代码定位太慢?蚂蚁ACL2026新作:让模型自己学会「该搜多少」
来源:互联网 更新时间:2026-06-14 13:10
AI编程现在确实火得一塌糊涂,但有个挺尴尬的现实:你花在让AI帮忙改代码上的钱,可能有一半以上都烧在了“找代码”这个环节上。
根据一些研究数据,顶尖的AI编程Agent,超过一半的计算资源其实都扔在了代码搜索和定位上——Agent来回翻文件、读代码、找函数,轮次消耗大,Token账单自然也跟着涨。
当大家都在比拼模型有多大、代码能写多长的时候,蚂蚁集团的一篇ACL 2026 Findings论文却瞄准了一个更基础的问题:能不能让搜索本身变得更聪明?
答案是可以,而且效果相当不错——一个只有40亿参数的开源模型FuseSearch-4B,在SWE-bench Verified上拿下了84.7%的文件级F1值,定位能力和Claude Haiku 4.5不相上下,但速度提升了93.6%,Token消耗也省了68.9%。
怎么做到的?一言以蔽之:让模型自己学会该并行多少。
代码定位:AI编程最烧钱的“卡脖子”环节
想想看,你让AI帮忙修一个Bug,它得在一个几十万行代码的大项目里,找到该改哪个文件、哪个函数。这就是代码定位——自动修复里最头疼也最烧钱的一环。
现在主流的做法大概分两类:一类用基于图或检索的方式,快速定位到文件级,然后交给LLM去敲定函数级位置;另一类让LLM自己逐轮调用工具,一步步缩小范围。但两类方法都有一个共同的毛病:一次只能做一件事。

每一轮交互只能调用一个工具,逐步缩小范围。这就像在图书馆找书,规定每次只能翻开一个书架看一眼——轮次用完了,信息还没收集够。论文把这种现象称为“信息匮乏”。
并行 ≠ 万能解药
那解决方案是不是很简单?一次多调几个工具不就行了?可惜没那么简单。论文实验发现,要是每轮固定调8个工具,只会产生34.9%的冗余调用——重复搜索已经看过的区域,不仅浪费Token,还引入噪声信号干扰判断。
核心矛盾就此浮出水面:并行少了,信息不够用,定位精度下降;并行多了,大量冗余,浪费计算资源。
FuseSearch的核心洞察是:搜索效率和搜索质量并非对立关系。关键不在于并行多少,而在于——什么时候该多并行,什么时候该少并行。
FuseSearch:极简工具箱 + 自适应智能
FuseSearch的设计哲学出奇地优雅:不给模型定死规则,让它自己学会动态调整并行度。
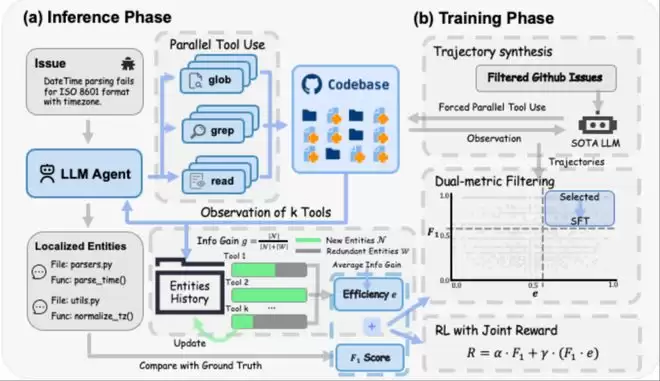
三把“瑞士军刀”
FuseSearch只用三个只读工具,极其克制:

就这三个。不需要代码知识图谱,不需要语法解析器,不需要任何重型基础设施。零依赖,拿来就能用,可即时部署到任意代码仓库。语言无关,Python仓库能用,Ja va仓库也能用。工具虽少,能力完备——glob找文件、grep搜内容、read_file读细节,三者组合可以遍历整个代码库。
关键创新:用“信息增益”量化搜索质量
论文首次提出“工具效率”指标,衡量每次工具调用的信息新颖性:信息增益 = 新发现的代码实体数 ÷ 总返回的代码实体数。
打个比方:你派了5个侦察兵去探路。如果5个人报告的都是同一条路,那4个人就白跑了。工具效率衡量的,就是“每个侦察兵带回了多少独家情报”。效率越高,每次搜索都在探索新区域;效率越低,说明在做重复劳动。
两阶段训练:先学会并行,再学会聪明地并行
FuseSearch的训练策略分两步走:
阶段一:监督微调(SFT)——建立并行能力。
阶段二:强化学习(RL)——学会自适应。
奖励 = 0.8 × 定位准确率 + 0.2 × (定位准确率 × 工具效率)
注意那个乘积项:只有“找得准”且“搜得不浪费”同时满足,才能拿到额外奖励。如果定位完全错误(准确率=0),无论效率多高,奖励都是零——模型不能“高效地犯错”。这个设计迫使模型在搜索的每个阶段都做权衡:当前是广撒网收益大,还是精准验证收益大?
训练结果:一种“先撒网、再收网”的搜索策略。

这种“先广度、后深度”的模式,完全是模型自己从奖励信号中学出来的,没有任何人工规则。
实验结果:小模型大翻身
5.1 核心数据(SWE-bench Verified,386个实例)
在Qwen3-4B上对比之前的方法RepoSearcher,FuseSearch的提升堪称碾压:
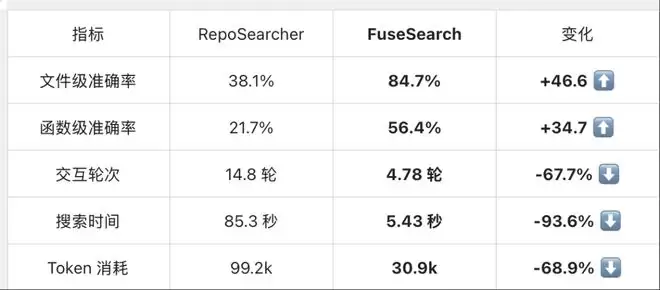
一句话总结:准确率翻倍,速度快16倍,Token省了近70%。
5.2 40亿参数 vs. 商用闭源大模型

一个可以本地部署的4B开源小模型,定位能力与商用闭源大模型持平,同时更快、更省。
5.3 接入下游Agent:不掉精度,省一半成本
把FuseSearch-4B作为Kimi-K2-Instruct的“前置搜索引擎”:
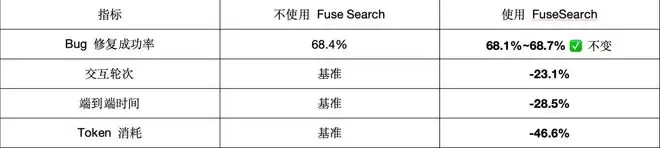
不影响修复效果,直接把成本砍掉近一半。
为什么这项工作值得关注?
FuseSearch带来了三个层面的贡献:
学术层面
工程层面
产业层面
论文信息
论文标题:FuseSearch: Learning Adaptive Parallel Execution for Efficient Code Localization
收录会议:ACL 2026 Findings
作者单位:蚂蚁集团(Ant Group)
论文链接:https://github.com/sxthunder/FuseSearch
-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
帅到极致的网名女生霸气(精选100个)
-
帅气继父网名女生可爱英文(精选100个)
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
韦一敏是什么梗
-
蒙古上单是什么梗
-
韩漫小少爷网名大全女生(精选100个)
-
网络热词聊污是什么意思
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
抖音最火沙雕男生网名(精选100个)
-
作家助手如何上传自制封面 作家助手如何设置小说的封面
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
三角洲行动卡战备怎么弄 三角洲行动卡战备攻略
-
1 程序员危!微软CEO纳德拉:公司高达30%代码是AI写的 04-30
-
2 告别UKey管理负担 锐安信远程代码签名服务来了! 03-23
-
3 扎克伯格亲自下场写代码 把办公桌搬进Meta AI实验室 04-16
-
4 从20%到80%!OpenAI总裁:AI写代码占比猛增 05-01
-
6 马斯克花600亿美元 买了个中国模型底座的代码编辑器 06-20



