别光给Agent加Tool了,它根本选不明白!复旦×通义提出全新CUA训练范式
来源:互联网 更新时间:2026-06-01 07:05
给Agent配上GUI操作和工具调用,结果准确率反而下降了——这听起来是不是有点反直觉?但现实就是这么令人头疼。
问题出在哪儿?模型根本不会在GUI和Tool之间做选择。该点击按钮的时候它去调API,该调API的时候它又在菜单里死磕,两头乱窜,越帮越忙。
复旦大学和通义实验室MobileAgent团队联合提出的
ToolCUA
结果相当亮眼。ToolCUA-8B在OSWorld-MCP上达到了
46.85%
Claude-4-Sonnet
Claude-4.5-Sonnet
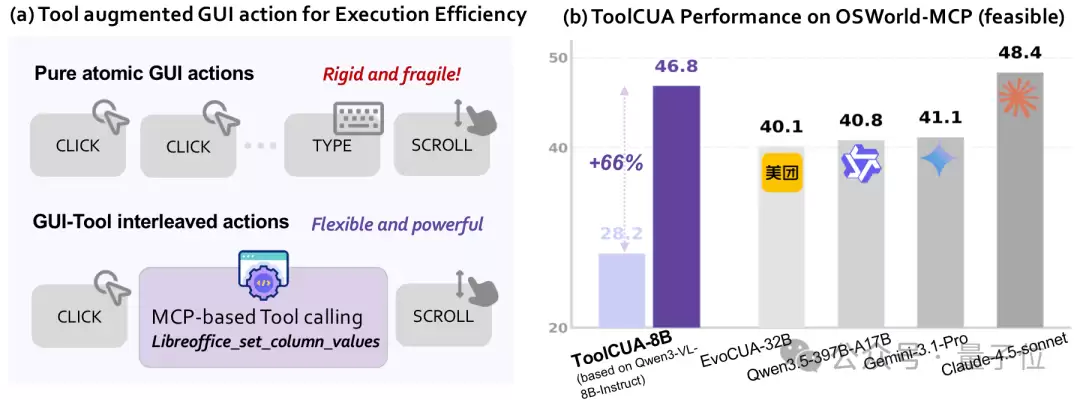
混合动作空间下的路径困惑
传统的CUA主要依赖原子化的GUI操作,比如点击、输入、拖拽、滚动。这类操作泛化性强,只要界面上能看到按钮,理论上模型就能点。但短板也很明显:步骤长,误差容易累积,在复杂任务中很容易出现cascading errors(级联错误)。
相比之下,Tool calls或API-based operations往往更高效、更精确。比如在LibreOffice里批量处理表格,用纯GUI可能需要一串冗长的菜单点击和参数配置,而工具调用可能一个API就搞定了。
看起来最自然的方案,是让Agent同时掌握GUI和Tool。但实验结果揭示了一个非常反直觉的事实:
直接把Tools接到强模型上,并不会自动提升性能。
在hybrid GUI-Tool action space中,Agent每一步都站在一个岔路口:左边是GUI,右边是Tool。GUI泛化强但慢,Tool快却依赖覆盖与上下文条件。如果模型缺少路径选择能力,就会表现出两类典型失败:
Tool underuse
Tool overuse
论文将这个问题定义为
optimal GUI-Tool path selection
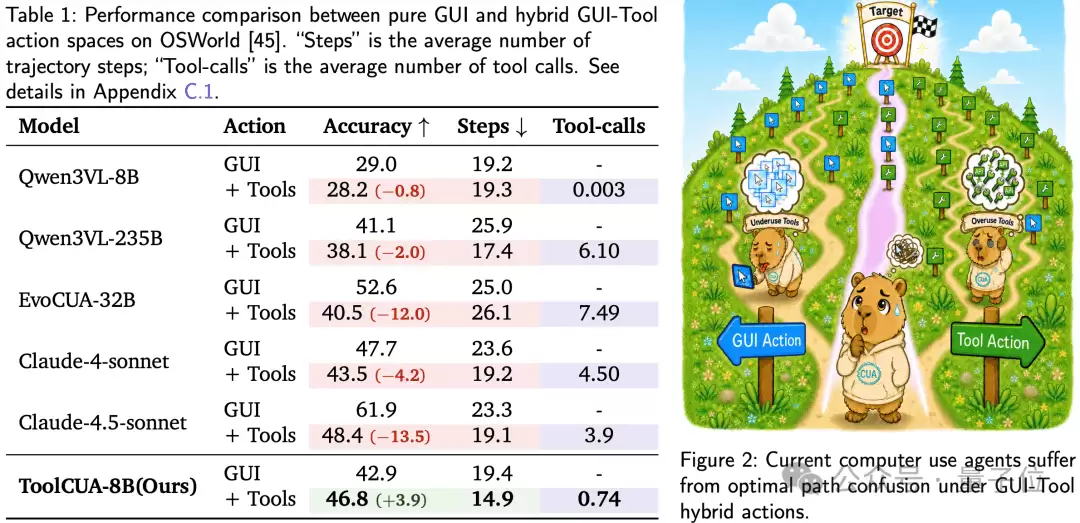
上图左侧的表格直接呈现了这个反直觉的现象:一旦给强模型加上tools,结果并不总是更好。
