Exa获2.5亿美元融资,打造Agent原生的“Google”
来源:互联网 更新时间:2026-06-05 12:54
最近这一年,Agent才算是真正从实验室走到台前,开始在ToC和ToB两个端落地生产力。在个人端,它化身私人助理和代码拍档,帮你处理搜索、写作、购物、旅行规划这些日常任务;在代码助理这个身份下,它又能直接帮开发者完成具体工作。
在企业端,Agent已经悄悄渗透进销售线索挖掘、客户研究、招聘、投研、法务尽调、代码开发、客服、数据分析等核心工作流里。
Agent的能力,掰开来看其实就是三件事:理解目标、获取信息、执行动作。模型负责理解和推理,工具负责执行,而搜索,则负责从外部世界获取情报。获取信息这件事,是Agent能力的命脉。如果拿不到高质量的信息,Agent很容易变成一个“高智商但满地跑调”的系统——听起来聪明,但给出的东西经不起推敲。
这就像当年Google用搜索重新定义了人类使用互联网的方式,最终成了科技行业事实上的基础设施。现在,Agent范式正在成为主流,它也需要一个Agent原生版本的“Google”来支撑。
有一家叫Exa的公司,把目标直接对准了这件事——他们想做的是“AI原生搜索”,成为AI和Agent默认的信息基础设施。
最近,Exa完成了2.5亿美元的C轮融资,估值达到22亿美元,由a16z领投,Benchmark、Lightspeed、Y Combinator也跟投。他们对外宣称,已经在服务Cursor、Cognition、HubSpot、OpenRouter、Monday.com等AI头部公司,背后还有40多万的开发者和5000多家公司。
AI时代,搜索需要从底层重做一遍
Exa的创始人是Will Bryk和Jeffrey Wang,两人在哈佛读本科时就已经相识,都是计算机背景,一起做过技术项目。毕业后,Will Bryk去了机器学习创业公司Cresta做软件工程师,Jeffrey Wang在Plaid工作。2021年,他们创立了Exa,最初的名字叫Metaphor。

早在2021年刚创立Exa时,他们就已经判断世界需要比Google更好的搜索。当年11月,Exa上线了第一版搜索引擎,大约两周后ChatGPT发布。团队很快意识到:AI应用会比人类更需要搜索。
为什么AI或Agent需要专属的搜索?它跟面向人的Google搜索,到底有什么不一样?
传统Google搜索的逻辑是:人类输入短关键词,搜素引擎返回链接列表,然后你一个一个点开、浏览、判断、整合。整个系统完全是围绕人类的行为模式优化的。
但Agent需要的是另一种东西。它要的是正文、摘要、结构化字段、JSON、引用、置信度、来源追踪。人类可以自己打开网页读,Agent却需要系统先把网页清洗、抽取、压缩成模型可以直接用的上下文。人类可以接受搜到“关于某类对象的文章”,但Agent往往需要对象本身——公司列表、人名列表、产品列表、代码片段、新闻事件。
而现在的一些Agent或AI搜索,底层其实仍然依赖Google/Bing针对人类优化过的搜索结果,上层只是用大模型加了一层摘要,并没有真正重建搜索本身。
Exa的判断是:AI时代,搜索必须从底层重做一遍。从网页爬虫(crawler)、索引(index),到检索模型(retrieval model)、向量数据库(vector database)、内容抽取(content extraction),再到Agent化的研究管线(agentic research pipeline)——整条链路都要重构。
换句话说,从抓网页、建索引、理解查询与网页之间的语义关系,用向量数据库做大规模语义检索,从网页中抽取模型可用的证据,再到让Agent多轮搜索、验证并生成结构化结果,每一个环节都跟传统搜索不一样。
