GSD 为什么 63.8K Star?从 24 到 75 个 CLI 模块的架构演进
来源:互联网 更新时间:2026-05-31 15:01
 GSD 框架架构演进信息图封面
GSD 框架架构演进信息图封面
你有没有过这样的体验?用 AI 编码助手写代码,前几轮对话质量还挺高,越往后越离谱——明明说了不要用 any,它照用不误;前边刚定义好的接口,后边就忘得一干二净。
这不是模型突然变笨了。这是上下文窗口被塞满后的必然结果。
GitHub 上有个项目,专门解决这件事。它叫 GSD(Get Shit Done),Star 数一度冲到 63.8K,Fork 4.3K,有 2,367 次提交。但今天不打算细数它有多少 Agent、多少命令——这些数字换个版本就过时了。更值得聊的是:它为什么能火?它的架构在演进过程中做对了什么?以及,它到底适合什么样的项目?
1. 为什么 63.8K Star?GSD 做对了什么
先说结论:GSD 踩中的不是某个技术风口,而是一个几乎所有 AI 编码用户都会遇到的痛点。
腾讯新闻上有一篇关于 GSD 的报道,里面有句话说得很到位:别再迷信 AI 能一口气把整个项目写完。先拆,拆小,拆清楚,再让它一段段做。
这就是 GSD 的核心设计哲学。它的官方定位是 meta-prompting 框架——不是替你写代码,而是在你和 AI 之间插一层结构化的上下文管理。这个框架支持 Claude Code、OpenCode、Gemini CLI、Kilo、Codex、Copilot、Cursor、Windsurf 等 15 种运行时,不绑定单一工具。
具体来说,它做对了三件事。
上下文原子化
GSD 把一个大项目拆成一个个子任务,每个子任务在独立的上下文窗口中执行。这意味着每个子任务都能获得约 200K token 的完整上下文空间,而不是和其他任务挤在一个不断膨胀的会话里。
CSDN 上有篇分析文章用了个术语叫“上下文原子化”——把臃肿的全局上下文拆成原子级别的独立单元,每个单元都在干净的环境里运行。
这解决了什么问题?一句话:context rot(上下文腐烂)。AI 编码会话越长,生成质量越差。CSDN 上有篇文章标题很直白:通过上下文原子化治理大模型代码生成的“注意力崩塌”。这不是偶尔发生的 bug,而是大模型上下文窗口有限性导致的结构性问题。不管模型参数量怎么涨,窗口大小总有上限。GSD 不是在治标,而是在架构层面绕开了这个问题。
Orchestrator-Agent 编排模式
