面向Skills编程-淘宝企业购端对端研发提效实践
来源:互联网 更新时间:2026-06-19 13:42
面向Skills编程:从“人写代码”到“人沉淀Skills,AI写代码”的范式升级,助力淘宝企业购实现端到端研发效率大幅提升。
核心内容:
- “面向Skills编程”新范式的核心理念与架构
- 以企业购客户对接为实战,验证提效成果
- 构建通用Skill体系的四步落地路径

这篇文章提出了一套“面向Skills编程”的新范式——把领域知识、工作流、约束规则统统封装成可版本化的Skills单元,让LLM在一个确定性的框架内生成代码。简单来说,就是从“人写代码”切换到“人沉淀Skills,AI写代码”的研发范式升级。以企业购客户对接场景为实战,通过打造项目评估、技术方案、代码生产的研发SOP,商品域的端到端交付周期缩短了65%,代码一次生成成功率达到了90%。

核心理念:从“配置化编程”到“面向Skills编程”
传统范式的天花板
过去应对业务变化的经典策略是DDD分层加配置化:通过领域建模拆分业务能力,再靠配置参数来驱动行为差异。这套模式在以人为主的传统研发模式下挺好使,但碰上高频定制化需求,人力瓶颈就暴露了。
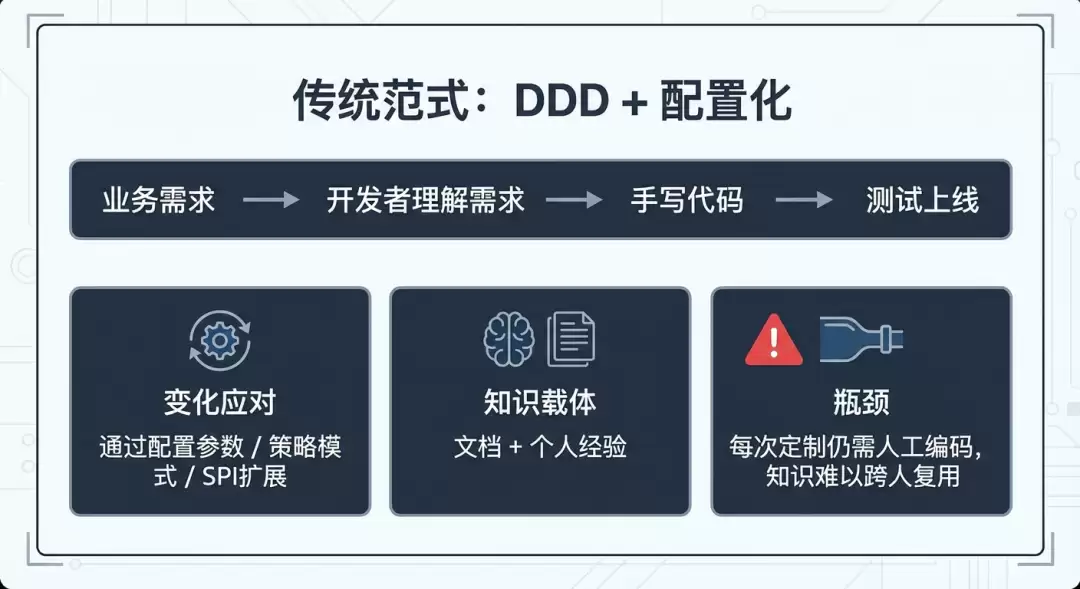
当定制化需求高频出现时——比如企业购每个客户的接口都不一样——配置化的参数空间直接爆炸,SPI扩展点变成了“每次都要写的代码”。开发者本质上还是在手写适配逻辑。DDD确实实现了架构解耦,但重复编码的问题并没有解决。
新范式:面向Skills编程
面向Skills编程的核心思想很直接:把“人写代码”变成“人写Skills,LLM基于Skills写代码”。程序员往更高一层抽象走——从“实现逻辑”升格为“定义Skills”,基于Skills把个人经验转化成可复用的AI能力单元。
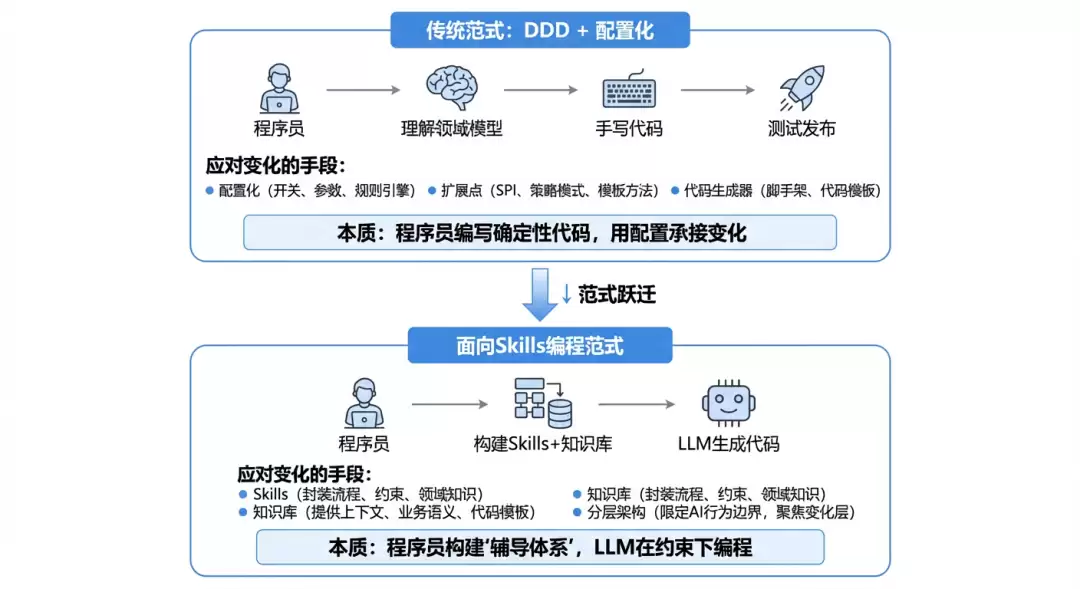
打个比方理解一下:如果说传统编程里“接口/抽象类”定义的是代码的契约,那么Skills定义的就是AI行为的契约——它告诉LLM“做什么、怎么做、不能做什么”,就像接口定义告诉实现类“必须实现什么方法”一样,让大模型从“知道分子”变成“行动专家”。
范式对比:从DDD+配置化到面向Skills编程
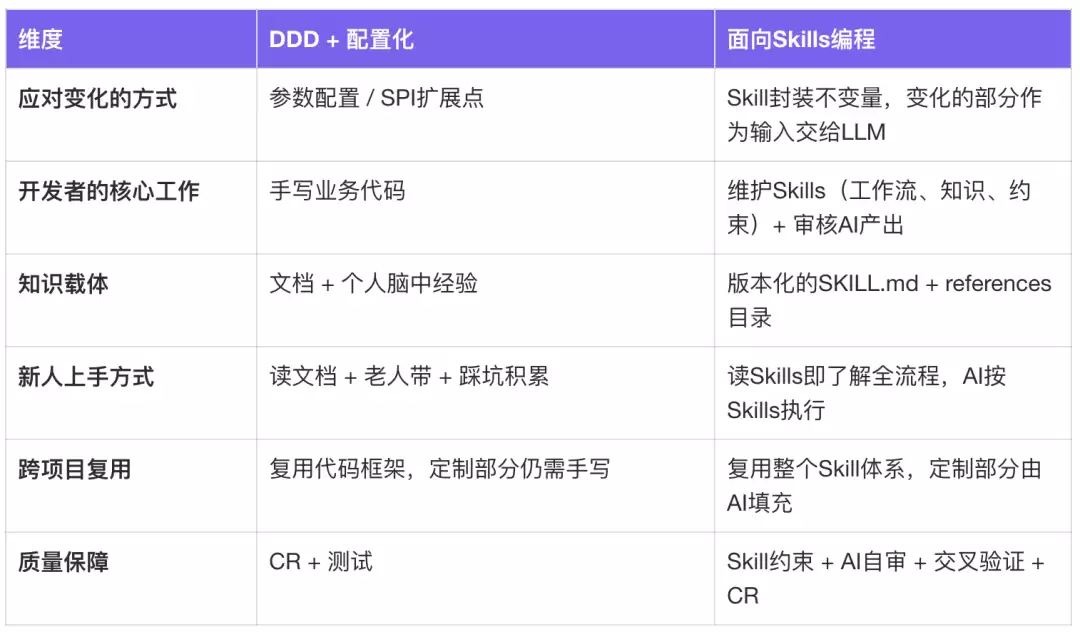
面向Skills编程的通用架构
垂直领域的Skills本身并不通用,但构建Skill的方法论是通用的——识别重复模式,把不变量封装成Skills,把变化的部分作为输入,然后让LLM在约束下执行。
维度评估:你的场景是否适合引入Skills
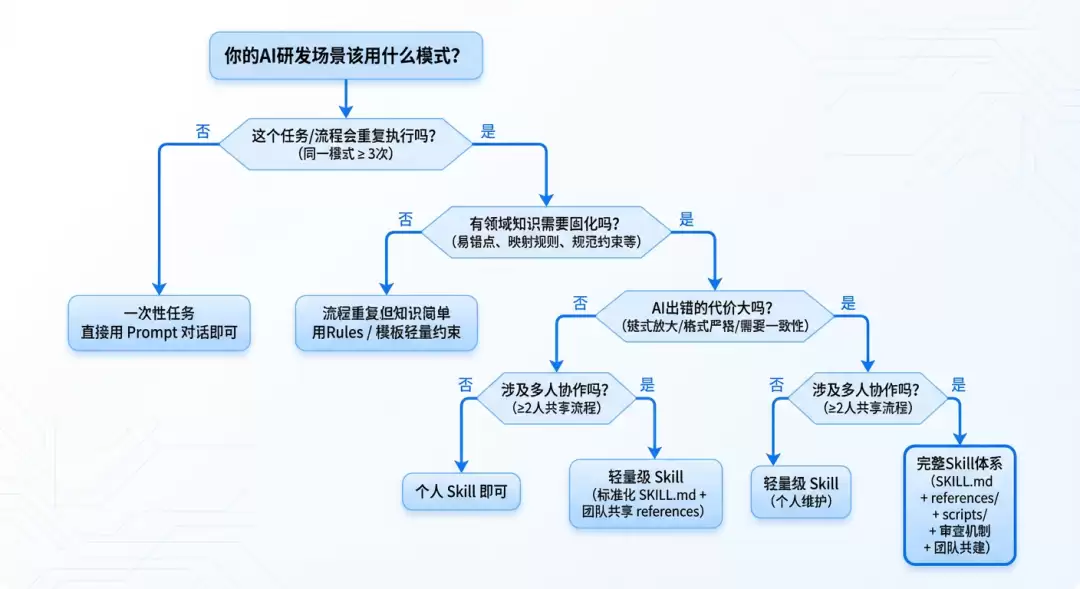
落地路径:四步构建你的Skill体系
不管你在哪个业务域,都可以按下面四步来构建自己的Skill体系:
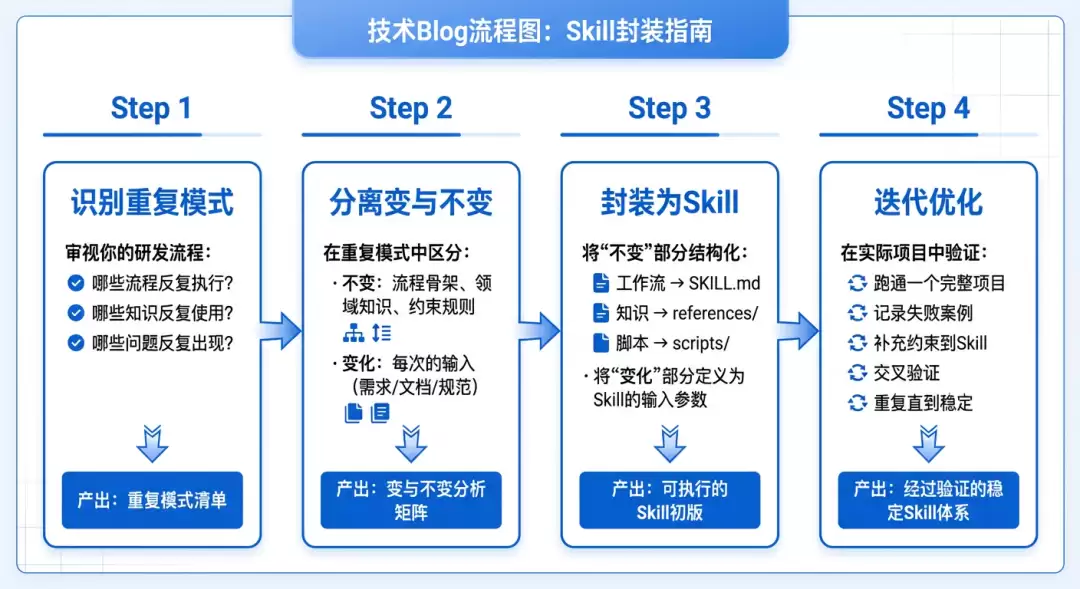

实战验证:企业购对接的AI研发演进路径
业务背景
淘宝企业购面向企业客户的采购需求,提供了一整套解决方案,包含淘宝全平台的丰富供给和私有化企业采购服务产品链。在标准模式(SKA模式)下,淘宝企业购已经提供了完善的基于淘宝开放平台的TOP标准接口,支持外部客户自主对接,覆盖标准化的商品、交易和结算服务。
但在实际业务拓展中,大量大中型客户自己有成熟的系统和接口规范:
- 自研内部商城:比如某大型政府机构,内部自建了采购商城系统,有自己的接口协议
- 外部SAAS商城:比如使用第三方SAAS采购平台的客户,遵循SAAS平台的接口规范
这些客户要改造自己的系统来适配淘宝企业购的标准接口,成本很高。因此,企业购需要反过来适配客户的系统接口。出于业务发展的需要,企业购得主动适配客户系统的接口规范,这就产生了客户定制对接这个高频研发场景。相对于客户主动对接TOP标准接口的标准对接模式,我们把这种企业购反向适配客户接口的模式定义为定制对接模式。
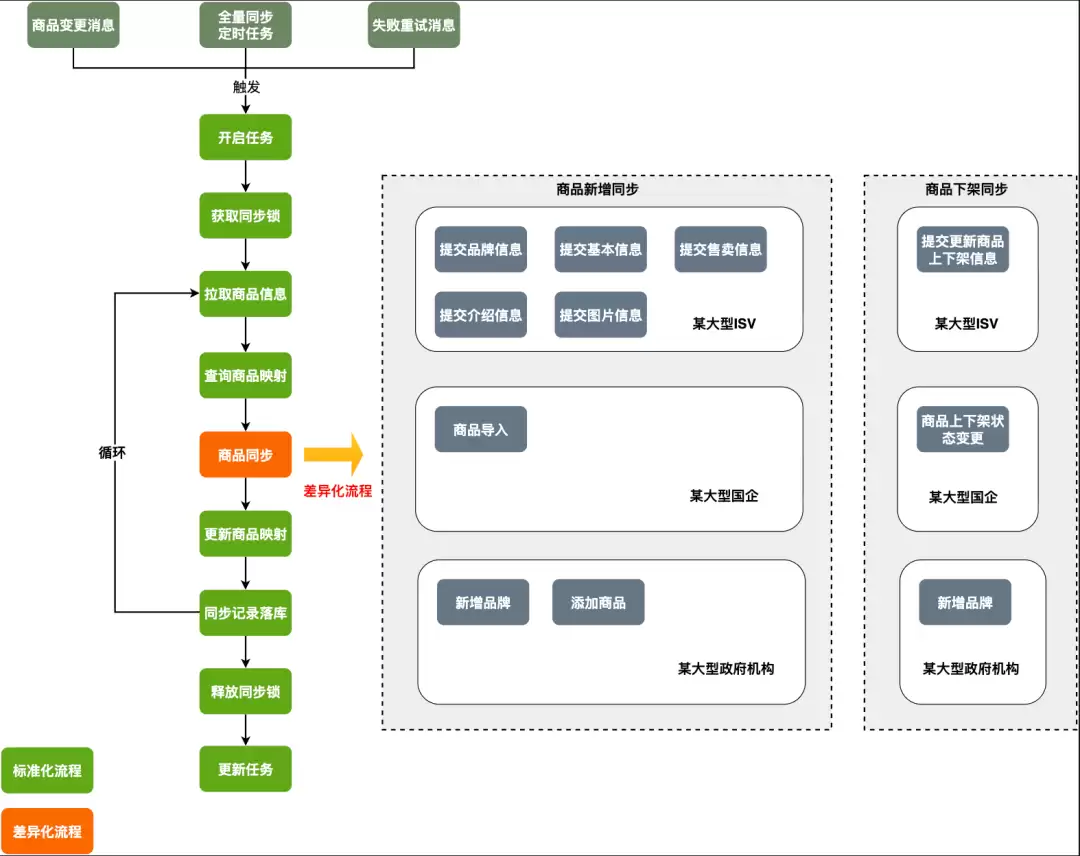
客户对接的核心工作是:基于客户提供的对接文档,理解他们的接口规范,开发适配层代码,实现企业购标准服务与客户系统的互通。一次典型的对接项目工作流程如下:
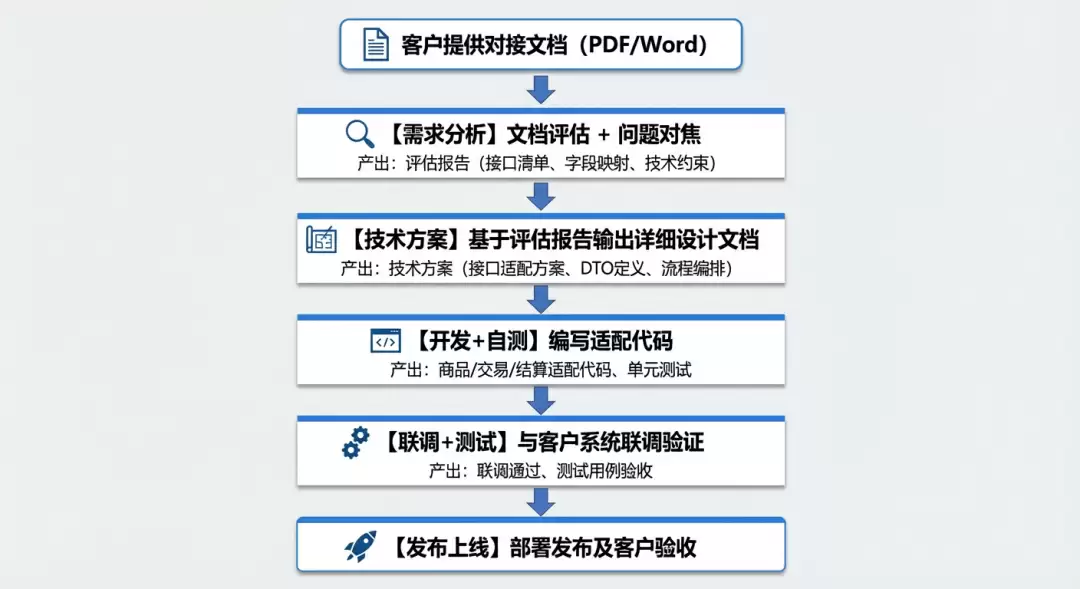
对接工作涉及三大业务域——商品(商品信息同步、类目映射)、交易(订单创建、物流同步、逆向)、结算(对账、结算单、发片管理)。每个客户的接口规范都不一样,适配代码几乎没法跨项目复用,每次对接都得从文档评估到代码开发全流程重新走一遍。
主要工作构成:
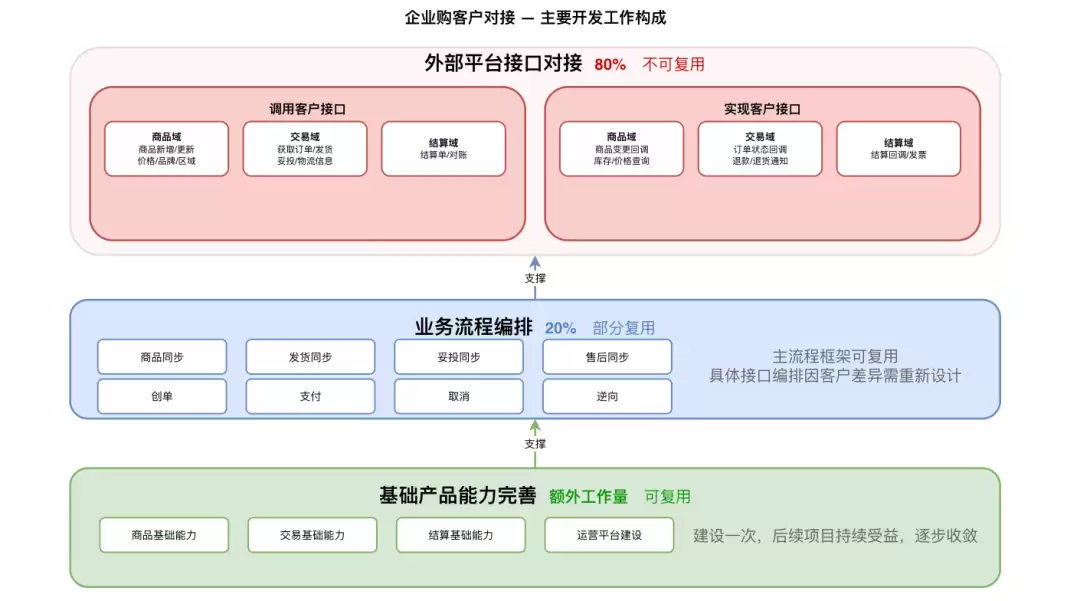
核心痛点
这一业务模式有四个典型特征:对外对接高频、需求碎片化、技术方案重复度高、交付周期敏感。在传统研发模式下,面临以下瓶颈:

核心问题在于:当前以人工为中心、AI辅助的研发模式,根本满足不了业务“快交付、低成本、高灵活”的诉求。
成果速览
经过近半年的系统性探索与实践(2025.8 - 2026.2),团队在研发范式、研发效率、技术沉淀三个维度取得了阶段性成果:
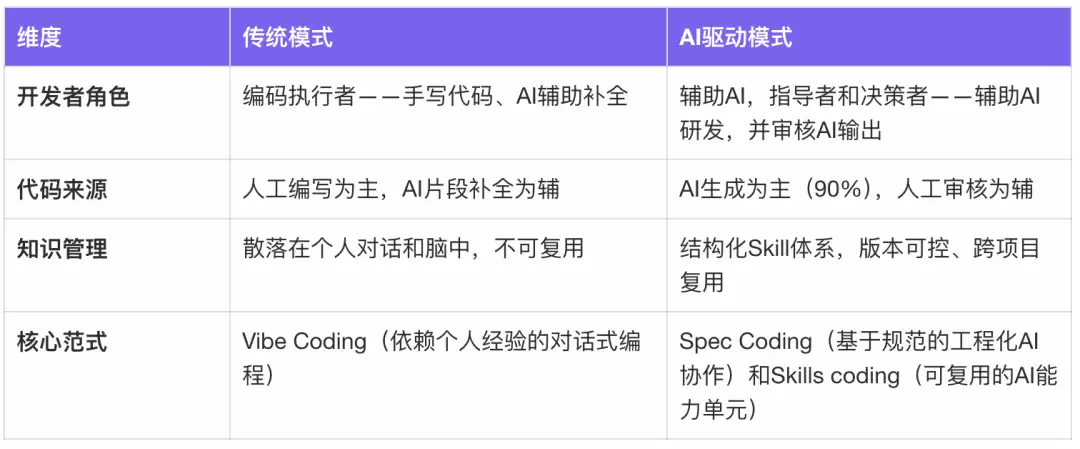
研发范式升级
从“依赖个人经验的对话式编程”迈向“基于Skills的工程化AI协作”,实现了端到端编程实践探索——以人为主导,逐步转向人通过Skills传递经验给AI,指挥AI编程。
研发效率提升
商品域端到端交付周期从23.5人日缩短到8人日,整体提效65%,代码一次生成成功率达到90%。
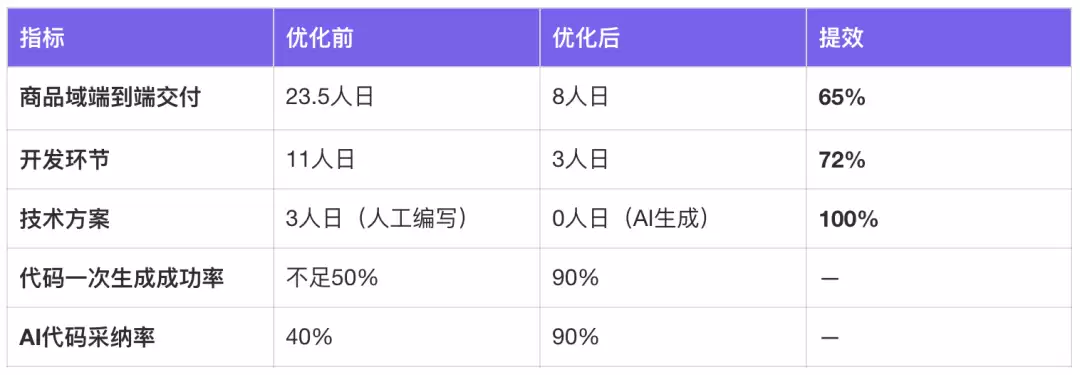
技术沉淀
构建了覆盖全链路的Skills体系和端到端生码平台,把个人经验转化为可复用的组织能力资产。


演进路径:AI研发提效的五阶段
过去半年,团队在巨大的交付压力下,围绕架构解耦、AI编程、AI工具应用三个方向做了系统性探索。演进路径与AI技术发展趋势高度一致,每一阶段都是对前一阶段“天花板”的突破。
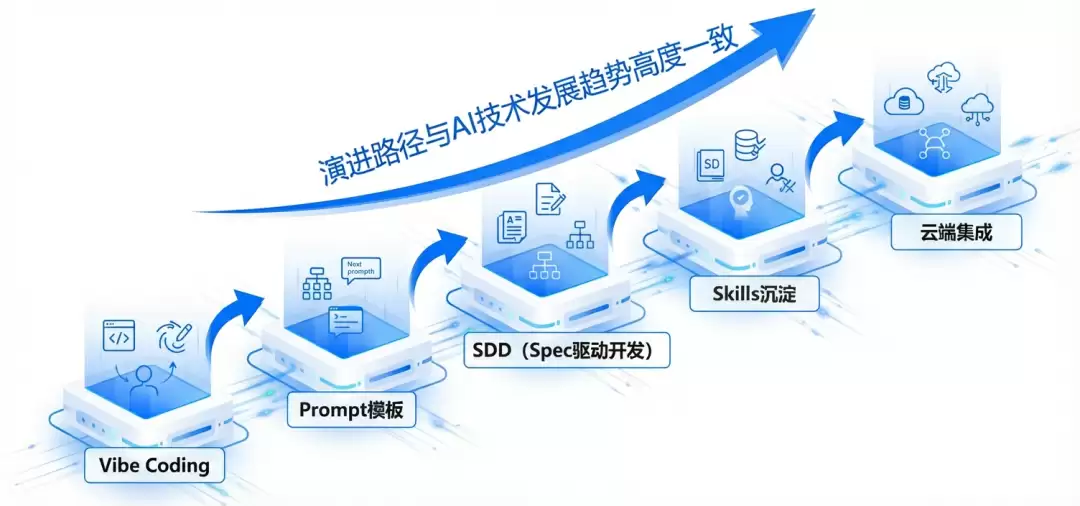
阶段1:Vibe Coding——以对话驱动需求具象化
2025年8月 | 落地项目:某大型ISV
做法:基于弹外架构独立部署的安全性优势(可以用所有开源代码、最新大模型和AI工具),团队开始尝试用自然语言对话驱动代码生成。开发者通过与AI对话描述业务需求,AI直接生成适配代码。
效果:迈出了AI编程的第一步,验证了对话式编码在外部接口适配场景中的可行性。基于某ISV项目完成了整体架构落地,实现了企业购标准服务与客户适配逻辑的解耦。
瓶颈:
- 产出质量不稳定:完全依赖个人Prompt技巧,同一个需求不同人写出的Prompt质量差距很大
