企业内部如何更好落地大模型?我们走访了 10+ 先行者
来源:互联网 更新时间:2026-06-01 09:32
微软Copilot的推出,像一块投入平静湖面的石子,瞬间让“大模型如何在工作里真刀真枪地干”成了圈内热议的话题。紧随其后,钉钉、飞书这些我们日常离不开的办公软件,也火速把AI功能塞进了新版本。
对于软件公司来说,在自家产品上嫁接AI能力,然后变&现——这条路已经被Notion、多邻国这些先行者跑通了。但另一个视角同样值得关注:在企业真刀真枪的生产环境里,怎么把LLM的能力内嵌进去,给整个组织赋能,这才是大家都在琢磨的AI落地的另一面。
Founder Park研究中心最近和一批最早吃螃蟹的实践者们聊了聊。一个很明显的感受是:大模型技术的热度破圈之后,这次跟以往的技术升级不太一样,来自各行各业的企业,都表现出了空前的意愿,想在自己的生产环境里试试LLM。
不过,话说回来,应用落地的速度快不快、质量好不好,说到底还是看企业自己对技术的理解深度、动手实践的能力,以及选了哪条落地路径。这份总结性的研究,就是希望能给那些正在思考、摸索如何用大模型给生产提效的企业,提供一些实在的参考。
核心判断提炼:
- 在企业生产里,LLM最能直接创造价值的方式,目前集中在三件事上:把专家/岗位的经验数字化、把最佳实践放大,以及给初级员工快速赋能。
- 那些规则说不清道不明,或者缺乏过程性数据的需求,眼下还不适合用LLM来解决。反过来,从企业有独特数据积累的、切口很小但很具体的功能入手,反而能更快获得正向反馈,为后续把LLM和业务绑得更深打下基础。
- LLM本质上是个输入和输出的过程。无论是用Prompt还是更重的SFT(微调),高质量输入都是高质量输出的前提。这包括:整理好的知识库文本、凝结了专家经验的Prompt,以及保留了“Knowhow”的过程性数据或问答对。
- 定义好输入输出,前提是你得先搞清楚,这个LLM在你工作流里到底扮演什么角色,承担什么具体职责。所以,从业务场景出发,基于工作流提出清晰明确的需求,应用才能顺畅落地。
- 想实现好效果,又想控制成本,得靠一套综合的技术组件灵活搭配,甚至是用通用模型加上特定功能的小模型来组合完成。最早跑通的应用思路,往往是在现有系统里把LLM的能力集成进去,做以前很难实现的功能。
- LLM本质上是个概率模型,在工程实现上有点黑盒属性。所以,应用的实施效率会随着经验积累越来越高。说白了,经验多的团队,更容易做出好效果。
- LLM的落地,需要自上而下和自下而上的视角结合。即便不需要一把手亲自上手写代码,至少得有一把手明确的意识。具体选什么切入点、用什么应用形态,最好让一线员工来参与定义需求。产品初版上线,员工愿意用、能持续反馈,应用才能越优化越好。

01 LLM的技术特性,决定了它最适合干什么
LLM作为一个概率模型,本质就是预测下一个Token。所以,不管应用的外在形式是什么,核心目标都一样:让模型在特定的语境下,预测下一个Token的准确率达到预期标准。
从通用角度看,LLM拥有语言理解和逻辑推理的能力,落实到应用上,可以拆解成两种基本模式:写作与交互。
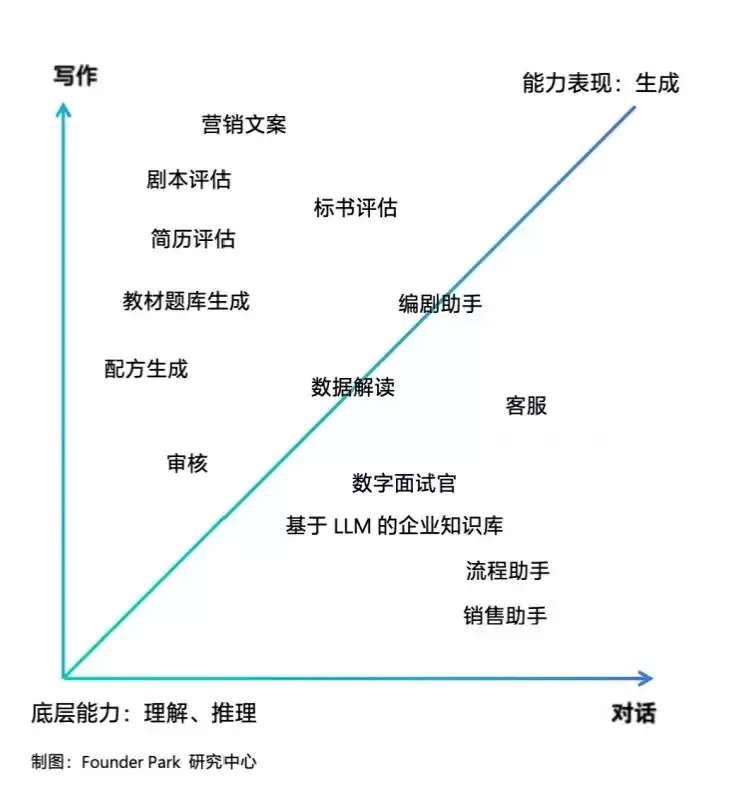
聚焦内容写作能力,以产出内容为交付结果。
最常见的例子就是营销文案生成、报表生成。这类应用的关键,在于让模型
按照特定的逻辑、风格和模式来生成内容
