大模型面经——以医疗领域为例,整理RAG基础与实际应用中的痛点
来源:互联网 更新时间:2026-05-30 08:39
聊到大型语言模型在垂直领域的落地,RAG 几乎是一个绕不开的核心组件。从问题诊断到效果调优,涉及的环节相当多。这个系列就以医疗领域为例,把 RAG 相关的实用经验逐步拆解出来——既覆盖理论认知,也包含代码实践。本篇先聚焦理论知识与经验总结,后续会结合最新的优化方法给出详细的优化代码,以及在实践中衍生的思考。
下面是本篇的快速索引:
- RAG 思路
- RAG 中的 prompt 模板
- 检索架构设计
一、RAG 思路
先看一张经典的流程图,它基本概括了 RAG 的标准工作方式:
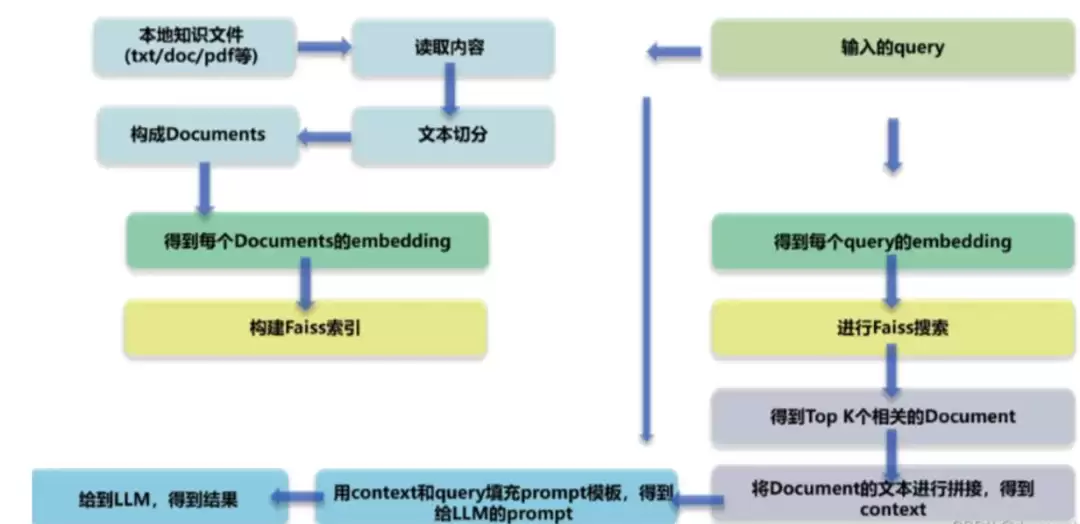
具体来说,整个流程可以拆解成这几个环节:
- 加载文件
- 读取文本
- 文本分割
- 文本向量化
- 问句向量化
- 在文本向量中匹配出与问句向量最相似的 top k 个
- 匹配出的文本作为上下文和问题一起添加到 prompt 中
- 提交给 LLM 生成回答
二、RAG 中的 prompt 模板
回到 prompt 设计本身,一个典型的模板长这样:
已知信息:{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}
这里的 {context} 就是检索出来的文档内容。
三、检索架构设计
基于 LLM 的文档对话架构,核心可以拆成两步:先检索,后推理。重心其实在前者——检索架构的设计(本质上是一个推荐系统),推理部分交给 LLM 处理就好,现有框架如 LangChain 已经做得很成熟了。
所以接下来重点聊聊检索架构。
1. 检索要求
一个好的检索系统,需要同时满足三个条件:
- 提高召回率
- 能减少无关信息
- 速度快
2. 检索逻辑
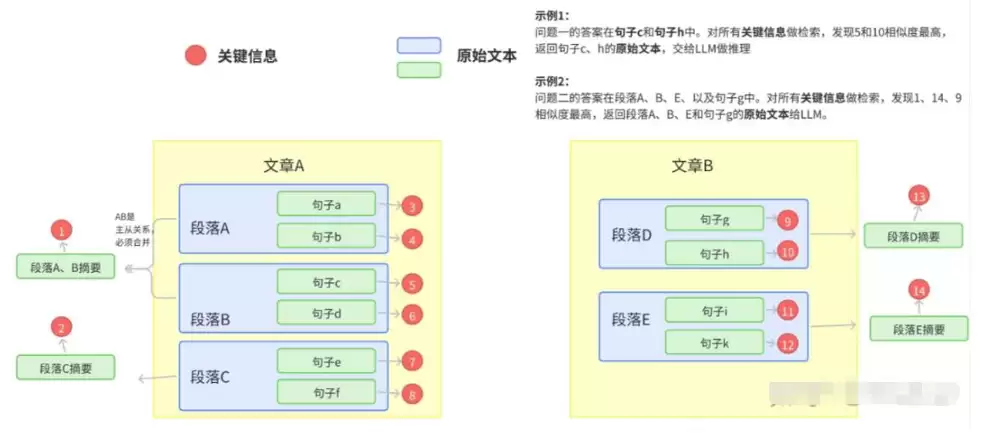
具体做法是:把需要建立检索库的文本组织成二级索引。第一级索引是「关键信息」,第二级是「原始文本」,两者一一映射。关键信息用于加速检索和参与向量相似度计算,原始文本则作为 context 返回给 prompt。
向量检索基于关键信息 embedding 进行相似度计算,检索命中后,再通过映射关系把对应的原始文本内容喂给 LLM。
3. 切分与关键信息抽取
关键信息抽取之前,先要解决文档切分的问题。切分的粒度是个老生常谈的难题——切得太细,跨段落的语义连贯性容易断裂;切得太粗,噪声又太多。因此比较稳妥的做法是按语义进行切分。
拿到文档后,先切分再抽取关键信息。具体是否需要进一步细化到文章、段落甚至句子级别,取决于实际场景。
下面展开讲讲方法和实践中的取舍:
1)切分
基于 NLP 篇章分析(discourse parsing)工具
提取出段落之间的主从关系,把所有存在主从关系的段落合并成一段,确保切分后的每个段落都在说同一件事。基于 BERT 的 NSP(next sentence prediction)训练任务
设定一个相似度阈值 t,从前往后依次判断相邻两个段落的相似度分数是否大于 t。大于则合并,否则断开。
2)关键信息抽取
直接存储以标点切分的句子
这个方法只适用于向量库足够小(检索效率高)且 query 也比较相似的情况,局限性比较大。传统 NLP 工具
成分句法分析(constituency parsing)可以提取核心部分,比如名词短语、动词短语;命名实体识别(NER)则能提取货币名、人名、企业名等重要实体。生成关键词模型
类似于 ChatLaw 中的 keyLLM 思路——训练一个专门生成关键词的模型。在医疗领域,这个方法目前来看是相对靠谱且泛化能力较强的方案。

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
无尽花界时装合辑
-
免费影视剧APP推荐
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
1 智能AI生成PPT,让创作更简单高效 05-30
-
2 AI生成视频PPT,你想象不到的创新力量! 05-30
-
3 WPS生成PPT,探索智能演示文稿制作的未来 05-30
-
4 国内AI技术进步,将表格处理提升到新高度 05-30
-
5 AI生成PPT教案,从机器的角度看智能演示助手 05-30
-
6 文档AI生成PPT,一键轻松打造专业展示 05-30
-
8 清华开源LongCite,如何提高大模型的溯源能力? 05-30
-
9 跟AI大模型实时语音通话解决方案 05-30
-
10 私域大模型建设记录(五) 05-30