Qwen3VL-8B几乎不使用工具,平均tool calls只有0.003,准确率从29.0%降到了28.2%;Qwen3VL-235B则更倾向于调用工具,平均tool calls达到6.10,步骤数从25.9降到17.4,但准确率反而从41.1%降到38.1%。
Claude系列同样印证了这一点。Claude-4-sonnet加入工具后步骤数从23.6降到19.2,但准确率从47.7%降到43.5%;Claude-4.5-sonnet的步骤数从23.3降到19.1,但准确率从61.9%降到48.4%。
这说明,混合动作空间真正的难点不在于有没有工具,而在于
模型在GUI和Tool之间会不会选路
第一阶段:数据合成与Tool-Bootstrapped RFT
要让模型学会GUI-Tool path selection,首先需要高质量的interlea ved GUI-Tool trajectories。但现实中,这类数据极度稀缺。
真实工具接口往往与应用强相关、覆盖不完整,而且维护成本很高;收集真实的GUI-Tool混合轨迹又需要复杂的环境接入和人工标注。已有的GUI数据虽然规模很大,但大多数是GUI-only trajectories,只教模型如何点击和输入,并没有告诉模型何时应该用工具替代冗长的GUI操作。
ToolCUA的第一步,就是把现有的GUI-only数据盘活,并顺势完成第一阶段的hybrid bootstrapping。
论文提出了
Interlea ved GUI-Tool Trajectory Scaling Pipeline
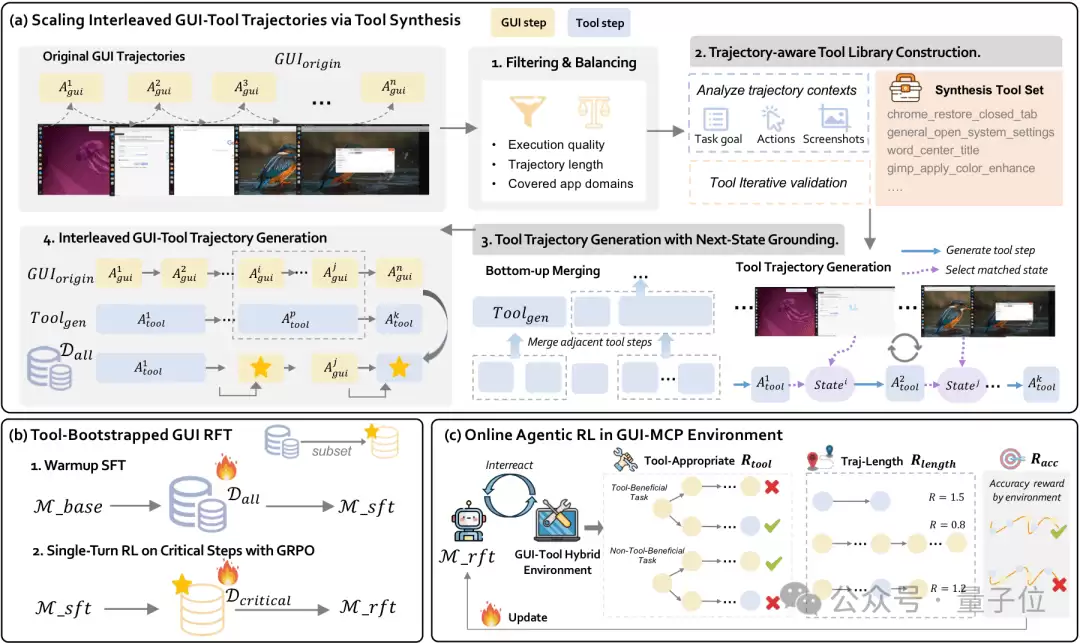
整个pipeline可以概括为三个步骤:
1、Trajectory-aware synthetic tool library construction。
对每条GUI轨迹,模型会分析任务目标、动作序列和截图描述,从真实操作流程中抽象出可调用的工具。比如从Chrome设置流程中抽象出chrome_open_language_settings,从LibreOffice表格操作中抽象出读取工作簿信息、创建透视表等工具。这些工具不是凭空生成的API模板,而是grounded in concrete trajectory beha vior——从真实的GUI行为中抽象出来的工具能力。