- 难以复用:知识散落在临时对话中,新人没法继承前人的经验
- 强依赖个人能力:AI输出质量跟开发者的提示词工程能力直接挂钩
阶段2:Prompt模板——标准化“业务→技术”的语义翻译器
2025年9月 | 落地项目:某大型企业
做法:采用流程模板化加子任务Prompt模板的双轨策略,取得了阶段性成效:
- 流程模板化:把共性环节(比如“商品同步”)抽象成可复用的对接模板——抽象商品同步流程,分离变与不变的逻辑。对接新客户时,只需要在已有模板基础上开发变化部分,就能快速生成可用流程,避免了从零编排。核心目的是让AI做确定性的具体事情,避免发散——通过预定义流程骨架,把AI的工作从“自由设计一个同步流程”收敛为“在已有模板上填充差异化逻辑”。这本质上是把“参数驱动”的旧范式,升级为“任务视角”的结构化表达——以终为始,围绕业务目标组织流程节点。
- 子任务Prompt模板:把开发过程拆成多个子任务(脚手架搭建、接口对象生成、对象映射、接口串联),为每个子任务预置结构化Prompt模板,统一输入格式、约束输出维度、嵌入业务规则。这显著降低了AI调用的随意性,提升了结果一致性和可维护性,是模板化在认知层的延伸补充。
示例:通过商品域主流程抽象,分离变化的部分和不变的部分,收敛AI的任务
- 流程抽象
效果:
- AI生成代码采纳率70%
- 4类Prompt模板形成可复用资产,新人可以快速上手
瓶颈:
Prompt模板虽然在单个子任务上效果显著,但暴露了两个核心问题:
问题一:AI发散不可控,无法提前预览设计思路
Prompt模板只约束了输入和输出格式,但没法约束AI中间的“思考过程”。开发者无法在代码生成前预览AI的设计思路(比如接口怎么拆分、DTO怎么设计、调用顺序怎么编排),导致AI生成的代码跟预期不符——发现问题时代码已经生成完毕,只能推翻返工,反而拉长了迭代周期。
问题二:单点提效,无法承载SOP
Prompt模板没法支撑端到端的标准化操作流程(SOP),核心原因在于:
- 执行不可控:Prompt模板受限于上下文长度和状态记忆缺失,容易出现步骤跳过、顺序错乱、工具误调用等问题,没法保障流程的确定性执行
- SOP与推理任务的本质冲突:SOP本质是有约束的确定性流程,不是开放性推理任务——需要把“自由发挥”转化为“受控选择”,但Prompt模板缺乏这种约束能力
- 缺乏能力基座:当前仍然依赖人工保证流程正确性,根本原因在于缺乏流程节点标准化、工具参数模板化、决策边界显性化的能力基座
阶段3:SDD(规范驱动开发)——构建研发流水线的“数据契约”
2025年12月 | 落地项目:SAAS项目
做法:引入SDD方法论,用结构化规格文档驱动AI生成。在SAAS项目中使用OpenSpec工具验证了Spec编程的可行性——从对话式编程到用规范约束AI,通过工程规范、开源知识库、业务约束三层引导,让AI输出能落地的代码。
效果:

- AI生成代码可用率从40%提升到80%
瓶颈:
SDD方法论验证了Spec驱动的可行性,但在实际落地过程中暴露出规模化推广的瓶颈:
- 流程执行成本高:SDD要求严格遵循“提案(Proposal)→ 实施(Apply)→ 归档(Archive)”三个环节顺序执行,过程中还涉及多轮需求澄清和方案迭代,单个Spec从编写到定稿往往需要3-5轮人工交互,流程本身的投入不可忽视
