我在技术面试中用 ChatGPT 作弊,没人知道
来源:互联网 更新时间:2026-06-01 14:46
ChatGPT 到底有多强?不用多说,大家都有目共睹。小到帮小公司自动化日常管理,大到给 Web 开发者写出一整个 React 组件——它的能耐似乎怎么吹都不过分。
但与此同时,一个棘手的问题一直盘旋在技术招聘圈:
ChatGPT 会不会让技术面试变成一场“作弊狂欢”?
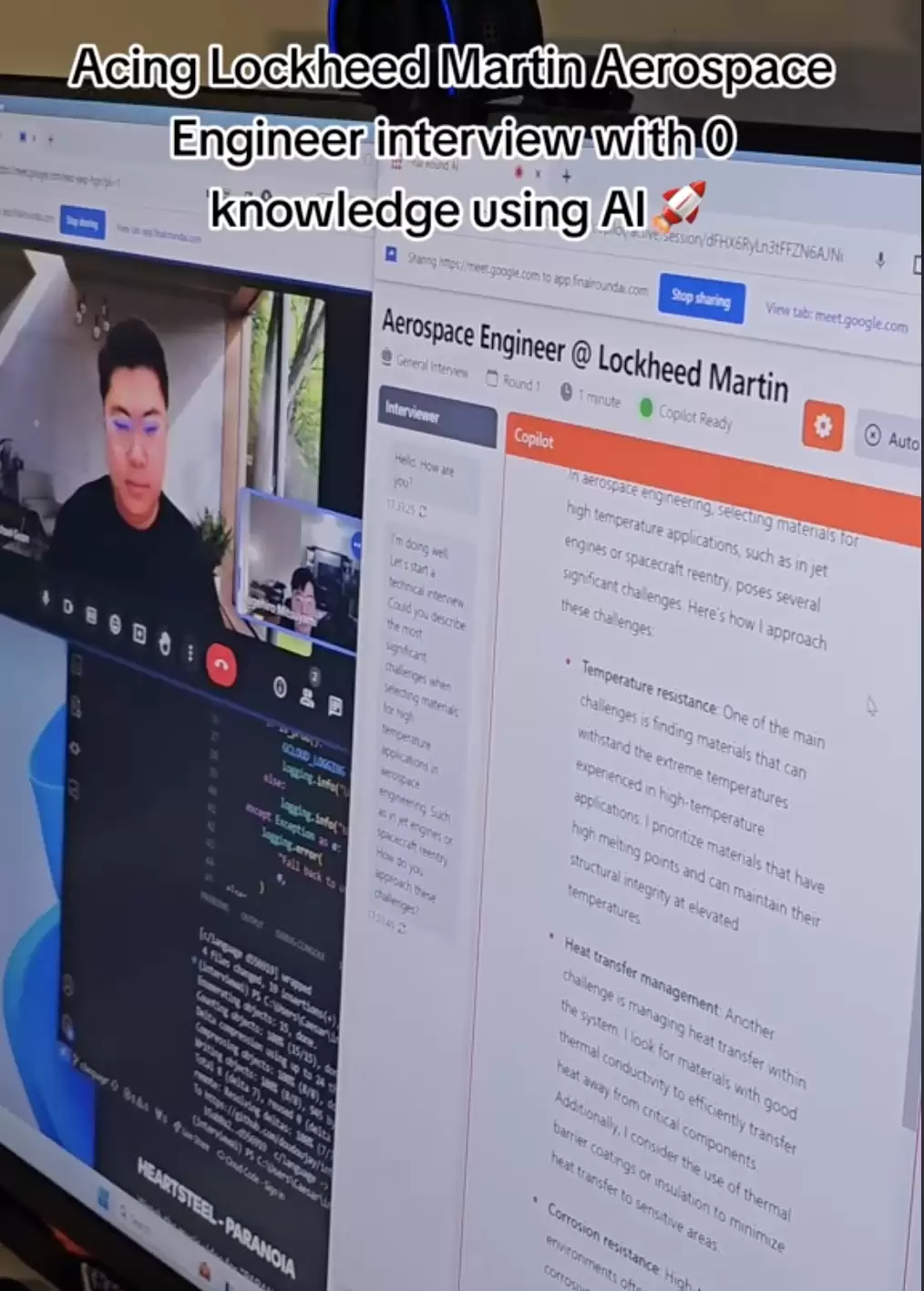
对于这类作弊工具,最初的行业反应几乎清一色是“狼来了”:
Reddit 上有人说:“ChatGPT 就是编码的终结者。”
YouTuber 高呼:“软件工程已死,凶手是 ChatGPT。”
X(前 Twitter)上也在问:“ChatGPT 意味着编码面试的终结吗?”
