,背后都是刻意的工程考虑。
三、整体架构:离线建库 + 在线AI问答
抛开细节,DocMind本质上就是两条链路:离线建库和在线问答,简略说明如下:

3.1 离线建库:把一个文档站变成可检索的知识
①
抓取范围按路径前缀限定
.../document/product/867,系统就只爬这一个产品的文档,不会顺着导航链接把整个站点都拖下来。这是个很实用的“圈地”机制——文档站内部互链极多,没有这个约束,爬虫会迅速失控。
②
正文容器自动识别
.markdown-body(常见markdown主题),都命中不了才回退整个③
切片:诚实地说,目前是固定窗口
④⑤
向量化与增量更新
url / title / chunk_index元数据——title后面用于来源溯源的友好展示。重复ingest时,按页面内容哈希判断是否变化,未变则跳过,并清理掉已不存在的过期文档,做到增量而非每次全量重灌。
3.2 在线问答:从一句提问到一段带出处的回答
⑥
语种识别
⑦
向量检索Top-3
⑧
相关度阈值闸门:查不到就老实说没有
这个闸门同时解决三个问题:
- :没有上下文支撑时,宁可说“我这儿没有这个信息”,也不让模型硬编一个似是而非的答案。
防幻觉
- :无关提问被挡在LLM之前,不产生Token消耗。
省成本
- :让助手始终待在“文档知识范围内”,不被诱导去回答它不该答的问题。
划边界
对于一个面向公众的问答系统,“敢于拒答”比“什么都敢答”要可靠得多。
⑨
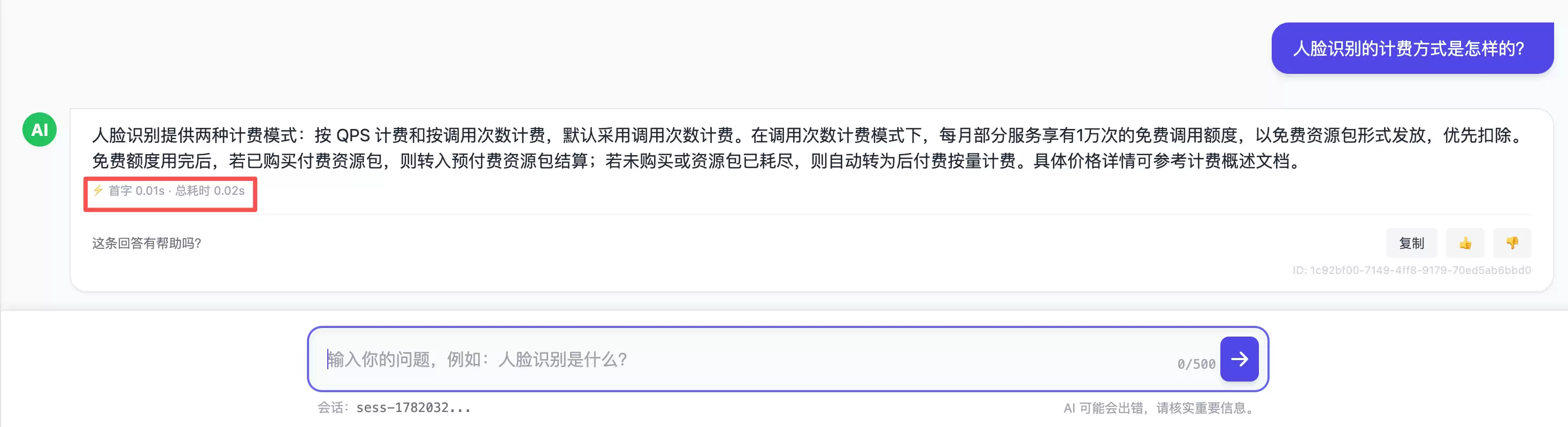
缓存:相同问题,算一次复用多次
需要把话说准:这是精确匹配缓存,不是语义缓存——“人脸识别是什么”和“什么是人脸识别”目前会被当作两个问题。把它升级成语义级缓存是一个有价值的方向,但也要权衡误命中的风险,这个取舍留待后续。
⑩
上下文组装与截断
⑪
后处理:把回答收拾干净
⑫
输出、溯源与追问
四、几个值得说的工程取舍
4.1 “流式”其实是模拟的——一个有意识做出的取舍