- 强依赖个人经验,无法规模化:Spec的编写质量高度依赖编写者对领域知识的掌握程度——比如SPU/SKU模型理解、推拉模式选择、字段映射方向等关键决策,仍然散落在个人脑中,缺乏标准化的知识载体。新人面对同一份客户文档,写出的Spec质量跟老手差距悬殊,没法通过简单培训弥合
- 领域知识未固化:SPU/SKU混淆、ID字段混淆等问题跨项目反复出现,说明领域经验没有沉淀为可复用的约束规则,每次都需要人工记忆和校验
阶段4:Skill沉淀——将经验固化为可复用的AI能力单元
2026年1-2月 | 落地项目:某大型ISV
做法:企业购客户对接场景天然适合Skill体系——每一次客户对接都是一个全新的项目,但执行的流程高度重复(文档评估→技术方案→代码开发),变化的只是客户接口规范、字段映射关系和业务流程编排。这跟Skills倡导的可复用技能包理念高度契合:把不变的流程、规则、领域知识封装成Skill,每次对接只需要输入客户文档,Skill就能驱动AI按标准化流程产出结果。
基于这一判断,团队采用Anthropic的Agent Skills标准(SKILL.md + references/ + scripts/)把领域经验封装成Skill,实现了“经验即代码”——工作流写在SKILL.md里,领域知识放在references目录,通过版本控制管理,换人、换模型、换平台都能复用。
最终构建了一条从客户接口文档评估到代码生产的AI全链路流水线,覆盖“文档评估 → 技术方案 → 编码”的完整链路,用XX项目(15个接口)跑通了商品域的整个流程。
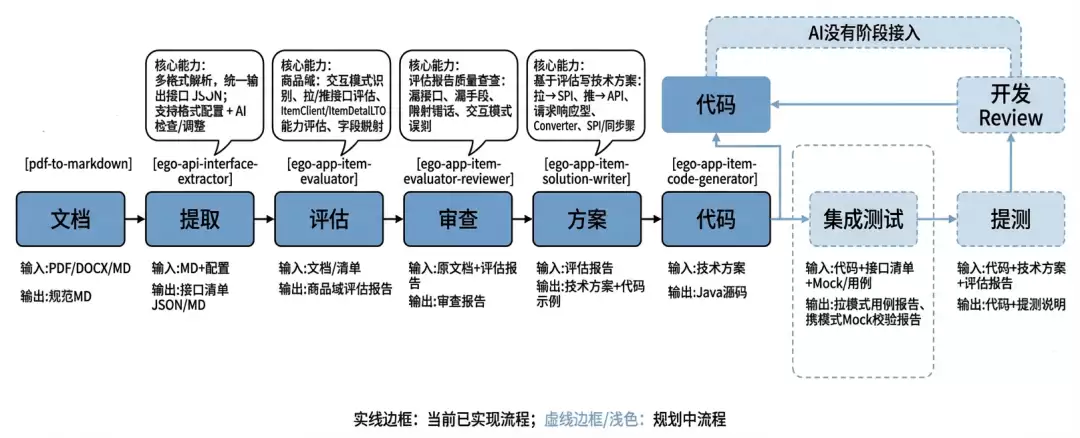
效果:

瓶颈:
Skill体系在技术研发侧取得了显著成效,但它的使用门槛决定了受众仍然局限于技术同学:
- 面向技术同学,产品和业务上手门槛高:Skill的安装、配置、调用都依赖Cursor等本地IDE环境,需要理解SKILL.md工作流、references目录结构、脚本执行等技术概念。产品经理和业务运营没法直接使用,仍然需要研发作为中间人代为执行,AI提效的红利无法辐射到更广泛的角色
- 依赖本地IDE环境,无法规模化推广:Skill运行在开发者个人的本地IDE环境中,换人、换机器需要重新配置环境,团队协同和知识同步的成本很高
- 能力无法产品化输出:技术侧已验证的全链路能力(文档评估→方案生成→代码生产)缺乏产品化载体,没法作为标准化工具赋能给产品和业务团队自主对接
阶段5:云端集成——打造端到端AI研发产品
2026年2月 | 探索中
做法:技术先行,利用OneDay搭建前端交互界面,结合Aone沙箱提供的代码编译与执行环境,自行搭建了端到端的生码平台原型。核心思路是把已验证的Skill能力从本地IDE迁移到云端,让非技术人员通过Web界面就能触发全链路流水线——上传客户对接文档后,平台自动完成文档解析、评估报告生成、技术方案输出、适配代码生产的完整流程。
目标:快速跑通端到端链路,验证Skill云端化的可行性,降低使用门槛,让产品、业务等非技术角色也能直接使用AI研发能力。
当前进展:
- 基于OneDay + Aone沙箱的生码平台已搭建完成,完整链路已跑通
- 商品域全流程(文档评估→技术方案→代码生成)已在平台上端到端验证通过
- 验证了Skill从本地IDE到云端平台迁移的可行性,核心能力可复用

方法论沉淀:我们是怎么做到的
从三个核心方向展开,重点分享可借鉴的经验:
架构先行:分层架构设计
为什么架构优化是AI编程的前提?