ChatGPT 能在面试中“助攻”,这几乎不言自明。但真正值得深挖的问题是:
它能帮到什么程度?
作弊(而且不被发现)到底有多容易?
那些还在用 LeetCode 原题的公司,是不是该立刻调整面试方式了?
为了拿到硬核答案,我们拉了一组专业面试官和真实求职者,搞了一场“作弊实验”。下面直接把结果摊开来说。提前剧透一句:
公司必须马上换题,刻不容缓!
实验准备
interviewing.io 本身是一个面向工程师的面试练习平台和招聘市场。工程师用它模拟面试,企业用它物色人才。我们的生态里有大量专业面试官,也有成千上万用平台准备面试的求职者。
面试官
面试官全部来自我们的专业面试官库,被随机分成三组,每组负责问不同类型的问题。
关键设定:面试官完全不知道这个实验跟 ChatGPT 或作弊有关。
三种问题类型如下:
- :面试官直接从 LeetCode 上挑的题目,一字不改。
LeetCode 原题
例:原封不动地问 Sort Colors 问题。
- :对 LeetCode 原题做了一些修改,看起来类似但又有明显不同。
改良 LeetCode 问题
例:对上面的 Sort Colors,把输入从 3 个整数(0,1,2)改成 4 个整数(0,1,2,3)。
- :题目与网上任何已知问题都没有直接关联。
自定义问题
例:给你一个日志文件,格式为
LOG FILE START NullPointerNinja: "who's going to the event tomorrow night?" - 100% LambdaLancer: "wat?" - 5% NullPointerNinja: "the event which is on 123 a venue!" - 100% SyntaxSorcerer: "I'm coming! I'll bring chips!" - 80% SyntaxSorcerer: "and something to drink!" - 80% LambdaLancer: "I can't make it" - 25% LambdaLancer: "?" - 25% LambdaLancer: "I really wanted to come too!" - 25% BitwiseBard: "I'll be there!" - 25% CodeMystic: "me too and I'll brink some dip" - 75% LOG FILE END
关于问题类型和实验设计的更多细节,请参考面试官实验指南文档:https://docs.google.com/document/u/0/d/1UdWZHUQfeLR8oUiNY4JfwgES42HTlAQL5z_VfQJPPKk/edit
面试者
面试者来自我们的活跃用户池,经过一个简短调查筛选。选择标准如下:
当前正在积极找工作;
有4年以上工作经验,申请的是高级职位;
对“ChatGPT 编码”的熟悉程度为中等或高等;
自认为能在面试中作弊而不会暴露。