拆完任务,还得有人协调。GSD 用的是 Orchestrator(编排器)加 Agent(执行器)的模式:Orchestrator 负责拆解任务和分配,每个 Agent 只负责自己那一小块。
这个模式的好处是职责隔离。每个 Agent 的上下文里只有和它相关的信息,不会被其他任务的上下文污染。Wa ve 机制还允许无依赖的任务并行执行——多文件复杂模块的生成速度,比单 Agent 串行快不少。
Spec-Driven Development(规范驱动开发)
GSD 强制要求先写规范(spec),再让 AI 按规范执行。这不是额外的文档负担,而是把开发者的意图显式化。当 AI 在一个新上下文中开始工作时,spec 就是它的“记忆”——它不需要从零理解项目,直接按照 spec 行事。
腾讯新闻那篇文章里还有一句说得很好:真正做项目时,问题往往不在于你会不会写一句漂亮的 prompt,而在于你有没有办法把开发流程收拾得足够清楚,让 AI 每次都处在一个相对干净、稳定的工作区里。
这三点加在一起,解释了为什么它能从一堆 SDD 框架里脱颖而出。不是因为它功能多,而是因为它精准地解决了一个高频痛点。
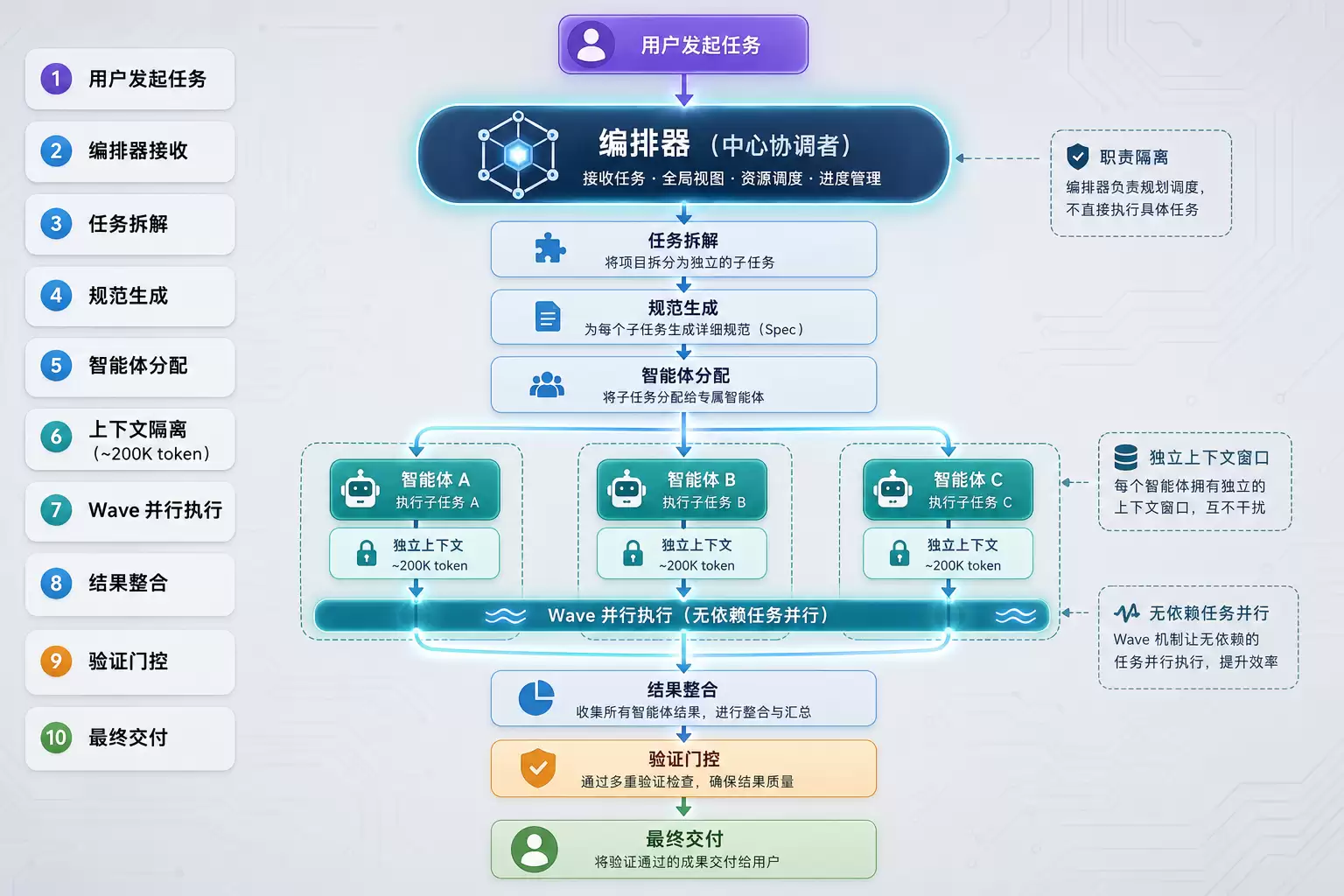 GSD Orchestrator-Agent 编排模式工作流程图
GSD Orchestrator-Agent 编排模式工作流程图
2. 新旧架构的技术演进
GSD 最近做了一次大规模的架构重构。旧版在 gsd-build/get-shit-done 仓库(npm 包名 get-shit-done-cc),新版迁移到了 open-gsd/get-shit-done-redux(npm 包名 @opengsd/get-shit-done-redux)。两个版本的核心设计理念一致,但工程化程度差异很大。
先看核心量化指标对比,数字来自两个仓库的源码分析:
| 组件 | 旧版 | Redux 版 | 变化 |
|---|---|---|---|
| CLI Modules | 24 | 75 | +51(3 倍增长) |
| Agents | 31 | 33 | +2 |
| Commands | 73 | 67 | -6(精简合并) |
| Workflows | 71 | 88 | +17 |
| References | 40 | 62 | +22 |
| Hooks | 9 | 13 | +4 |
