谷歌正式推出Gemma 4 12B多模态模型
来源:互联网 更新时间:2026-06-12 14:12
先圈几个重点:Google 正式发布了 Gemma 4 12B 模型,目标是把智能体多模态能力直接塞进笔记本电脑。这款模型定位很明确——它正好卡在边缘设备适用的 E4B 和更高阶的 26B 混合专家模型之间,内存占用更小,功能却不含糊。更重要的是,它是目前端侧中型模型里,头一个原生支持音频输入的。
开发者社区的支持力度相当可观,Gemma 4 系列模型的下载量已经突破 1.5 亿次。从可穿戴机械臂到企业级 AI 安全方案,各种应用层出不穷。现在,大家又可以拿这款新模型继续折腾了。
Gemma 4 12B 的几个关键亮点:
全新的统一架构——不需要多模态编码器,视觉和音频输入可以直接喂进大语言模型的主干网络。推理能力相当能打——基准测试表现接近 26B 模型,多步骤推理和智能体工作流都解锁了。适配笔记本是个硬指标——16GB 显存或统一内存就能在本地跑起来。开放且好拿——Apache 2.0 许可,开发者生态广泛支持。还带草稿模型——多 Token 预测草稿模型能把推理延迟明显降下来。
这几项加起来,意味着先进的多模态能力可以跑到日常硬件上,速度不掉链子,推理能力也没缩水。接下来,细看看它是怎么做到的。
在本地运行最先进的智能体
标准基准测试里,Gemma 4 12B 的表现跟体量更大的 26B MoE 模型非常接近,内存占用却不到后者的一半。16GB 内存的消费级笔记本就能本地跑,直接在设备上解锁多模态和智能体体验。
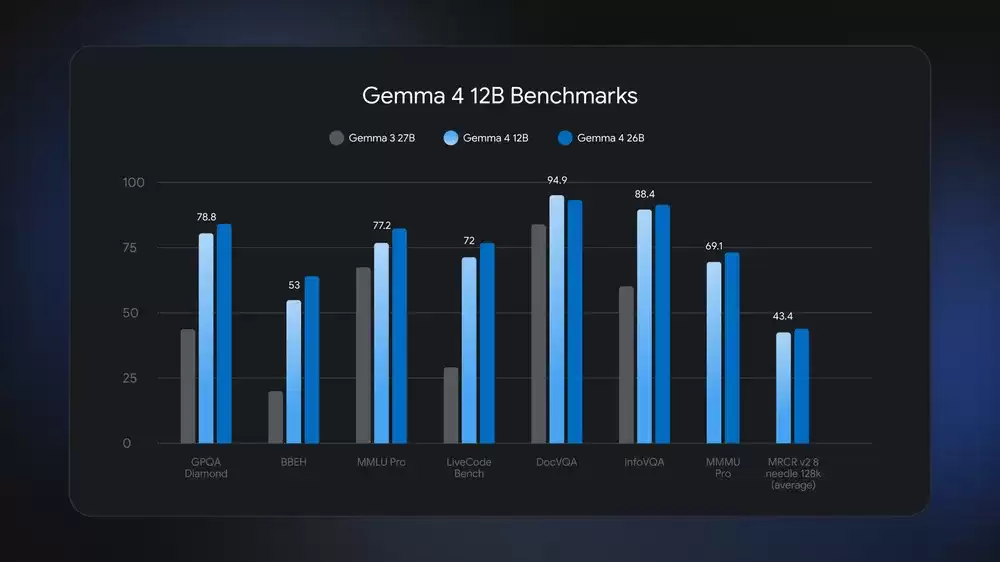
体验独特高效的统一架构
Gemma 4 12B 真正亮眼的地方,在于处理视觉和音频输入时的极简设计。传统多模态模型通常依赖独立编码器来转换图像和音频,再把这些表征传给语言模型。分开的编码器既拖延迟又占内存,所以 Gemma 4 12B 直接用免编码器架构训练,把音频和视觉输入整合到一起。
具体来说,Gemma 4 12B 原生处理多模态输入的方式是这样的:视觉方面,用一个轻量级嵌入模块取代视觉编码器——就是单个矩阵乘法加上位置嵌入和归一化,大语言模型主干直接接手视觉处理。音频方面更彻底,直接移除音频编码器,把原始音频信号投影到跟文本 Token 一样的维度空间里。
想直观感受原生音频处理的实战效果?可以看看 Gemma 4 12B 如何利用 Google AI Edge Eloquent 应用,在完全离线的情况下对语音输入进行转录、格式化和翻译。
现在就可以亲自上手试试:LM Studio、Ollama、Google AI Edge Gallery App、Google AI Edge Eloquent app、LiteRT-LM CLI 里,点几下就能开始实验。模型权重可以直接从 Hugging Face 和 Kaggle 下载预训练和指令微调后的检查点。开发文档和快速入门 Notebook 也准备好了。用 Hugging Face Transformers、llama.cpp、MLX、SGLang、vLLM 这些工具构建本地推理流水线,或者用 Unsloth 高效微调,都行。
为了支持智能体开发,官方还发布了 Skills Repository——一个专门为赋能智能体使用 Gemma 模型而设计的 Skills 库。生产环境部署方面,Google Cloud 可以快速启动推理端点,通过 Gemini 企业级智能体平台的 Model Garden、Cloud Run 和 GKE 来灵活部署。

-
《Off Campus》第二季官宣:这对CP还在,但不再是主角
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
免费影视剧APP推荐
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
DOTA2 TI时隔七年重返上海!门票6月10日开抢,国服享受优先购买!
-
HBO 奇幻剧《龙之家族》第三季定档 6 月 22 日,最终预告片曝光喉道海战
-
抖音最火沙雕男生网名(精选100个)
-
帅气继父网名女生可爱英文(精选100个)
-
网络热词聊污是什么意思
-
阿里发布Qwen3.7-Max大模型,全球第五、国产第一
-
SpaceX狂揽AI人才,马斯克亲自面试且不看简历背景
-
金铲铲之战s17六暗星卡莎阵容玩法构筑指南
-
免费看电影的软件推荐
-
我的末日校园海斗手游上线时间是哪天
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
晨字沙雕网名大全女生(精选100个)
-
短剧《情绪超市》剧情介绍
-
1 读懂 Harness,掌握智能体工程化的核心骨架 06-08
-
7 手机AI天花板 中兴gui手机智能体全方位断层第一 06-10
-
9 三星升级 Bespoke AI 冰箱 家庭中心,全面提升智能体验 06-11
-
10 全球芯片产能持续紧张!谷歌考虑与三星合作研发下一代AI芯片 06-12



