大模型RAG最佳实践指南
来源:互联网 更新时间:2026-05-30 07:54
今天分享一篇来自复旦大学的硬核研究。大模型时代的RAG技术已经锤炼了一年多,各种高级技巧层出不穷。但问题来了——到底哪些技巧真正有用?哪些搭配在一起效果最好?这篇论文给出了系统性的答案。
Searching for Best Practices in Retrieval-Augmented Generation
检索增强生成(RAG)已被证明能有效整合最新信息、减轻幻觉、提升响应质量,尤其在专业领域。尽管已有大量RAG方法通过查询检索来增强大语言模型,但它们仍面临实现复杂、响应时间长的问题。通常,RAG工作流涉及多个处理步骤,每个步骤都有多种执行方式。本研究系统梳理现有RAG方法及其潜在组合,以确定最佳实践。
研究覆盖了RAG的完整工作流:从用户查询分类、文档召回重排,到摘要生成,每个环节都尝试了不同方法。需要对比组合的核心策略一览如下: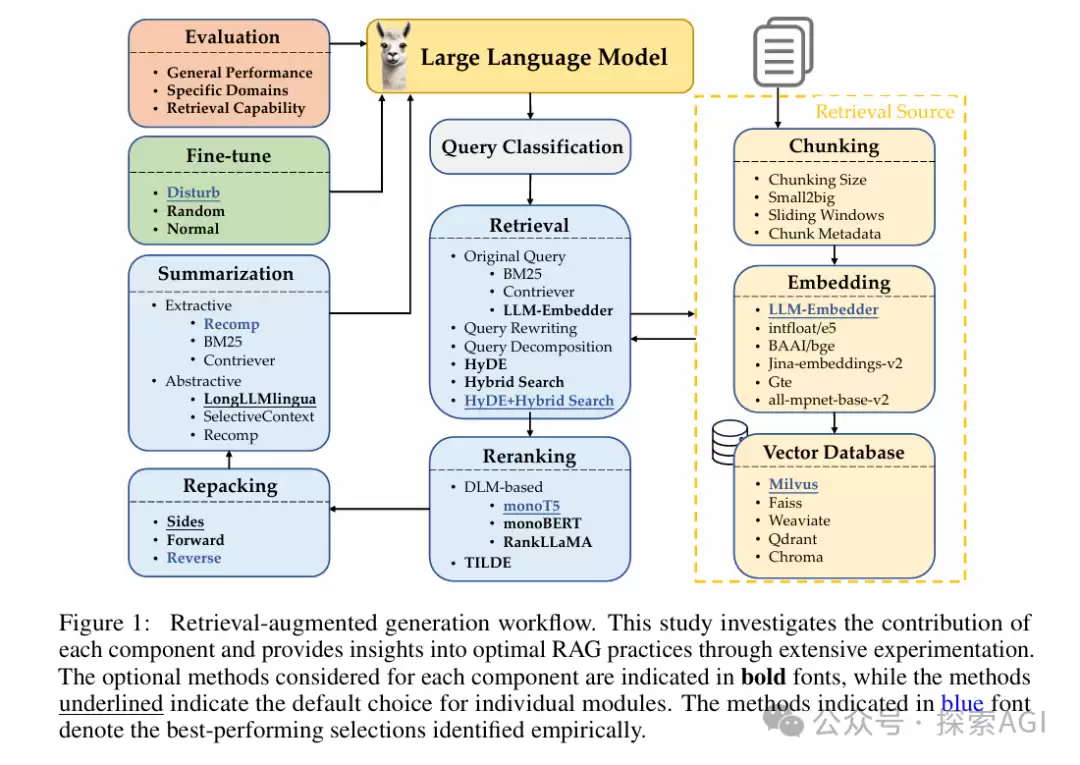
一个真实的问答系统,并非所有用户查询都需要外部知识。首先要解决的是查询归类问题——比如翻译、改写、推理这类信息充足的场景,根本不需要召回外部知识。下图展示了问题类别样例:黄色部分不需要RAG,橙色部分需要RAG。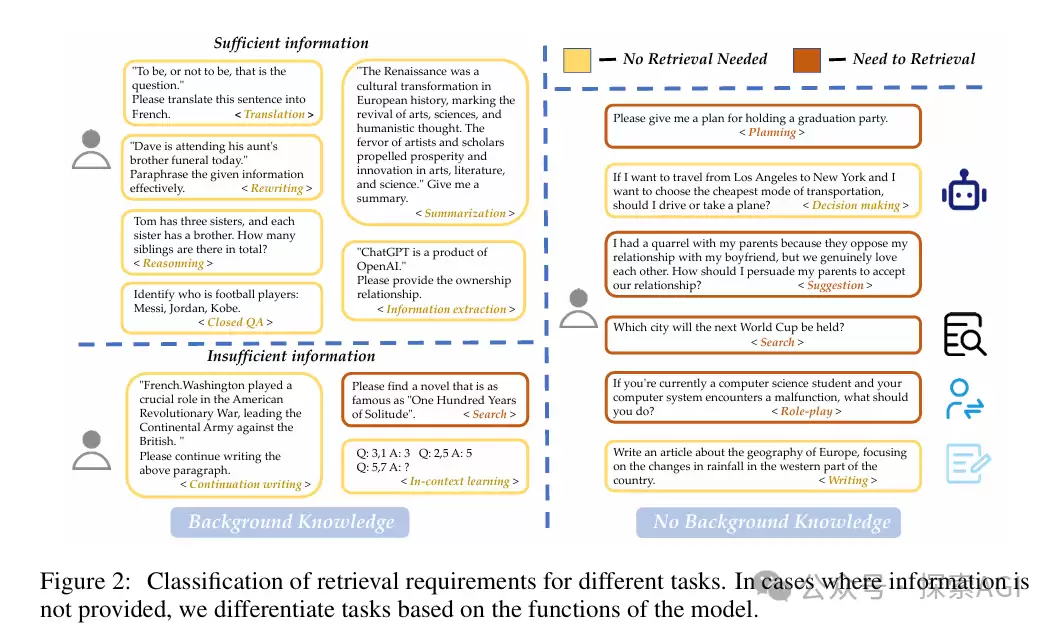
作者训练了一个二分类器来判断是否需要召回,结果相当乐观。
确定需要召回后,下一步是验证文档分块策略。评测涉及三个维度:块大小、分块策略、向量模型选择。
块大小的实验使用OpenAI Ada 002作为向量模型、GPT-3.5 Turbo作为生成模型。结果显示,块大小从128增加到512时收益递增;但更大的块(1024、2048)反而效果更差。
分块策略方面,small2big指用128的块做匹配,扩展到512的块用于生成;sliding window则设置20个token的重叠。结果发现sliding window相对更优。
向量模型选择的实验参考意义不大,因为这里是英文场景,结果如图。
向量数据库方面,作者推荐Milvus,支持多种索引、十亿级向量和混合搜索。
文档建立索引后,下一个大模块是怎么召回?