这样的筛选,就是为了挑出最可能在真实面试中作弊的那批人——既有动机,又熟悉 ChatGPT 和编码面试。
我们明确告诉面试者:面试中必须使用 ChatGPT,目标就是测试你们用 ChatGPT 作弊的能力。
最终我们完成了 37 场面试,其中 32 场有效(去掉了 5 场,因为参与者没按要求操作):
11 场“LeetCode 原题”
9 场“改良 LeetCode 问题”
12 场“自定义问题”
说明:因为平台允许匿名,面试只开音频不开视频。匿名为的是给用户一个安全空间,让他们能快速试错和学习,不被评判。这对用户是好事。但我们也要承认,没有视频会让实验比真实面试稍简单一些——真实面试有摄像头,作弊难度会上升,但不会消失。
面试结束后,面试官和面试者都要填一份退场调查。我们问面试者:用 ChatGPT 作弊时遇到了哪些困难?问面试官:对这场面试有什么担忧?我们想看看有多少面试官会把面试标为“有问题”,或在调查中报告怀疑作弊。
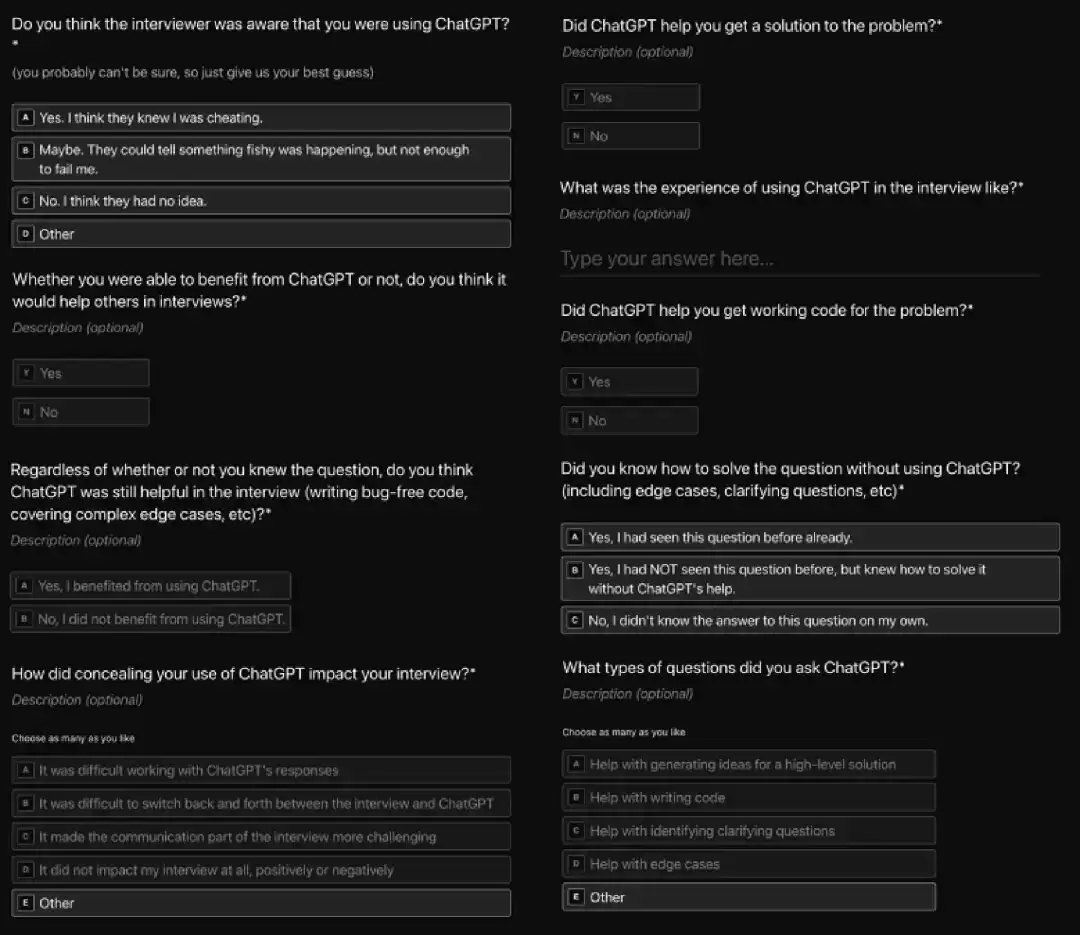
后续调查:面试者问题
后续调查:面试官问题
实验开始前,我们也没底。但设想一下:如果有一半作弊的求职者都能顺利通过,那对整个行业来说绝对是个警钟。
实验结果
在剔除不按要求进行的面试后,结果如下。对照组是平台上常规模拟面试的通过率(53%),这些面试来自实验之外,大部分是 LeetCode 风格的问题(FAANG 公司主要就问这些)。这一点后面会讨论。
与平台平均值和“自定义”问题相比,“原题”的通过率要高得多。“原题”和“改良”问题的差异没有统计学意义。“自定义”问题的通过率则明显低于其他任何一组。
回答原题,表现最好
不出所料,使用原题的那组表现最好,73% 通过了面试。面试者反馈说,ChatGPT 直接给出了完美的解决方案。
这一组调查中最值得注意的评论非常能说明面试官的心态:
应聘者能轻松回答这个问题,很难判断是因为他们真的厉害,还是因为他们以前听过这个题。通常为了区分,我会对问题做一两处修改。那么,当面试官真的对问题做了修改之后,情况会怎样呢?来看“改良问题”组。
回答改良问题,要更多提示
这一组拿到的是标准 LeetCode 问题,但经过了无法从网上直接查到的修改。也就是说,ChatGPT 不可能直接背出答案,而需要靠自身能力去解决。因此,面试者更依赖 ChatGPT 的实际推理能力,而非背诵。
结果与“原题”组差别不大:67% 的求职者通过。统计上,这个差距并不显著——说明“改良问题”和“原题”本质效果一样。这证明
ChatGPT 完全能处理面试官对问题的小修小改
不过面试者也提到,让 ChatGPT 解决修改后的问题需要给出更多提示。有人这样说:
直接回答 LeetCode 原题毫无压力。但让 ChatGPT 回答一个不那么直接的 LeetCode 风格后续题,难度会明显增加。自定义问题,通过率最低
“自定义”问题组的通过率果然最低,
在统计上,它不仅明显低于另外两个实验组,还明显低于对照组!