界面上回答是逐字蹦出来的打字机效果,但我要诚实地讲清楚它的实现:上游LLM调用是非流式的——我先一次性拿到完整答案,再在本地把它切成小片,通过SSE逐片下发,模拟出流式效果。
为什么不直接用真流式?因为我在拿到完整答案后还要做两件需要全文才能做的事:语言一致性纠偏、剥离开头废话;以及把完整答案写入缓存。真正的逐Token流式,会让这些“针对全文的后处理”变得复杂得多。
它的代价我也不回避:因为要等全文生成完才开始吐字,界面上的“首字耗时”其实约等于整段生成时间(这也是为什么Demo里首字~3s、总耗时~4s两个数字很接近)。所以可以这样理解:demo项目真正的“快”,是缓存命中时的秒回,而不是首次生成的首字延迟——首次延迟取决于你接的上游模型。
如果要兼得,正确方向是“真流式 + 增量后处理”(边收Token边做可增量的清洗),这是已列入计划的优化项。
4.2 把“耗时”显示做成一等公民
特意把每条回答的首字/总耗时直接显示在界面上。这不只是个炫技的小徽章——它是一种对用户和对自己的诚实:用户能直观感知快慢,自己也能借它快速评估“换个上游模型值不值”“缓存命中率高不高”。一个系统愿不愿意把自己的延迟摊在明面上,某种程度上反映了它对自身表现的底气。
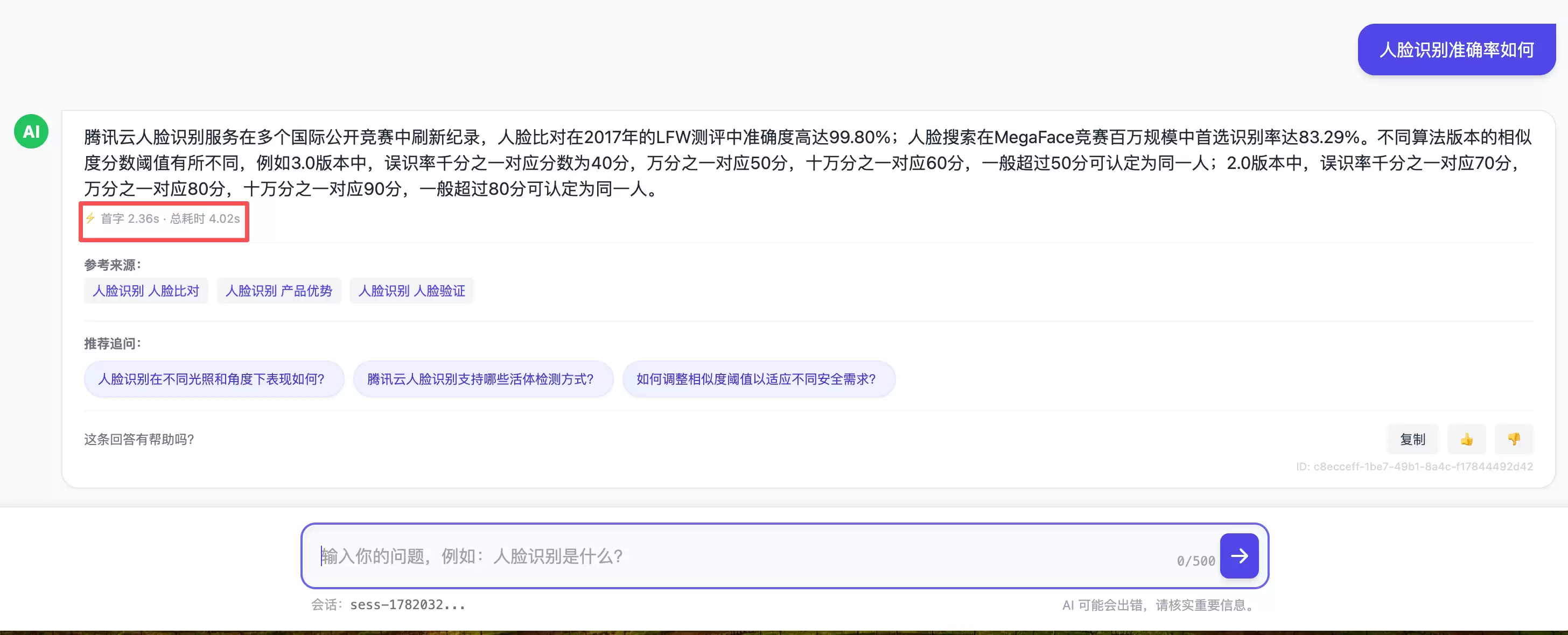
4.3 来源溯源:让AI不是黑箱嘴替
每个回答都带回它依据的文档标题和链接,用户一点就能跳到原文核对。对文档问答这种“答案必须可信”的场景,可溯源不是加分项,是底线——它把“AI说的”还原成“文档里写的,AI只是帮你找到并归纳”。
4.4 轻量的理由与代价
无Redis、无MongoDB——向量库用嵌入式ChromaDB(一个本地目录),审计/反馈与爬虫元数据各用一个SQLite文件,限流、缓存、会话历史等运行时状态用进程内的LRU + TTL容器承载。
好处是部署极简,从git clone到能跑只需几步。代价也很清楚:进程内状态意味着单实例——要做多副本水平扩展,这些内存态就得外移到共享存储。这是一个明确的定位取舍:DocMind服务的是中小规模文档中心的“轻量落地”,不是为超大规模高可用集群设计的。
