两周两轮20亿,全球最火具身数据公司爆发
来源:互联网 更新时间:2026-06-24 09:55
投资界消息,光轮智能刚刚完成了一轮10亿元的战略融资。
本轮的投资方阵容相当有分量——中关村科学城基金、四川发展科创基金、山东发展科创投等政府基金都在列,巨人网络、宇信科技、宝通科技、中科产投、量图智策等产业和财务机构也参与其中。老股东方面,建投投资、三七互娱、森马投资继续跟投。
算起来,这已经是光轮智能近期连续完成的又一轮大额融资了。就在上个月底(5月末),他们刚宣布了一轮融资,当时估值已经冲到了150亿元以上。
连续融资背后,一个信号正在变得越来越清晰:具身智能的产业重心,正从模型和本体本身,悄悄延伸到支撑机器人持续学习的底层基础设施上。
机器人从实验室演示走向真实场景,挑战远不止完成单次任务这么简单。它还要能在长尾任务、复杂环境和持续反馈中不断提升能力。行业真正要回答的问题,也随之变成了一个更根本的命题:机器人到底怎么持续学习?
光轮智能切入的,正是这个命题的核心——支撑机器人持续学习的数据与评测基础设施。
物理AI基础设施进入窗口期
人工智能每一次重大跃迁的背后,都少不了基础设施的演进。
大语言模型的爆发表面看是算法和模型能力的突破,但底层真正撑起这片天的,是英伟达构建起来的一整套基础设施体系:GPU提供算力底座,CUDA连接开发者,TensorRT和DGX支撑模型优化、训练与部署,开发者生态持续放大应用创新。可以说,英伟达定义了数字AI时代算力、模型、开发者和应用之间的共同接口与基础设施底座。

每一次新兴技术进入规模化周期,都需要重新定义底层的工具链、标准接口和生态系统。如今,物理AI正在进入这样一个基础设施机会窗口期。
与大语言模型或者自动驾驶不同,机器人领域并不存在一个免费、标准化、可直接拿来用的预训练数据集。真实世界中发生的海量物理交互,并不会天然沉淀为可训练、可评测、可复用的具身数据。
机器人学习的是手与物体、机器与环境之间连续发生的物理交互——抓取、推动、装配、形变、摩擦、碰撞,这些复杂过程。这些经验如果不能被系统性地记录、转化和验证,机器人学习闭环就很难真正实现。
物理AI需要的不只是真机数据,而是一套跨本体、跨场景、跨任务的数据与评测系统。它不绑定单一机器人硬件,也不局限在单一场景里,而是能够被不同本体、不同模型、不同任务反复调用,持续产生经验、发现问题并反哺训练。
可以这样理解:如果说GPU和CUDA解决了AI时代模型训练与应用规模化的问题,那么在物理AI时代,数据、仿真、评测与部署反馈要解决的,就是机器人如何在真实世界中持续验证和迭代。
数据,正从服务变成基础设施
过去的数据公司很难成为真正意义上的基础设施,原因在于传统的数据交付往往是围绕单个客户、单个任务和单次训练展开的。项目一结束,数据价值大多就停留在当下了。这更像是一门依赖人力、周期和定制需求的服务生意。
但物理AI所需要的数据,完全不同。
机器人面对的是连续、复杂、不可穷尽的真实世界。要支撑机器人持续学习,数据必须是一套能够持续生成、验证、复用并反馈的系统。
同一份人类操作经验,可以服务多个机器人团队;同一个工业场景,可以支撑多个模型训练和评测;同一套评测结果,也能反向定义下一轮数据生产的方向。

这正是数据与基础设施之间的真正区别:服务型数据公司的收入依赖项目交付,做一单交一单;基础设施型数据系统的价值,则来自资产沉淀、复用次数、标准接口和客户网络。前者交付的是数据,后者沉淀的是可被持续调用的资产。