上一代搜索战争,由“为人类组织信息”的公司赢得;下一代,很可能由“为Agent组织信息”的公司赢得。
Exa还有一个核心判断:未来Agent对搜索的需求量会远远超过人类。人类每天搜几十次可能就算重度用户了,但Agent完成一个任务,可能连续搜索几十次、上百次。长远来看,大模型发起的搜索量,可能达到今天Google搜索量的1000倍。
那么,Exa跟那些底层仍依赖人类搜索结果的AI搜索有什么本质不同?我们可以从两条线来看:底层系统怎么建,以及它的产品如何帮助AI/Agent获取信息。
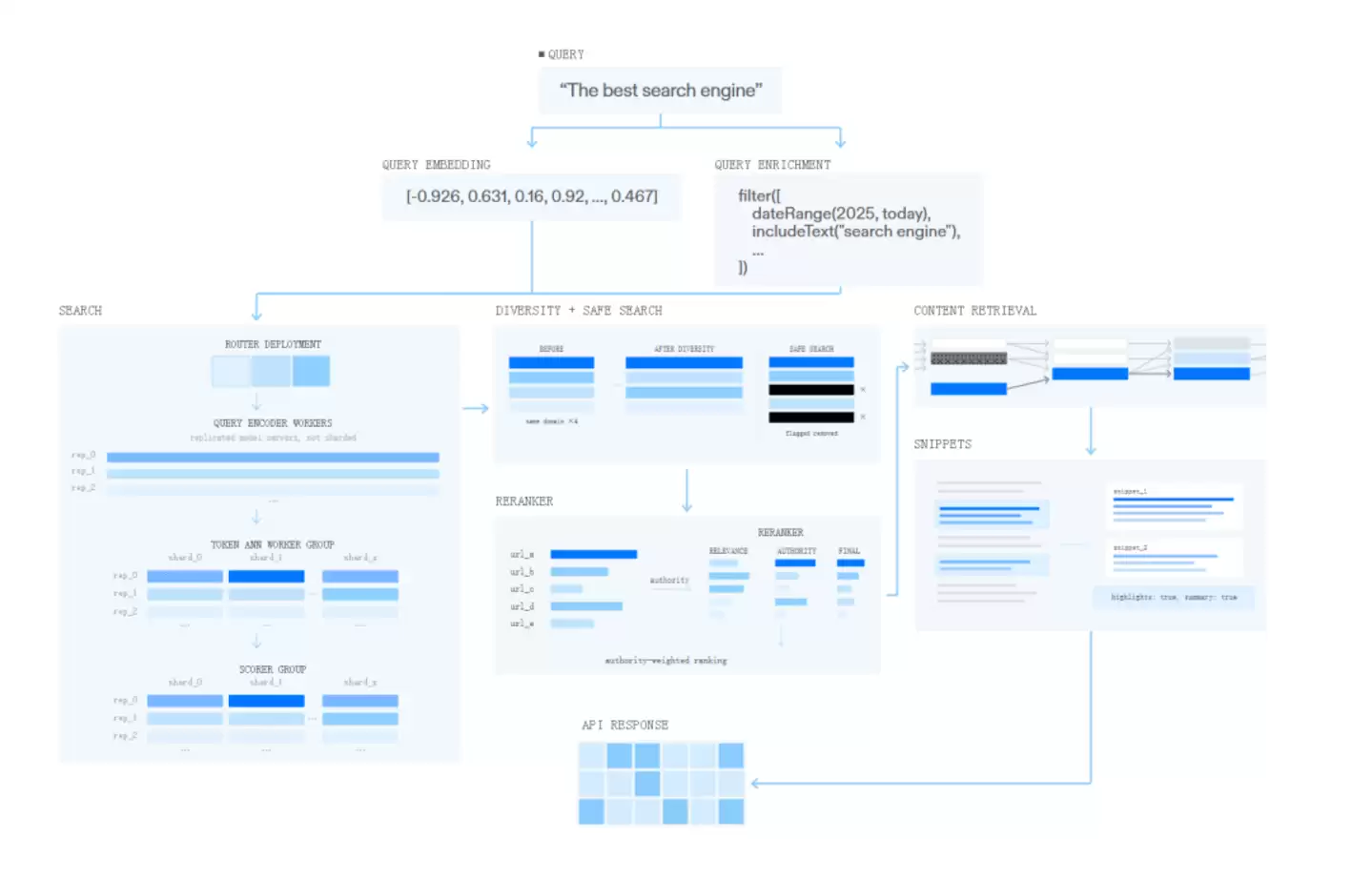
先看底层系统。Exa把搜索基础设施拆成三件事:网页抓取、文档处理、查询服务。
第一步是网页抓取。Exa自建爬虫(crawler),持续发现新URL,用分布式机器和IP池抓取网页,再通过自建的HTML解析器(HTML parser)处理页面,最终把数据存入数据库。据Exa透露,他们的爬虫已经追踪了5000亿以上的URL。真正的难点其实不只是规模——网页格式混乱、内容持续变化、低质量页面占比极高,系统必须有能力判断哪些页面值得进入高质量索引。
第二步是文档处理。网页进入系统后,会被加工成多种可检索的形态:关键词索引、BM25(一种经典的关键词相关性算法)、元数据(metadata)、高相关片段(highlights)和语义向量。Exa走的是关键词检索与神经网络语义搜索(neural search)的混合路线,用来覆盖精确匹配、长查询、语义搜索,以及人物、公司、代码这类实体搜索。
第三步是查询服务。用户或Agent发起搜索时,系统既要兼顾低成本、高QPS(每秒查询数)和低延迟,也要让复杂查询获得更多计算资源。为此,Exa自建了向量数据库(vector database),并用聚类、嵌套式向量、二值量化、SIMD(CPU指令级并行优化)、Rust等方式来提升检索效率。
在搜索流程上,Exa用一套叫Canon的编排系统,把查询改写、检索、重排序、去重、内容读取和来源追踪等模块组合起来,支撑起Fast Search、Deep、Websets、Agent API、Monitors等不同的产品形态。
Exa有一个长期判断:最终胜出的系统,一定是能吸收更多计算资源、并且随着计算增加持续变强的系统。传统关键词搜索更像静态系统,增加算力很难带来根本变化;而基于向量表示的神经网络搜索(embedding-based neural search),则可以通过更多训练数据、更多GPU和更强模型来持续迭代。
落到产品层面,Exa的能力对应的是Agent获取信息的一条完整路径。
首先是找信息。Agent通过Exa Search API搜索开放网页,获取最新信息,补足模型参数中的旧知识。
接着是读网页。搜到网页之后,Agent还要能读取内容。Exa的Contents API,以及Search API里的contents参数,可以从网页中提取正文、摘要、highlights和metadata,把原本杂乱的网页内容整理成大模型可以直接使用的上下文。
遇到复杂任务时,搜索会进入更深的研究模式。Exa在Search API中提供了deep、deep-reasoning等搜索类型,用更多查询和推理步骤来做结果综合。同时,他们还推出了更高算力版本Deep Max,面向研究、尽调、市场分析和线索挖掘这类高难度任务。
最后是结构化输出。通过Agent API、Websets、Answer API、Research相关能力,Exa可以把搜索和网页读取的结果整理成JSON、表格或字段列表——比如公司名、融资轮次、创始人、近期动态、来源链接等,方便直接接入CRM、投研系统或Agent workflow。Monitors则负责持续追踪变化。
