RAG混合检索:掌握倒数秩融合RRF多维度提升检索结果评分的秘诀
来源:互联网 更新时间:2026-05-30 10:50
在RAG(检索增强生成)搜索中,当你同时执行两个或更多查询时,就会遇到一个经典问题:每个查询都会产出一份独立的排名结果集,怎么把它们整合成一个既能体现各自优势、又足够靠谱的最终答案呢?这时候,
倒数排名融合(RRF)
简单来说,RRF是一种优雅的算法,它会逐一评估来自不同排名的搜索结果,然后把它们融合成一个统一的结果集。无论是混合搜索,还是并行执行的多个向量查询,RRF都是那个负责“一锤定音”的角色。
它的核心思想,就是利用“倒数排名”这个概念——也就是搜索结果列表中,第一个相关文档的排名的倒数。说白了,它就是看一个文档在各个列表里排得有多靠前,排得越靠前,它在最终结果里的分量就越重。
RRF算法详解
RRF算法详解
在聊RRF之前,先讲清楚一个核心背景:RAG系统的成败,很大程度上取决于检索阶段的表现。如果检索器没能找到相关文档,后面生成环节的精度就会直线下降,所谓的“幻觉”问题(模型生成不准确甚至荒谬的内容)也会随之增加。这是所有从业者都不愿看到的局面。
实际情况是,不同的查询往往需要不同的检索策略。有些查询,用基于关键字的检索(比如BM25)效果更好;另一些查询,则用依托语言模型嵌入的密集检索(dense retrieval)更准确。混合检索技术,就是为了取这两种方法之长,而RRF正是将各路检索模型的排名结果巧妙合并、输出统一排名的聚合利器。
RRF算法原理
RRF算法原理
RRF的工作原理,可以简单分成几个步骤来看:
- :用户输入一个查询。
用户查询
- :这个查询被同时发给多个检索器,这些检索器可能各自采用不同的模型,比如密集检索、稀疏检索或混合检索。
多重检索器
- :每个检索器各自独立地对相关文档进行排名。
独立排名
- :利用RRF公式,将所有独立排名结果合并起来。
RRF 融合
- :根据计算出的RRF分数,输出一个统一的文档排名。
生成最终排名
- :生成模型从排名最高的文档中提取信息,生成最终回答。
生成答案


RRF背后的数学直觉
RRF背后的数学直觉
RRF的公式看上去非常简单:
分数 = 1 / (rank + k)
- :公式的核心是给排名靠前的文档更大权重。这很符合直觉,毕竟排名第一的文档,其相关性比排名第二、第三的高出不少,权重理应更高。
排名第一的艺术
- :分数的贡献随着排名增大并非线性递减,而是呈非线性递减。这反映了另一个现实:排名第1和排名第2之间的相关性差异,通常远比排名第100和排名第101之间的差异要重要得多。
收益递减
- :通过对所有检索器的倒数排名求和,RRF能有效融合多方证据。这就好比让一群专家各自投票,再把这些票数加起来做判断——最终结果通常比任何一位专家的判断都更稳健、误差更小。
汇聚众智
- :常数k起到了平滑作用,防止任何一个检索器的排名结果对整个结果形成过度主导,同时也能更优雅地处理低排名项目的平局情况。
平滑因子k
k 值的选择
k 值的选择
在RRF的实际应用中,k=60是一个非常经典的默认值。这个数值为什么被广泛采用?背后有几点考量:
- :在各种数据集和检索任务中,k=60都表现出了令人满意的效果。
实证典范
- :它很好地在高排名项目和低排名项目的影响力之间找到了平衡点。
平衡的艺术
- :在低排名项目中,k=60能有效打破平局。
打破僵局
- :无论面对何种类型的检索系统和数据分布,这个值都表现出很强的鲁棒性。
稳定性强
当然,有一点必须强调:
虽然k=60是得力助手,但最优值永远取决于具体应用场景和数据特性。
RRF的应用
RRF的应用
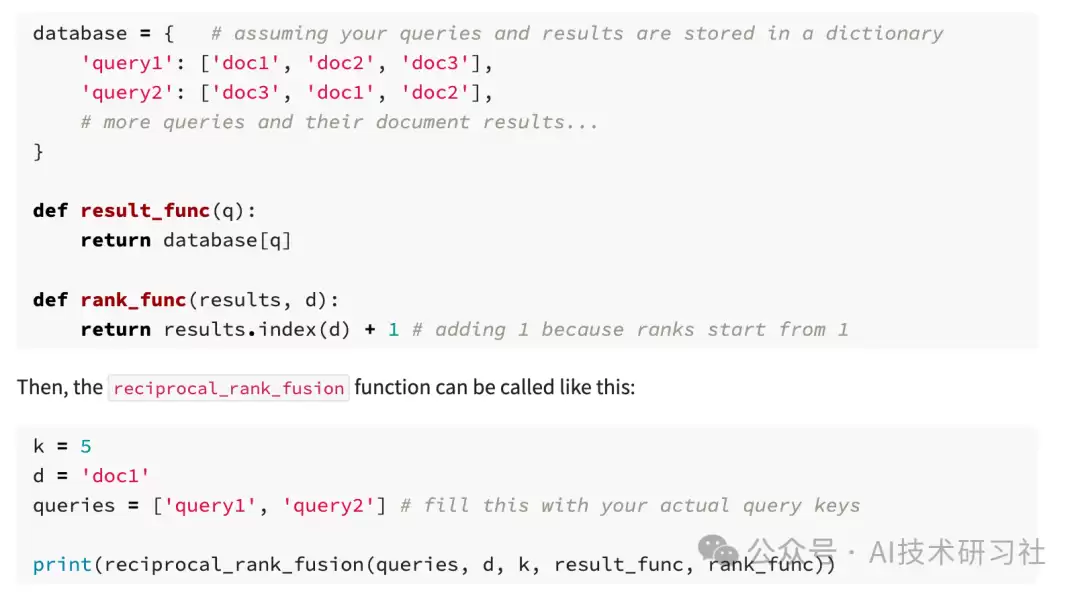
在实际的RAG系统里,RRF的代码实现思路很清晰:
score = 0.0
for q in queries: # 遍历发送到不同搜索引擎的查询
if d in result(q):
score += 1.0 / ( k + rank(result(q), d))
return score
# 其中
# k 是排名常数
# q 是查询集合中的某个查询
# d 是q结果集中的某个文档
# result(q) 是q的结果集
# rank(result(q), d) 是文档d在result(q)中的排名(从1开始)
如果用Python,甚至可以写成一行:
def reciprocal_rank_fusion(queries, d, k, result_func, rank_func):
return sum([1.0 / (k + rank_func(result_func(q), d)) if d in result_func(q) else 0 for q in queries])
结论
结论
RRF之所以在RAG系统中成为排名聚合的明星,在于它能以轻量级的数学手段,将多个检索器的优势充分结合,生成更稳健、更相关的统一文档排名。可以说,掌握RRF的原理和应用,就是掌握了提升RAG系统检索质量的一把关键钥匙。对于从业者而言,理解并优化这项技术,意味着能让自己的系统在面对复杂查询时,输出更准确、更可靠的结果。

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
无尽花界时装合辑
-
免费影视剧APP推荐
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
1 AI四巨头内部报告首度公开:AI正在学会撒谎求生 05-30
-
2 【西湖心辰大模型】西湖大模型 05-30
-
3 AvaloniaChat:一个基于大语言模型用于翻译的简单应用 05-30
-
5 润建股份与环江县人民政府达成战略合作,AI赋能县域新发展! 05-30
-
6 大模型应用,独立APP和内嵌AI,谁会胜出? 05-30
-
7 非结构化数据解析 &GenAI的应用探索和实践(文字稿) 05-30
-
8 AI提问万能公式,可极大提升回复质量 05-30
-
9 五个AI落地叙事,拆解出一场“企业坦白局” 05-30
-
10 AI大模型龙头,启动A股IPO 05-30



