图灵奖得主Sutton新作:用一个1967年的公式,解决流式强化学习一大缺陷
来源:互联网 更新时间:2026-06-11 15:06
2024年底,一篇题为《流式深度强化学习终于跑通了》的论文在学界激起了不小的波澜。作者来自阿尔伯塔大学的Mahmood团队,他们在论文中花了大量篇幅,描述了一个令人尴尬的现实:强化学习,这种本该“边走边学”的方法,在深度神经网络时代却几乎做不到这一点。只要去掉回放缓冲区,把批量大小设为1,训练过程立刻就会崩溃。他们给这个现象起了个名字,叫
“流式壁垒”
当时,他们提出的StreamX系列算法,依靠精心调配的超参数、稀疏初始化和各种稳定化技巧,算是勉强翻过了这堵墙。
然而,不到一年半之后,同一个课题组的一位成员,联合来自Openmind研究院的合作者,给出了一个截然不同的答案:
流式壁垒的根源,或许不是“数据不够多”,而是“步长选错了单位”

一脚油门,开出了多大的坑
一脚油门,开出了多大的坑
想象一下,你正在学车,练习倒车入库。教练告诉你,每次“踩油门0.1秒”。问题来了:同样是踩0.1秒,上坡和下坡、空载和满载,车子实际前进的距离可能天差地别。有时候差一厘米刚好停正,有时候差三十厘米就直接撞墙。
传统的梯度学习,其步长设置干的正是这种事:它规定了参数每次移动的“距离”,但对于函数输出到底因此改变了多少,却完全没有控制。在批量训练时,成百上千个样本的误差平均下来,极端情况被稀释了,问题还不明显。但在“流式”环境下,每一步只有一个样本,没有平均可言。一旦梯度方向不稳定,更新幅度就会忽大忽小——今天前进30厘米,明天后退50厘米,整个学习过程就在这种剧烈震荡中崩溃了。
这种
“过冲与欠冲”现象
重新定义“一步该做多少”
重新定义“一步该做多少”
那么,有没有可能换个思路?来自Openmind研究院的Arsalan Sharifnassab与阿尔伯塔大学的Mohamed Elsayed、A. Rupam Mahmood和Richard Sutton等人在新论文中提出的方案,核心思想很简单:
与其规定参数移动多少,不如直接规定函数输出该改变多少。
这个想法并非凭空而来。早在1967年,日本学者Nagumo和Noda就在自适应滤波领域提出了“归一化最小均方差”算法,其本质就是用期望的输出变化来反推步长,而不是反过来。只不过,那个算法只适用于简单的线性场景。
现在,研究者们将这一思路推广到了深度强化学习。他们称之为
“意图更新”
具体来说,对于价值学习(预测未来奖励),他们定义的意图是:每次更新后,当前状态的价值预测误差应该缩小一个固定比例,比如5%。对于策略学习(优化决策行为),意图则是:
当前动作的选择概率,每一步只允许改变一个“适度”的量
回到开车的比喻:这就好比司机每次操作前,先决定“我要让车向前移动20厘米”,然后根据当前路况(坡度、载重)自动计算该踩多深的油门,而不是每次都机械地踩下同样的深度,然后听天由命。
图灵奖得主与他的拼图
图灵奖得主与他的拼图
这篇论文的署名作者中,有一位重量级人物:Richard S. Sutton——2024年图灵奖得主,被广泛誉为“现代强化学习之父”。
Sutton在学界的地位,大约相当于物理学里的费曼。他不仅提出了时间差分学习和策略梯度这两个奠定现代强化学习基础的框架,还与Andrew Barto合著了该领域最权威的教材。2024年,他与Barto共享图灵奖,获奖理由是“为强化学习奠定了概念与算法基础”。
获奖之后,Sutton没有选择退休,而是将奖金投入他创立的Openmind研究院,专门资助那些愿意在“不受商业化压力影响的环境下探索基础问题”的年轻研究者。这篇新论文,正是从这家非营利机构走出来的成果。
而论文的第一作者Sharifnassab,此前刚刚在ICML 2025发表了MetaOptimize框架,研究如何在线自动调整学习率。两个课题的关注点高度一致:如何让“步长”这个最基本的组件,本身变得更智能。
算法细节:比想象中简洁
算法细节:比想象中简洁
“意图更新”的数学推导并不复杂,其核心公式可以用一句话概括:步长等于“期望的输出变化量”除以“梯度方向对输出的实际影响力”。
在价值学习中,这个“实际影响力”就是梯度向量的范数(相当于衡量当前参数区域有多“陡”):越陡的地方,步长自动变小;越平缓的地方,步长自动变大。这样一来,就能保证每次更新对价值函数造成的“冲击”是基本一致的。
在策略学习中,“期望变化量”被定义为与优势函数成比例:当前动作比平均水平好多少,策略就往那个方向调整多少——同时通过一个滑动平均来归一化量级,确保长期来看,策略改变的幅度稳定在一个可解释、可控制的范围内。
研究者还将这一核心思想与两个成熟的工程实践相结合:
RMSProp风格的对角缩放
资格迹
最终,他们形成了三个完整的算法:用于价值预测的
Intentional TD (λ)
Intentional Q (λ)
Intentional Policy Gradient



实验结果:不靠GPU也能打平SAC
实验结果:不靠GPU也能打平SAC
论文在多个标准基准上评估了这套方法,结果相当令人印象深刻。