2、Tool trajectory generation with next-state grounding。
给定合成工具库和原始GUI轨迹,MLLM生成一个功能等价的tool-only trajectory,并为每一步预测tool response。随后通过next-state grounding,将工具执行效果锚定到原始GUI轨迹中的下一帧截图,验证工具步骤和可见状态变化是否一致。
3、Interlea ved GUI-Tool trajectory generation。
最后,系统不会简单地把所有GUI操作都替换成工具,而是随机采样部分工具调用,再替换回对应GUI子序列,形成多种GUI与Tool交错的轨迹。这个设计非常关键:它让模型看到不同tool a vailability下的决策边界,也自然产生了GUI -> Tool和Tool -> GUI的critical switching steps。

最终,ToolCUA的数据包括了大约4k个unique tools,覆盖fine-grained、mid-grained、coarse-grained多级粒度,大约有180k steps数据用于warmup SFT,还从critical steps中sample出5k条用于single-turn RL。
基于这些数据,ToolCUA进一步执行
Tool-Bootstrapped GUI RFT
具体来说,ToolCUA先在D_all上进行warmup SFT,学习多模态工具调用知识,包括工具用途、参数、返回结果,以及工具执行后的状态变化。随后,模型在D_critical上进行single-turn RL,在明确的GUI-Tool switching steps上采样多个completion,并通过反馈校准模型在局部边界上的选择。
这一阶段做的事情,可以概括为:
先把interlea ved GUI-Tool数据合成出来,再让模型学会用工具,并在局部切换点上别选错。
Online Agentic RL与Tool-Efficient Path Reward