代码分层越清晰,AI生成质量越高。架构优化不是为了优化而优化,而是为了让AI能够更好地理解和生成代码。分层架构设计是AI编程的基础设施,它通过清晰的结构和明确的边界,让AI能够像人类开发者一样理解代码的组织逻辑,从而生成更高质量、更符合规范的代码。
分层架构设计
通过代码分层,把系统拆分为原子能力层、模板层、适配层三层架构。这种分层不仅是传统工程意义上的解耦,更是为AI编程量身设计的——通过流程模板化限定AI行为边界,避免发散,让AI聚焦于专一任务(仅实现适配层逻辑),从而显著提升AI输出的准确性和一致性。
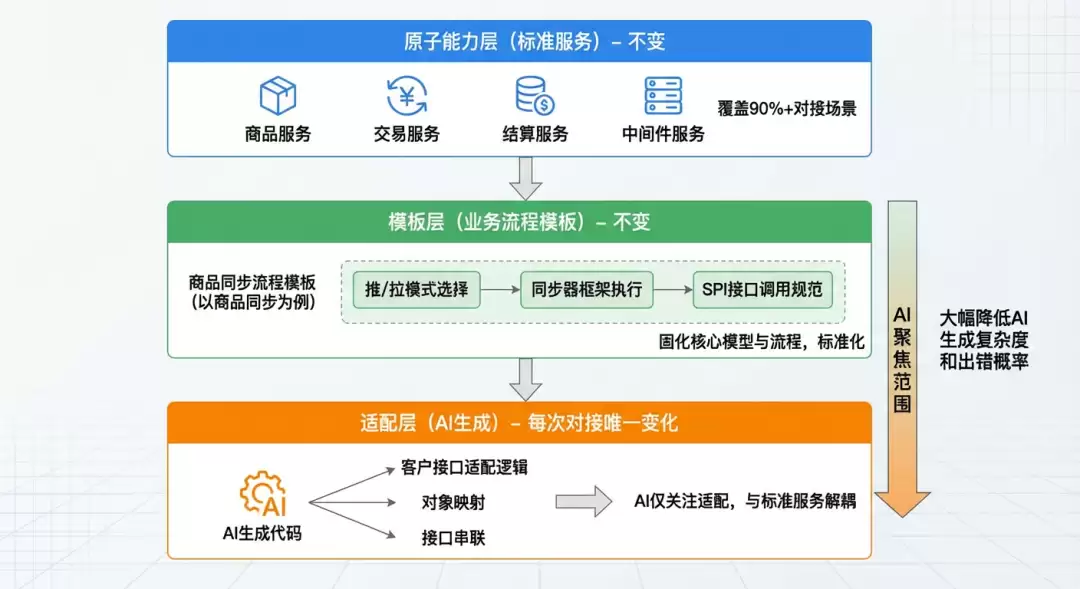
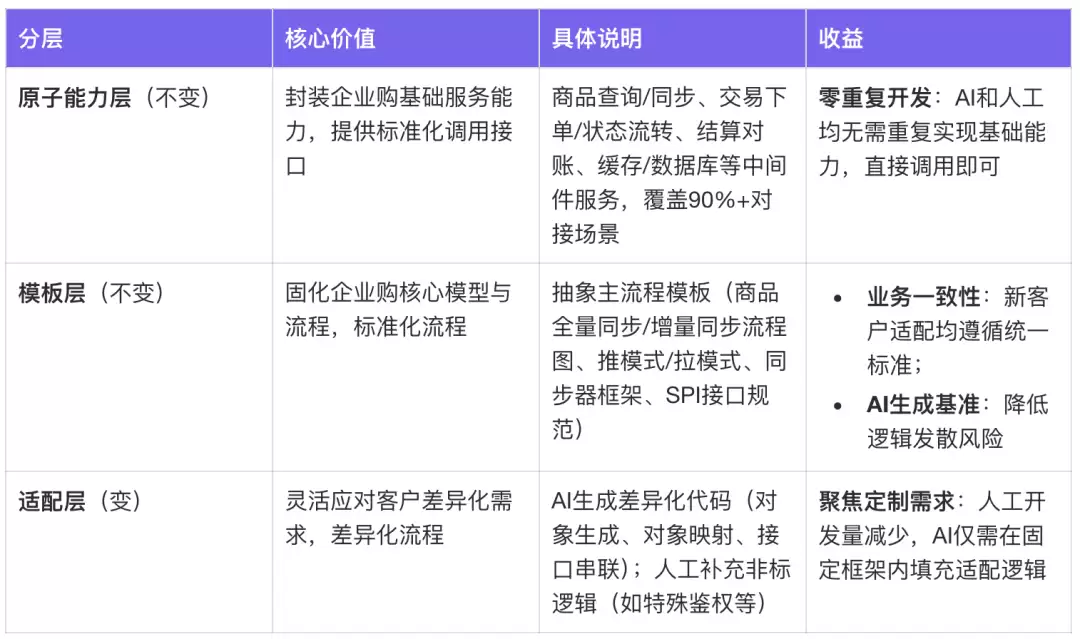
原子能力层和模板层是稳定不变的,AI生成的代码只聚焦于适配层——这相当于把AI的工作范围从“理解整个系统”收敛为“在固定框架内填充适配逻辑”,大幅降低了AI生成的复杂度和出错概率。
实际效果:
- 适配层代码量减少60%:客户差异化开发聚焦在协议转换等核心逻辑上
- 多客户并行开发零冲突:支持多项目并行开发与独立部署
- 原子服务复用:覆盖90%以上的对接场景,AI不需要重复生成基础能力代码
垂直领域Skill的构建与调优
为什么做垂直领域Skills
回到Skills的本质来理解——我们要构建的是领域专家,而不是通用方案。围绕企业购做垂直域深耕,才能真正实现业务提效。
构建的Skills专注于企业购对接这一专业领域的具体需求,与企业购业务强相关——所需的领域知识是SPU/SKU模型、推拉模式、字段映射规则等专业知识,而不是通用能力(比如PDF解析、代码格式化等通用Skill)。选择垂直深耕而非通用方案,基于两个核心判断:
- 垂直域深耕ROI更高:基于Spec范式、Skills、SubAgent技术体系,围绕企业购项目对接集中人力进行实践和应用,最大程度提升研发效率(质量可控、可复用、可迭代),并通过产品化实现技术赋能业务
- 通用方案短期不可行:Spec范式的流程验证和可行性验证已经完成,但网站技术域涉及面太广,做通用的研发方案成本高、短期成功率低,而且集团已经有较多的专门团队在投入
期望的是:在构建专业垂直领域Skill的过程中,沉淀调优经验和方法论,使之可以复用于其他领域快速构建Skill——垂直领域的Skill本身不通用,但构建Skills的方法论是通用的。
Skill构建思路
- Spec驱动原则:通过提升项目评估、技术方案等前置链路准确性,实现生码准确率提升——前序环节的质量决定了后续环节的天花板
- 工程师思维:先完成链路搭建,再基于实际项目拆解到不同节点进行问题分析,通过工程加AI结合,以解决问题为第一目标
- 借鉴和学习:参考Anthropic官方最佳实践(三层架构)、优秀开源项目经验(everything-claude-code、superpowers等)进行实践验证
实际案例
成功率从早期不足50%提升到当前90%,核心在于解决了接口提取幻觉、复杂逻辑输出不稳定、长上下文导致信息丢失三大类问题。调优过程按链路节点逐段攻破:
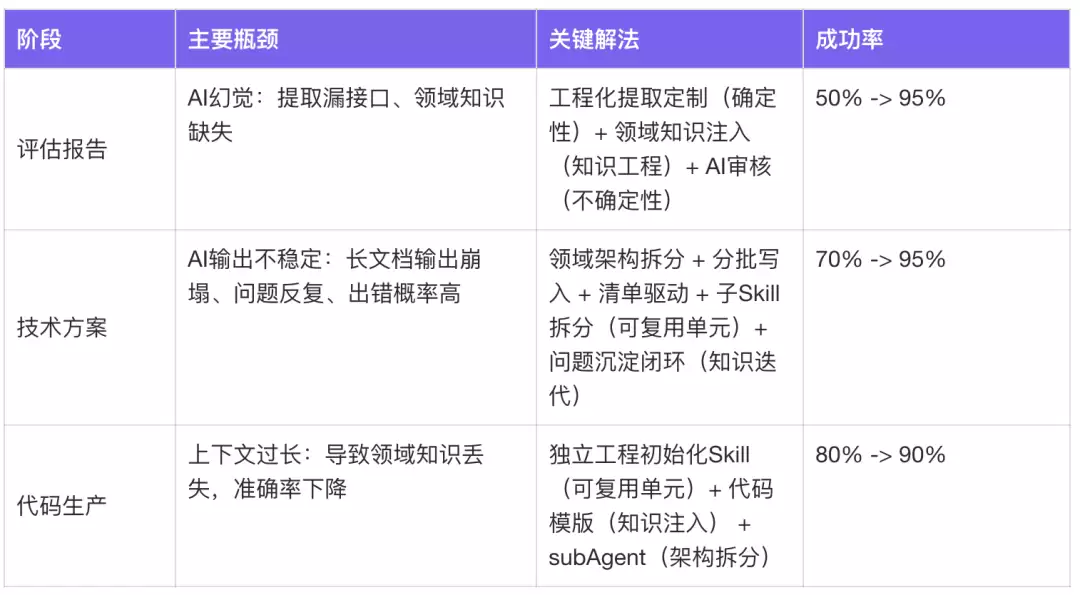
评估报告阶段
评估报告是整条链路的输入源头,类似于PRD的理解,这个阶段要解决两个问题:接口提取不准和领域知识缺失。
问题1:接口提取——AI幻觉导致遗漏
早期完全依赖模型提取接口,模型幻觉导致接口遗漏或误提,错误沿着流水线逐级放大——提取漏一个接口,评估就少评一个,方案就少写一个,代码就少生成一个。
典型案例:客户项目A4.5节标题是“获取所有图片信息”,模型没有识别为接口定义,直接跳过了。