在MuJoCo连续控制任务(包括Ant、Humanoid、HalfCheetah等复杂的仿真机器人)上,新方法Intentional AC在纯粹的流式设置下(批量大小=1,无回放缓冲区),其最终性能多次接近甚至比肩SAC——后者是使用大批量回放缓冲区、几乎是当前连续控制任务的黄金标准算法。而在计算开销上,差距更为明显:
每次Intentional AC更新所需的浮点运算,只有一次SAC更新的约1/140
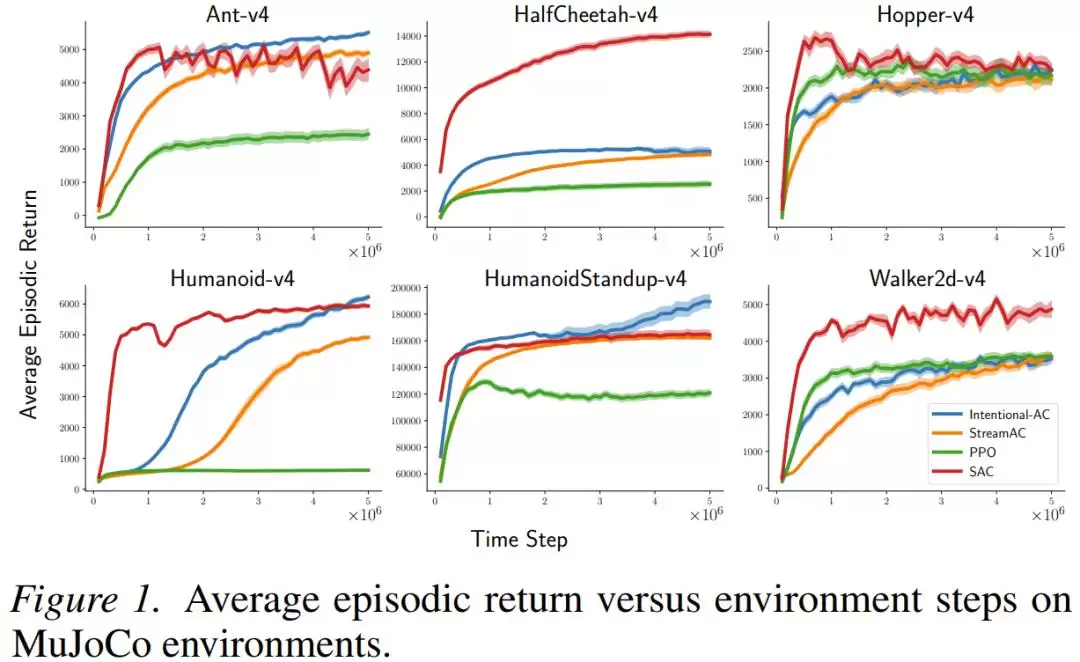
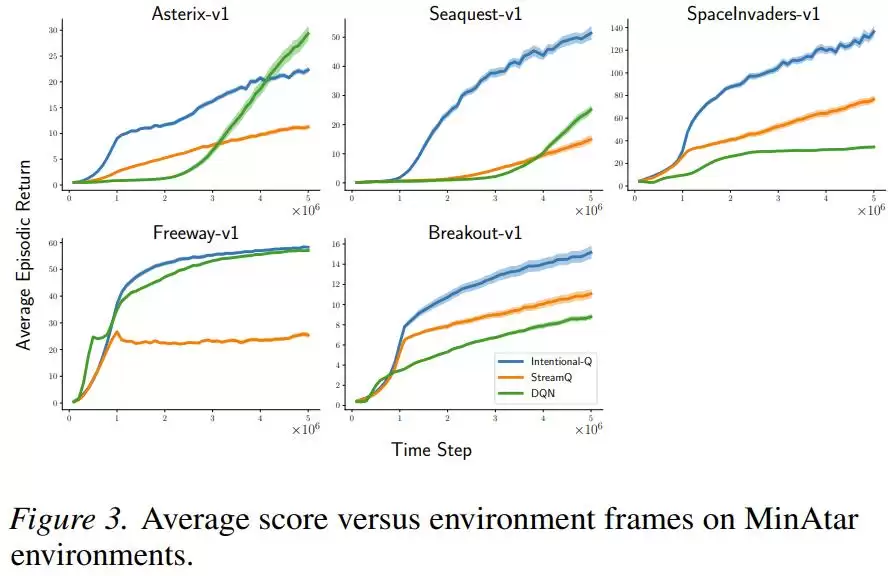
在Atari和MinAtar离散动作游戏上,Intentional Q-learning的表现同样与使用回放缓冲区的DQN相当,并且用同一套超参数设置就跑通了全部任务,无需为每个游戏单独调参。
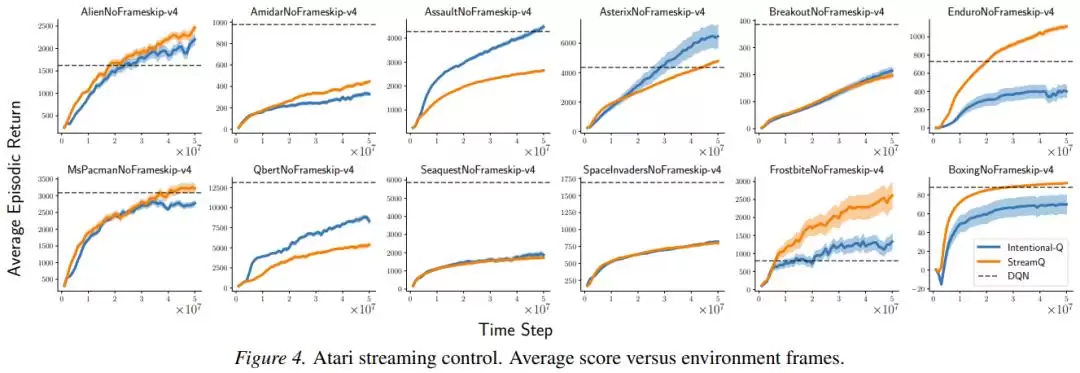
研究者还专门验证了“意图”是否真的被实现了。他们测量了实际更新量与预期更新量的比值。在禁用资格迹的简化设置下,这个比值的标准差仅为0.016到0.029,99分位数均在1.07以内。这意味着,在绝大多数情况下,更新确实做到了“说好要做多少,就做多少”。
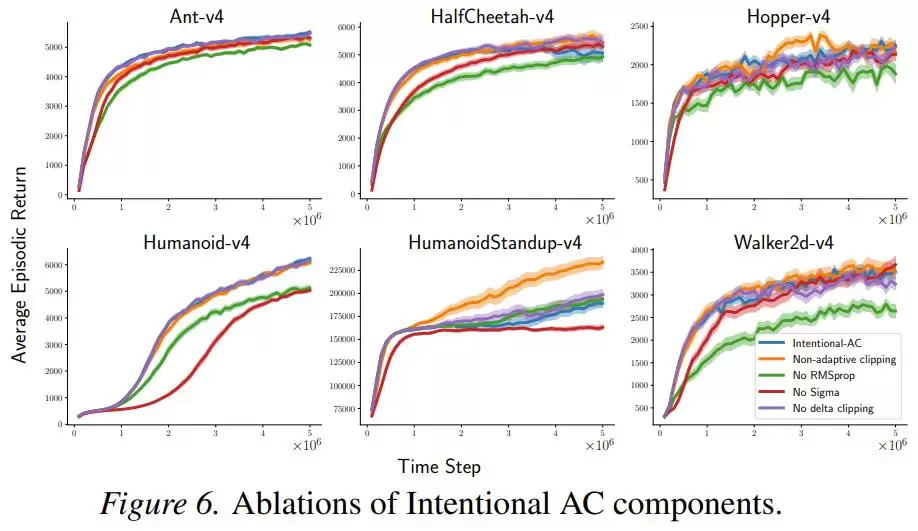
此外,一组消融实验表明,即使去掉RMSProp归一化或者某些辅助项,性能虽有下降但仍有竞争力,而“意图缩放”机制本身才是首要的贡献者,其他组件更多是起辅助稳定作用。
问题还是有的
问题还是有的
“意图更新”框架在鲁棒性上也展示出优势。当研究者逐一去掉StreamX方法所依赖的各种稳定化技巧(如稀疏初始化、奖励缩放、输入归一化、LayerNorm)时,Intentional AC的性能退化明显少于原始的StreamAC。这说明,意图缩放从根源上减少了对这些外部“拐杖”的依赖。
但论文也坦诚指出了一个尚未完全解决的问题:在策略学习中,步长依赖于当前采样的动作,这会使不同的动作被隐性地赋予不同的“权重”,从而可能改变策略梯度的期望方向。在Humanoid等任务中,通过测量期望更新方向的余弦相似度,研究者发现这种偏差在关键学习阶段接近0.96(影响微乎其微);但在Ant-v4任务中,对齐度的中位数降至0.63,说明问题并非总能被忽略。
作者指出,未来的研究应当寻找对动作选择无关的步长策略,使得“意图”在期望意义上也能保持无偏。这是该方向留给后来者的一个明确课题。
结语:让AI像人一样边做边学
结语:让AI像人一样边做边学
