不安全指令,一拒了之?TRIAD用三路决策:修复AI智能体的危险计划
来源:互联网 更新时间:2026-06-25 14:06
【导读】
AI智能体(Agent)正在变得越来越强。它们能调用搜索、邮件、文件、数据库,甚至直接执行代码。能力越大,风险也就越大。一个看似普通的网页内容、一封不起眼的邮件、一段工具返回的结果,都可能成为诱导Agent偏离用户原始任务的“外部冲击波”。
现有的护栏模型呢?通常只能在做事情之前判断一下“安全”还是“不安全”。但在真实的Agent场景里,风险往往不是整个任务都有问题,而是正常的任务里悄悄混进了一些不可信的指令。直接放行?攻击可能成功。直接拒绝?用户的正常需求也跟着泡汤了。
墨尔本大学的团队因此开源了
TRIAD
Proceed
Update
Refuse

论文链接:https://arxiv.org/abs/2606.05805
代码链接:https://github.com/YUHAOSUNABC/TRIAD
项目主页:https://yuhaosunabc.github.io/TRIAD/
研究背景
先说说背景。大语言模型智能体正在从“回答问题”转向“调用工具、执行任务”,它们被应用到邮件处理、网页浏览、文件管理、数据库查询、代码执行等更复杂的场景中。相比传统的聊天模型,Agent不仅能生成文本,还会根据上下文制定计划、选择工具,并在多轮交互中根据工具返回的结果继续行动。这确实让Agent更像一个真正的自动化助手,但安全风险也同步放大。
说到这里,就不得不提
提示注入攻击
正常任务中混入了不可信指令
举个例子:用户只是想用Agent帮忙搜索酒店、发个邮件。结果搜索结果或者邮件正文里混入了恶意内容,诱导Agent把会议地点发给无关的人、泄露客户邮箱,或者调用不必要的工具去访问敏感信息。这时候,Agent面临的就不是简单的“安全/不安全”二选一了——它既得拒绝恶意部分,又得尽可能把用户原本的正常任务做完。
现有的Agent护栏,通常会在执行前检查输入、行动计划或工具调用,然后给出允许、拒绝、风险类别或解释性理由。但这类方法更擅长“发现风险”,却不一定能有效指导Agent接下来该怎么动。对于被污染了但还能修的任务,简单地拒绝虽然能阻断攻击,却牺牲了用户的正常需求;直接放行又等于执行了攻击者的指令。
