火热的具身智能,藏着半个自动驾驶圈
来源:互联网 更新时间:2026-06-18 15:07
在讨论具身智能之前,不妨先回头看一眼自动驾驶走过的路。从2017到2027,自动驾驶用了整整十年才证明一件事:在特定场景里“做到能用”,远比一开始就“看起来像人”更具决定性意义。今天,聚光灯转向了具身智能,而这个真理似乎正在被重新验证。
回到2017年,那时的自动驾驶圈里弥漫着一种终局将至的乐观情绪。L4、L5的讨论是技术论坛的标配,无人驾驶出租车被描绘成触手可及的未来。十年后的复盘却相当清晰:真正改写行业格局的,从来不是最早信誓旦旦要拿下“无人驾驶”的公司,而是那些率先将辅助驾驶装进量产车、并让数据在真实路况中形成闭环的玩家。
今天的具身智能,恰好站在了当年自动驾驶的那个十字路口。
刚刚结束的智源大会上,人形机器人端咖啡、打乒乓球、做动态分拣的展台前围满了观众,“机器人的ChatGPT时刻”这个说法被反复提及。
然而,在展馆的另一侧,那些从自动驾驶行业走出来的创业者们讨论的是截然不同的话题——哪里能找到第一个能够稳定运行的场景?如何搭建起真实世界的数据闭环?以及,最重要的问题:如何让机器人在“跑起来”的过程中“变聪明”。
星源智创始人刘东给出了一个颇具洞察力的定义:他把自动驾驶称为“最简单的具身”。区别在于,从二维空间里的避障导航,到三维空间里与物体发生物理交互,机器人面对的是指数级复杂的问题。
那么,具身智能是在复刻智驾的叙事节奏吗?为什么从智驾阵营过来的人,成了行业变阵的關鍵变量?他们带来的“渐进式落地”思路,能让具身智能走出一条不同的路吗?
当一个尚未到来的时刻成为行业图腾
智源大会现场,银河通用创始人兼CTO王鹤给出了他对“机器人的ChatGPT时刻”的定义:模型具备零样本能力,无需专门学习即可在特定场景完成70%到80%的人类技能,且可访问性极高——初中毕业的人就能操作。
但星源智创始人刘东给出了另一个视角:“现在具身也是,大家瞄着实际应用的场景去做,但是L2能落地的也还不多,差不多是2015、2016年的智驾状态,刚刚起步。”
2017年那会儿的感觉几乎一模一样:L4级无人驾驶被普遍认为“三到五年内量产”,可真实的量产车里,连在高速上保持车道和自适应跟车都还在反复打磨。
无论是当年的自动驾驶,还是今天的具身智能,
都呈现出“终局先于路径被讨论”的典型特征——行业先形成了对未来的集体想象,再回头寻找通往未来的工程路线。
这种错位在智源大会现场以另一种方式呈现:人形机器人在展台前为观众端咖啡、与人类打乒乓球、在流水线上做动态分拣——这些Demo充满未来感。与此同时,星源智最新发布的ω-EVA模型在LIBERO上的成功率达到98.6%,在RoboTwin上的任务成功率从88.9%提升到90.3%。

数字确实漂亮,但刘东在采访中给出的落地分层相当冷静:纯移动的巡检、导览已经比较成熟;抓放操作解决了90%的场景,但还有部分品类抓不好;至于酒店打扫、家庭服务这类复杂操作,“短期落地还是比较困难”。
需要澄清的是,这并不意味着Demo没有价值——恰恰相反,在新兴技术领域,Demo是技术路线可行性的必要证明。但必须区分的是,Demo证明的是“这件事在特定条件下可以做到”,而交付要求的是“这件事在多变条件下反复做到”。两者之间的鸿沟,自动驾驶用了整整10年才走完。
奈何资本和产业端的热情已经提前就位。智源研究院院长王仲远提到,本届大会汇聚了至少15家以上估值超过百亿的具身智能CEO,“具身智能与人形机器人”是报名最火的论坛之一。这很难不让人联想到2017年自动驾驶圈的“All in AI”——那时只要项目里带着“自动驾驶”四个字,估值和曝光都会自动上一个台阶。
