从技术层面聊聊英特尔Panther Lake为何非常值得期待
来源:互联网 更新时间:2025-10-15 23:31
此前,我们对英特尔Panther Lake处理器的架构以及核心IP设计做了比较全面的分析,了解了其在能效、性能方面的表现以及CPU、GPU、NPU、IPU等计算单元的新特性以及升级点。
不过在一些细节技术层面,如封装、分支预测、线程调度、电源管理、GPU/NPU计算单元技术细节等方面未进行深入探究,所以才有了这篇Panther Lake的“技术细节补完”内容。
作为Intel18A制程工艺打造的首款移动端处理器平台,Panther Lake汲取了上一代Lunar Lake的高能效和Arrow Lake的高性能优势,在CPU和GPU性能方面相较上一代产品均提升了50%,这样的性能进步在近年来的移动端处理器领域极为罕见,同时其在性能大幅提升的情况下,依旧保持出色的能效体验,可以说是展现出了Intel 18A制程工艺的核心优势。
Intel 18A制程工艺的核心优势来自于两大关键技术突破
那么肯定会有朋友存疑——Intel 18A制程工艺的核心优势到底是什么?
其实答案就是两大关键技术的突破:RibbonFET全环绕栅极晶体管技术以及PowerVia背面供电技术。
了解半导体芯片的朋友都知道,性能提升其实简单来说就是来自于晶体管密度的不断增加。但是对于芯片厂商来说,在提升晶体管密度的同时又要不断缩减芯片面积,这就造成了高制程节点下良率、供电/漏电、发热等层面的巨大挑战。
Intel 18A制程工艺之所以能够在1.8nm制程下通过晶体管密度提升提高性能的同时,还能够获得良好的能效表现,正是在确保良率的基础上,通过RibbonFET全环绕栅极晶体管技术以及PowerVia背面供电技术解决了供电、漏电、发热等棘手问题。
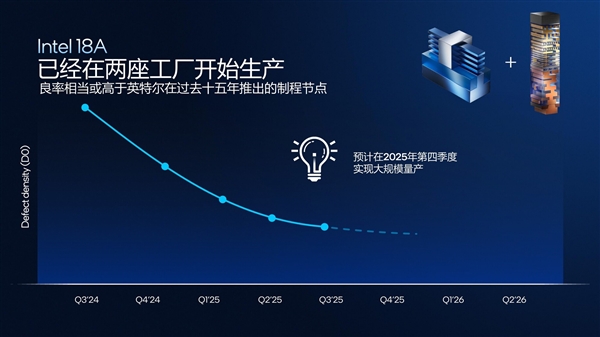
另外在10月初笔者受英特尔邀请前往美国亚利桑那州凤凰城参观英特尔Fab52晶圆厂时,已经看到有ASML光刻机正在量产Panther Lake芯片,这意味着其良率已经达到了正式投产的要求。而且Intel 18A现阶段的良率其实已经高于英特尔在过去十五年推出的制程节点。
回到两大关键技术,RibbonFET全环绕栅极晶体管实现了全环绕栅极(GAA)架构,
以垂直堆叠的带状沟道,提高晶体管的密度和能效,实现电流的精准控制,在实现晶体管进一步微缩的同时减少漏电问题发生。
通过下图可以看到,沿用多年的FinFET晶体管单个鳍片为三面通电,而RibbonFET全环绕栅极晶体管每一个鳍片实现了四面全包围通电,漏电率显著降低的同时,整个晶体管体积得到大幅缩减。

晶体管作为半导体芯片最为关键的元件,会直接对性能产生影响,积热造成的处理器频率下降是影响性能体验最为直观的因素。
而半导体芯片性能提升又与晶体管密度关系密切,不断缩小的芯片面积与不断增加的晶体管密度看似是一组矛盾因子,因此需要RibbonFET全环绕栅极晶体管这样的技术突破来冲破壁垒,确保更高晶体管密度下的性能释放不被电流和温度所影响。
PowerVia背面供电技术则是对芯片制造进行了全面革新,越来越多的使用场景都需要尺寸更小、密度更高、性能更强的晶体管来满足不断增长的算力需求,但混合信号线和电源一直以来都在“抢占”晶圆内的同一块空间,从而导致拥堵,并给晶体管进一步微缩增加了难度。
PowerVia背面供电技术通过将粗间距金属层和凸块移至芯片背面,并在每个标准单元中嵌入纳米级硅通孔 (nano-TSV),以提高供电效率。这项技术实现了ISO功耗效能最高提高4%,并提升标准单元利用率5%至10%。

