为什么Kriging 与高斯过程回归出自同一数学框架,但实际效果却差很远
来源:互联网 更新时间:2026-06-25 12:22
做过地质统计学、储层建模或空间机器学习的人,大抵都曾直面过这个灵魂拷问:选Kriging(经典地质统计学的扛把子),还是高斯过程回归(GPR,机器学习圈更爱叫它贝叶斯优化利器)?数学上,它们是相通的——都基于协方差/核函数,构建“最佳线性无偏预测器”。但实际用起来,简直是两个世界。Kriging快、可解释、有几十年的工程积淀;GPR慢、更灵活、背后有sklearn的精良封装。
这次,我在SPE9数据集上做了一组正面对比,覆盖了多种Kriging变体、GPR,以及几个机器学习基线方法。还特意用5折和20折交叉验证各跑了一遍,看看结果到底稳不稳。
结果出乎意料。过程中还碰到一个让不少人(包括我自己)困惑过的问题:R²的名字里明明带“平方”,怎么可能是负数?这个问题值得花点时间说清楚——因为没搞懂它之前,上面那些数字根本没法正确解读。
数据集:SPE9
SPE9是个经典的Benchmark——一个合成但具有现实意义的3D渗透率网格,几十年来一直被用来测试模拟器和建模工作流。这次实验把它当空间插值问题处理:
- 输入:储层网格内归一化的 (x, y, z) 坐标
- 目标:该位置的渗透率
- 任务:给定一批已知点,预测未知位置的渗透率
从网格中采样了1,500个点,分别用于单次划分(1,200训练/300测试)、5折交叉验证(每折1,200训练/300测试)和20折交叉验证(每折1,425训练/75测试)。
对比模型一览
普通Kriging(Ordinary Kriging,OK)
Kriging将未采样位置的值预测为附近已知值的加权平均,权重来自变差函数——描述两点之间相似度随距离变化规律的函数。变差函数拟合一回,之后对每个预测点用k个最近邻解一个小型线性方程组。测试了两种配置:自动选择变差函数模型(球形/指数/高斯/线性,通过交叉验证拟合选优)和固定球形模型。
泛Kriging(Universal Kriging)
思路和普通Kriging相同,但额外在残差之上拟合一个多项式“漂移”项——线性或二次。漂移项负责捕捉大尺度趋势,变差函数则只需解释局部小尺度变异。
嵌套变差函数Kriging(Nested Variogram Kriging)
这是最有意思的变体,也是专门为这次研究实现的。标准变差函数只有一套nugget/sill/range,只能描述单一尺度;而真实空间场往往同时存在多个尺度的变异:短程局部噪声,加上大范围缓变的区域趋势。嵌套变差函数把两个(或多个)协方差结构叠加在一起:
gamma(h) = nugget + ps1 * structure_1(h, range_1) + ps2 * structure_2(h, range_2)
这和GPR中叠加两个核函数的做法直接对应,比如:
RBF(short_length_scale) + RBF(long_length_scale)
用Rust实现,采用广义N参数Levenberg-Marquardt拟合器,接入局部Kriging引擎,测试了球形+高斯和球形+球形两种组合。
高斯过程回归(GPR)
直接用了sklearn的GaussianProcessRegressor。底层数学与Kriging相同,区别在于:核函数超参数通过最大化边际似然来优化,而非拟合经验变差函数;复杂度是训练点数量的O(N³)——没有最近邻这类快捷方式。
随机森林(及“回归Kriging”混合版)
作为非空间基线,加了一个普通的RandomForestRegressor,直接以(x, y, z)为输入训练渗透率预测。还尝试了回归Kriging混合方案:先用机器学习模型拟合大尺度趋势,再对残差做Kriging,试图捕捉剩余的空间结构。
第一轮:单次1,200/300划分
先做最简单的对比——在1,200个点上训练,对300个留出点评估,只跑一次。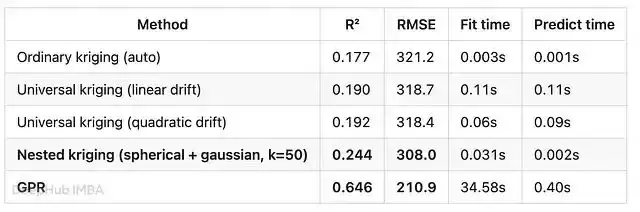
- GPR以大幅优势胜出——R² 0.646,而Kriging各变体只有0.18–0.24。
- GPR的拟合速度慢约1,000倍,预测速度慢约200倍。
- 嵌套变差函数将与GPR的差距缩小了约三分之一(从0.177提升到0.244),但计算代价几乎为零。
- 泛Kriging的多项式漂移几乎没有帮助(0.177 → 0.19),计算开销却比普通Kriging高30–100倍。
为什么GPR在这里赢得这么彻底?