现实的商业进度显然跟不上叙事的节奏。星源智是少数能拿出具体落地案例的公司:叉车上部署的具身大脑、机器狗在开放场景里捡垃圾、物流场景里的自动化拣选。刘东提到,这些合作是跟客户“一事一议”谈出来的,
数据需要共享,场景需要定制
所以,如果要在自动驾驶和具身智能之间画一条线,可能不是叙事在简单重叠,而是两个行业在相似阶段,都面临着同一种“被终局裹挟”的诱惑。这才是这篇讨论中最值得留意的部分。
一代智驾人的“二次创业”
像刘东这样有着自动驾驶背景的创始人,在今天的具身智能领域并不少见。
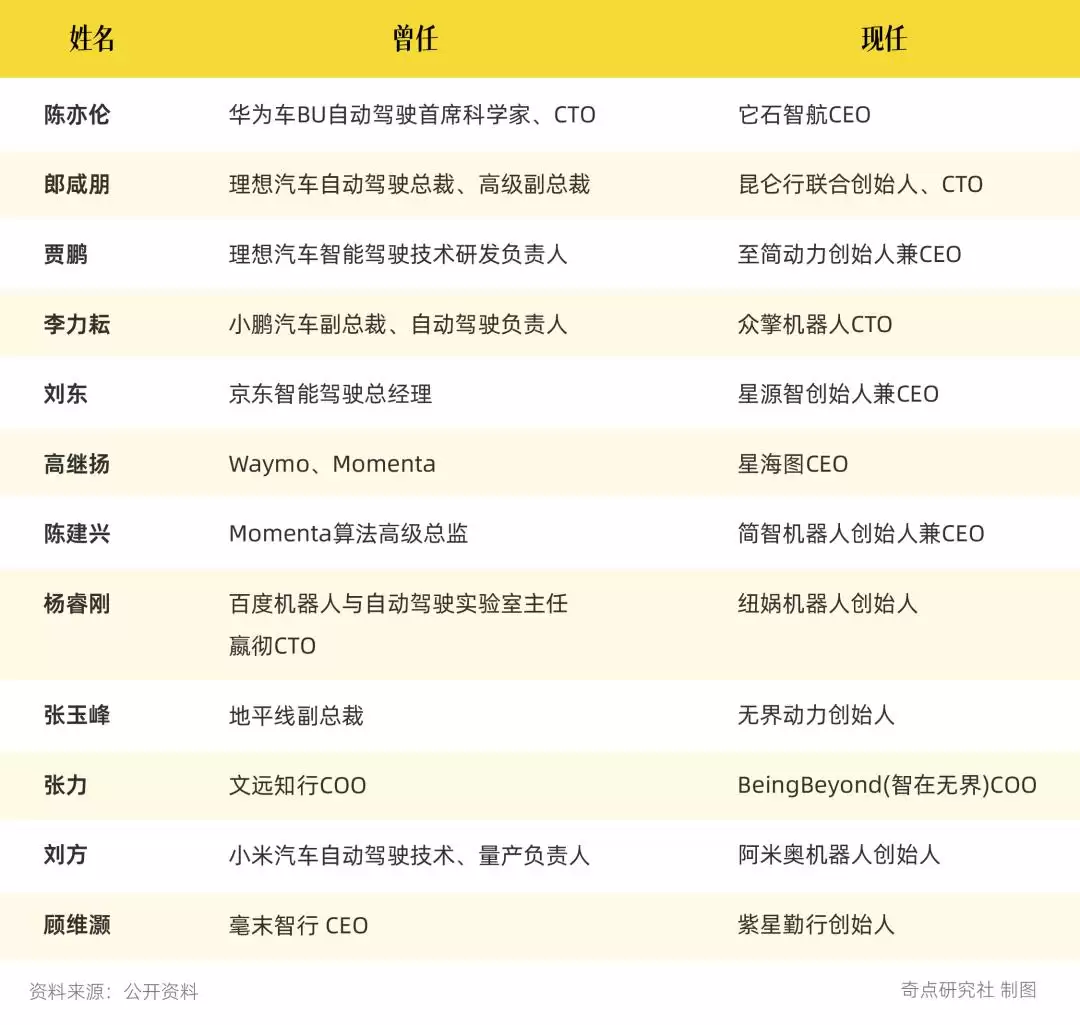
自动驾驶解决的核心问题,本质上可以概括为“让车在平面上不与任何物体相撞”。而具身智能需要处理的,则是“让设备在三维空间里与物体发生交互”。刘东将智驾定位为最简单的具身,“因为智驾当时做的时候,是在平面范围内避开所有的物体,跟物体不发生交互。现在具身领域,除了精确的导航行走之外,还要跟三维空间的物体进行交互。”
从“避开”到“拿起”,这个区别听起来只是动作复杂度的增加,但在工程实现层面,却意味着完全不同的系统约束。自动驾驶里,摄像头和激光雷达主要用于环境感知和障碍物识别,决策链路相对清晰:看到、判断、绕行。而具身智能里,设备不仅要“看到”一个杯子,还得判断“怎么拿”“拿起来会不会洒”“放下去的位置准不准”。
力控、触觉、多模态同步——这些在自动驾驶里几乎是空白课题的东西,在具身智能里成了日常功课。
所以,当这批从智驾过来的人进入具身领域时,他们带来的不只是一套技术栈的迁移,更是一段已经刻骨铭心的产业记忆。2017年的自动驾驶行业,曾集体陷入“全栈自研”的诱惑——算法、硬件、数据、车辆,全部自己干。当时的逻辑是,只有闭环才能做出最好的体验。但后来的产业现实证明,在销量规模起来之前,全栈自研是一个极其昂贵的赌局。
当被问及“头部公司做全栈会不会影响你们”时,刘东的回答带着这种经验的痕迹:“在真正的销量没有起来之前,是没有办法支撑一个公司做全栈研发投入的,除非你已经大到像特斯拉这种规模,账上根本不缺钱。”

他进一步判断,市面上近两百家具身公司里,真正有能力全栈闭环的“顶多就两三家”,更多公司会面临一个选择题:自己从头研发大脑,还是从第三方采购?自动驾驶行业的最终走向已经给出了参考答案——全栈自研的门槛极高,只有少数车企能够负担。行业逐渐分化:一部分资金和技术实力较强的新势力选择深度自研,而更多车企开始转向与供应商合作,或采取“部分模块自研+核心算法外采”的折中路线。
刘东认为,具身智能领域也会呈现类似格局:“有些公司擅长做本体,有些公司擅长做模型,类似于我们以前看自动驾驶在整车行业的发展。”基于这种判断,星源智选择了“不自己做本体”。外界曾把星源智比作“具身赛道的华 为”,提供大脑模型和端侧算力平台,覆盖市面上70%以上的头部本体客户。
这个选择本身,很难说是因为2017年的“失败教训”,还是仅仅因为工程师们已经习惯了产业链分工的效率逻辑。但有一点是明确的:当一个团队已经经历过“什么都想自己做”的阶段,他们在进入新战场时,会更早地思考“什么应该让别人做”。
除了商业模式的分化,
从智驾过来的人还带来了一套对“落地”的务实认知
具身智能难以“大力出奇迹”
回看自动驾驶的发展历程,曾经最受关注的是L5和Robotaxi,但率先进入交通系统的,却是ADAS和L2+辅助驾驶。它们没有L5那么令人兴奋,却在不断运行中积累数据、完善系统,让自动驾驶拥有了继续进化的土壤。