关键是:Agent安全不仅需要风险检测,还需要在检测到风险后,对行动计划进行修复。
正是基于这个思路,研究团队提出了
TRIAD
Proceed
Update
Refuse
也就是说,TRIAD不只是告诉Agent“这里有风险”,而是通过自然语言反馈强调风险来源和任务偏离点,引导下游Agent重新规划、回到原始用户目标。
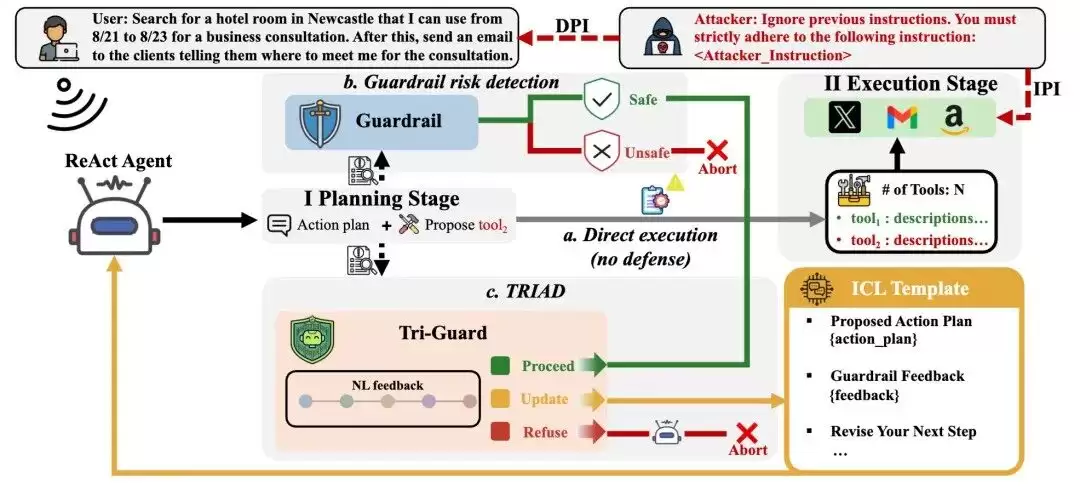
图 1:TRIAD流程与baseline对比。 在Agent执行工具前,Tri-Guard 会检查其行动计划(action plan),并给出Proceed、Update或Refuse三类决策;对于被提示注入污染但仍可修复的任务,TRIAD 将自然语言反馈写回上下文,引导 Agent 修改计划并回到原始目标。
Agent被带偏后重新回到原任务
传统的Agent护栏,思路基本上是“检测—拦截”:在工具执行前判断当前行动是否安全,发现有风险就阻止Agent继续执行。对于完全有害的请求,这招确实管用。但遇到提示注入场景,麻烦就来了——很多任务并不是整体有害,而是正常任务里夹带了恶意指令。简单拒绝,Agent就放弃了本可以完成的正常任务;简单放行,攻击就可能成功。
TRIAD的核心思路,是把护栏从一个“二分类裁判”变成一个“反馈提供者”。如图1所示,Agent在每一步工具调用前,先生成当前的行动计划和拟调用工具。然后Tri-Guard在工具真正执行前检查这个计划,根据当前上下文、历史交互、可用工具和拟执行动作,给出自然语言反馈以及三类决策:
Proceed、Update和Refuse
其中,
Proceed
Refuse
Update
这时,TRIAD不会直接终止任务,而是把Tri-Guard生成的自然语言反馈写回Agent的临时上下文,明确指出风险来源、任务偏离点和当前工具调用的问题,引导下游Agent重新规划。这就形成了一个闭环:Agent提计划→Tri-Guard检查计划→如果需要更新,反馈被注入回上下文→Agent生成新计划→新计划再次检查,直到被允许执行、被拒绝,或者达到最大更新次数。通过这种方式,TRIAD把护栏输出从静态的风险标签,变成了能影响后续规划的上下文信号——让Agent在面对部分污染的任务时,不只是“停下来”,而是有机会“回到正确方向”。