机器人学习的共性并不限定在单一机器人上,而是沉淀在任务结构、场景分布、物理属性、行为轨迹和反馈模式之中。这让数据复用成为可能。只有当这些共性被标准化为可调用的场景、任务、物理属性、行为轨迹和评测指标,数据才能真正实现跨客户、跨模型、跨本体的复用。
评测在这个过程中扮演着关键角色。它不只是单次训练后的验收环节,更是驱动数据产生复利的组织系统:人类经验和仿真持续供给学习素材,评测发现能力边界,部署反馈再把真实世界中的失败、异常和约束带回数据与评测系统,推动下一轮训练和验证。只有这套系统持续运转,机器人才能真正走向复杂场景。
据投资界了解,光轮智能的数据已经实现了最高10倍的复售率。这一指标的意义不只是销售效率的提升,更说明数据、场景和任务已经具备了标准化、可调用、可复用的资产属性。
物理AI时代被重新定价的,不再是某一份数据,而是数据持续生成、评测验证、标准化沉淀和资产化复用的能力。
光轮智能被市场持续看好,也正是源于此。
不止于数据,光轮智能搭建物理AI时代的数据与评测基础设施
曾经市场把光轮智能理解成一家数据公司。但数据其实只是个起点。
就像英伟达的价值早已超出GPU本身,演变成了一整套基础设施栈一样。
光轮智能的数据与评测基础设施已经形成了清晰的轮廓:它的核心不是算力调用,而是经验如何被采集,能力如何被评测,部署反馈如何回流,以及真实世界如何被转化为可训练、可验证的仿真世界。
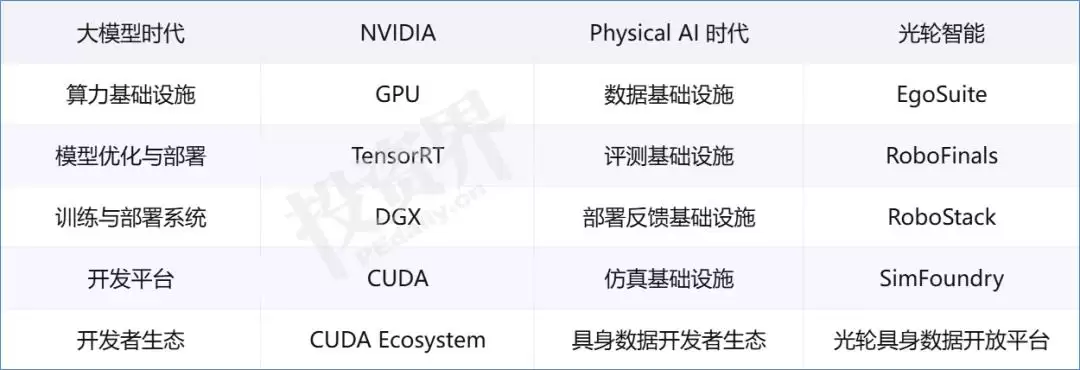
总的说来,光轮智能的产品体系围绕机器人持续学习,形成了一套内外环结构。
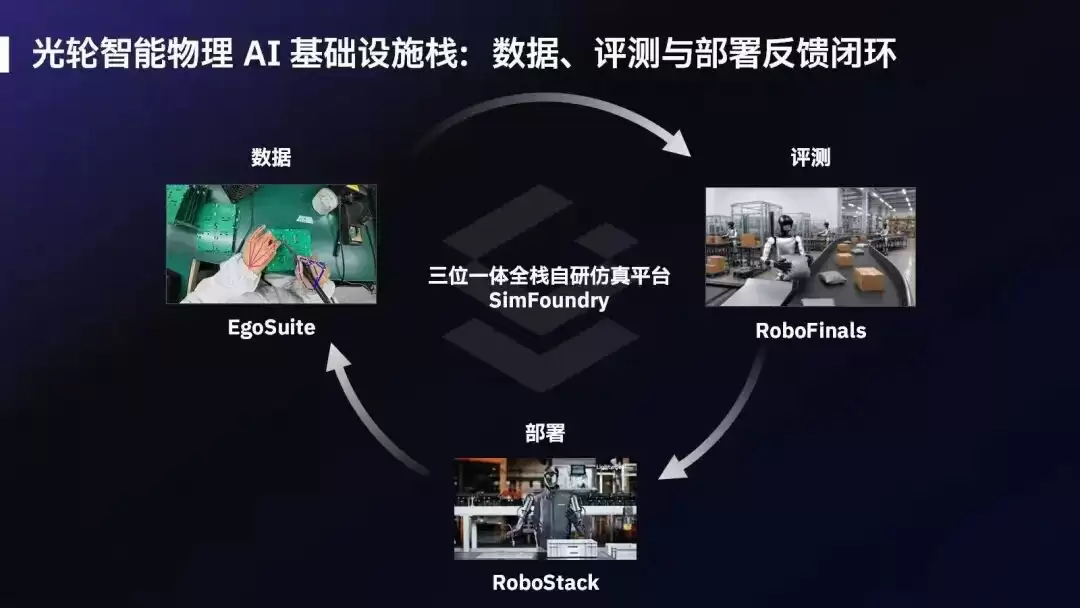
从外层看,EgoSuite、RoboFinals和RoboStack分别对应数据、评测和部署反馈三大板块。
·EgoSuite沉淀高质量、规模化、跨本体的人类行为数据。它记录的不是简单动作,而是人类在真实世界中的观察、操作、纠错和长程任务经验,是机器人获得可规模化行为经验的入口。
·RoboFinals提供工业级规模化评测。通过标准化任务、可复现环境和可比较指标,它可以判断机器人模型学会了什么、能力边界在哪里、失败模式是什么,并反向定义下一轮数据需求。
·RoboStack连接真实部署反馈。机器人进入工厂、仓库、农业、物流等产业现场后,会持续遇到新的任务分布、异常情况、失败样本和现场约束;这些反馈被重新带回数据、仿真和评测系统,成为下一轮学习的起点。
内层则是SimFoundry。作为光轮自研的物理AI仿真基础设施,SimFoundry通过“求解—测量—生成”三位一体全栈自研技术,把真实世界规模化转化为可执行、可训练、可评测的仿真资产与场景,支撑数据生成、评测验证和真实反馈的持续迭代。
这样一来,几个产品便形成了清晰的协同:EgoSuite提供经验数据,RoboFinals验证模型能力,RoboStack回流真实部署反馈,SimFoundry则作为仿真基础设施,支撑数据生成、评测验证和真实世界反馈的持续迭代。
英伟达重新定义了AI时代的算力基础设施;光轮正在定义的,则是机器人走向真实世界所需的数据与评测基础设施。
机器人越走向真实世界,这套系统的价值就越清晰。
开放生态,共建物理AI时代的CUDA
基础设施的规模化,始于产品,成于生态与标准。
GPU奠定了算力底座,CUDA则把开发者、模型、工具链和应用纳入同一套共同语言。到了物理AI时代,类似的共同语言也在形成,只是连接的对象变成了数据采集、仿真生成、模型评测、产业部署和真实世界反馈。
