3B小模型,编程得分比肩Opus 4.5,神秘模型引发热议,原是国产
来源:互联网 更新时间:2026-06-18 13:54
在AI圈子里,最近有个小模型彻底火了。3B的参数量,硬是在编程这类可验证的推理任务上,跟Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5这些动辄几百B甚至上千B参数的“巨无霸”打得有来有回,进入到了相同的性能区间。体积差了几个数量级,但表现却毫不逊色。

这个模型叫VibeThinker-3B,一个只有30亿参数的密集型推理模型。它的目标很明确:在如此严苛的小模型规模下,把可验证推理能力推向一个极致。模型发布后,社区里不少人都被它的成绩惊到了,纷纷表示想上手一试。

更让人意外的是,它还是一个国产模型,出自新浪微博团队之手。
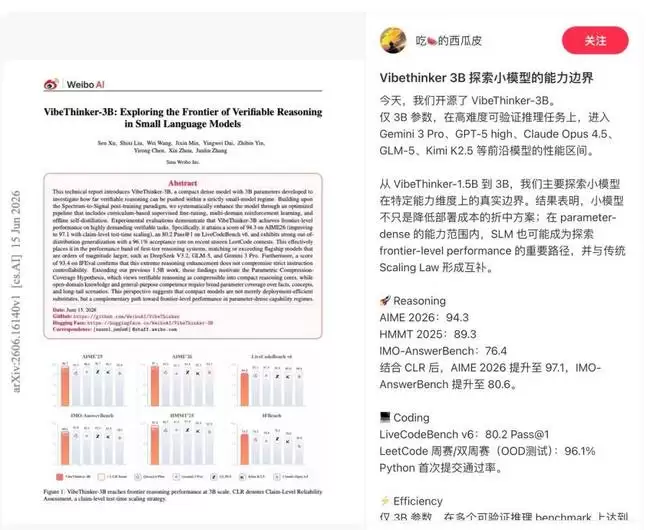
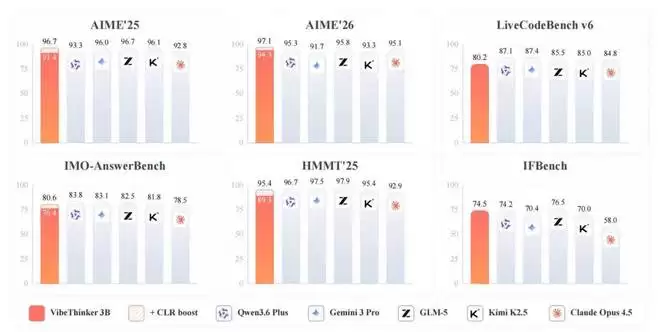
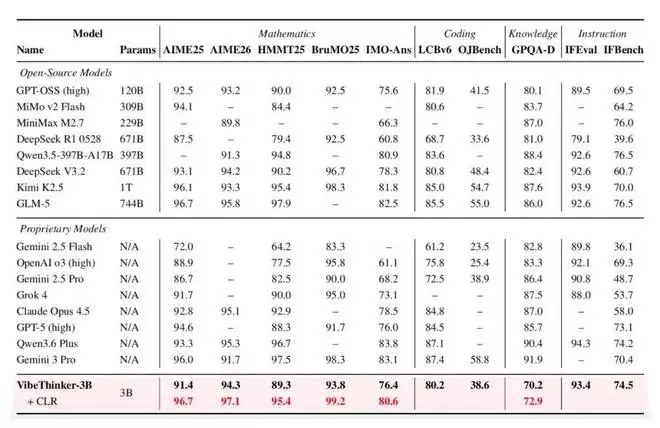
根据技术报告,这个模型专为那些有明确验证信号的任务而生——数学推理、竞技编程、STEM推理,以及带有严格约束的指令执行。因此,它在各项基准测试中表现相当亮眼:AIME26拿了94.3分,HMMT25是89.3分,LiveCodeBench v6(Pass@1)达到了80.2%,更夸张的是,在2026年4月到5月期间LeetCode最新未公开的周赛和双周赛上,它拿到了96.1%的通过率。
那么,这么强的模型到底是怎么训练出来的?技术报告里透露了一些细节。