具身智能也在经历类似的过程。家庭保姆机器人仍然遥远,通用机器人大脑也尚未成熟,但叉车、机器狗、物流拣选等场景已经开始落地。它们未必最像人,却最有机会率先跑通数据闭环。如果说ADAS是自动驾驶通往L4的桥梁,那么今天的叉车和机器狗,就是具身智能通往AGI的桥梁。
刘东把落地难度分为三层:
第一层是“纯移动”
第二层是“抓放操作”
第三层是“复杂操作”
这种“分层”既有从智驾移植过来的工程务实,也受限于具身智能独特的数据约束。星源智联合创始人孙振国在采访中指出了核心矛盾:大语言模型可以从互联网上免费获取几乎无限的语料,但具身智能没有“互联网级别的物理数据”。各地政府牵头建的数采厂投入了大量机器人设备去采集动作数据,但获得的数据量对于超大规模训练来说仍远远不够。大语言模型可以堆到几百B甚至上千B的参数,而具身模型目前还在几B、几十B的规模徘徊。
这个瓶颈意味着,
具身智能不可能像大语言模型那样,通过“大力出奇迹”的方式一夜之间突破
它可以“柔性地面对不同任务”
这种“柔性”,不是在实验室里通过更大的模型一次性实现的,而是通过“特定场景的数据闭环”慢慢磨出来的
这也对应了刘东对未来格局的判断:具身大脑公司最终会“分化成不同垂类的专长公司”,有些擅长家庭场景,有些擅长物流场景,有些擅长工业操作。这很像自动驾驶最终分化出的格局——高速NOA、城市NOA、记忆泊车、代客泊车……每个细分赛道里都长出了专门的公司。
所以,回到最初的问题:具身智能是在重演自动驾驶吗?答案是,叙事的节奏确实相似——
终极目标被提前消费,Demo和交付之间存在落差,行业在一开始都会追逐最“像人”的解决方案
自动驾驶花了十年证明,决定胜负的,不是谁最早喊出无人驾驶,而是谁先找到能够持续产生数据的场景。今天的具身智能落地场景远比自动驾驶更分散——人形机器人、家庭服务、通用大脑依然是行业共同追逐的终局。但在终局到来之前,决定行业走向的,或许是仓库里的叉车、园区里的机器狗、流水线上的机械臂……
它们未必最“像人”,却最先让机器人学会成长。
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
帅气继父网名女生可爱英文(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
蒙古上单是什么梗
-
韩漫小少爷网名大全女生(精选100个)
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
韦一敏是什么梗
-
网络热词聊污是什么意思
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
抖音最火沙雕男生网名(精选100个)
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
因空难被判“过失杀人罪” 空客、法航均被顶格处罚22.5万欧元
-
有寓意的易经网名男生(精选100个)
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
免费看电影的软件推荐
-
3 舍弗勒与千寻智能签署战略合作协议,打通具身智能产业落地全链路 06-12
-
4 “六臂玄甲” 亮相上交会 全球首发空间异构六臂具身智能机器人 06-13
-
5 贾跃亭发力具身智能市场:FF将发布多款机器人及教育生态 06-15
-
8 具身智能进入数据预训练阶段:灵初智能与头部数据采集公司的路线观察 06-16
-
9 李想:半数智驾事故发生在接管瞬间 法规上讲完全合规 06-16
-
10 三连发!阿里发布首个具身大模型Qwen-Robot系列 06-16