4.5 为什么没有直接套一个现成RAG框架
这个问题绕不开:LangChain、LlamaIndex、Dify这些成熟方案都在,为什么还要自己写一套?
我的判断是:对这个具体场景,自己实现这条主干链路的边际成本,低于驾驭一个大框架的认知成本与约束成本。RAG的核心链路——爬取、切片、向量化、检索、阈值判断、组装、调用——本身并不复杂,代码量可控、每一步都看得见摸得着。而通用框架为了覆盖所有场景,引入了大量抽象层;一旦我需要做“阈值拒答”“输出侧剥废话”“精确匹配缓存”“面向公网的多维限流”这类贴着业务的定制,在框架的抽象里反而要绕路、甚至要和它的默认行为对抗。
这不是说造轮子更高明——而是在“可控、可读、可改”和“开箱即用、但内部是黑箱”之间,为这个项目选了前者。如果是一个要快速对接几十种数据源、上百种工具的复杂Agent系统,我的选择会反过来。技术选型从来不是比谁更先进,而是看它是否匹配你当前要解决的问题的形状。
4.6 可观测与反馈闭环:上线只是开始
一个要对外服务的系统,光能跑还不够,得“看得见、调得动”。这块做了两件事:
- :每一次问答、每一条用户反馈,都同时写到结构化日志(stdout JSON,方便实时
审计双写
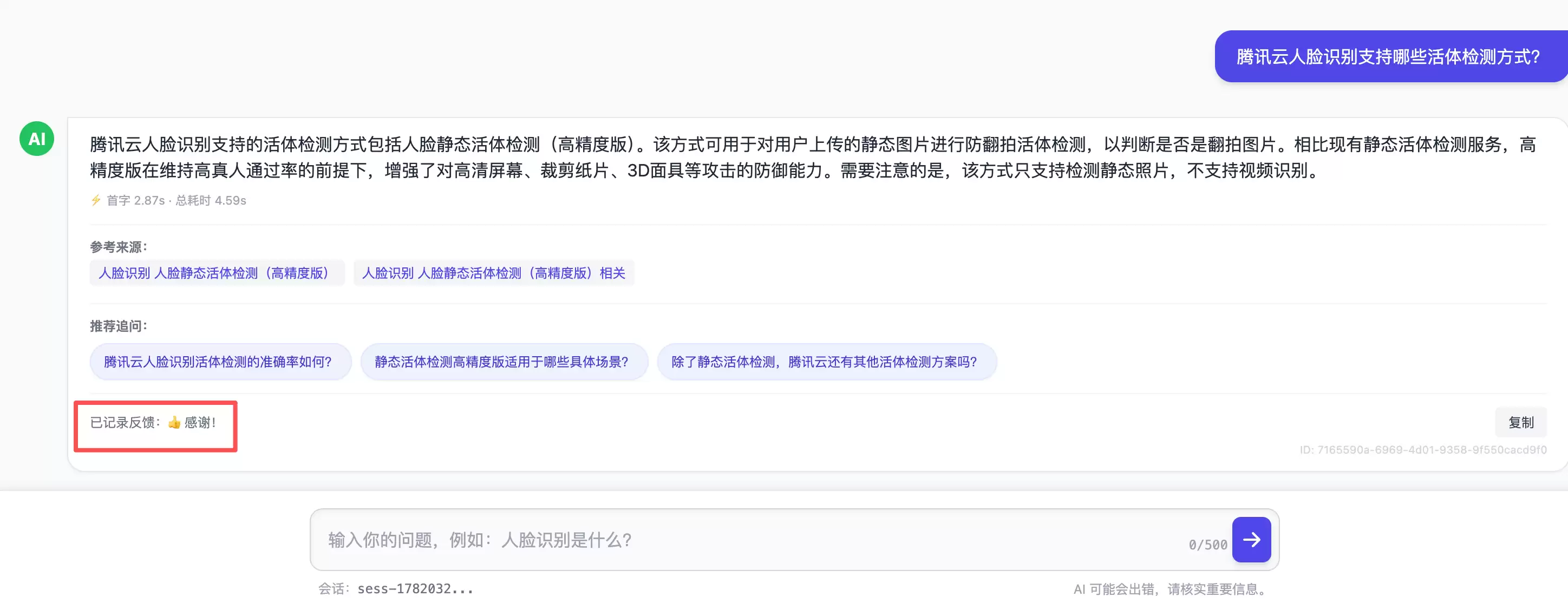
grep+jq)和一个独立的SQLite表(支持分页、过滤、关键字检索)。每条记录带request_id,可串起全链路追踪。需要强调的是:审计数据绝不进向量库——避免有人通过提问反查到“别人问了什么”。 - :每条回答下方有? / ?,差评可填具体原因。这些反馈结构化落库,是后续迭代“哪些问题答得不好、知识库哪里有缺口”的第一手依据。一个问答系统的质量不是上线那一刻定死的,而是靠这个闭环持续往上走。
反馈闭环
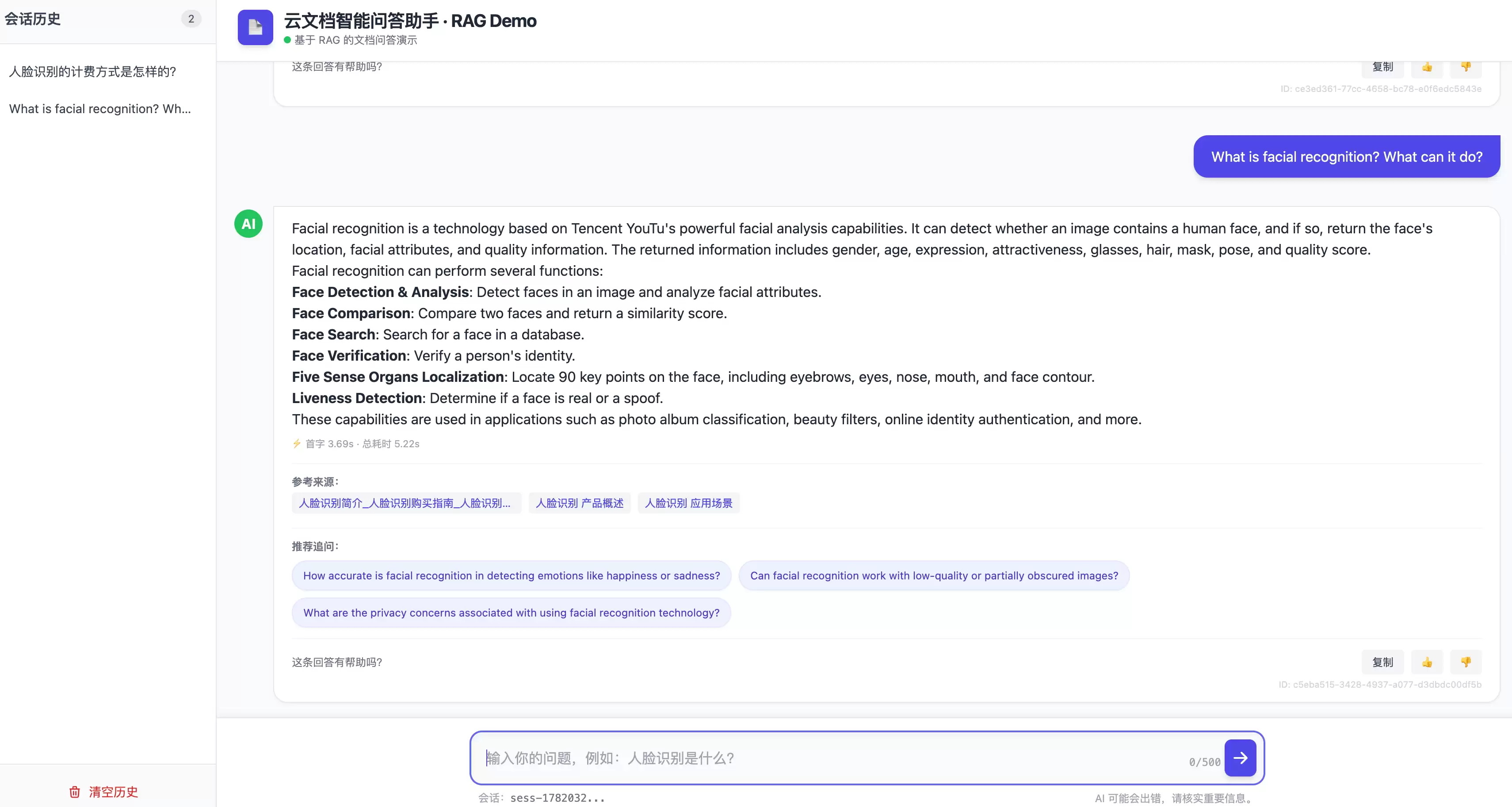
五、跨语言:一份中文文档,服务多语种用户