| Tests | 190 | 548 | +358(近 3 倍) |
有几个变化值得单独拎出来说。
CLI 工具层:从 24 到 75 个模块
这是新旧版本差异最大的部分,也是最能体现工程化演进的地方。
旧版的 CLI 层有 24 个模块,覆盖基础的状态管理、配置、阶段操作。够用,但粒度较粗。
Redux 版膨胀到 75 个模块。新增的模块不是拍脑袋加的,每一类都对应具体的工程问题:
命令路由层。
gsd-workflow、gsd-project、gsd-quality、gsd-context、gsd-manage、gsd-ideate),每个命名空间内部有自己的路由表。展示 6 个路由器只需要约 120 tokens,每轮对话节省约 2,000 tokens。这个优化看起来不起眼,但在长对话场景下累积效果很可观。
安全审计。
secrets.cjs(秘密扫描)和 package-legitimacy-gate(npm 包合法性审计)。后者会在 research 和 planning 阶段自动检测推荐的 npm 包,用 sloplcheck 过滤低质量或恶意包。被标记 [SLOP] 的包直接移除,[SUS]/[ASSUMED] 标记的包需要人工确认,并在安装前注入 checkpoint:human-verify。
安装配置档案。
--profile=core 只装 6 个核心循环技能,--profile=standard 包含核心加阶段管理,默认完整安装。配置档案可组合:--profile=core,audit。旧版没有这个选项,始终全量安装。
上下文效率模块。
prompt-budget.cjs(提示词预算管理)、context-utilization.cjs(上下文利用率追踪)、surface.cjs(Skill surface 控制)。还引入了 /gsd:surface 命令,允许运行时动态启用/禁用技能集群,无需重新安装。
Workflow 大小预算
这是个有意思的设计。Redux 版引入了 workflow 文件的大小预算,由测试文件 workflow-size-budget.test.cjs 强制执行:
| 层级 | 行数上限 | 用途 |
|---|---|---|
| XL | 1700 行 | 顶级编排器(execute-phase、plan-phase、new-project) |
| LARGE | 1500 行 | 多步骤 planner 和大型 feature workflow |