来看看GPR实际拟合出的核函数长什么样:
0.96² · RBF([0.294, 2.91e-05, 0.0183]) + 0.072² · Matern([4.47e-05, 3.08e+04, 4.53e+04], nu=1.5) + WhiteKernel(0.0293)
关键就在那个Matern项:它在y和z维度的长度尺度极大(约30,000–45,000),在大多数域范围内等效于一个近线性的大尺度趋势。GPR的优化器发现了渗透率场的结构:x方向存在短程局部变异,叠加了一个大范围、平滑、近乎线性的区域模式——于是自动组合出RBF(局部结构)加近线性Matern项(区域趋势)的核函数。
嵌套变差函数试图表达的正是同一回事——短程结构加长程结构。效果不如GPR,原因有两点:一是嵌套拟合中第二个结构只支持有界协方差形状(球形、指数、高斯),无法像长度尺度极大的Matern项那样干净地表达无界的近线性趋势;二是GPR的超参数通过最大化边际似然做全局联合优化,而变差函数是先独立拟合经验曲线再用于预测,两步解耦精度自然有损。
如果进行修正:按各轴变差函数范围对坐标重缩放,以校正几何各向异性(该场在x、y、z三个方向的相关长度差异很大)。结果反而更差(R²降至-0.03到0.07)——某一轴上估计的范围极小(约0.005),把距离放大到如此程度,几乎所有点对在重缩放空间中都变得“无限远”,彻底破坏了Kriging依赖的空间相关性。“更复杂”不等于“更好”,所以各向异性校正需要比逐轴重缩放谨慎得多的处理。
第二轮:交叉验证下结论还成立吗?
单次80/20划分只反映数据的一个切面。在同一1,500个点的数据池上,我们跑了5折交叉验证(每折1,200训练 / 300测试)和20折交叉验证(每折1,425训练 / 75测试)。
5折结果(5折均值 ± 标准差)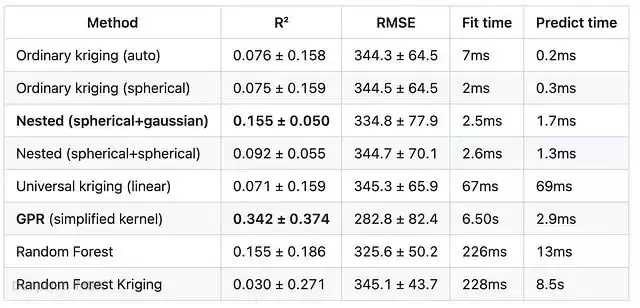
注意:交叉验证中使用的GPR核函数比较简单(ARD RBF + 白噪声,重启两次),而非第一轮中完全优化的核函数——平均R²(0.342)低于单次划分的0.646。这说明单次划分碰巧是对GPR特别有利的一次。
两个问题:
- GPR自身的精度也不稳定——标准差0.374极大。第3折的R²实际为负(-0.351),第4折又高达0.694。同一模型、同样的超参数搜索,仅因留出的300个点不同,结果便天差地别。
- 嵌套变差函数是所有纯空间方法中最稳定的——标准差(0.050)在所有方法(包括GPR)中最低,从未跌入负R²;而普通Kriging和泛Kriging在第3折时都出现了约-0.20的负值。
20折结果(20折均值 ± 标准差,每折75个测试点)
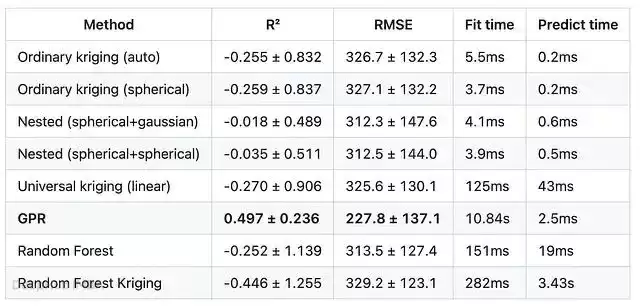
测试集缩小到每折75个点后,情况更加清晰:除GPR外,所有方法的平均R²均为负,即在20个不同留出集上平均下来,这些方法还不如直接在每处预测平均渗透率。GPR是唯一稳定超越均值预测基线的方法,平均R²(0.497)最高,方差(0.236)也最低。嵌套变差函数再次是纯空间方法中“最不差”的,均值最接近零(-0.018、-0.035),标准差约0.49,而普通Kriging为0.83–0.91。随机森林和随机森林Kriging则成了最差的选手——单次灾难性折叠(R²分别为-4.55和-4.92)将平均值拖入深度负区间。
R²怎么会是负数?