这是我最看重的能力,第2篇会完整展开,这里先给一个准确的轮廓。
传统多语言方案往往是“把文档翻译成N种语言、维护N套知识库”,成本和一致性都是负担。DocMind走的是另一条路:知识库只放一份原始文档(源文档是什么语言就是什么语言),靠BGE-M3多语言向量做跨语言检索——外语问题和中文原文被映射到同一语义空间,所以英语、日语等提问也能命中中文文档;回答语种则跟随提问语种(中英之间还做了一致性纠偏兜底,demo版本已进行精简,实际上可以基于用户原语言进行自动跟随的多语种问答)。
对有海外用户、或团队本身多语种的文档中心,这意味着:一份知识库,多语种可用,不必翻译、不必多套维护。至于“跨语言检索为什么能成立”“回复语种如何稳定控制”这些机制细节,留给第2篇。
六、技术栈一览
| 层 | 选型 | 说明 |
|---|---|---|
| 后端 | FastAPI + Uvicorn | 全异步,天然适合IO密集的检索+LLM调用 |
| 向量库 | ChromaDB | 嵌入式持久化,一个本地目录,无需独立服务 |
| Embedding | BAAI/bge-m3 | 本地多语言模型,跨语言检索的基石 |
| LLM | OpenAI兼容API | 默认DeepSeek,可换任意兼容网关 |
| 存储 | 2个SQLite文件 | 审计/反馈 + 爬虫元数据,无Redis / 无MongoDB |
| 前端 | 原生HTML/JS + TailwindCSS | 无构建步骤,一个静态页 |
整套东西的设计哲学就一句话:能不引入的依赖,就不引入。
七、快速上手(5步)
# 1) 克隆 + 装依赖
git clone https://github.com/lukyFun/search-ai.git docmind && cd docmind
pip install -r requirements.txt
# 2) 下载 embedding 模型(国内走 ModelScope 镜像更快)
pip install modelscope && python3 scripts/download_model_cn.py