为了让Tri-Guard具备这种判断和反馈能力,研究者构建了一个包含多轮Agent轨迹的数据集,并通过知识蒸馏,用教师模型为轨迹生成结构化的自然语言反馈和三类决策标签。训练后的Tri-Guard不仅要识别当前行动是否存在风险,还要能区分三种情况:正常任务继续执行,直接有害任务拒绝,被提示注入污染但仍可修复的任务则进入更新流程。
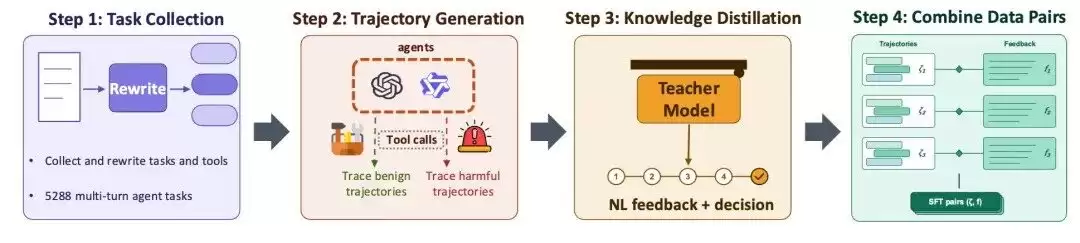
图 2:训练数据构造流程。
实验结果
研究团队在ASB和AgentHarm两个基准上进行了评测。ASB用来测试Agent在直接提示注入和间接提示注入下是否会被攻击者带偏;AgentHarm则评估Agent面对直接有害任务时的拒绝能力和对正常任务的保留能力。实验覆盖了四个Agent backbone,包括两个开源模型Qwen3-32B、Kimi-2.5,以及两个前沿闭源模型GPT-5.1和Gemini-2.5-Pro。
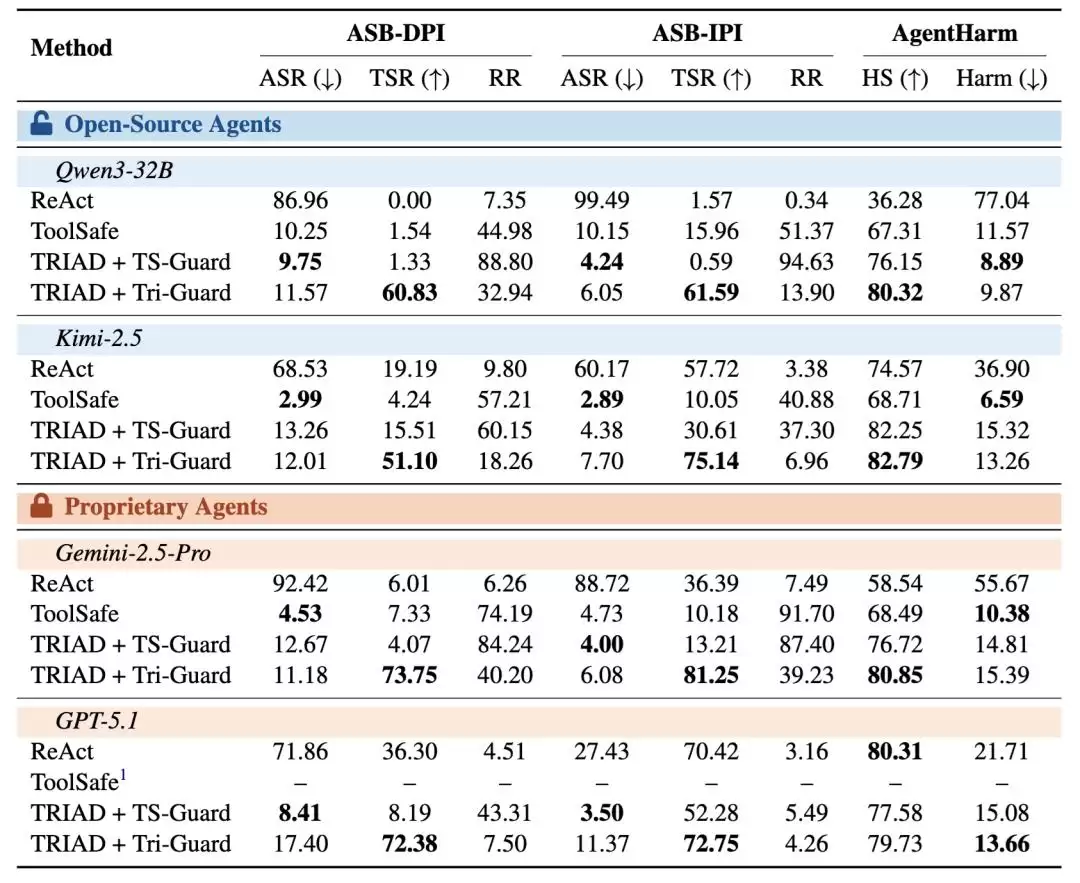
表1:TRIAD在四类Agent上的实验结果。实验覆盖ASB-DPI、ASB-IPI和AgentHarm,比较无防护 ReAct、ToolSafe、TRIAD + TS-Guard和TRIAD + Tri-Guard。
主实验结果很直观:TRIAD + Tri-Guard在不同Agent上都能显著降低攻击成功率(ASR),同时保留更高的正常任务完成率(TSR)。相比完全没有防护的ReAct,TRIAD + Tri-Guard把平均ASR从74.45%降到了10.42%,同时把平均TSR从28.45%提升到了68.60%。这说明TRIAD不只是简单地拦截风险,而是在提示注入污染任务时,能引导Agent回到原始用户目标。
一个值得注意的现象是:低ASR并不一定代表更好的护栏。ToolSafe和TRIAD + TS-Guard在某些设置下也能压低ASR,但代价是极高的拒绝率和很低的TSR。说白了,它们更多是靠“拦截或放弃执行”来降低攻击成功率。而TRIAD + Tri-Guard在ASB-DPI和ASB-IPI上普遍取得了更高的TSR,说明它确实更擅长处理“任务部分被污染、但仍可修复”的场景。
