决策树模型理论学习总结(一)
来源:互联网 更新时间:2026-06-26 07:29
最近在琢磨怎么用决策树模型做企业IT系统的故障根因分析,顺带把思路梳理了一遍。目前规划了两个方向:一个是用决策树模型做训练,另一个是结合大模型来搞。问了问DeepSeek,它给的建议大致是这样的——如果手头已经有历史故障数据,整理出了比较清晰的故障特征和结果标签,而且数据量不算特别大,那决策树其实是更务实的选择。万一碰到决策树没见过的复杂场景,再拿大模型来兜底,两者配合着做诊断,综合推断根因。
那今天这篇,就先聊聊决策树模型的理论底子。
一、决策树概念
决策树(Decision Tree)是分类与回归问题里最基础也最常用的算法之一。分类任务的目标是离散值,回归则是连续值。从分类问题的角度看,一般分两步走:第一步是模型构建,也就是归纳——通过对训练集的学习,建立分类模型;第二步是预测应用,也就是推论——用建好的模型去测试新样本。
决策树本质上就是通过一系列规则对数据进行分类。它的优点很明显:推理过程直观,能表示成If Then的形式;完全依赖属性变量的取值来做决策;还能自动忽略那些对目标变量没啥贡献的属性,顺带帮你筛掉不重要的变量,减少特征数量。
决策树技术背后,核心机制是归纳算法——从特殊到一般的推理过程。由于归纳学习依赖检验数据,有时也叫检验学习。整个决策树学习通常包含三个步骤:特征选择、决策树生成、决策树剪枝。
二、决策树的组成部分
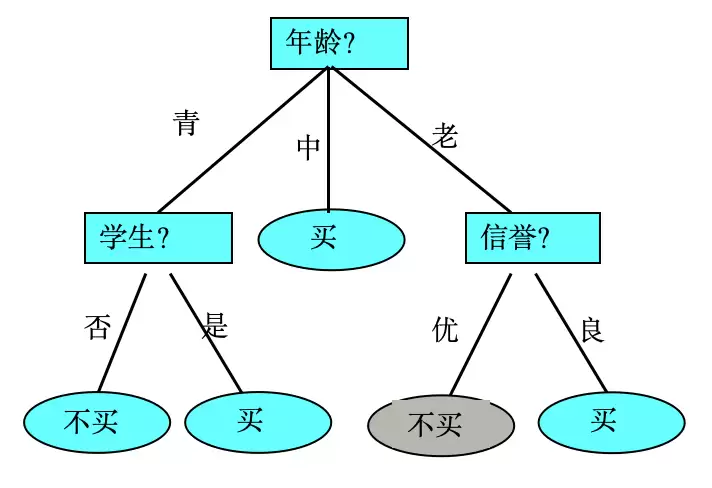
决策树的基本部件有三个:决策结点、分支和叶子。最顶上的叫根结点,是整棵树的起点。每个分支要么是个新的决策结点,要么直接连到叶子。每个决策结点代表一个问题或决策,通常对应一个待分类的属性;而每个叶结点,则代表最终的一种分类结果。
遍历决策树的过程,就是从根到叶一路向下:在每个结点做一次测试,根据测试输出的不同走向不同分支,最后抵达叶子结点。本质上,就是利用若干个变量来判断属性的类别。
三、熵、信息增益与基尼系数
这几个指标是决策树算法里绕不开的概念。
1. 熵(Entropy)
熵用来度量信息量的大小,或者说随机变量的不确定性。越有序,熵越低。计算公式是这样的:
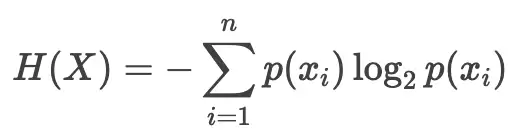
其中p(xi)是事件xi发生的概率。熵值越大,系统越混乱、越难预测。
2. 条件熵
设有随机变量(X, Y),联合概率分布如下:
条件熵H(Y"X)表示在已知X的条件下,Y的不确定性。定义为X给定条件下,Y的条件概率分布的熵对X的数学期望:
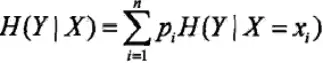
当熵和条件熵中的概率由数据估计(比如极大似然估计)得到时,对应的就称为经验熵和经验条件熵。
3. 信息增益算法

输入:训练数据集D和特征A;输出:特征A对数据集D的信息增益g(D,A)。
a. 计算数据集D的经验熵H(D):
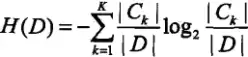
b. 计算特征A对数据集D的经验条件熵H(D"A):
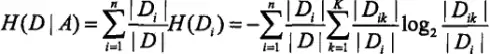
c. 计算信息增益:
4. 信息增益比
直接用信息增益选特征,容易偏向取值多的属性。信息增益比可以校正这个问题。特征A对训练集D的信息增益比定义为:信息增益与训练集D关于特征A的值的熵之比。
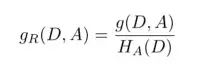
