NL2SQL 的四条主路线,一定是谁优谁劣么?
来源:互联网 更新时间:2026-07-02 07:24
这两年聊 NL2SQL,大家经常有意无意地走捷径。之前因为工作原因,我自己也难免如此,哈哈。
最常见的捷径,就是一句话给某条路线判死刑。
有人说,直接让大模型生成 SQL,天生就是玩具;有人说,DSL 太老;有人说,MQL 只是 BI 的补丁;还有人觉得 Logic Plan 这套太重,只有巨头才养得起。
如果真把这些路线拉到企业里看,其实真实的结论远没这么简单。
NL2SQL 没有绝对的谁好谁坏。真正需要判断的,是你准备解决什么场景,愿意付出什么建模成本,以及想把系统的天花板抬到哪里。
如果只是做一个自然语言问数 Demo,四条路线里很多都能跑起来。
如果你想做的是企业级数据智能,事情就会变成另一套评判标准:口径稳不稳、关系路径能不能管住、权限能不能解释、模型升级后结果会不会漂、系统能不能持续做回归。
为了方便讨论,先把四条路线临时叫成这几个名字(名字不重要,关键是中间层的抽象程度不一样):
NL2LLM2SQL:自然语言直接交给大模型,大模型直接生成 SQL。NL2DSL2SQL:自然语言先落到预制模板、规则槽位或 DSL,再编译成 SQL。NL2MQL2SQL:自然语言先落到指标语义层、度量模型或语义查询层,再编译成 SQL。NL2LP2SQL:自然语言先落到 Logic Plan / Logic Form 这一类语义计划,再编译成 SQL。
这里的 MQL 和 LP 不是全行业统一叫法,你也可以叫 Semantic Query、Metric Query、Logic Form、YLP。名字不重要,关键是中间层的抽象程度不一样。

一、NL2LLM2SQL:最快入门,也最容易让人误解
这条路之所以火得最快,原因很现实。
它离用户最近,也离 PoC 最近。
用户问一句“上个月华东区净销售额是多少”,系统直接吐一段 SQL,数据库执行,结果出来,观感非常顺。对创业团队、内部工具团队、分析师 Copilot 场景来说,这条路几乎一定是最先尝试的。
它的优点也很直接:冷启动快;不要求你先做完整建模;适合分析师提效、SQL 修正、SQL Review、简单自助问数;对小团队很友好。
但这条路最早暴露的问题,也恰恰是企业最怕的问题。
一旦业务问题稍微复杂一点,大模型要一次性承担的责任就会变得很多:理解意图、识别业务词、找表、找字段、判时间、选口径、走 join、守权限、适配 SQL 方言。这里面任何一层走偏,最后出来的 SQL 仍然可能执行成功。
但可执行成功,不代表业务含义成立。这也是为什么很多团队做了一轮 NL2LLM2SQL 以后,会突然觉得模型“不稳定”。模型当然有问题,但更多时候,真正缺的是上下文工程。
这条路并非没有出路。