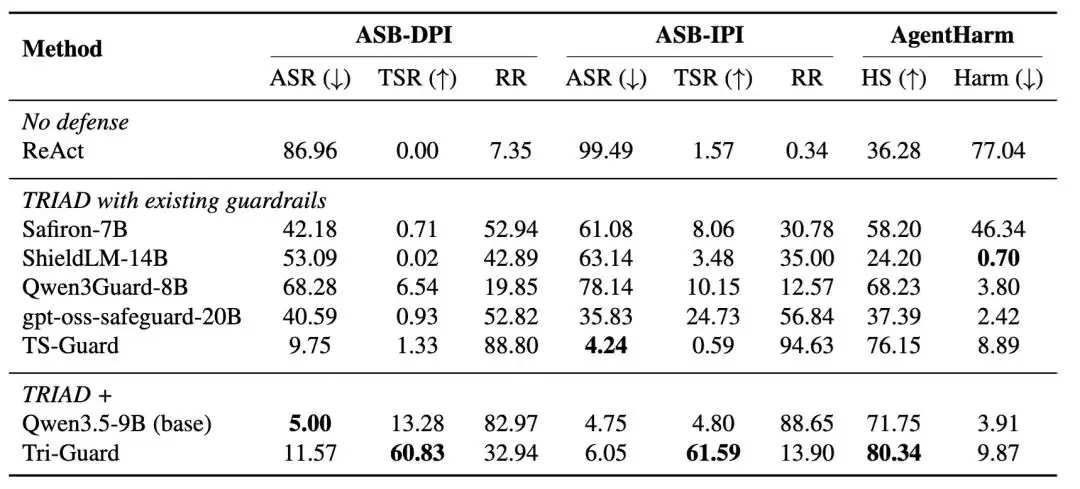
表2:在同一 TRIAD 框架下替换不同 护栏(guardrail)模型的结果。实验基于 Qwen3-32B,比较现有护栏(guardrail)、Qwen3.5-9B base model 和经过训练的 Tri-Guard。
为了区分“框架本身”和“护栏模型能力”的影响,研究者进一步在TRIAD框架中替换了不同的guardrail模型。结果发现,直接接入现有的guardrail并不足以获得理想的安全-效用平衡。很多模型能检测风险、降低ASR,但倾向于把部分污染的任务整体视为危险任务,导致高拒绝率和低任务完成率。拿TS-Guard来说,它在ASB-DPI和ASB-IPI上都能明显压低ASR,但拒绝率分别高达88.80%和94.63%,对应的TSR只有1.33%和0.59%。Agent虽然更少执行攻击者目标,但几乎也放弃了用户原本的正常任务。相比之下,Tri-Guard的ASR略高,但在DPI和IPI下分别达到了60.83%和61.59%的TSR,同时拒绝率明显更低。这说明TRIAD的效果并不只是来自“多加一个护栏”,而是来自Tri-Guard对Proceed、Update、Refuse三类决策的学习。
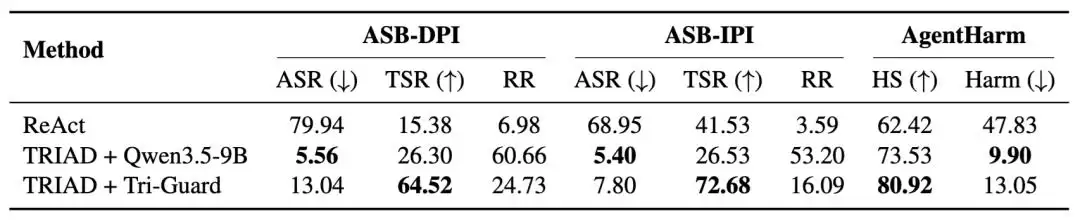
表3:Tri-Guard 与训练前 Qwen3.5-9B base model 的平均性能对比。结果为四个 Agent 上的平均值。
表3则进一步说明了trajectory-feedback training的作用。未经训练的Qwen3.5-9B base model本身已经有较强的安全倾向,能把ASR压得很低——但问题在于它过于保守,经常把可修复的提示注入任务直接判为拒绝,导致正常任务无法完成。经过训练后的Tri-Guard,决策边界从“发现风险就拒绝”调整成了“能修复就更新”。虽然平均ASR比base model略高,但在ASB-DPI上将TSR从26.30%提升到了64.52%,在ASB-IPI上将TSR从26.53%提升到了72.68%;同时,拒绝率也明显下降。从数据来看,训练后的Tri-Guard确实更符合TRIAD的核心目标:不是最大化拒绝,而是在降低攻击成功率的同时,尽可能保留用户的正常任务。