得益于两大关键技术的突破,首个Intel 18A制程处理器Panther Lake真正实现了芯片性能、密度和能效的显著提升。
封装
制程技术突破,为Panther Lake打下了很好的基础,但想要真正发挥制程技术优势,少不了先进封装技术的支持。2023年9月,笔者受英特尔邀请参观了其位于马来西亚槟城的PG8、PG15、PG16三个封装厂区,以及位于居林(Kulim)的DSDP/SIMS工厂,全面了解了英特尔在2D和3D封装技术领域的硬核实力。
本次推出的Panther Lake可以说是英特尔先进封装技术的得意之作。
首先,英特尔通过EMIB-M 2.5D技术,帮助自家新一代处理器实现了关键性能突破:一方面缩小了Bump pitch(凸块)的间距,并且提升了Bump density,也就是密度,另一方面还显著的降低了芯片间C2C的功耗含量,增强了信号的完整性和效率。
同时,英特尔通过Foveros Direct 3D封装技术(Panther Lake使用到的是Foveros-S 3D封装),将以往的凸块直连改变为铜对铜的混合键合,其好处是带来了更高的密度、更低的延迟、更低功耗的互连,这也是未来大规模系统级集成的核心技术。
另外尤其是用在服务器方面,它可以为更大面积的芯片,更大规模的互连带来极大好处,比如与Panther Lake一同推出的288核小核的Clearwater Forest,也就是至强6+处理器上,这项封装技术实现了量产。

Panther Lake主要使用了Foveros-S 2.5D封装技术,各个功能模块和被动基础模块相连,充分发挥其在高密度、高能耗场景下的优势。
此前我们在Panther Lake技术解析文章中介绍了它的全新性能核以及能效核架构,本文不再赘述。下面我们从性能核和能效核的相关技术优化,来聊聊Panther Lake的性能为何会有50%的提升幅度。
性能核优化
首先我们来看看性能核的相关技术优化。
分支预测
其实除了核心架构之外,分支预测是现代处理器提升性能的核心技术指标之一。优秀的分支预测可以减少流水线停顿、优化指令预期和缓存命中,应对复杂控制流,并且可以对编译器与代码进行优化。

Panther Lake的分支预测并非推到重来,而是在前代Lunar Lake引入分支预测新算法的基础上,进行了深度迭代与优化,目的是让分支预测效率更高。同时Panther Lake的分支预测准确度也得到了进一步提升。
了解处理器技术的朋友都知道,分支预测的核心在于CPU预判程序执行路径中可能出现的分支,并提前做好准备。这包括预测分支的走向,以及能够多快地将预测结果反馈给CPU核心流水线。
在Panther Lake这一代的分支预测方面,相比Lunar Lake而言,首先在预测准确性上有了进一步提高,另外分支预测的延迟也大幅度缩短,这意味着CPU能够将更少的时间花费在预测和修正的开销上,而将更多的时间投入到真正有用的计算任务中,从而显著扩大有效计算时间的占比。
最终结果就会直接体现在用户能够直观感受到的CPU性能显著提升。
内存消歧
除了分支预测之外,在针对内存密集型负载时,Panther Lake的内存消歧技术也会对其性能体验的提升有明显的助力。
从传统层面来讲,CPU在处理内存读写操作时,往往需要严格遵循指令的顺序。例如,一个读取操作可能依赖于前一个写入操作的结果,或者多个操作指向同一内存地址时,必须按序执行。这种严格的依赖关系导致内存单元经常处于等待状态,使得内存带宽的利用率低下,无法充分发挥硬件潜力。
而内存消歧技术的核心在于,它能够智能地预测并打破这种表面依赖关系,允许CPU的多个执行单元进行乱序(Out-of-Order)或并行的内存读写操作,从而充分利用内存带宽。
当然,在实际代码中,真正的内存依赖关系依然存在。内存消歧技术的高明之处在于,它能精准预测哪些操作可以并行执行,哪些存在真实依赖。一旦预测错误或检测到实际冲突,它能以极快的速度进行恢复,以确保程序的正确性。
通过这种机制就能够显著提升CPU与内存之间的带宽利用率。这部分内存消歧在Cougar Cove上,相比前代Lion Cove做了更好的提升,消歧技术性能更可靠,细节更准,并且恢复更快。