当前主流的大模型训练范式,依赖于对海量数据的批量消化:把互联网上的文本和代码全部喂进去,反复迭代,最终涌现出惊人能力。这套路线已被证明行之有效,但它从根本上说是“先学后用”的:一旦训练完成,模型便基本冻结,难以从后续每一次实际交互中持续、高效地更新自己。
流式强化学习所追求的,是另一种截然不同的模式:
不依赖海量经验回放,不依赖庞大的GPU集群,让每一步经历都立刻转化为参数更新,持续、廉价、自适应
从2024年“终于跑通了”的初步突破,到这篇论文提出的“意图更新”原则,流式深度强化学习正在以令人意外的速度走向成熟。它不会取代批量训练的大模型,但对于需要长期在线适应的机器人、边缘计算设备,以及任何无法承受大规模回放缓冲区和GPU集群的应用场景来说,这条技术路线正变得越来越有说服力。
步长不只是一个需要调试的超参数,它本质上是AI每一步“想做多少”的承诺。当这个承诺变得清晰、可控,学习过程本身,也就稳定了。
-
archiveofourown 实战指南:常见用法整理
-
币安Binance虚拟货币交易平台 币安官方APP安卓苹果下载入口
-
客单价碾压宝马奥迪!极氪5月交付新车34377辆:连续4个月双增长
-
折后价近千元 澳洲一店主将真老鼠缝到内裤上当时尚单品卖
-
电视剧《小欢喜》剧情介绍
-
如何在夸克浏览器中开启网页视频的倍速播放功能?
-
美好的简约网名男生(精选100个)
-
植物娘大战僵尸电脑端与手机端存档转移的方法
-
《梦幻西游》159五开五门怎么搭配-159五开五门常见搭配
-
欧易OKX官方网站直达入口 2026欧易官方App安卓版v7.1.0下载安装
-
腾讯元宝怎么用来分析股票基金的基本面信息?
-
盖乐世社区怎么删除帖子?盖乐世社区个人发布内容撤回步骤
-
wallpaper壁纸声音怎么开启
-
独家/李宰旭入伍前「登上孤岛服役」 惊见前辈裸体:忍不住笑了
-
国际贵金属走低,现货黄金价格跌0.49%
-
短剧《嫡女她是山大王》剧情介绍
-
问题:CIA币好不?Cia Protocol币今日上线:价格预测、代币经济学和未来潜力
-
看韩漫的APP推荐 2026免费韩漫阅读软件大全
-
OpenAI 调整手机端 ChatGPT,提示词可提前选 AI 响应档位
-
免费观看国外短视频的app有哪些 观看国外短视频的软件下载
-
1

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
-
2 图解强化学习 |手算GRPO 05-27
-
3 谷歌浏览器Mac版怎么添加搜索引擎 01-30
-
4 洛克王国世界昏昏鸡怎么进化 01-30
-
5 云顶之弈s17特攻剑圣阵容推荐 01-27