如果说第一阶段解决的是让模型先进入hybrid action space,那么第二阶段解决的就是:
模型如何在真实环境里学会trajectory-level的路径选择。
ToolCUA的第二阶段是
Online Agentic RL
团队首先构建了同时具备GUI actions和Tool calls的高可用Sandbox用于agentic RL,并且为工具返回结果设计了更结构化的格式,便于模型理解。
Agentic RL优化的核心是
Tool-Efficient Path Reward
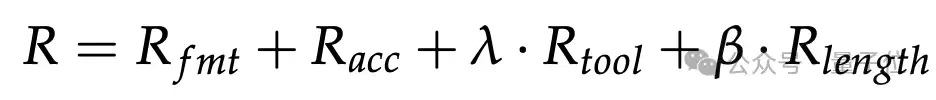
其中,R_fmt和R_acc分别是标准格式奖励与任务成功奖励;R_tool和R_length则是ToolCUA专门设计的两项轨迹级奖励,并且它们只在成功轨迹上激活,避免模型从失败执行里学到错误偏好。
第一项是
Tool Appropriateness Reward (R_tool)
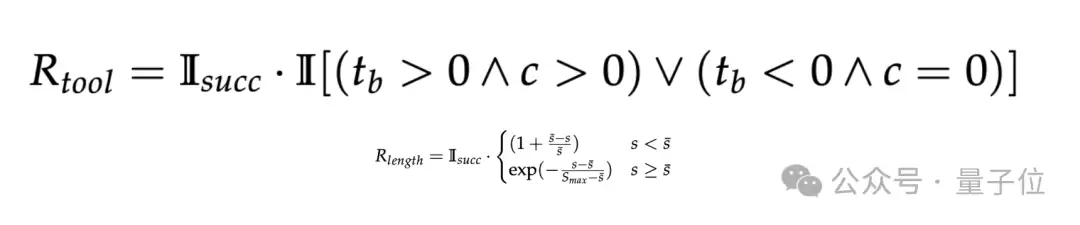
在数据构建时,每个任务会带一个task-level的tool-beneficial标记:t_b = 1表示这个任务适合用工具,t_b = -1表示不适合用工具。同时,c表示整条轨迹里的tool calls数。
于是,R_tool奖励的不是工具调用更多,而是更精确的两种行为:对于适合工具的任务,成功轨迹里确实调用了工具;对于不适合工具的任务,成功轨迹里反而没有乱用工具。
它要解决的正是前面提到的hybrid confusion:有些模型明明该用工具却不用,有些模型则在不该用的时候乱用。R_tool的作用,就是把工具是否合适这件事从任务成功里单独拎出来训练。
第二项是
Path Efficiency Reward (R_length)
这里,s是当前轨迹的步数,bar{s}是同组rollout的平均步长,S_max是最大执行步数。ToolCUA不拿一个固定阈值来判定长还是短,而是做group-relative comparison:
如果某条成功轨迹比组内平均更短,就给线性bonus;如果更长,就做衰减。