需要说明:这个数字最初计算时略高,后来仔细检查自定义问题后,我们发现了一个意料之外的问题,下一节会细说。
没有人被抓到作弊
实验中,面试官完全没有意识到面试者是被要求作弊的。每次面试后,面试官要完成调查,描述他们对评估结果的信心。
面试官对自己判断的正确性信心满满,72% 的人表示对招聘决定有把握。
仅仅一次面试就下这种结论,可能有些过于自信了。
我们早就知道工程师不善于自我评估,现在发现面试官也会高估自己问题的有效性,或许也不该感到意外。
有部分面试官(28%)对招聘决定没信心,问及原因,他们的回答如下:
注意:没有任何一个原因提到“作弊”!
大多数面试官具体描述了不自信的原因:解决方案不够优、遗漏边缘情况、代码混乱、沟通糟糕等。我们特意设置了一个“其他问题”选项,想看看是否有人提作弊,但深入挖掘后只看到诸如“性格问题”“需要加快编码速度”之类的轻微意见。
除了这个开放机会,我们还在后续调查中给了面试官三次机会去指出其他担忧:包括自由文本框和几个选择题,选项可以直接解释他们的担心。
当
面试者因为不理解 ChatGPT 提供的回答而面试失败时
面试官却把那些奇怪的行为和生硬回答归结为“缺乏练习”
“求职者的方法不够清晰,而且他们急于开始编码。”
“这位求职者甚至没准备好解决 LeetCode 上最基本的编程问题。”
“总的来说,解决问题的能力不错,但应聘者需要在编码和识别关键边缘情况方面加快速度。”
那么,到底有没有面试官记录了对作弊的担忧?有人被抓到吗?
事实是:没有一位面试官提到对求职者作弊的担忧。
我们自己也惊讶:面试官竟然完全没有怀疑。有趣的是,面试者自己也很自信:81% 的人表示不担心被发现,13% 的人觉得面试官可能已经发现,只有 6% 的参与者认为面试官会怀疑他们作弊。
大部分面试者都确信作弊不会被发现。少数人担心被发现,面试官也确实在事后分析中给出了异常评价,但没人往作弊上想。总而言之,
大多数面试者认为作弊不会被发现——他们是对的!
企业应立即改变所提的问题
从这些结果可以得出一个清楚到不能再清楚的结论:
公司必须立刻开始问自定义问题,否则求职者就能在面试中轻松作弊,最终面试完全失去信号价值
。
ChatGPT 已经淘汰了原题。还在依赖 LeetCode 原题的公司,招聘过程基本就是随缘了。招聘本来就够难了,再摊上作弊问题更是雪上加霜。如果你所在的公司还在原封不动地用 LeetCode 的原题,请务必把这篇文章转给内部同事看看。
使用自定义问题不仅能有效防止作弊,还能过滤掉那些只会背 LeetCode 答案的求职者(你看,自定义问题的通过率比对照组还低很多)。同时,这也能显著改善求职者的体验,让人才更愿意为你工作。不久前我们做过一项分析:什么造就了优秀的面试官?不出意外,“提出好问题”是最高频的答案。而我们评分最高的面试官,往往是那些更愿意出自定义问题的人。在我们的研究中,问题质量对求职者是否愿意留在公司的影响,甚至超过了公司品牌实力。品牌实力在吸引人进来时很重要,但面试过程中,问题的质量才是关键。
来看看求职者们的真实反馈:
“要是不仅仅是简单的算法问题会更好。”“我喜欢这个问题——它把一个相对简单的算法问题(构建并遍历树)加了些深度。面试官还把问题跟 [Redacted] 的实际产品联系起来,让它看起来不像玩具问题,更像实际问题的精简版。”
“这是我在这个网站上遇到过的最喜欢的问题。它是少数几个看起来适用于现实生活的方法之一,来自一个真实的(或潜在的)业务挑战。它还很好地融合了复杂性、效率和阻塞等挑战。”
对于那些决定采用更个性化问题的公司,还有一个略显微妙的建议:你可能会把 LeetCode 原题拿过来稍作修改。这很容易理解,毕竟比从头出题要简单。遗憾的是,这并不可行。
就像实验里看到的,一个问题看上去像自定义,不意味着它真的是自定义。它可能本质上还是那个 LeetCode 原题。
仅仅给问题“化个妆”是不够的。
面试官使用的具体问题我们不能分享。但可以给个例子,展示这种有严重缺陷的“自定义”问题——ChatGPT 一眼就能认出它:
For her birthday, Mia received a mysterious box containing numbered cards
and a note saying, "Combine two cards that add up to 18 to unlock your gift!"