| DEFAULT | 1000 行 | 聚焦的单用途 workflow |
超过预算的文件必须拆分子模块(拆到 workflows/ 或 templates/)。旧版没有这个约束。
背后的逻辑很直接:大文件 = 大 token 消耗。一个 3000 行的 workflow 文件被注入上下文时,会直接吃掉 3000 行的 token 预算。通过强制拆分,Redux 版在结构层面控制了上下文成本。
决策覆盖门控
Redux 版在 plan-phase 和 verify-work 中引入了双层门控:
plan-phase(BLOCKING):
verify-work(NON-BLOCKING):
旧版没有这个机制,Planner 可能静默忽略用户的决策偏好。这个特性在多人协作的场景下特别有用——它确保了项目中的关键决策不会被 AI 在执行过程中遗忘。
新增 Agent:文档质量进入工程视野
Redux 版新增了两个 Agent:gsd-doc-classifier(文档分类)和 gsd-doc-synthesizer(文档合成),对应新增的 docs-update workflow 增强。
这两个 Agent 反映了一个容易被忽略的工程问题:在 AI 辅助开发中,文档往往是产出物里质量滑坡最严重的部分。代码有测试兜底,文档却经常没人审。把文档分类和合成做成专门的 Agent,意味着 Redux 版试图把文档质量也纳入工程化管理,而不是当作附带的副产品。
测试从 190 到 548
测试覆盖近 3 倍增长,说明 Redux 版不是简单的代码迁移,而是做了大量的功能验证和边界测试。新增的 workflow-size-budget.test.cjs 就是典型例子——用测试来强制执行架构约束,而不是靠人工 code review。从这个角度看,Redux 版的工程纪律比旧版严了不少。
MCP Token 预算意识
Redux 版的架构文档里有一组常被忽略的数据:重量级 MCP 服务器(如 browser/playwright)每个可能消耗 20K tokens/轮。如果同时启用多个 MCP 服务器,光 MCP 的 token 开销就能吃掉上下文预算的一大块。
这解释了为什么两阶段路由不只是“代码整洁”的问题,而是直接影响成本。当你只展示 6 个命名空间而不是 86 个平铺技能时,省下来的不只是展示开销,还有后续调用中 MCP 服务器的触发次数。架构决策和 token 经济学是绑定的,这是 Redux 版在设计上比旧版成熟的地方。