裸奔的 NL2LLM2SQL 天花板不高,但带着知识工程、示例 SQL、语义元数据和评测体系的 NL2LLM2SQL,依然能打。比如 Databricks 现在对这件事情的理解,就很有参考价值。
Databricks 官方现在对 AI/BI Genie 的做法,已经不是“给模型一堆表结构,然后让它自由发挥”。它在官方文档里明确强调几件事:给 Genie Space 配置 example SQL;配置 plain-text instructions;配置 knowledge store snippets;用 Unity Catalog 和 business semantics 管理数据对象;给 metric views 添加 display names、synonyms、formatting 这类 agent metadata;跑 benchmark、review 生成 SQL、监控空间质量。
如果把 LLM-Wiki 理解成一套企业化上下文工程和知识组织思想,那 Databricks 实际上已经在往这个方向走了。它在做的事,是给这条直生成路线不断加护栏:让模型少猜一点;让上下文更干净一点;让示例和规则更可复用一点;让 bad case 更容易被积累和回归一点。
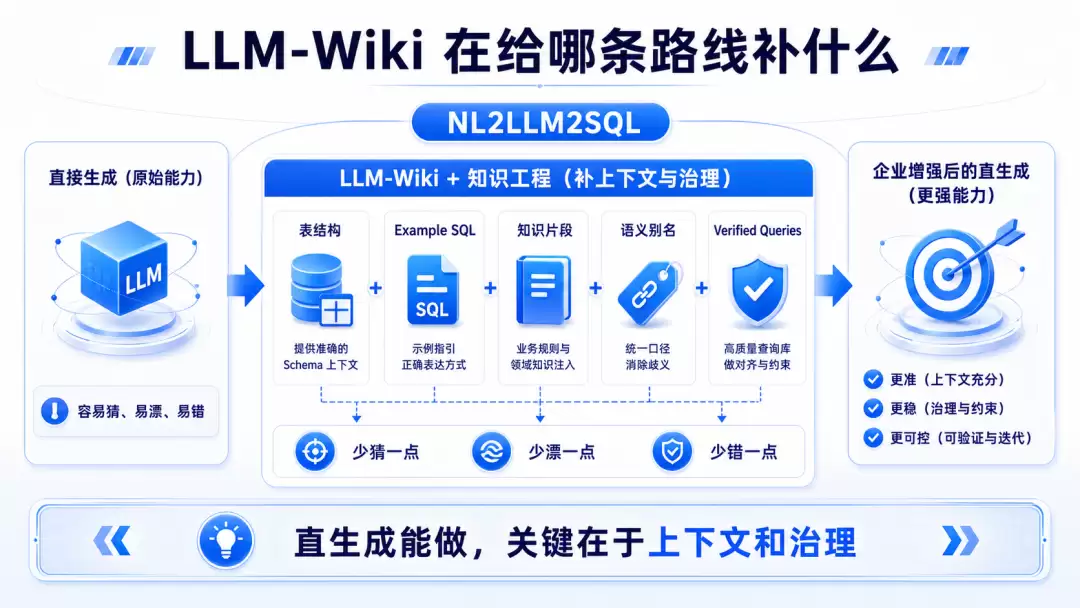
所以,NL2LLM2SQL 行不行?可以明确地说:能做,而且很多团队一开始就该从这里起步。问题会出在另一头:你如果把它当成企业终局,后面大概率会被口径、权限、关系路径和稳定性拖住。但如果你突破了 LLM-Wiki 企业级的知识库构建壁垒,那说不定可以成为一种 LLM2SQL 的终局。
二、NL2DSL2SQL:最稳的模板工人,最怕长尾问题
这条路线很多人现在不太爱讲,因为它说起来感觉有点“Low”。但不代表它在实际落地过程中就消失了。尤其是在固定报表问答、有限指标集、流程型运营查询、金融风控规则问答、客服辅助查询这类场景里,DSL 或模板槽位式方案一直都很能打。
它的优势很简单:稳定、可控、可测、很容易给出确定边界。
如果用户的问题类型本来就很固定,比如:某个指标按某几个维度切片;某类 TopN 排行;某个固定分析报表的补充问答;某几个预设口径的下钻——那 DSL 很可能比纯 LLM 更省心。
它的问题也很直接:一旦问题空间开始扩张,DSL 的维护成本会飞速上升。每新增一种表达、一个业务口径、一条关系路径、一个时间语义,你都要补模板、补规则、补测试。
模板系统很像一个非常勤快的老员工:让它干固定活,它非常稳;让它临场应对长尾问题,它就开始吃力。
所以这条路线非常适合做“可控场景内的高稳定问数”,不太适合承担企业开放式分析入口。DSL 的上限不在准确率,而在覆盖面。场景越窄,它越稳;场景一旦往开放分析走,维护压力会迅速反噬。
三、NL2MQL2SQL:语义指标层路线,最适合做可信问数
如果说 NL2LLM2SQL 更像从模型出发,那 NL2MQL2SQL 更像从数据平台和语义治理出发。