Exa之所以选择自建这些环节,是因为Agent搜索对实时性、完整性、结构化和可验证性的要求比人类搜索高出一个量级。掌控了crawler、index、检索模型、向量数据库和内容抽取,就能更主动地优化召回范围、更新频率、延迟、单位成本和结果格式。这些能力持续积累下来,就会形成比单一模型或单一API更难复制的系统壁垒。
在应用场景上,Exa目前的重点是把能力嵌入Agent和企业工作流。公司称,已有5000多家公司使用Exa,场景覆盖代码、销售、研究和AI应用基础设施。
在代码Agent场景里,Cursor、Cognition、CodeRabbit这些产品需要搜索技术文档、API reference、GitHub issue、release notes等内容,帮助Agent理解外部代码环境,再生成修改建议或执行任务。
在GTM和销售场景里,HubSpot、11x、WebFX等会用Exa来找公司、找人、补全线索和监控客户动态。比如按行业、地区、融资阶段、技术栈筛选潜在客户,再补充决策人、近期动态和来源链接,直接接入CRM或销售自动化流程。
在市场研究、投研和企业研究场景里,Exa Deep、Deep Max、Websets可以读取新闻、公司公告、融资稿、招聘信息、行业资料,并输出表格、字段列表或研究摘要。
Agent成为主流,它的基础设施里藏着巨大机会
Agent逐渐成为主流应用范式,这事儿带来的变化是根本性的。
在应用层面,人们和AI的交互不再只是让它完成工作流里的一个环节,而是把一个任务整个丢给它,让它独立完成。更彻底一点,你甚至可以让多个Agent并行完成多个任务。以前我们把AI当工具用,现在可以把它当成一个AI员工、一个AI同事。
在商业模式上,AI正在从卖Token、卖订阅席位,转向卖结果。因为Agent真的开始能够独立交付高质量的结果了。
当Agent变成AI的主流应用范式,它必然会推动配套的基础设施一起改变——无论是云端和终端的算力,还是管理工具调用的“互联网”,当然也包括这次聊到的、专门为Agent打造的搜索引擎Exa。这里面蕴藏的机会,才刚刚开始浮现。
-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
免费影视剧APP推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
好用的手环阅读app下载安装
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
短视频软件推荐
-
短剧《情绪超市》剧情介绍
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
官姓可爱谐音网名女生(精选100个)
-
《梦幻西游》出道人金价走势解析-云游道人影响解析
-
免费看电影的软件推荐
-
1 日产逍客座椅加热功能如何操作 06-05
-
2 Codeium写README开头提示词怎么写才不生硬 06-05
-
3 Codex生成的文案太生硬?调整语气与风格的技巧【解答】 06-05
-
4 罗曼股份业务重构进行时,2.93亿定增持续加码算力业务 06-05
-
5 数字化领航碰撞安全新征程:第四届博士生论坛分会场共话创新未来 06-05
-
6 文心一格写运动品牌视觉提示词怎么把限制条件说完整 06-05
-
7 Runway写转场提示词时,提示词里要写哪些背景信息 06-05
-
8 Pika生成短剧冲突片段提示词怎么把目标用户说清楚 06-05
-
9 Suno v4安装后找不到图标?桌面快捷方式恢复方法【方法】 06-05
-
10 讯飞星火润色短句提示词怎么避免一眼模板感 06-05