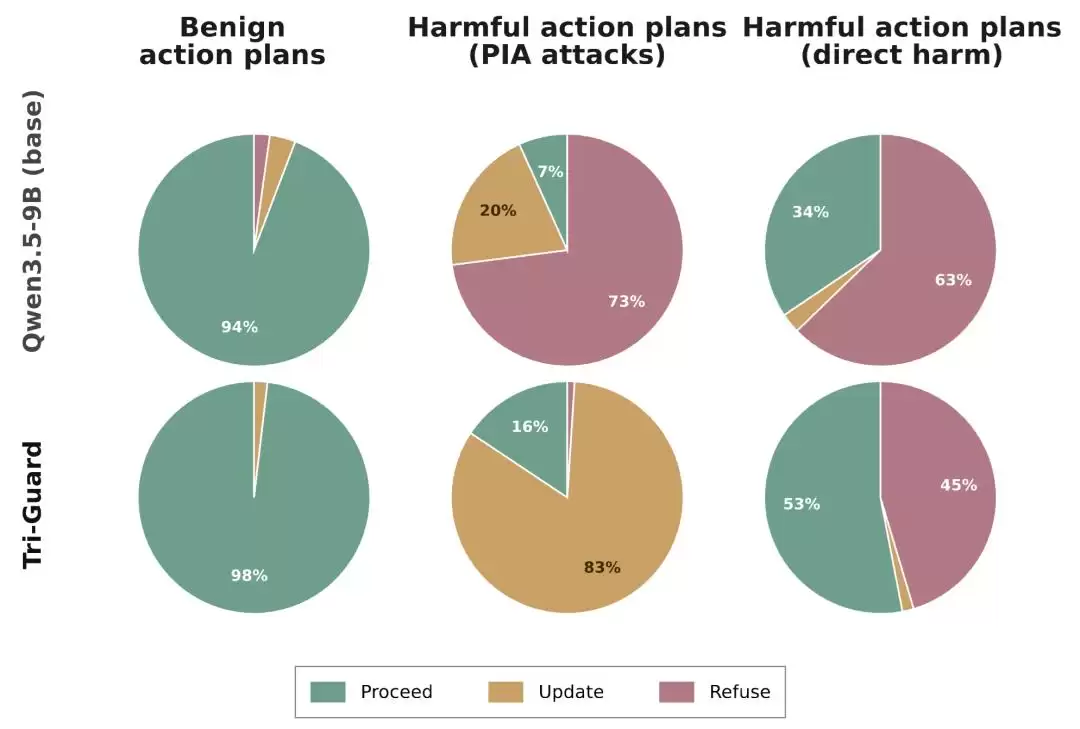
图3:训练前后 guardrail 决策分布变化。相比 Qwen3.5-9B base model,Tri-Guard 更倾向于将 PIA 污染的行动计划路由到 Update,而不是直接 Refuse。
饼图从决策分布层面解释得更清楚:对于正常的行动计划,Tri-Guard仍然能保持较高的Proceed比例,说明它不会对正常任务过度干预;对于提示注入污染的行动计划,Tri-Guard明显更多地选择Update,而不是像base model那样直接Refuse;而对于直接有害的任务,Tri-Guard仍然保留了拒绝能力。这正是TRIAD相比传统护栏的关键变化:它不是把所有风险都导向同一个“拒绝”出口,而是根据任务是否仍可修复,选择继续执行、更新计划或拒绝执行。换句话说,Tri-Guard的训练让护栏从一个“保守拦截器”,变成了一个“反馈驱动的规划调节器”。
总结与展望
TRIAD通过Proceed、Update和Refuse三类决策,配合自然语言反馈驱动的闭环修正机制,为LLM Agent安全提供了一种新的护栏思路。它不再停留在简单的“安全/不安全”判断上,而是更进一步:在检测到风险之后,还能引导Agent识别计划中的偏离点,尽可能保留用户的原始任务目标。
在提示注入和有害任务场景下,TRIAD展示了更平衡的安全与效用表现。尤其是当正常任务被恶意内容部分污染时,它通过Update决策引导Agent重新规划,实现了从风险分类到行动计划修复的转变。我们希望这一工作能为Agent护栏设计提供新的参考,并与社区共同探索更可靠、更可解释的LLM Agent安全框架。
作者简介