# 3) 配置 .env:至少填 LLM_API_KEY;
# 换文档站只改 ASSISTANT_NAME / KNOWLEDGE_SCOPE / TARGET_URL 等几项,无需改代码
cp .env.example .env
# 4) 启动(首次会加载 BGE-M3 模型,约 5~10 秒)
bash run.sh
# 5) 建知识库:先 preview 验证抓取效果,再正式 ingest
python3 scripts/ingest_cli.py --mode preview --url "<你的文档入口>" --limit 5
python3 scripts/ingest_cli.py --mode ingest --url "<你的文档入口>" --limit 50
随后打开 http://localhost:8100 即可提问。换成你自己的文档站,通常只改配置、不动代码。
八、写在最后
DocMind想解决的诉求其实很朴素:让文档中心不止能“搜”、还能“答”;不止服务一种语言、还能服务全球用户;而且别太重、别太贵。
这一篇我刻意没有停留在“功能罗列”,而是把架构链路和几个关键取舍——模拟流式的代价、阈值拒答的边界、缓存的精确匹配局限、轻量的单实例代价——都摊开讲。因为我相信,一个系统可不可靠,不取决于它宣称了多少能力,而取决于它的作者是否清楚每个决策的代价、并诚实地标注出适用边界。
系列后续两篇会深入这次只点到的两个主菜:
- :跨语言问答是怎么做到的——BGE-M3多语言向量、语种自适应回复,以及“让RAG别瞎编”的检索质量工程(阈值、来源溯源、切片优化)。
第2篇
- :把它扔到公网——无中间件的轻量持久化、内存防OOM,以及面向公网的15层安全防护(多维限流、每日Token预算、提示注入拦截……)。
第3篇

-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