这样设计的好处是,模型会自然倾向于探索更短的成功路径。而在很多场景里,更短的路径恰恰意味着:用一个高层工具替代一长串冗余GUI操作。因此,R_length本质上是在鼓励模型发现更高效的
GUI-Tool execution path
所以,这一阶段的核心并不是让模型调用更多工具,而是让它学会两件事:
什么时候工具真的合适,什么时候这条执行路径真的更短。
OSWorld-MCP上达到46.85%,相对提升约66%
ToolCUA主要在OSWorld-MCP上进行评测。这个benchmark在传统OSWorld的基础上引入了hybrid GUI-Tool action space,覆盖典型GUI actions、150+ tools和主流桌面应用,很适合衡量模型在真实混合动作空间中的执行能力。
评测指标包括:
- Accuracy:任务成功率
- TIR (Tool Invocation Rate):是否做对任务,并且在tool-beneficial tasks中使用工具,在non-tool-beneficial tasks中避免工具
- ACS (A verage Completion Steps):平均完成步数,衡量执行效率
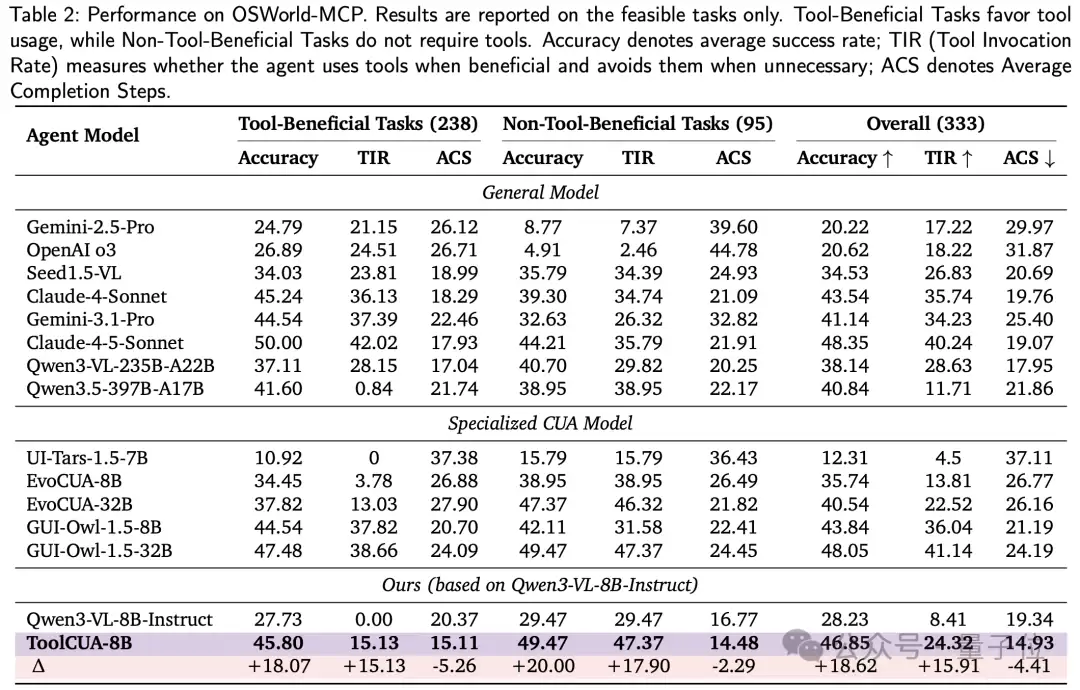
ToolCUA-8B在OSWorld-MCP上取得了
46.85%
28.23%
66%
同时,ToolCUA超过了GUI-Owl-1.5-8B(
43.84%
41.14%
43.54%
48.35%
48.05%
更值得关注的是效率指标。ToolCUA的ACS仅为
14.93 steps
与Qwen3-VL-8B-Instruct相比,ToolCUA的overall TIR从
8.41%
24.32%
19.34
14.93
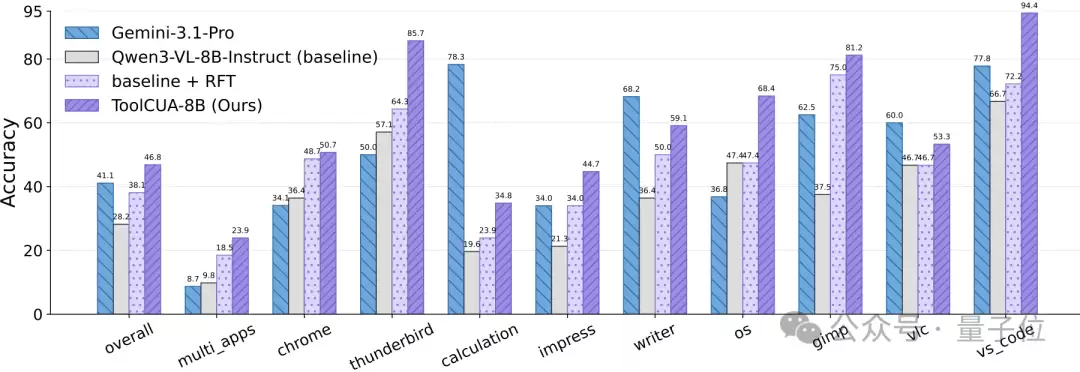
在训练阶段,Online Agentic RL只使用单应用Linux任务,并刻意排除了multi_apps domain,用于OOD验证。
结果显示,在held-out multi_apps任务上,ToolCUA从baseline的
9.8%
18.5%
23.9%
在具体应用域上,ToolCUA也有明显提升。例如在libreoffice_calculation上从