解决方案:脚本提取为主,AI辅助校验
核心思路是把“提取”这个对准确性要求极高的环节从模型能力中剥离出来,改用确定性的脚本解析,AI只负责前后两端(理解格式 + 检查补漏):
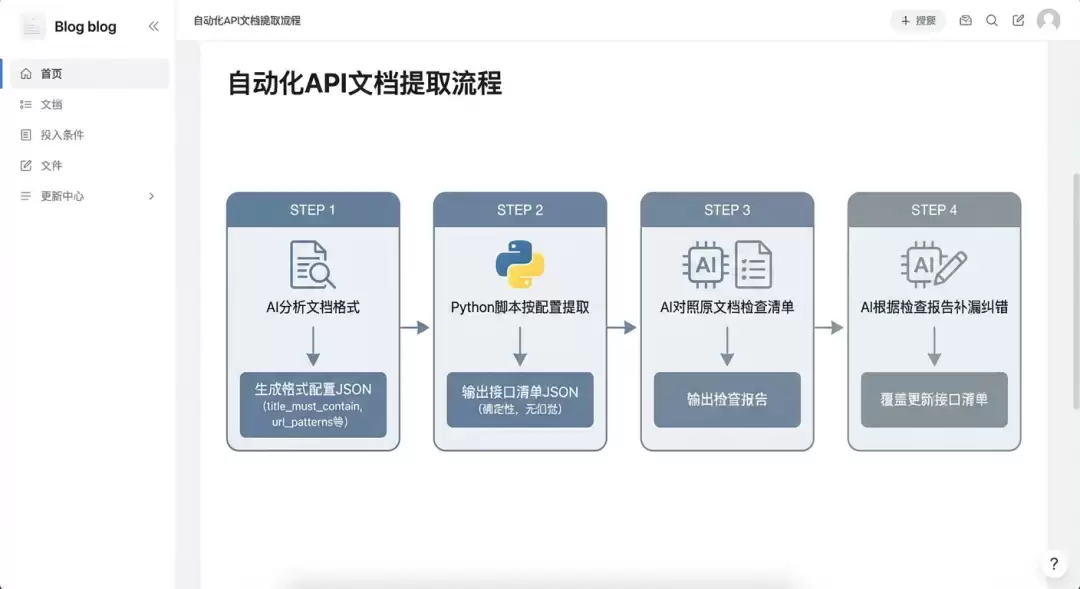
问题2:领域知识缺失——映射关系混乱
AI缺乏商品域业务知识,导致字段映射方向搞反、ID混淆、参数丢失等问题。
解决方案:领域知识内嵌——把人脑中的业务经验转化为Skill的references和约束规则,让AI从“通用地写代码”变成“带着领域知识写方案”。

技术方案阶段
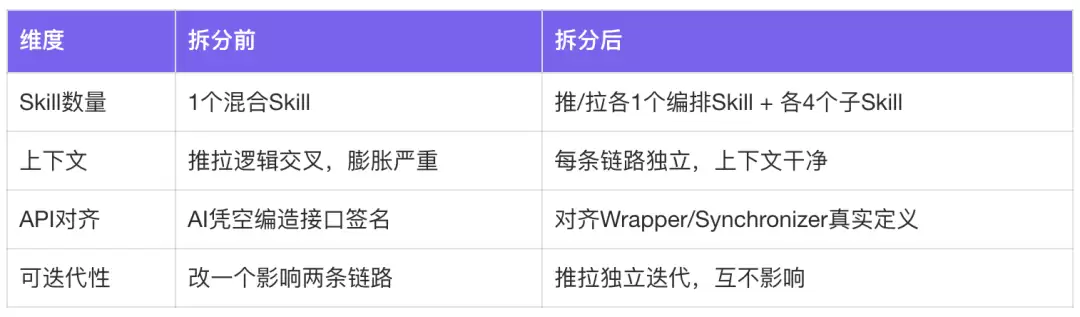
评估报告准确之后,技术方案阶段暴露出两个新问题:推拉模式混杂导致API不对齐和长文档输出崩塌。
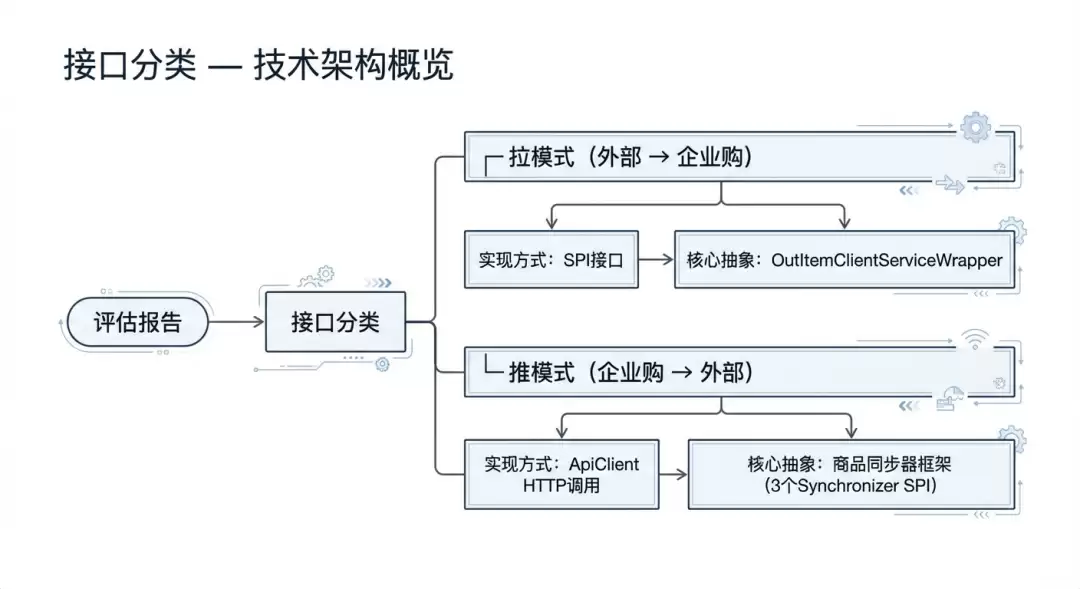
问题1:推拉模式混杂——生成代码与实际系统API不对齐
早期推模式和拉模式混在一个Skill里生成方案,导致上下文膨胀、AI凭空编造接口签名和DTO结构。
解决方案:领域架构拆分,按调用方向拆分链路 + 系统API抽象注入
问题2:长文档输出崩塌
某ISV有15个接口,AI只完整实现了前4个,后面的都用“类似”带过。
解决方案:把方案生成Skill拆成4个子Skill,每个接口在独立上下文中处理。本质是用架构手段解决模型能力边界问题——不指望模型在超长上下文中保持一致性,而是把问题拆到模型能稳定处理的粒度。
pull-generator(编排)
│
├── pull-indexer 脚本解析评估报告 → JSON索引(含子章节行号)
├── pull-model-designer 按子章节精确读取参数 → 设计通用基类
├── pull-interface-generator × N 单个接口独立处理(每个约8k tokens)
└── 汇总组装 拼装N个接口文件 → 最终文档

问题闭环:同类问题跨项目、跨模型反复出现(比如XX系统修了SPU/SKU混淆,换B系统又犯),通过ADJUSTMENT_PLAN机制(发现→定位Skill→补约束→验证→交叉验证)把11类高频问题全部沉淀为Skill约束,不再复现。
代码生产阶段
评估报告和技术方案准确之后,代码生产阶段的核心瓶颈是代码规范和编译成功率。
问题:AI生成的代码不可用
典型案例:
- 项目骨架没有初始化(pom.xml占位符没替换、AKSK没配置),代码放进去编译不过
- AI用了
ItemClient而不是ItemClientWrapper(后者封装了ID映射和参数校验),运行时直接报空指针 - 生成顺序不对:先生成SPI实现类,但此时请求/响应基类还不存在,编译报错
解决方案:
- 工程初始化Skill前置:把项目骨架搭建(占位符替换、AKSK生成、Ma ven编译验证)拆成独立的
ego-project-initializationSkill,确保代码生成在一个可编译的工程上进行 - 代码模板驱动生成:把
ItemClientWrapper使用方式、工具类API、注解规范、Request/Response/Converter/SPI四类代码模板注入Skill的references/code-templates/,AI按模板填充而不是凭空编写 - 按依赖顺序生成:拉模式按“通用基类→请求类→响应类→转换器→SPI实现”的依赖顺序逐接口生成,避免前置类不存在导致编译失败
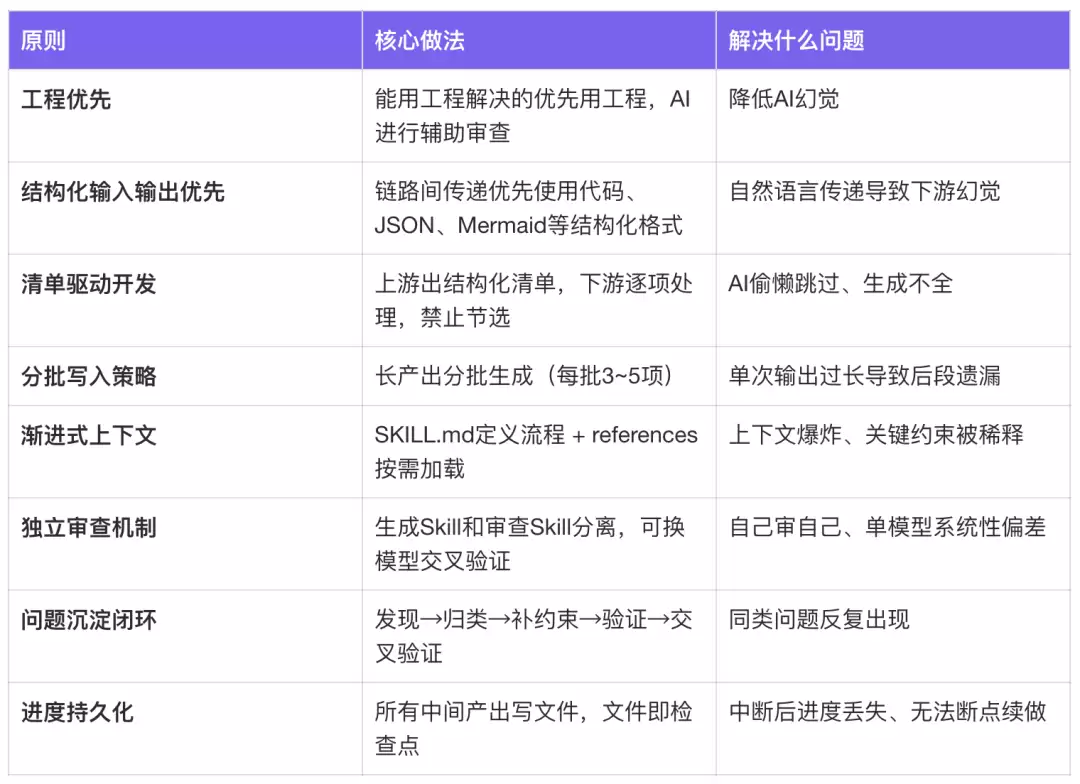
经验总结
Skills构建原则
基础认知:
- Skills是AI研发的最小可复用单元:类比软件工程中“函数/类”封装逻辑,Skill封装的是工作流 + 领域知识 + 约束规则——做什么(SKILL.md)、用什么知识做(references)、不能怎么做(约束与禁止项)。新客户对接不是从零开始,而是换一份输入文档跑同一条流水线
- 质量瓶颈不在模型,在知识工程:50%到90%的提升全部来自知识注入和约束迭代,不是换更强的模型。领域知识(映射规则、API签名、模式判定)不会从训练数据中涌现,必须显式注入
- 确定性工程 + 不确定性AI = 可控的研发流水线:高精度环节用脚本(接口提取),模型不稳定的用架构拆分绕过(推拉分离、子Skill),反复出错的沉淀为约束——三者配合把“不可控的对话”变成“可复现的流水线”
实践经验:
质量控制
通过“事前约束→运行时约束→事后审查→人工卡点”四层防线,贯穿评估→方案→代码全链路:
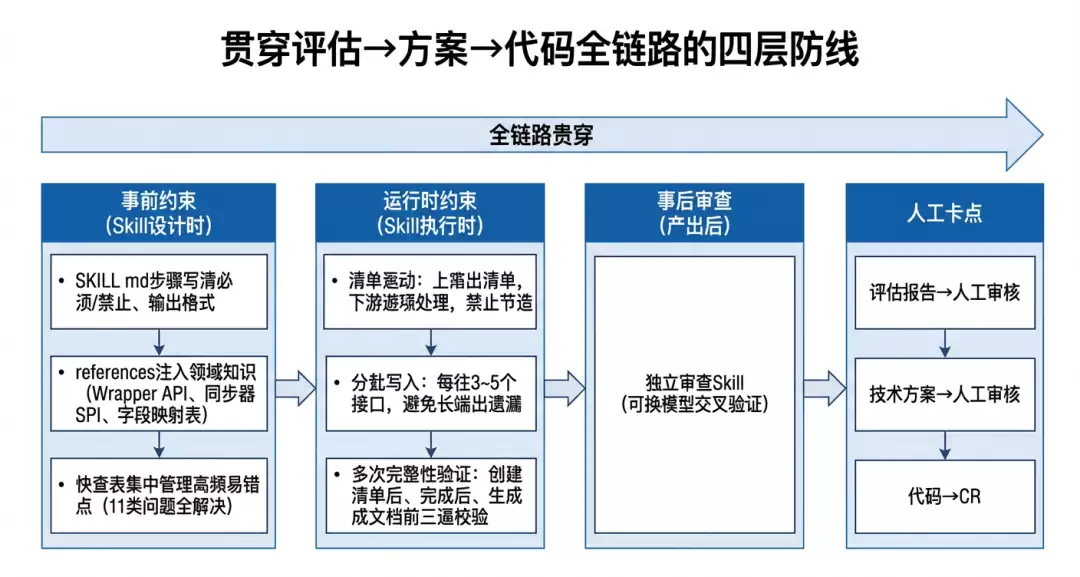
实际效果(XX项目):审查Skill对评估报告审查结果为接口覆盖15/15、字段遗漏率0%、映射方向正确。早期(XX项目)的11类高频问题已全部通过约束沉淀解决。
知识库建设
为什么需要知识库
建设专有知识库,能让AI懂得业务现有的技术背景、领域知识、架构、流程、代码结构等知识,让AI研发更可靠、更“聪明”。在Skill体系中,领域知识通过references目录内嵌到每个Skill中,但随着Skill数量增长,出现了知识分散、更新不同步、跨Skill复用困难等问题,需要构建统一的知识库体系来支撑。
知识库全景
知识库采用三种存储载体协同的架构,覆盖从代码到文档的全域知识管理:
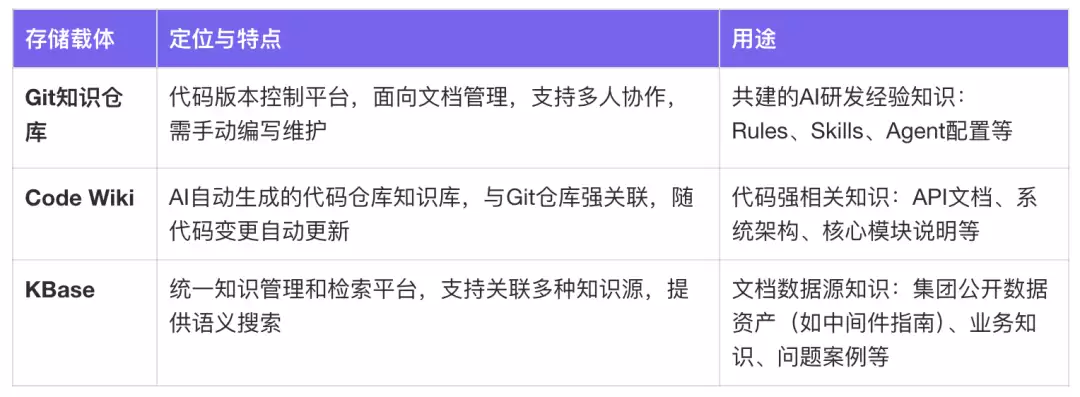
知识的生产与使用
生产知识:
- 多模态支持:钉钉文档、代码、PDF等多种格式
- 多数据源:Git知识仓库、Code Wiki、KBase等
- 多种生成方式:人工维护(研发过程中沉淀的Rules、可复用的原子Skills)+ 自动生成和增量更新(比如KBase支持的钉钉知识库同步、需求完成后Hooks自动更新)
使用知识:
- AI研发流程自动加载知识,通用Skills隐藏底层检索细节
- Git知识仓库:自建索引,支持渐进式拉取
- KBase:RAG召回(文本块/原文),自然语言提问可以召回代码片段加原文档链接
标准化知识管理
参考Anthropic官方Skill的渐进式加载策略(SKILL.md触发时加载 + REFERENCE.md按需加载),构建了三级索引结构,实现知识的按需发现和加载:
ai_coding/
├── GUIDE.md # 一级索引:使用指导,记录目录结构及索引文件位置
├── rules/ # 编码规范
│ ├── index.md # 二级索引:记录所有规则的简单描述
│ ├── alibaba/ # 阿里巴巴编码规范
│ │ └── ja va编码规则规范.md # 三级:知识本身,含元数据+使用示例
│ └── growth/ # Growth 业务规范
├── docs/ # 文档
├── skills/ # AI 技能配置
├── agents/ # AI Agent 配置
├── commands/ # 命令配置
└── package/ # 包配置(批量操作)
每个知识文件通过标准化元数据(name、description、tags等)实现自描述,索引文件自动生成维护,支持按场景检索和按标签检索。
知识分发工具
构建了CLI工具kn-fetcher,支持知识的拉取、搜索和批量分发:
# 拉取编码规范
kn-fetcher pull --platform aone-copilot --rules ja va-coding-standards
# 搜索知识
kn-fetcher search --rules ja va
# 批量初始化(一键拉取项目所需的所有知识)
kn-fetcher pull --platform aone-copilot --package growth-batch-pull
通过init命令一键完成通用知识的初始化下载,降低新人和新项目的知识配置成本。
当前进展
- Code Wiki已完成试跑,生成的数据模型、开发指南、核心模块、API参考符合预期,可以通过MCP召回知识
- KBase已完成试跑,自然语言提问可以召回代码片段加原文档链接
- 三级索引结构和元数据规范已定义完成
kn-fetcherCLI工具6个基础命令(pull / list / search等)已完成,待对接Skill体系

规划与展望:迈向“端到端智能交付”的研发未来
当前评估→方案→编码链路已验证,但沙箱测试(TDD)、SubAgent并行化等能力还没有完全完成,仍有较大的提升空间。下一阶段将继续推进端到端研发闭环,进一步缩短交付周期。
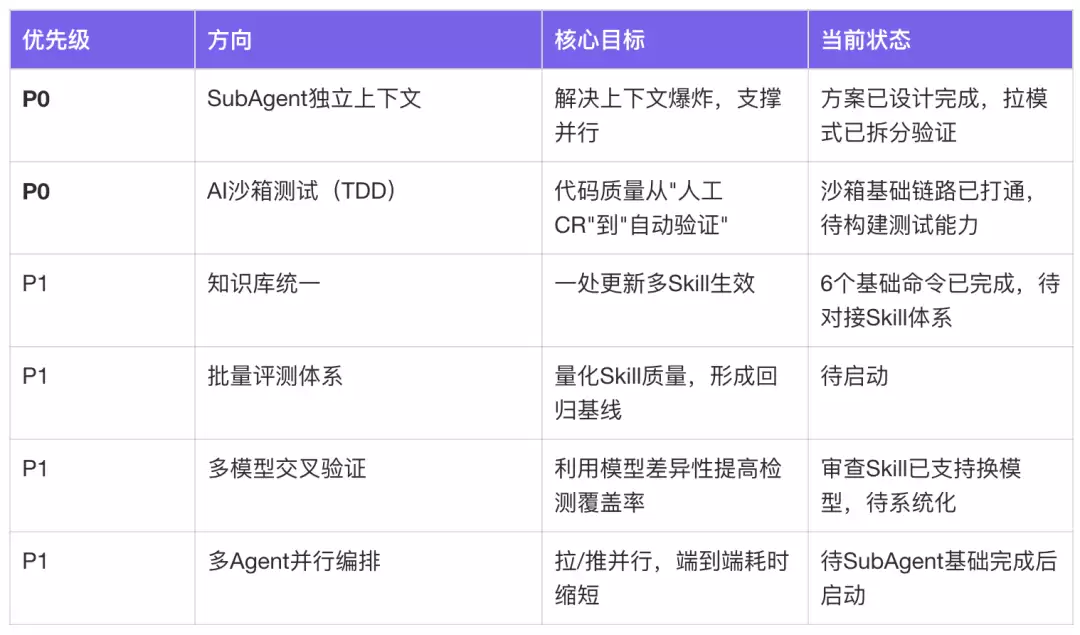

结语
从Vibe Coding到Skills coding,从50%的代码生成成功率到90%,从23.5人日的交付周期到8人日——这不仅仅是工具链的升级,更是研发范式的重构。
在传统思维中,文档是代码的注释;而在SDD思维中,Spec是源代码——开发者维护规范,代码由AI生成。开发者的角色从编码执行者转变为审核者、架构师。
在Skills编程体系里,Skills是人类最佳实践的能力封装。开发者的角色从AI辅助研发,变成辅导AI进行研发,人类彻底成为指挥AI进行工作的人。人类研发可以把更多精力投入到架构设计、代码审核、规范设计等更高价值的创造性工作中。
展望未来,当每个领域的最佳实践都能被沉淀为Skills时,意味着个人经验的产品化、标准化和资产化。AI会真正从“知道分子”成为“行动专家”;AI不是替代者,而是为我们工作的数字专家,帮助我们解放重复劳动,聚焦更高价值的创造。


-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
帅气继父网名女生可爱英文(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
蒙古上单是什么梗
-
韦一敏是什么梗
-
韩漫小少爷网名大全女生(精选100个)
-
网络热词聊污是什么意思
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
抖音最火沙雕男生网名(精选100个)
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
三角洲行动卡战备怎么弄 三角洲行动卡战备攻略
-
因空难被判“过失杀人罪” 空客、法航均被顶格处罚22.5万欧元
-
2 AI知识库的发展,会冲击律师行业吗? 06-19
-
4 Deepseek在政务办公领域12大应用场景 06-19
-
5 AI Agent 助力零售业升级,运营效率提升50% 06-19
-
6 AI越强,越要“杀死”过去的自己 06-19
-
7 腾讯老兵+大厂00后新锐,码上飞想做的不只是AICoding 06-19
-
9 起跑线还没过呢,香槟就开了 06-19
-
10 18年前不让你苦修PS的美图,这次不让你苦修AI了 06-19