“R的平方”这个名字让人天然地以为它是某个量的平方,平方不可能是负数。但实际计算的公式是:
R² = 1 - (SS_res / SS_tot)
其中:
SS_res = Σ(y_true - y_pred)²——模型的总平方误差SS_tot = Σ(y_true - ȳ)²——最笨基线(对每个点都预测y_true均值)的总平方误差
两个求和项都非负,但它们的比值没有上界约束。模型预测比猜均值还差时,SS_res > SS_tot,比值超过1,1 - 比值就成了负数。
“相关系数的平方”这个解释是有前提条件的:带截距的普通最小二乘线性回归,在训练数据上评估。这种情况下,拟合直线被保证至少不比均值差——因为“零斜率、截距=均值”本身就是OLS优化器考虑过的合法候选,优化器只会选更好或相等的结果。这个保证把R²锁定在[0, 1]内。而它恰恰不适用于留出测试集,也不适用于Kriging和GPR这类空间/非线性模型。
测试集上出现负R²不是Bug,也不是指标失灵——而是指标在正确地告诉你:模型对空间结构的过拟合或误设定已经严重到“什么都不预测”反而更好的程度。在20折结果里,除GPR之外的所有方法平均如此。这是一个真实、有据可查的发现,只是结果很差罢了。
选Kriging还是GPR?
答案和数据科学里大多数问题一样,取决于样本量和时间预算——但可以说得更具体些。
选GPR的场景:
- 数据量只有几千个点或更少(O(N³) 的复杂度决定了它无法扩展)
- 精度优先于延迟
- 能接受超参数搜索的时间成本(本Benchmark中每次拟合需要几十秒;N=4,000训练点时,GPR拟合11分钟没有跑完)
- 希望通过核函数组合自动发现多尺度结构
选(嵌套)Kriging的场景:
- 需要对50K–1M+个点打分(GPR根本做不到)
- 需要毫秒级预测
- 能接受精度上的明显折损,但想要折损范围内最稳定的那个版本
- 已有领域知识表明存在多空间尺度(局部非均质性 + 区域趋势)——嵌套变差函数能以极低代价捕捉GPR核组合捕捉到的部分信息
所以,在大网格主体上用Kriging(尤其是嵌套版),在感兴趣的小区域或验证/校准场景中保留GPR,让更高的精度在值得的地方发挥作用。
总结
Kriging看起来是用约0.47个R²单位换取了1,000倍的加速。20折交叉验证下,每种Kriging变体(以及随机森林和随机森林Kriging)的平均R²均为负——平均下来还不如一条水平线。只有GPR稳定地超越了这条基线。
嵌套变差函数通过叠加两个协方差结构来模拟GPR的核组合,没有补上这个差距,但让失败变得不那么严重、不那么随机。这是真实、有用的改进,只是不是当初期望的那种。
如果只带走一条结论:永远做交叉验证,永远把R²与均值预测基线对照。单次训练/测试划分可能让一个既快又脆弱的模型看起来像是白捡来的午餐。
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
archiveofourown 实战指南:常见用法整理
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
电视剧《小欢喜》剧情介绍
-
全链网:黄金价格因美元的走强及利率担忧而下跌
-
美国市场:股票相对债券的风险溢价正在消失
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
有寓意的易经网名男生(精选100个)
-
植物娘大战僵尸电脑端与手机端存档转移的方法
-
电影《遁甲门之消失的公主》剧情介绍
-
动漫《柚木家的四兄弟》剧情介绍
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
卡厄思梦境哀嚎螺旋塔攻略 哀嚎螺旋塔怎么玩
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
1 数据建模怎么做?一文解析8种经典数据建模方法 06-15
-
2 基于形态滤波的ECG基线漂移去除方法详解 06-27
-
3 谷歌浏览器Mac版怎么添加搜索引擎 01-30
-
4 洛克王国世界昏昏鸡怎么进化 01-30
-
5 云顶之弈s17特攻剑圣阵容推荐 01-27