19.6%
34.8%
66.7%
94.4%
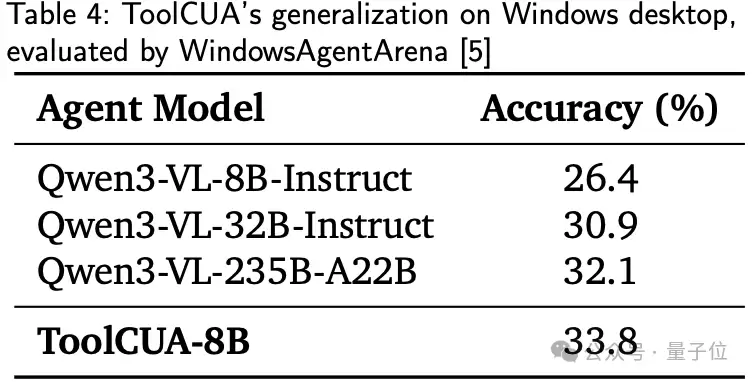
更进一步,ToolCUA还在WindowsAgentArena上进行了评测。
尽管训练数据和sandbox都来自Linux桌面环境,ToolCUA在unseen Windows desktop apps上达到了
33.8%
26.4%
30.9%
32.1%
这说明ToolCUA学到的并不只是某些特定任务模板,而是更接近一种可迁移的
hybrid action orchestration
为什么ToolCUA真正学会了选路
ToolCUA的提升究竟来自哪里?论文里的消融实验很清楚地给出了三条结论。
第一,如果没有interlea ved GUI-Tool trajectory data,online RL本身学不会可靠的tool use。
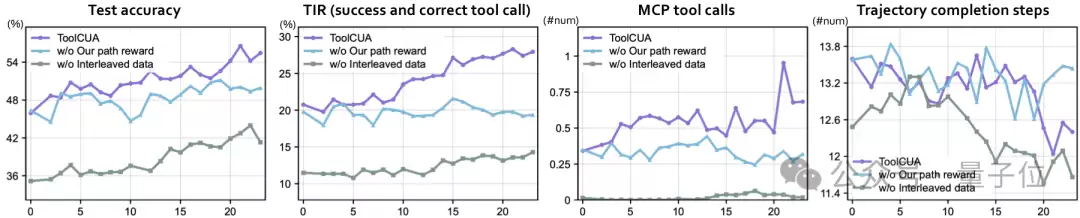
当去掉offline interlea ved GUI-Tool bootstrapping,直接从Qwen3-VL-8B-Instruct baseline开始做online agentic RL时,模型的overall accuracy虽然也会继续上升,但它很难真正学会稳定的工具调用行为。
最典型的现象是:TIR长期偏低,训练后期也只到约
15%
0
这说明,仅靠trajectory-level online reward,并不足以让一个GUI-centric base model自然生长出靠谱的hybrid switching能力。模型需要先通过interlea ved supervision获得工具知识和切换先验。
第二,如果没有Tool-Efficient Path Reward,模型学不会稳定且高效的路径。
同样在rl_dynamics里可以看到,去掉R_tool和R_length后,只保留标准的R_acc与R_fmt,accuracy曲线会明显更不稳定,在训练step
8-11
7个点