TLB增强
此外,英特尔对Panther Lake进行TLB升级。TLB简单理解就是一种缓存,其本质上是CPU内部虚拟地址到物理地址的映射缓存。对于混合型工作负载,TLB至关重要。
它避免了CPU频繁访问系统内存进行耗时的页表遍历,而是将常用的地址映射预先存储,实现快速查找。这极大地加速了内存访问,显著提升了复杂场景下的性能。
这一次在Panther Lake里,英特尔实现了1.5倍的TLB容量提升,这一点得益于Intel 18A先进制程以及PowerVia这些关键技术,将TLB做到50%的容量扩容,对现代性的复杂性工作负载来说体验会更好。
另外,Panther Lake性能核其实还能够做到16.67MHz的精准时钟频率间隔,这意味着内部能够实现更精细的性能与能效调控,从而提供更快速的响应和更精确的核心性能与功耗管理。
能效核优化
与性能核一样,能效核的分支预测能力以及内存消歧也得到了相应增强,这里就不再赘述。
动态预取器控制
首先我们来聊聊动态预取器控制。
预取器的核心作用是预测CPU即将需要的数据和指令,并提前将其从内存加载到缓存中,以确保执行单元能够持续高效工作,避免因等待数据而产生的空闲。
而动态体现在,Panther Lake的预取器能够根据当前的工作负载类型和实时变化,智能地调整预取策略。这不仅能最大限度地保持执行单元的繁忙状态,提升性能,还能在某些场景下,通过优化预取行为,有效降低不必要的功耗。

Nanocode
Nanocode可以理解为比传统Microcode更底层的微操作指令。Microcode通常面向CPU的逻辑模块,定义了如何执行一条复杂指令。而Nanocode则将Microcode进一步分解,直接面向前端的硬件执行小单元,例如一个独立的加法器或加载单元。这种更细粒度的控制,使得Panther Lake能够更精准、更灵活地调度硬件资源。
举例来说,当某个执行单元因Microcode的粗粒度定义而无法充分利用时,Nanocode能够打破这种限制,将任务的细小部分分配给当前空闲的硬件单元。通过这种方式,Panther Lake大幅提高了硬件资源的利用率,进而显著提升了整体性能并降低了CPU的执行延迟。
另外相比前代Arrow Lake平台来说,Panther Lake的Nanocode可以覆盖的应用场景更多。以前可能只针对某几种类型的负载,但是在Panther Lake更加丰富,这意味着在更多应用场景下,Panther Lake能够充分释放能效核的性能与低功耗优势。
GPU部分
作为移动端平台来说,Panther Lake的iGPU部分也是相当令人期待,毕竟Lunar Lake的锐炫140V/130V核显带来了极其惊艳的图形性能表现,甚至让轻薄本、商务本都具备了1080p分辨率、中低画质下运行3A游戏的能力,这一变化彻底改变了轻薄本、商务本的应用方式。
而Panther Lake的GPU采用了全新的Xe3架构,新增支持了多帧生成技术,核心规模也得到大幅度拓展,所以明年Panther Lake产品上市之后,图形性能应该会给大家带来极其惊喜的表现。
下面咱们看看为什么我们会如此期待Panther Lake的iGPU的表现。
这次Panther Lake的iGPU优化主要是扩展性层面的提升,这使其核心实现了更大的规模。单个渲染切片最多包含的Xe核心达到了6个,顶配型号拥有12个Xe核心,这种核心规模的升级对于GPU而言就是最直接的性能提升手段。
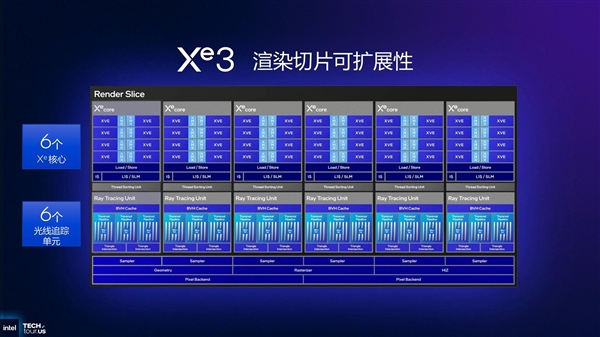
同时,Panther Lake把GPU模块从计算模块中分离出来,所以核心规模的配比上相比以往会更加灵活。首发有4核和12核,后续随着型号的丰富,其实Xe核心的数量会非常灵活。不像以往设计在计算模块中无法更改。