对光轮而言,开放生态的半径进一步扩展,已经进入了基础设施建设本身的层面。
机器人进入真实世界,数据来自不同设备和场景,模型由不同团队训练,评测运行在不同仿真环境,反馈发生在不同产业现场。这些分散的能力必须进入同一套接口、质量和评测标准,才可能支撑机器人长期迭代。

围绕这套基础设施,光轮智能已经在数据采集、云与算力、世界模型和产业场景侧形成了合作网络。PICO、舞肌科技等伙伴提升人类行为数据采集的质量和标准化程度;阿里云、摩尔线程等提供数据生成、仿真训练和规模化评测支撑;生数科技等企业探索真实世界数据如何进入可生成、可交互、可训练、可评测的仿真环境;新希望、宝通科技等产业方则把数据与评测体系带入工业、矿业、农业等真实现场。
合作网络之上,平台规则开始变得更加关键。评测牵引数据,用统一基准识别模型能力边界,并反向定义下一轮数据需求;数据标准,让多源数据在统一结构、标注、时序和质量门槛下进入训练与评测体系;数据配方,则沉淀不同数据来源在不同任务、场景和模型阶段中的组合方法。
平台规则向前一步,就是行业标准。
数据需要在统一结构下复用,仿真结果需要在统一接口下比较,模型能力需要在统一评测基准下稳定评估。如今,光轮智能已受邀加入国际开源物理仿真引擎Newton技术指导委员会(TSC),与英伟达、谷歌 DeepMind、迪士尼研究院、丰田研究院四家顶尖机构共同推动下一代开源物理AI仿真标准建设。同时,光轮也与国家机器人检测与评定中心推进“真实+仿真”的评测体系建设。
从数据采集到仿真生成,从规模化评测到真实部署反馈,物理AI正在走向一套开放协作的基础设施体系。
「数据的英伟达」指向的,正是这种行业位置:把数据、仿真、评测、部署反馈和产业生态连接起来,成为机器人走向真实世界的共同底座。
一个新的产业周期,已然开始。
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
archiveofourown 实战指南:常见用法整理
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
美国市场:股票相对债券的风险溢价正在消失
-
有寓意的易经网名男生(精选100个)
-
电视剧《小欢喜》剧情介绍
-
全链网:黄金价格因美元的走强及利率担忧而下跌
-
618装机配置作业! 从入门到顶配 每一分钱都花在刀刃
-
电影《遁甲门之消失的公主》剧情介绍
-
网石18禁MMO《RAVEN2:渡鸦》大型更新推出全新职业“军阀”
-
动漫《柚木家的四兄弟》剧情介绍
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
植物娘大战僵尸电脑端与手机端存档转移的方法
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
2 赛力斯机器人曝光,车企为何自研机器人? 06-23
-
3 68亿,具身机器人史上最大采购来了 06-23
-
5 Pi币(π)安全圈设置,如何提高挖矿率? 06-23
-
8 跨越感知瓶颈!单芯片8T8R毫米波雷达如何让机器人读懂复杂世界? 06-24
-
9 贾跃亭推出美国首个工业级轮臂机器人 06-24
-
10 人类已经追不上机器人了,液冷散热“立大功” 06-24