与此同时,TIR和tool-calls也没有稳定上升趋势,trajectory length也缺少持续下降。这说明,任务成功奖励本身不足以教会模型什么时候工具是合适的,以及什么路径才是真正高效的。
第三,Hybrid GUI-Tool training比pu re GUI training更有效。
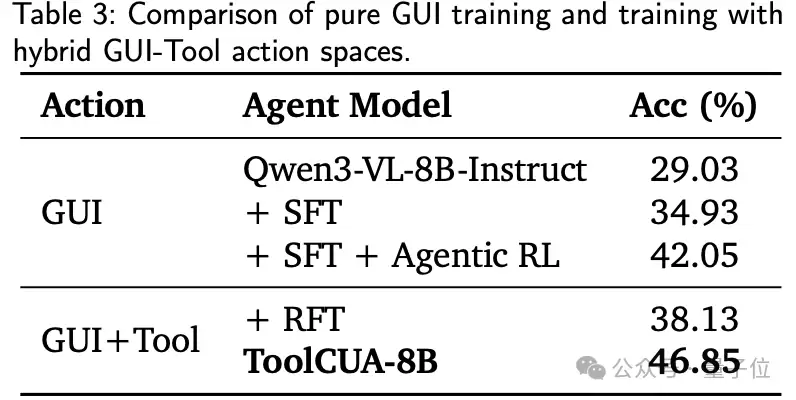
论文进一步比较了pu re GUI training和hybrid GUI-Tool training。
GUI-only pipeline从baseline
29.03%
34.93%
42.05%
38.13%
46.85%
这表明hybrid GUI-Tool action space本身就是一个更高保真的训练环境。模型不只是学visual grounding,也在这个过程中学会了何时应该用结构化工具替代冗余GUI操作。
WindowsAgentArena的结果也说明,这种训练范式带来的不是单点收益,而是更强的
跨平台泛化能力
真正的GUI-Tool协同
为了更直观地理解ToolCUA的能力,可以看两个实际案例。
第一个是LibreOffice Calc任务:要求在一个名为Sheet2的新sheet中创建两个pivot tables,分别统计product和sales channel对应的total revenue。
GUI-only方法通常需要选择数据范围、打开菜单、配置字段、确认参数,步骤冗长且容易出错。ToolCUA则先调用工具读取workbook信息和sheet内容,识别数据结构与字段位置,然后直接调用create_pivot_table生成透视表。
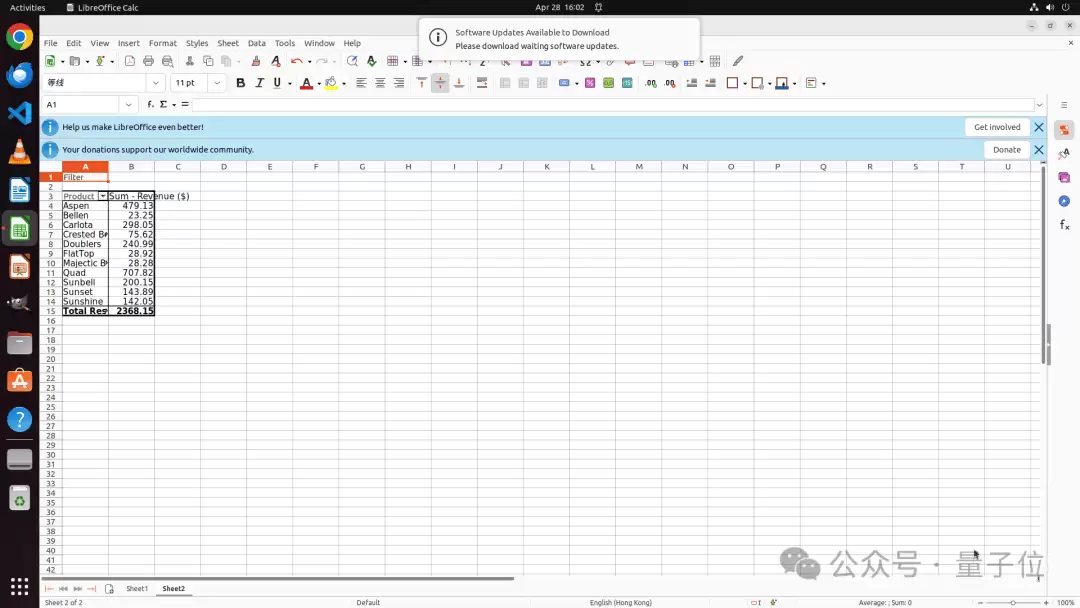
这个案例展示的不是工具永远比GUI好,而是:当任务核心是结构化表格操作时,Tool可以绕过脆弱的逐步GUI导航,用更确定的方式完成任务。
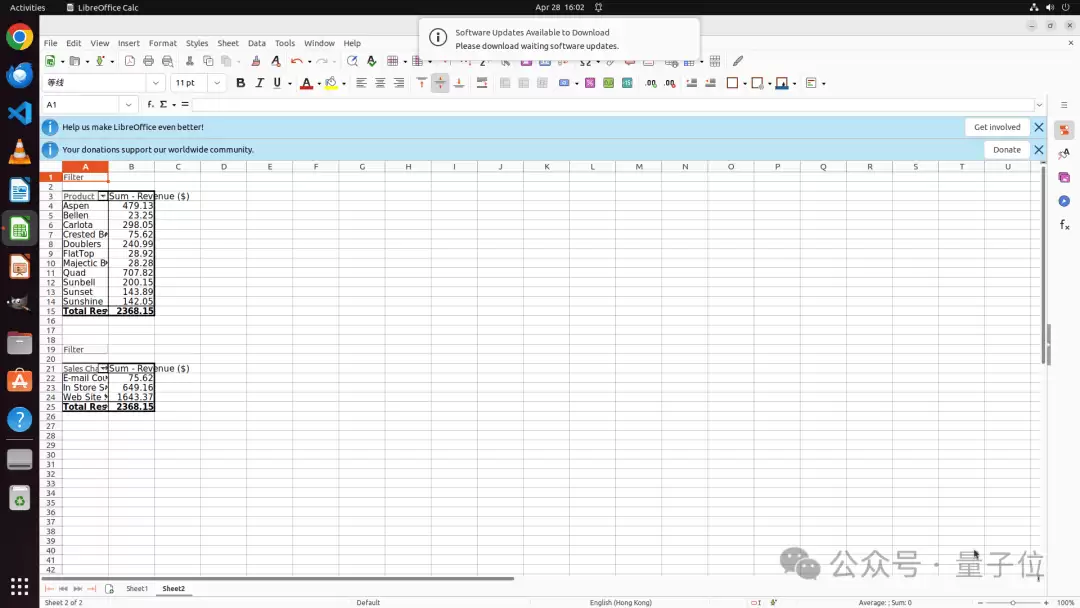
第二个案例来自VS Code。任务是将/home/user/data1和/home/user/data2两个文件夹加入当前workspace。