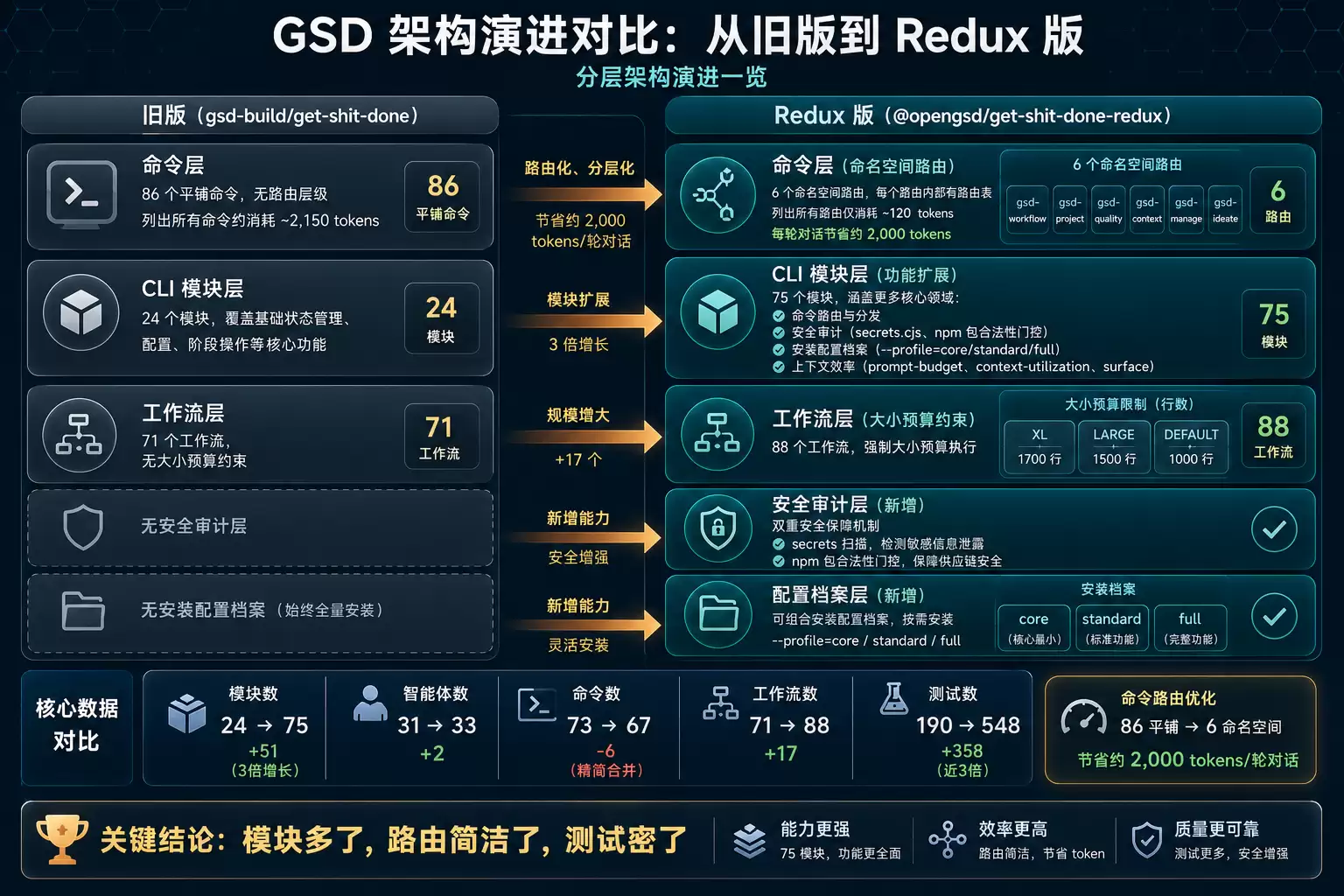 新旧版本 CLI 模块分层架构对比图
新旧版本 CLI 模块分层架构对比图
3. 项目迁移的工程视角
GSD 从旧版迁移到 Redux 版,Star 数从 63.8K 归零。这是 GitHub 平台的设计——Star 与仓库绑定,仓库迁移不会继承。
但比 Star 数更重要的是:为什么要迁移?
根据 Redux 版 README 的公开声明,迁移的直接原因是 trust and ownership concerns,涉及旧版生态中的一个 meme-coin 事件。从工程视角看,这件事的本质是一个开源项目的治理危机。
旧版的问题:README 里包含 $GSD Token 的 Dexscreener 链接(Solana 链上的 memecoin)。一个面向开发者的工程工具,和一个投机性质的加密货币绑定在一起,这在信任层面是个严重的信号。不管技术上有没有问题,用户会怀疑:这个项目到底是为开发者服务的,还是为 token 服务的?
Redux 版的应对很工程化:
- 移除了所有加密货币相关内容
SECURITY.md从 940 字节扩展到 5,292 字节- 新增独立的
docs/security/目录和审计透明度报告 - 引入
package-legitimacy-gate在安装环节做安全检查 - 维护者从个人(TÂCHES)变为社区团队(open-gsd)
说白了,这是一次用工程手段重建信任的操作。Star 归零不可怕,可怕的是项目被信任问题拖垮。Redux 版选择从安全性、透明度、社区治理三个维度同时发力,这个决策从长远看是理性的。
但也要客观说:社区对 Redux 版的反响目前还不够强烈。GitHub Discussions 上关于旧版的讨论远多于新版,Reddit 和 Hacker News 上也没找到 Redux 版的独立讨论帖。日文社区的 Qiita 文章和中文社区的 CSDN 博客,讨论的也多是旧版。迁移是否能成功重建社区,还需要时间验证。
话说回来,开源项目因为治理问题 fork 或迁移,在 GitHub 历史上并不少见。Node.js → io.js → 回归 Node.js,Jenkins → Hudson,都是类似的故事。GSD 的迁移能不能成功,取决于 Redux 版能不能在技术上持续证明自己——而目前的架构数据(548 个测试、75 个 CLI 模块、完善的审计体系)至少说明,方向是对的。