查询侧涉及三种策略:查询改写、查询分解为子问题、伪文档生成(HyDE)。测试表明,如果不考虑延迟,HyDE+混合搜索效果最佳;如果考虑延迟,混合搜索性价比最高。
选择HyDE后,还要考虑构造多少个伪文档。实测发现,伪文档数量越多增益越大,但延迟也会增加,需要在效果与效率之间权衡。
稠密向量的语义搜索与稀疏向量的文本级检索,两者相关性融合的权重alpha如何设定?实验发现,alpha=0.3左右(即稠密向量占比更大)时效果最优。
召回的最后一步是重排序对比。DLM(交互式二分类模型)、TILDE(基于语言模型概率验证)等方案中,交互式模型优势明显。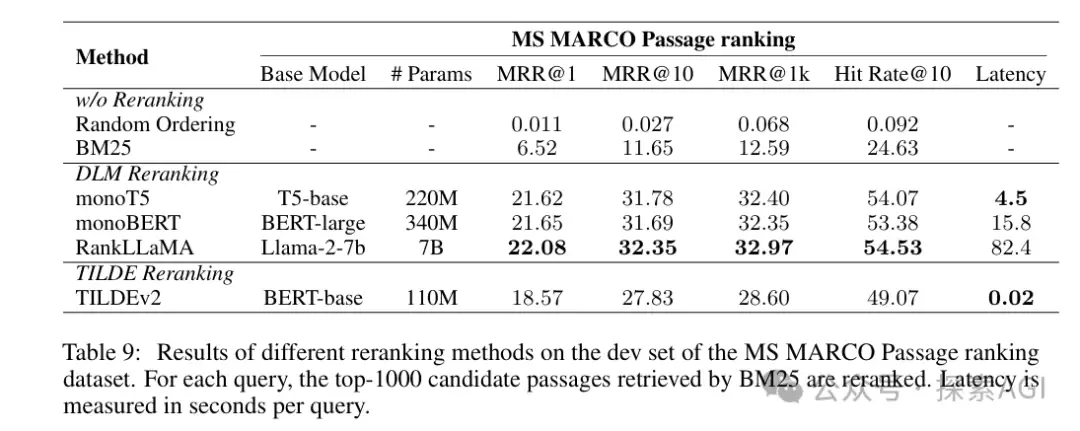
召回文档在prompt中的排序方式有三种:按相关性降序(forward)、升序(reverse)、头尾颠倒(slides)。结果出人意料——reverse竟然最好,是不是和直觉不太一样?
召回文档的摘要生成,大类分为抽取式和生成式,其中Recomp效果最佳,不过实际应用中可能用得较少。
最后是生成模型的微调。不同构造数据方式的结论是:在训练期间使用一些相关且随机选择的文档进行增强,效果最为优秀。
最后一张大表,清晰展示了最佳实践指南。前置分类器对降低延迟帮助明显;混合搜索+重排序是必备手段;其他如顺序调整、摘要生成等属于锦上添花,能带来正向提升,但并非核心。

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
无尽花界时装合辑
-
免费影视剧APP推荐
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
1 智能AI生成PPT,让创作更简单高效 05-30
-
2 AI生成视频PPT,你想象不到的创新力量! 05-30
-
3 WPS生成PPT,探索智能演示文稿制作的未来 05-30
-
4 国内AI技术进步,将表格处理提升到新高度 05-30
-
5 AI生成PPT教案,从机器的角度看智能演示助手 05-30
-
6 文档AI生成PPT,一键轻松打造专业展示 05-30
-
8 清华开源LongCite,如何提高大模型的溯源能力? 05-30
-
9 跟AI大模型实时语音通话解决方案 05-30
-
10 私域大模型建设记录(五) 05-30