它基于Qwen2.5-Coder-3B,然后采用了一个升级版的Spectrum-to-Signal流程进行后训练。这个流程很有意思,它在监督微调(SFT)阶段强化了数据合成、质量过滤和课程学习,然后把MGPO风格的强化学习扩展到多个可验证领域,保留完整的长上下文推理轨迹,最后通过离线自蒸馏和指令强化学习(Instruct RL)来巩固各个能力。
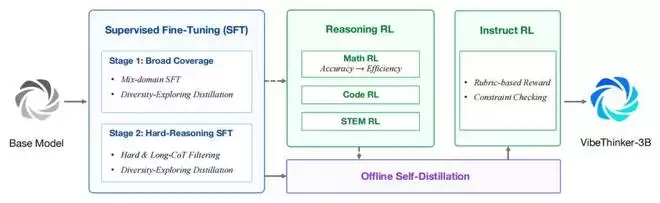
VibeThinker-3B整体训练流程
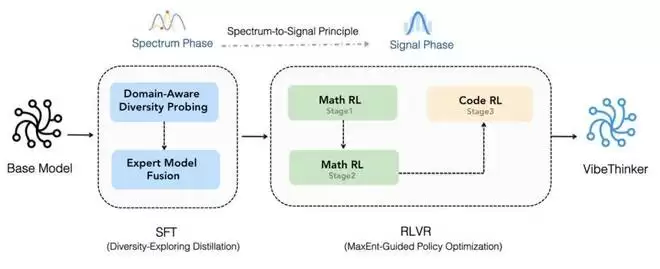
Spectrum-to-Signal流程
此外,VibeThinker-3B还引入了一个叫Claim-Level可靠性评估(CLR)的测试时scaling策略,专门针对答案可验证的推理。这个策略进一步把数学基准测试的成绩往上拉,AIME26从94.3提高到97.1,HMMT25从89.3提升到95.4,BruMO25更是达到了99.2。
具体训练流程可以概括为这几个步骤:
第一,基于课程的两阶段SFT。第一阶段聚焦数学、编程、STEM推理、通用对话和指令遵循,实现广泛的能力覆盖;第二阶段则转向更高难度、更宽视野的推理样本。多样性探索蒸馏被用来保留多个有效的解决方案路径。
第二,多领域推理强化学习。这里重用了MGPO方案,依次在数学、编程和STEM推理上应用强化学习。训练窗口使用了单个64K的长上下文,确保完整的长时域推理轨迹不被截断。
第三,离线自蒸馏。从数学、编程和STEM RL的检查点中,筛选并提炼出高质量轨迹,最终合并到一个统一的学生模型里。这里用了一个“学习潜力评分”机制,优先考虑那些回答正确但学生模型还没完全模仿好的轨迹。
第四,Instruct RL。最后阶段,增强模型对用户提示的可控性。对于格式敏感和开放式的教学数据,结合基于规则的验证器和基于评分标准的奖励模型来训练。
知名AI研究者Sebastian Raschka也系统总结了这份技术报告里的关键点。