ToolCUA先连续调用add_folder工具,把两个目录加入VS Code workspace。这一步非常适合工具调用,因为路径明确、操作结构化、目标可验证。
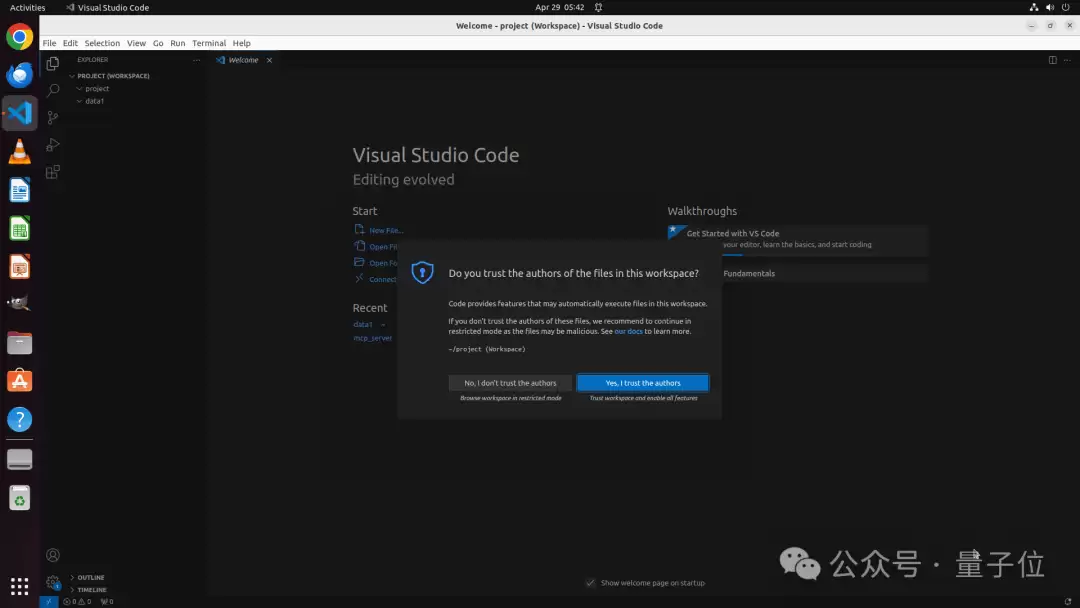
但工具调用完成后,VS Code弹出了"Do you trust the authors?"的信任确认对话框。这个状态不是简单tool call就能闭环的。此时ToolCUA切换回GUI action,点击"Yes, I trust the authors"。
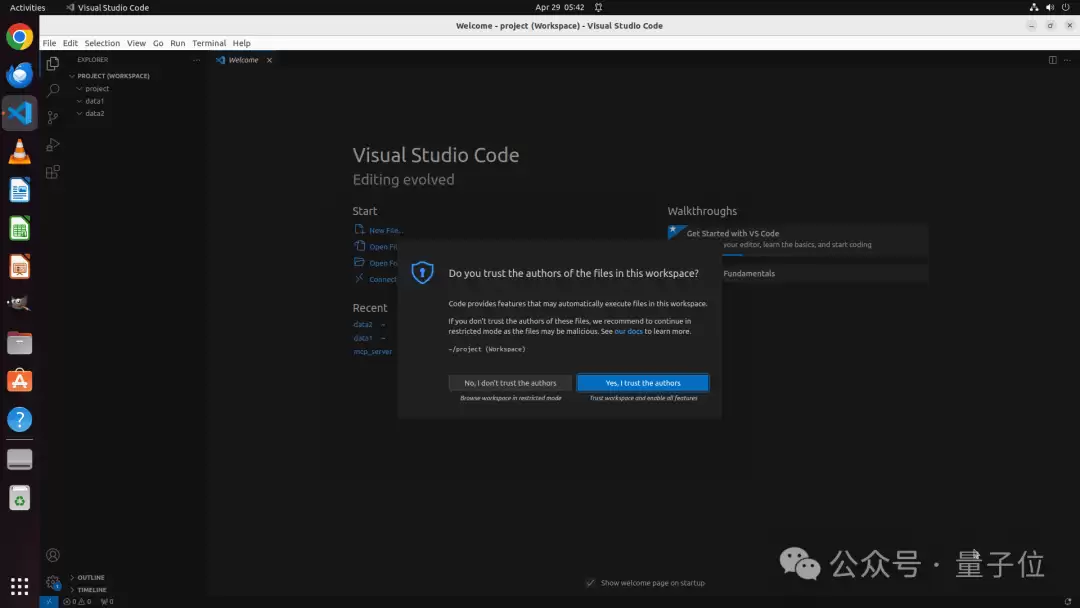
完成界面上的最后一步。
这正是ToolCUA想解决的问题:它不是试图用Tool替代所有GUI,也不是退回纯GUI操作,而是在真实环境里学习两种action space的
协同与切换
Hybrid action training,下一代CUA训练范式
在Agent热潮的推动下,Computer Use Agent正在更积极地探索真实世界里的落地路径。
ToolCUA为社区揭示了一个关键现象:一旦进入hybrid action space,现有CUA和部分强基座模型会出现明显的路径困惑,甚至导致准确率下降。
团队通过staged training paradigm在hybrid action training上做了一次有益探索,并验证了这一路线的有效性。
接下来,更值得持续推进的方向,是构建更大规模的CUA工具,训练更大规模的CUA基座模型,让CUA原生具有hybrid actions的能力,更好地解决人类的复杂问题。
-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
免费影视剧APP推荐
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
3 4S店和外面汽修店补漆有什么不同 06-01
-
4 如何辨别车尾钣金修复是否到位? 06-01
-
6 Codeium把脚本改成可配置版本提示词怎么控制篇幅和格式 06-01
-
7 光影魔术手如何压缩照片 06-01
-
10 小米YU7标准版交付即搭载XLA认知大模型,实测续航达成率97.4% 06-01