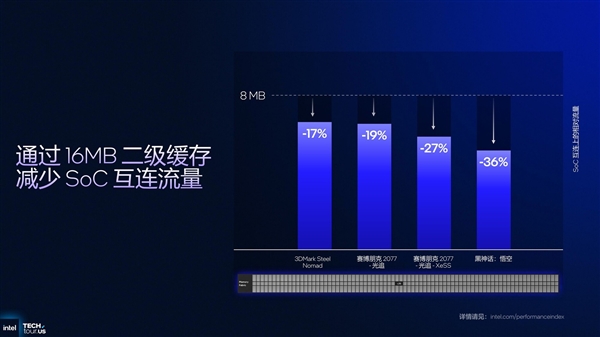
同时,12核心GPU还提供了更大的二级缓存容量,由此前的8MB提升到16MB,更大的L2缓存可以减少约17%到36%的对主内存的访问次数,通过更低频次的内存访问,提供更流畅的体验。
核心规模拓展加上L2缓存扩容之外,关键计算单元的性能优化也是Panther Lake iGPU体验提升的关键一环。这里包含了第三代Xe核心、更强的光追单元、更好的矢量引擎以及更出色的图形专用硬件管线。
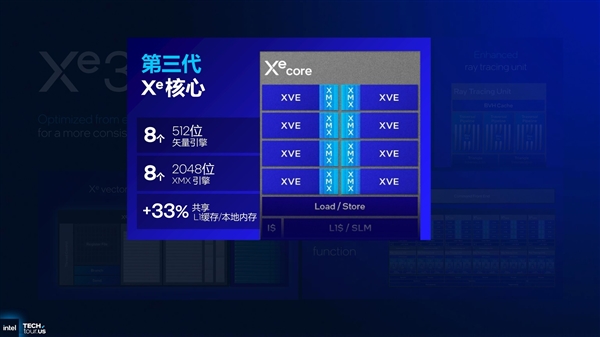
在Xe3核心中,提供了8个512位矢量引擎和8个2048位XMX引擎,并且将L1缓存增加了三分之一,赋予了Xe核心更强大的性能。
在Xe矢量引擎中,线程数增加了25%,还添加了可变寄存器分配。通过增加线程数和可变寄存器分配,英特尔有效提升了Xe矢量引擎的使用效率,使得相同的硬件能够支持更多、更快的负载。同时,Panther Lake的iGPU支持原生FP8反量化,以及SIMD16原生ALU、三路并发、扩展数据指令集与FP64,并支持Xe矩阵扩展。

此外,这一代iGPU在AI算力方面直接提升到了120TOPS,巨大幅度的提升来自于XMX AI加速引擎。其每个时钟周期可执行1024个XMX TF32操作,支持2048个XMX FP16/BF16运算,4096个XMX INT8运算和8192个XMX INT4/INT2运算,这些都比上一代有了显著提升。

在光追单元方面,这一代开始支持异步光线追踪的动态光线管理。其实在光线追踪中最具挑战性的是管理大量光线,当光线过多导致硬件单元无法及时处理时就会发生拥塞。此时,GPU就需要一个更优的调度机制,能在拥塞即将到来时降低光线分发频率,这自然需要高效的调度器设计。Xe3支持下一代异步光线追踪的动态光线管理,可大幅提升光线追踪负载下的性能。