4. 什么场景选 GSD?实战建议
社区对 GSD 的评价两极分化。正面评价集中在上下文隔离和并行执行确实解决了实际问题;负面评价主要集中在学习曲线陡、Token 消耗大、规划深度不够。
基于调研数据和竞品对比,建议按项目规模和团队阶段来选。
适合用 GSD 的场景
中型以上项目,多文件协同开发。
已有成熟开发流程的团队。
同时使用多个 AI 编码工具。
不太适合的场景
小型项目或快速原型。
--profile=core 模式可以在一定程度上缓解这个问题,但学习成本依然存在。
需要深度需求分析和多角色协作。
Token 预算敏感。
兼容性要求高。
和其他框架的关系
根据社区的多篇横评,目前的 SDD 框架格局大致是这样:
| 框架 | 核心定位 | 适合场景 |
|---|---|---|
| GSD | 上下文工程 + 并行执行 | 中型项目、多文件协同 |
| Superpowers | 严格自动化 SDD + TDD | 代码质量优先的团队 |
| BMAD | 企业级敏捷开发 + 多角色 | 大型企业、深度规划 |
| OpenSpec | 轻量级快速迭代 | 中小型项目 |
| SpecKit | GitHub 官方端到端 SDD | 中大型、合规项目 |
流水理鱼的一篇横评里有个挺实用的总结:想要多快好省 → 用 GSD;追求代码质量 → 用 Superpowers。
更有意思的是,两者其实可以互补。理论上可以用 GSD 管理项目整体拆解(解决“怎么拆”的问题),用 Superpowers 的 TDD 技能处理每个子任务的执行质量(解决“怎么做”的问题)。Qiita 上的日文指南也提到了这种组合的可能性。这种搭配在大型项目里可能会产生不错的效果。
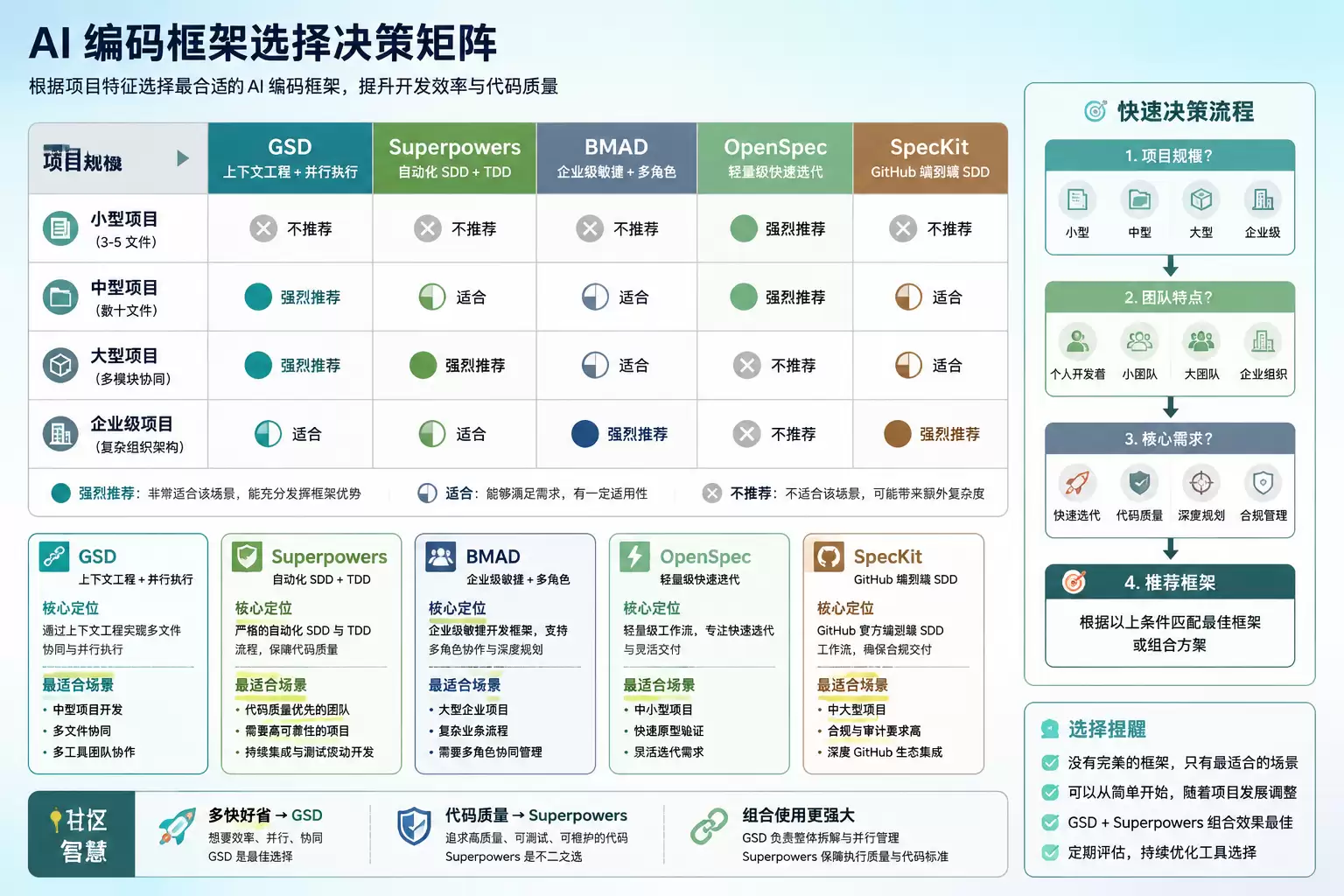 框架选择决策矩阵图
框架选择决策矩阵图
你在项目中用过类似的 AI 编码框架吗?更倾向于哪种方案?欢迎在评论区聊聊。
总结
GSD 的核心价值,不在于它有多少 Agent 或命令,而在于它提出了一套工程化的上下文管理方案。把 AI 编码中“上下文腐烂”这个模糊的体验问题,拆解成了可管理的架构问题——上下文原子化、Orchestrator-Agent 编排、Workflow 预算控制。
Redux 版的架构重构进一步强化了这个方向:CLI 模块从 24 增长到 75,每一类新增模块都对应具体的工程问题(路由效率、安全审计、迁移管理);命令从 73 精简到 67,靠的是合并冗余而非砍功能;测试从 190 增长到 548,用测试来强制执行架构约束。