Help Mia find the right pair of cards to reveal her surprise.
Input: An array of integers (the numbers on the cards), and the target sum (18).
arr = [1, 3, 5, 10, 8], target = 18
Output: The indices of the two cards that add up to the target sum.
In this case, [3, 4] because index 3 and 4 add to 18 (10+8).发现问题了吗?这不过就是经典的 TwoSum 问题套了个故事壳——输入输出一模一样。唯一的“自定义”就是加了点情节。既然与已知问题完全相同,ChatGPT 当然表现良好,哪怕故事再独特也白搭。
如何创建好的自定义问题
对于原创好题,一个特别实用的方法是:在团队内建一个共享文档,每当有人遇到一个认为有趣的问题——无论多小——都随手记下来。这些笔记不需要完善,但可以成为面试题的种子,帮你把日常工作提炼成富有吸引力的挑战。把这些“种子”变成面试题需要思考和打磨:删去太多细节,提炼出本质,确保求职者不需要花大量时间去理解背景。你可能要反复推敲几次才能搞定,但回报也是巨大的。
需要强调:我们并不主张彻底删除数据结构和算法(DS&A)题。DS&A 之所以名声不好,是因为一些面试官不敬业、不思考,也因为公司偷懒直接复制 LeetCode 原题(其中很多题本身就很糟糕,跟实际工作无关)。在好的面试官手里,DS&A 问题非常有力。用上面提到的方法,你完全可以提出新的 DS&A 问题——有实践基础,同时能吸引求职者,让他们对你的工作感到兴奋。
这样做,你也在推动行业的进步。如果背一堆 LeetCode 题就能获得面试优势,作弊反而成了理性选择,那就不对了。解决办法就是雇主多付出一点,提出更好的问题。一起行动起来吧。
给求职者的真心话
好了,现在,所有正在积极找工作的人,请竖起耳朵听:没错,你的一部分同事现在会在面试中使用 ChatGPT 作弊。对于那些还在用 LeetCode 原题的公司(很遗憾,很多公司都是),这些同事短期内确实能占点便宜。
但我们正处在一个临界点:公司的流程还没反应过来,但很快就会了。他们要么彻底放弃 LeetCode 原题(这对行业是好事),要么重新回到现场面试(这样作弊者基本没戏),或者两者兼而有之。
在当前本就不易的就业环境下,担心别人作弊确实令人沮丧。但凭良心,我们不能为了“公平”也去作弊。
而且,使用 ChatGPT 的面试者普遍反映: 在面试中用 AI 反而让整个过程更难了。下面视频里,一位面试者完美回答了问题,但在分析时间复杂度时却磕磕绊绊。他着急慌地想解释一个错误的时间复杂度(ChatGPT 给的),面试官直接懵了。
实验中没人被抓到作弊,因为他们没开摄像头。但正如视频所示,即使对熟练的求职者来说,作弊也很困难。撇开道德不谈,作弊本身很难、很累、而且执行起来并不简单。与其这样,不如把这些精力投入到真正的练习中。一旦公司改变了面试流程(希望很快),你就能凭真本事脱颖而出。最后,我们希望 ChatGPT 的出现能成为催化剂,推动行业面试标准从死记硬背转向真正考察工程能力。

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
免费影视剧APP推荐
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
短视频软件推荐
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
2 T-RAG=RAG+微调+实体识别 06-01
-
6 大语言模型RAG落地方案 06-01
-
7 海螺AI写书店氛围视频提示词怎么控制输出层级 06-01
-
8 即梦AI团队多人协作项目怎么管理权限和版本?企业账户设置教程 06-01
-
9 业内人士日常都用AI干什么? | 创业Lifestyle 06-01
-
10 超全总结!大模型算法岗面试真题来了! 06-01