archiveofourown 实战指南:常见用法整理
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
电视剧《小欢喜》剧情介绍
-
全链网:黄金价格因美元的走强及利率担忧而下跌
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
有寓意的易经网名男生(精选100个)
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
植物娘大战僵尸电脑端与手机端存档转移的方法
-
动漫《柚木家的四兄弟》剧情介绍
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
拼多多品牌好货是官方店铺吗?拼多多品牌好货是官方还是自营店铺
-
独家/李宰旭入伍前「登上孤岛服役」 惊见前辈裸体:忍不住笑了
-
腾讯元宝怎么用来分析股票基金的基本面信息?
-
国际贵金属走低,现货黄金价格跌0.49%
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
1 小猿AI个性化练习题智能推荐系统详解 06-28
-
2 灵光AI闪应用生成入口:30秒手搓AI小工具官方网址 06-28
-
3 Canva_AI写App空状态文案提示词怎么输出可执行清单 06-28
-
4 文心一言AI工具清单文章提示词怎么写才能让每个工具都有适用场景 06-28
-
5 Notion_AI写产品迭代说明提示词有哪些实用问法 06-28
-
6 如何使用夸克AI搜索进行跨端文件同步管理 06-28
-
7 如何在文心AI中输入动作指令让角色做出特定姿态 06-28
-
8 怎样用夸克AI搜索自动拦截网页商业弹窗广告 06-28
-
9 Monica_AI写知识博主短文提示词怎么让AI先列判断标准 06-28
-
10 豆包写课程转化文案提示词怎么让AI先列判断标准 06-28