有一组数字能概括这次重构的本质:旧版 24 个 CLI 模块、190 个测试、86 个平铺命令;Redux 版 75 个 CLI 模块、548 个测试、6 个命名空间路由。模块多了,路由简洁了,测试密了。这不是简单的代码膨胀,而是在可控复杂度和工程纪律之间找到了一个更好的平衡点。
但 GSD 不是银弹。它的学习成本和 Token 消耗是真实存在的 trade-off。选不选用,取决于项目规模和团队状态。如果正在为“AI 写着写着就变傻了”这个问题苦恼,值得试试。如果项目本身就很小,可能还没遇到这个问题。
关于 GSD,最想了解的是什么?是具体的安装配置,还是和某个竞品的深入对比?留言告诉我。
相关资源
GSD 旧版仓库:https://github.com/gsd-build/get-shit-done
GSD Redux 版仓库:https://github.com/open-gsd/get-shit-done-redux
GSD 中文社区版(v1.22.0):https://github.com/lisitan/gsd-chinese
-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
免费影视剧APP推荐
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
好用的手环阅读app下载安装
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
1 诺基亚发布200 4G微聊手机,支持微信小程序互联,售价199元 05-31
-
2 台积电回应芯片技术路线:能源效率成未来关键,黄仁勋称领先优势稳固 05-31
-
3 摩托车转速线损坏了会有什么表现 05-31
-
4 踏板式摩托车改装通常包括哪些常见项目 05-31
-
5 喜之郎夏日奇冰脆脆冰促销:34根到手价14.8元 05-31
-
6 黄仁勋员工大会幽默互动,跨界联姻引发全场欢笑 05-31
-
7 小米YU7 GT首批车主交付仪式举行,车厘子红配色最受欢迎 05-31
-
8 我国首个血管芯片国家标准获批 将于2027年5月起正式实施 05-31
-
9 问界M9搭载华为800V高压平台,续航与能效实现显著提升 05-31
-
10 顶尖科学家携团队全职回国,助力半导体核心材料研发 05-31