这条路线的核心思路,是先定义好业务指标、维度、事实、关系和业务友好的命名,再让自然语言先落到这层语义模型,最后再编译成 SQL。
这条路最大的好处,是它特别适合企业里最常见的一类问题:指标查询、多维切片、同比环比、TopN、Drill-down、经营报表补充问答、跨团队统一口径的自助分析。
一旦一个企业对“销售额”、“净收入”、“活跃用户”、“履约率”这类指标已经有稳定定义,那 MQL 路线会非常顺手。因为它把系统最容易漂的地方,提前收束到了语义层里。
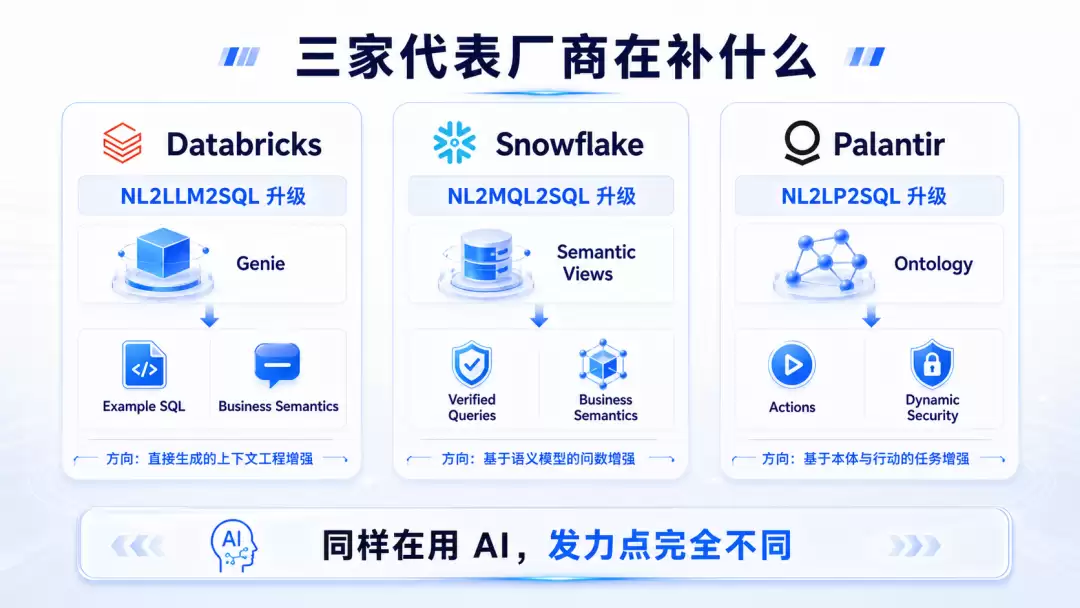
Snowflake 现在的做法,基本就落在这条路线的主轴上。Snowflake 官方对 Cortex Analyst 的定义非常明确:它通过 Semantic Views 来理解数据,并生成 SQL。Semantic View 里会定义 logical tables、business concepts、metrics、facts、dimensions、relationships,还支持 YAML 规范、custom instructions、verified query repository、evaluation。
Snowflake 抬这条路线天花板的办法,也很明确:把语义模型做得更像一个可治理的中间层,再用 verified queries 去持续修正和扩展它。
这条路线很适合大公司、成熟数仓团队、已有 BI 和指标体系的团队。因为它跟现有组织的衔接最自然:指标团队能参与;BI 团队能参与;数据建模团队能参与;SQL 仍然是执行层;上层却已经不是裸 SQL 世界了。
它的短板也很明显:只要问题主要围绕指标、维度和报表分析,这条路会很舒服。等问题开始进入复杂业务对象关系、事件序列、状态迁移、审批链路、动作边界时,MQL 的表达空间就会开始发紧。MQL 路线的强项是“可信问数”,它离“业务世界建模”和“语义执行”还有一段距离。
这也是为什么很多云厂商会先走到这一步,因为这一步最容易和现有数据平台、BI、指标体系打通,也最容易先释放商业价值。
四、NL2LP2SQL:企业级天花板最高,代价也最重
到了 NL2LP2SQL 这条路,问题就不再只是“怎么把自然语言变成一条更准的 SQL”了。
这条路线真正关心的是:问题里有哪些业务对象;对象之间是什么关系;时间和状态应该怎么理解;哪些规则是业务规则,哪些只是物理 join;当前用户可以看到什么、可以做什么;结果要不要进入后续动作、写回、审批和审计流程。
也就是说,它开始把自然语言问题先落成一层逻辑计划,再由这层计划去编译查询、解释、权限判断和后续动作。
这条路的建设成本当然更高。你需要的不只是模型和 SQL Tool,你还需要:语义资产、对象建模、关系建模、规则建模、Workbench、发布和回归、Trace、Guard、运行治理。