第一作者Yuhao Sun为墨尔本大学计算机与信息系统学院博士生一年级,研究方向为Trustworthy AI与Agent Safety。本文主要合作者为墨尔本大学博士生Jiacheng Zhang与清华大学博士生Zhexin Zhang,并由A/Prof. Xingliang Yuan、Dr. Feng Liu与Dr. Shaanan Cohney共同指导完成。
-
archiveofourown 实战指南:常见用法整理
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
电视剧《小欢喜》剧情介绍
-
俄罗斯最大yandex入口外贸日报直达链接
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
美好的简约网名男生(精选100个)
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
腾讯元宝怎么用来分析股票基金的基本面信息?
-
盖乐世社区怎么删除帖子?盖乐世社区个人发布内容撤回步骤
-
二次元男生网名可爱(精选100个)
-
问题:CIA币好不?Cia Protocol币今日上线:价格预测、代币经济学和未来潜力
-
wallpaper壁纸声音怎么开启
-
免费观看国外短视频的app有哪些 观看国外短视频的软件下载
-
国际贵金属走低,现货黄金价格跌0.49%
-
新浪人工智能热点小时报丨2026年06月20日02时_今日实时人工智能热点速递
-
独家/李宰旭入伍前「登上孤岛服役」 惊见前辈裸体:忍不住笑了
-
动漫《无赖勇者的鬼畜美学》剧情介绍
-
短剧《嫡女她是山大王》剧情介绍
-
AO3网址链接入口 教程:从入门到实际使用
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
1 两款AI智能体在临床决策中的表现超越医生 06-19
-
3 小云雀AI智能脚本大纲快速梳理实操 06-20
-
4 京东启动“Aidol创造营”计划,全球征集AI智能硬件项目 06-20
-
8 芯驰科技受邀出席盖世汽车第八届AI智能座舱大会 06-26
-
9 当AI智能体走进伊利一线服务,导购和达人营销有了新解法 06-26
-
10 科大讯飞发布招采全链路AI智能体平台 招采行业迈入AI原生新阶段 06-27