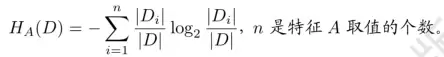
5. 基尼系数
基尼系数是CART树做分类时,衡量数据集或节点“不纯度”的核心指标。(CART做回归则主要用平方误差最小化。)
基尼系数反映的是:从数据子集中随机抽两个样本,它们类别标签不一致的概率。系数越大,不纯度越高。计算公式如下:
对包含K个类别的数据集D,Gini(D) = 1 - Σ (p_i)^2,i从1到K,其中p_i是第i类样本的比例。
举个例子:如果节点里全是A类,Gini = 1 - (1² + 0²) = 0,表示纯净;如果A和B各占50%,Gini = 1 - (0.5² + 0.5²) = 0.5,最不纯;如果是70% A和30% B,Gini = 0.42。
四、决策树算法介绍
1. 重要算法一览
决策树领域里,几个关键算法包括:CLS、ID3、C4.5、CART。
2. 发展历程
1966年,Hunt、Marin和Stone开发了CLS学习系统,用于学习单个概念。1979年,J.R. Quinlan提出了ID3算法,并在1983年和1986年做了总结和简化,使其成为决策树学习的标杆。1986年,Schlimmer和Fisher改造ID3,在每个可能的决策树节点创建缓冲区,实现递增式生成,称为ID4。1988年,Utgoff在ID4基础上推出ID5,效率进一步提升。1993年,Quinlan将ID3改进为C4.5。
另一条线是CART,跟C4.5不同,CART的决策树由二元逻辑问题生成,每个节点只有两个分支,分别对应正例和反例。
3. 各算法的特征选择方式
ID3用信息增益选特征,增益大的优先。C4.5改用信息增益比,解决信息增益偏好取值多的属性的问题。ID3和C4.5都基于熵模型,涉及大量对数运算。CART分类树则用基尼系数代替信息增益比,简化模型又不失熵模型的优点。基尼系数越小,不纯度越低,特征越好——这点和信息增益(率)正好相反。
4. 三种算法对比
五、Python的sklearn中的决策树初步介绍
sklearn的tree模块实现了两种决策树:DecisionTreeClassifier(分类树)和DecisionTreeRegressor(回归树)。分类树预测离散值,回归树预测连续值。
需要注意的是,sklearn中的分类树只实现了ID3和CART算法,而且没有内置剪枝步骤。如果要限制树的大小,可以在初始化时设置参数,比如max_depth(树的最大深度)、max_leaf_nodes(最大叶子节点数)。至于sklearn决策树在实际项目中的应用,后面会结合具体案例持续更新实操内容。
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
archiveofourown 实战指南:常见用法整理
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
有寓意的易经网名男生(精选100个)
-
电视剧《小欢喜》剧情介绍
-
美国市场:股票相对债券的风险溢价正在消失
-
全链网:黄金价格因美元的走强及利率担忧而下跌
-
618装机配置作业! 从入门到顶配 每一分钱都花在刀刃
-
电影《遁甲门之消失的公主》剧情介绍
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
动漫《柚木家的四兄弟》剧情介绍
-
植物娘大战僵尸电脑端与手机端存档转移的方法
-
卡厄思梦境哀嚎螺旋塔攻略 哀嚎螺旋塔怎么玩