但它的上限也明显更高。
Palantir 这条线,就是一个非常典型的参照物。Palantir 官方对 Ontology 的描述,已经不再停在“语义层”这个词上了。它把 Ontology 讲成 organization 的 operational layer,里面有 objects、properties、links,也有 actions、functions、dynamic security。它的价值不只是在问数时给模型更好语义,还在于把业务对象、关系、动作和治理一起组织起来。
这件事带来的结果是什么?系统回答一个问题以后,不一定只停在“给你一条 SQL 和一个图表”。它可以继续往下走:解释这个结果从哪些对象和关系来;判断当前用户有没有权限看到下一层;调用 function 做额外分析;触发 ontology action 去写回或发起后续动作;留下审批、回滚和审计痕迹。
到了这一步,SQL 已经只是执行层的一部分。
LP 路线的真正价值,在于它把企业的业务世界先组织成可治理的语义计划,再去做查询、解释和动作。
所以如果只用“它能不能生成更准的 SQL”来评价这条路线,其实把它看得太片面了。
五、如果目标是真正企业级,哪条路线的天花板更高
如果非要把四条路线压成一句话,可以这么总结:
- 冷启动最快的是
NL2LLM2SQL; - 窄场景最稳的是
NL2DSL2SQL; - 可信问数最顺的是
NL2MQL2SQL; - 企业级上限最高的是
NL2LP2SQL。
但企业真实落地,很少会单押一条。

更常见的情况,是分层并存:外围入口,你会想要 NL2LLM2SQL 的覆盖面和自然交互能力;固定高频场景,你会想要 DSL 的稳定和确定性;指标问数、经营分析、报表体系,你会想要 MQL 的口径治理;高价值核心场景,比如复杂归因、业务对象关系分析、动作闭环、审批写回、跨系统执行,你迟早会走向 LP。
所以这四条路线更像四级台阶,不是四个互斥阵营。
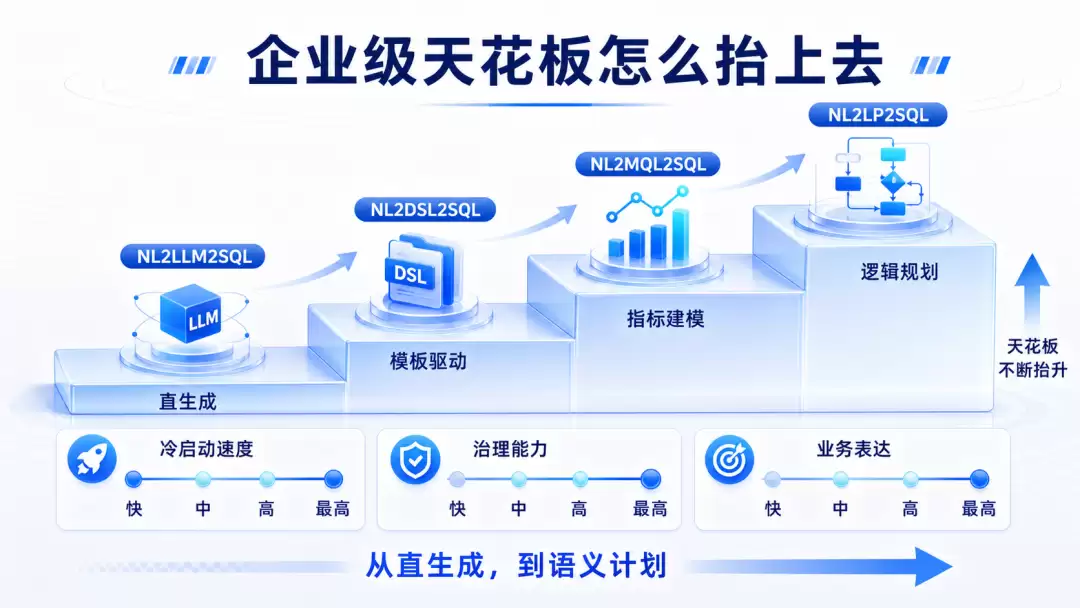
真正的问题从来都不是“谁彻底淘汰谁”。真正的问题是:你的企业现在站在哪一级台阶上,下一步要补的是上下文工程、模板治理、指标语义层,还是更高阶的本体化语义层。
这也是现在越来越确定的一点:企业级 NL2SQL 的天花板,最后一定不会只靠模型能力拉开,真正拉开差距的,是语义基座、上下文治理和运行治理。
六、为什么要把这部分内容放进知识星球
如果你只是想建立一个判断框架,这篇文章和周四晚上一小时直播,基本已经够了。
如果你真想把这四条路线一条条做出来,那远远不够。因为从文章到落地,中间还差很多东西:prompt 怎么写;SQL review 怎么接;trace 怎么留;eval 和 bad case 怎么做;example SQL 和 LLM-Wiki 怎么沉淀;DSL 怎么设计边界;MQL 怎么定义指标和关系;LP 怎么组织对象、规则、路径和权限;每条路线的 demo 应该先做成什么样;什么阶段该往上一层升级……