如果你对这些细节感兴趣,可以去找完整的技术报告来读,模型也是能公开下载的。

报告标题:VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
报告链接:https://arxiv.org/pdf/2606.16140
HuggingFace链接:https://huggingface.co/WeiboAI/VibeThinker-3B
不过,这个模型的应用范围有明显的局限性——它在需要通用知识的领域表现并不出色。
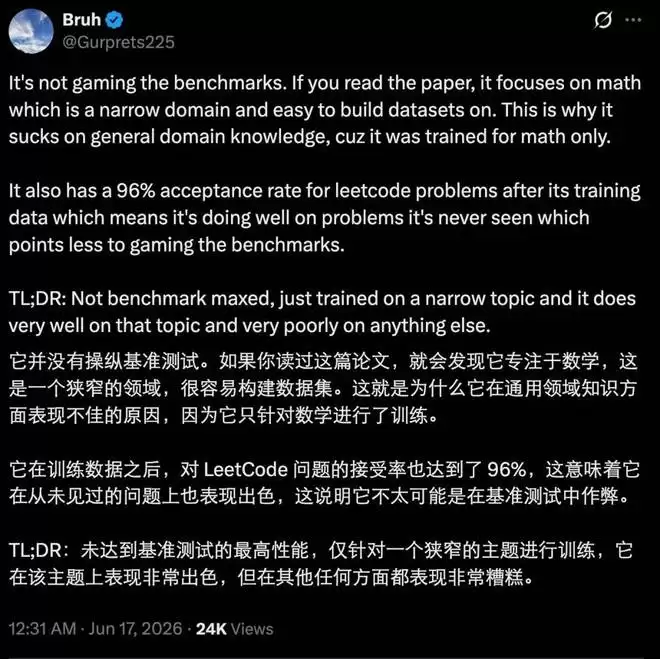
作者团队也明确指出了这一点,并提出了一个“参数压缩覆盖假设”:不同的能力对模型参数的依赖方式完全不同。可验证推理更像是一种高度可压缩、参数密集的能力,核心在于多步推理、约束满足、自我纠错和答案验证。当任务空间结构足够清晰、反馈信号足够可靠时,紧凑型模型也能逼近前沿推理水平。相比之下,开放领域知识、通用对话和长尾场景理解,则依赖大规模参数来广泛覆盖事实、概念和世界知识。
这个假设非常有启发性。正如VentureBeat在报道中提到的:“它揭示了推理能力和事实知识之间是部分解耦的,前者可以比之前设想的更高效地压缩。这对业界如何看待模型设计、部署成本,以及高级AI功能的普及性,都有深远影响。”

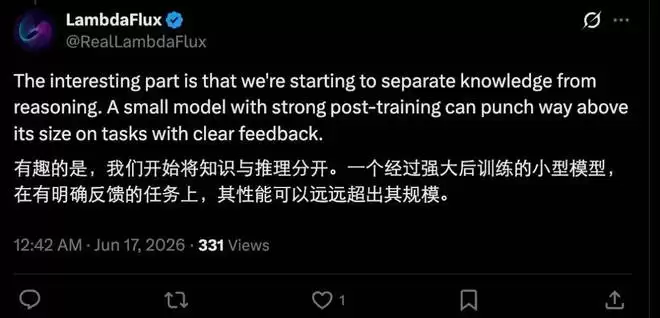
作者表示,他们的目标不是用一个小模型去替代大模型,而是想沿着特定能力维度,审视小模型真正的边界在哪里。通过VibeThinker-3B,他们希望传递一个信号:小模型不应该只是降低部署成本的妥协方案。在那些有清晰反馈和验证机制的能力领域中,小型语言模型正在展现出很有前景的研究路径,有望达到前沿性能,并与传统的参数规模扩展范式形成根本性的互补。
当然,这个模型在社区里也面临一些质疑。如果你感兴趣,不妨亲自下载试一下,看看它的表现到底如何。

参考链接:https://x.com/orcus108/status/2066876960073288567
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
archiveofourown 实战指南:常见用法整理
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
帅气继父网名女生可爱英文(精选100个)
-
帅到极致的网名女生霸气(精选100个)
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
韩漫小少爷网名大全女生(精选100个)
-
网络热词聊污是什么意思
-
电视剧《小欢喜》剧情介绍
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
有寓意的易经网名男生(精选100个)
-
小众游戏抖音网名男生(精选100个)
-
电影《遁甲门之消失的公主》剧情介绍
-
美国市场:股票相对债券的风险溢价正在消失
-
全链网:黄金价格因美元的走强及利率担忧而下跌
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
2 腾讯元宝上线AI编程模式:双栏界面实现边提需求边写代码 06-17
-
3 编程语言排行榜公布:Python蝉联榜首 C语言重返第二 10-07
-
4 古法编程是什么梗 05-23
-
5 全家桶在手的谷歌和字节,为什么编程仍然是软肋? 05-26
-
6 如何入门VB弹球小游戏编程 05-31
-
7 思科发布全新云控制平台:统一管理、自然语言编程与智能运维闭环 06-05
-
8 QoderWake环境搭建:如何打造极简高效的编程界面 06-06
-
9 ChatGPT编程提示词教程怎么控制标题长度和语气 06-08
-
10 Sora编程提示词问题怎么筛掉无关主题 06-19