GPU性能升级的另一大关键优化就是固定功能管线。其核心是英特尔为Panther Lake的GPU带来了全新的URB管理器。
URB是一个存储单元,用于GPU内部子单元之间的数据转换和传输。在以往的URB设计中,即使只传输少量数据,也需要对整个URB进行同步,效率自然会比较低下。新的URB管理器设计允许对部分URB进行传输同步,最高可支持2倍的异向性过滤,并使模板测试速率最高提升2倍。
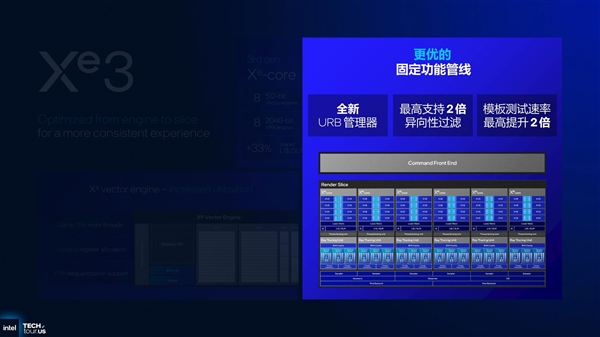
基于上述升级,Panther Lake的Xe3核显性能非常让人期待。
在CPU与GPU性能大幅提升的同时,Panther Lake在NPU、IPU、内存性能、无线连接能力等方面也有着极大程度的升级。而基于这些升级,英特尔也有意推动PC行业伙伴去打造支持高效AI智能体的全新业态PC产品。
通过强力的硬件以及丰富的软件栈,构建本地AI智能体,让电脑变得更加智能化,用户只需要一条或几条指令,就可以自动调用各类软件完成复杂工作流,这可以说是非常领先的一种未来PC发展理念。
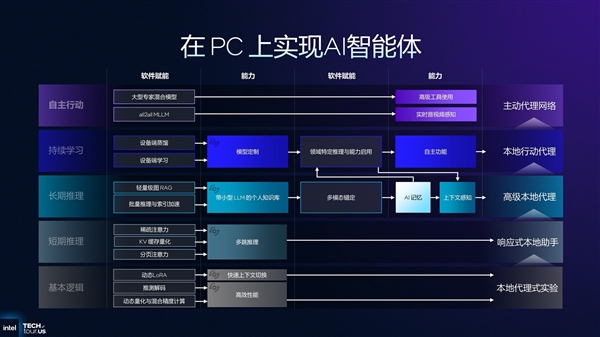
总体来说,Panther Lake作为Intel 18A制程工艺的首个处理器平台,其整体表现相当值得期待。根据官方消息来看,预计明年1月份的拉斯维加斯CES上就会有搭载Panther Lake的新品亮相。
笔者最近也接到了一些PC厂商的CES参展邀请,如果能够成行的话,我会给大家在CES前方带回第一手的Panther Lake新品报道。
-
抖音月付功能在哪里开通?月付功能开好还是不开好?
-
抖音双号开播是不是容易封号?怎么多个账号直播?
-
全民k歌大神都是怎么调音 全民k歌调音方法
-
世界已知最古老!东南亚惊现1.2万年前木乃伊
-
微信视频号可以实名认证几个账号?实名认证如何注销?
-
现代战舰055驱逐舰怎么玩
-
牧场物语风之繁华集市全村民生日喜好一览
-
《地下城堡4:骑士与破碎编年史》地歌石脉藏品收集攻略
-
燕云金瓯碎片五色琉璃
-
崩坏星穹铁道星迹重温是什么
-
爱奇艺如何投屏到奇异果 爱奇艺投屏到奇异果方法介绍
-
梦幻西游化生寺帮战装备175级展示图
-
抖音第一个作品发布时间多少合适?怎么发布自己的作品?
-
原神5.6新卡池预测
-
《无主之地4》改版武器与装备现于eBay平台销售
-
空洞骑士丝之歌噬丝蛆怎么拿
-
蚂蚁庄园小课堂今日最新答案2025年9月30日
-
燕云十六声官服好玩还是渠道服好玩
-
安徽师范大学给学生发150元过节费 学生:感觉被狠狠宠爱了
-
王者荣耀排位系统优化来袭
-
3 全美第一个量产2nm的 Intel芯片要再次伟大:至少增长3倍 10-09
-
6 当EUV光刻机近在眼前!Intel亚利桑那州晶圆厂行记 10-10
-
8 Intel重申支持开源社区 但不能再让友商获得好处 10-10