这正是把它放进知识星球长期项目线里的原因。
不想把这件事做成“看一篇文章,点个赞,觉得有道理就结束”的内容。更想把它做成一套连续项目:从最简单的 NL2LLM2SQL baseline 开始;往里补 LLM-Wiki、example SQL、context engineering;再做 DSL 的稳定窄场景;再做 MQL 的指标语义层版本;最后再把 LP 和本体化语义层的方向逐步展开。
NL2SQL 没有银弹。真正拉开差距的团队,最后拼的也不会只是模型,而是谁先把语义、上下文和治理一层层补齐。
-
archiveofourown 实战指南:常见用法整理
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
电视剧《小欢喜》剧情介绍
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
美好的简约网名男生(精选100个)
-
植物娘大战僵尸电脑端与手机端存档转移的方法
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
腾讯元宝怎么用来分析股票基金的基本面信息?
-
盖乐世社区怎么删除帖子?盖乐世社区个人发布内容撤回步骤
-
wallpaper壁纸声音怎么开启
-
独家/李宰旭入伍前「登上孤岛服役」 惊见前辈裸体:忍不住笑了
-
国际贵金属走低,现货黄金价格跌0.49%
-
问题:CIA币好不?Cia Protocol币今日上线:价格预测、代币经济学和未来潜力
-
看韩漫的APP推荐 2026免费韩漫阅读软件大全
-
短剧《嫡女她是山大王》剧情介绍
-
俄罗斯最大yandex入口外贸日报直达链接
-
OpenAI 调整手机端 ChatGPT,提示词可提前选 AI 响应档位
-
免费观看国外短视频的app有哪些 观看国外短视频的软件下载
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
1 航空服务口号:飞跃晴空,更加完美。 07-02
-
2 2026高考壮行口号有哪些? 07-02
-
3 质量安全口号:再小的缝隙都会演变一个大缺口! 07-02
-
4 公司企业激励口号精选 07-02
-
5 团队励志激励口号汇编 07-02
-
6 CDR文字转曲的快捷键是什么【教程】 07-02
-
7 电信积分商城在线兑换入口 中国电信积分兑换商城官网 07-02
-
8 菜鸟怎么查询快递单号 菜鸟物流实时追踪方法【技巧】 07-02
-
10 Live2D Cubism提示授权失效怎么办 激活修复方法【指南】 07-02



