英伟达杀疯了!DeepSeek V4推理成本狂砍80%
来源:互联网 更新时间:2026-07-02 16:09
7月2日消息,
英伟达宣布其Blackwell平台通过全栈推理软件优化,DeepSeek V4模型的单Token成本在一个月内最多降至五分之一。
随着企业从AI试点走向生产型AI工厂,基础设施决策已从芯片规格峰值转向每元、每瓦特及延迟目标内能交付多少有用Token。
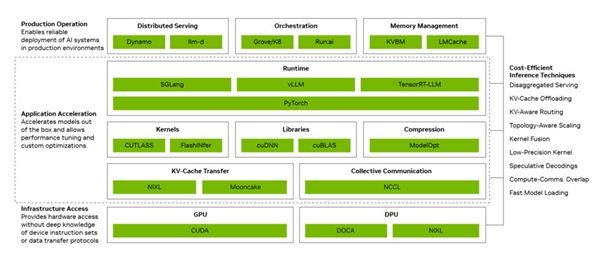
英伟达通过三层架构实现Token成本的大幅下降。生产运营层负责分布式服务编排与自动扩缩容,应用加速层通过计算通信重叠和内核融合进行运行时优化,基础设施访问层则直接调用GPU、网络与系统能力。
多项技术叠加后,Blackwell平台单GPU的Token吞吐量最高可提升20倍。
英伟达将单Token成本列为AI总拥有成本的核心指标,
Blackwell平台已将其降至行业最低水平。
多家推理服务商已从中获益。
Baseten利用TensorRT-LLM开源库在Blackwell上服务DeepSeek V4 Pro,每秒Token输出量提升高达50%。
Cognition借助Dynamo推理框架管理GPU,无需从零构建即可扩展强化学习工作负载。Together AI用TensorRT-LLM帮助Cursor加速从模型优化到生产终端的路径。
开源生态进一步放大了全栈优势。PyTorch等主流框架原生基于CUDA构建,使新研究成果能立即在NVIDIA GPU上运行。
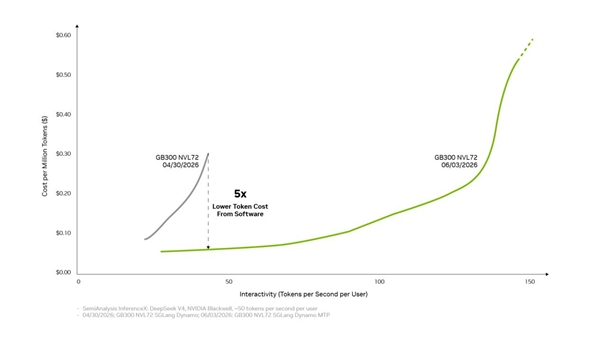
DeepSeek V4发布后,vLLM和SGLang等框架随即为Blackwell提供部署方案,一个月内性能提升高达5倍。

-
archiveofourown 实战指南:常见用法整理
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
电视剧《小欢喜》剧情介绍
-
俄罗斯最大yandex入口外贸日报直达链接
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
美好的简约网名男生(精选100个)
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
腾讯元宝怎么用来分析股票基金的基本面信息?
-
盖乐世社区怎么删除帖子?盖乐世社区个人发布内容撤回步骤
-
二次元男生网名可爱(精选100个)
-
问题:CIA币好不?Cia Protocol币今日上线:价格预测、代币经济学和未来潜力
-
wallpaper壁纸声音怎么开启
-
免费观看国外短视频的app有哪些 观看国外短视频的软件下载
-
国际贵金属走低,现货黄金价格跌0.49%
-
新浪人工智能热点小时报丨2026年06月20日02时_今日实时人工智能热点速递
-
独家/李宰旭入伍前「登上孤岛服役」 惊见前辈裸体:忍不住笑了
-
动漫《无赖勇者的鬼畜美学》剧情介绍
-
短剧《嫡女她是山大王》剧情介绍
-
AO3网址链接入口 教程:从入门到实际使用
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
2 DeepSeek终于要融资了?而五家国产大模型都找到了赚钱的路 07-01
-
3 百万年薪不是梦!英伟达在华狂招机器人工程师 07-01
-
6 4000亿DeepSeek,如何花掉融来的500亿? 07-02
-
7 估值超百亿美元:国产大模型黑马DeepSeek开启首轮外部融资 07-02
-
8 真核动力AI!英伟达Blackwell芯片成功用上反应堆供电 07-02
-
9 GPU技术冲击5G基站芯片市场,英伟达联盟获超130家企业支持 07-02
-
10 英伟达扶持新兴云服务商:助力小型AI初创公司租赁GPU 07-02