代码辅助可以看作是写作的一个特殊场景。作为模型评测的重要指标,coding能力本身就是LLM的强项。它能快速补全代码、修正错误,甚至还能做代码注释和运行。在企业内部,代码往往跟业务强相关,有些特性是通用的。在研发场景里,把模型能力做个性化适配,不仅能提升开发效率、统一代码格式,还能整体上提高代码复用率,帮企业沉淀代码资产。
当然,目前也有局限:模型输出的代码长度大概在30-50行,只能实现一些代码片段。要具备更高级的软件工程能力,还得等大模型本身的能力再进化。
工作执行需要对话交互,并且对交互质量有要求。
常见例子是企业内部的员工问答助手、客服助手。这类应用的关键,在于
让模型根据交互的具体情境来解读信息
在实践中,这两种能力模式往往会根据具体需求组合使用。比如,在对话交互中,帮业务人员生成所需的报告;为了更好的交互效果,从相关文档中抽取有针对性的信息,再进行话术写作。
02 具体到企业,LLM到底能带来哪些真金白银的价值?
LLM交付的不仅是工具,而是整个流程里某个环节的“工作成果”。
应用落地,可以看作是为模型提供
具体的语境
明确的行为规范
在实际的企业生产中,如果想落地应用,
专家/岗位知识数字化
高质量过程性数据
通过整理知识库来实现专家/岗位知识数字化,比如客服环节。因为它有明确的话术规则和对答规范,而LLM还能在这个基础上实现更自然的交流。
有些岗位的技能或Knowhow,很难用语言清晰描述,但它们会存储在工作流程的文件里。比如项目策划从需求到初稿再到定稿的过程、HR对简历的分析和评价、优秀销售和客户的交流记录。把这些过程性数据喂给模型,它就能从中汲取能力并进行模仿。
模型对生产环节的价值增量,可以从风险规避、开源、节流三个维度来评估。
节流
开源
风险规避
从效果角度来说,大模型带来的价值增量与应用成本之间的差值,当然是越大越好。
理想情况下,应用带来的价值增量如果能用指标来衡量,那项目落地就会顺利得多。比如销售场景,从使用大模型前后的复购率等指标变化,就能估算出对销售额的贡献;招聘场景,对比简历采纳率的变化,能估算出节省的人力成本;云成本管理场景,节省的成本更是可以直接感知。
大模型的应用落地,是“一把手工程”。如果能有效辅助管理层决策,也是很有潜力的落地场景。用LLM的对话能力,可以把企业的不同数据库打通,让管理层方便地调用、分析具体数据,高效获取决策所需的背景信息。

03 部署应用的成本,已经比想象中低很多了
优质开源模型出现后,闭源模型在能力上并没有显示出明显的代际差异,之前那种因为稀缺性带来的高议价能力也随之消失。2023年,千亿参数模型的私有部署方案,价格已经从千万元级别降到了百万元级别。而可以免费获取的开源模型,更是直接降低了项目的入门门槛。
其次,从性能与成本的平衡角度看,能达到性能要求之后,选择最具性价比的工程方案就行了。如果需要本地部署模型,成本主要取决于模型的大小,以及是否做微调。
私有部署模型不需要一味追求参数规模,而是在效果达标的前提下,追求最优成本。
选用量化模型能进一步降低本地部署的算力门槛。
以常用的13B模型举例,FP32全精度、FP16半精度、Int8精度部署方案对显存的要求分别是52G、26G、13G。对应的算力资源则分别为2张A6000、单张A6000、单张A10,成本区间大约在7万、3.5万、2万。
微调不一定非得做。
在访谈中,对于微调,也有观点认为是否需要微调,跟工程方案以及是否调用更强能力的通用模型API等因素相关。
如果企业想自己搭应用,模型调用和测试这笔隐形成本容易被忽略。
大模型的黑盒属性,也给工程方案带来了随机性,而且高度依赖经验。有做了半年以上方案落地的供应商感叹,在那些尾端的实现细节上,“只能踩坑,不过随着经验变多,从坑里爬出来的速度也会越来越快”。
两种成本模式:
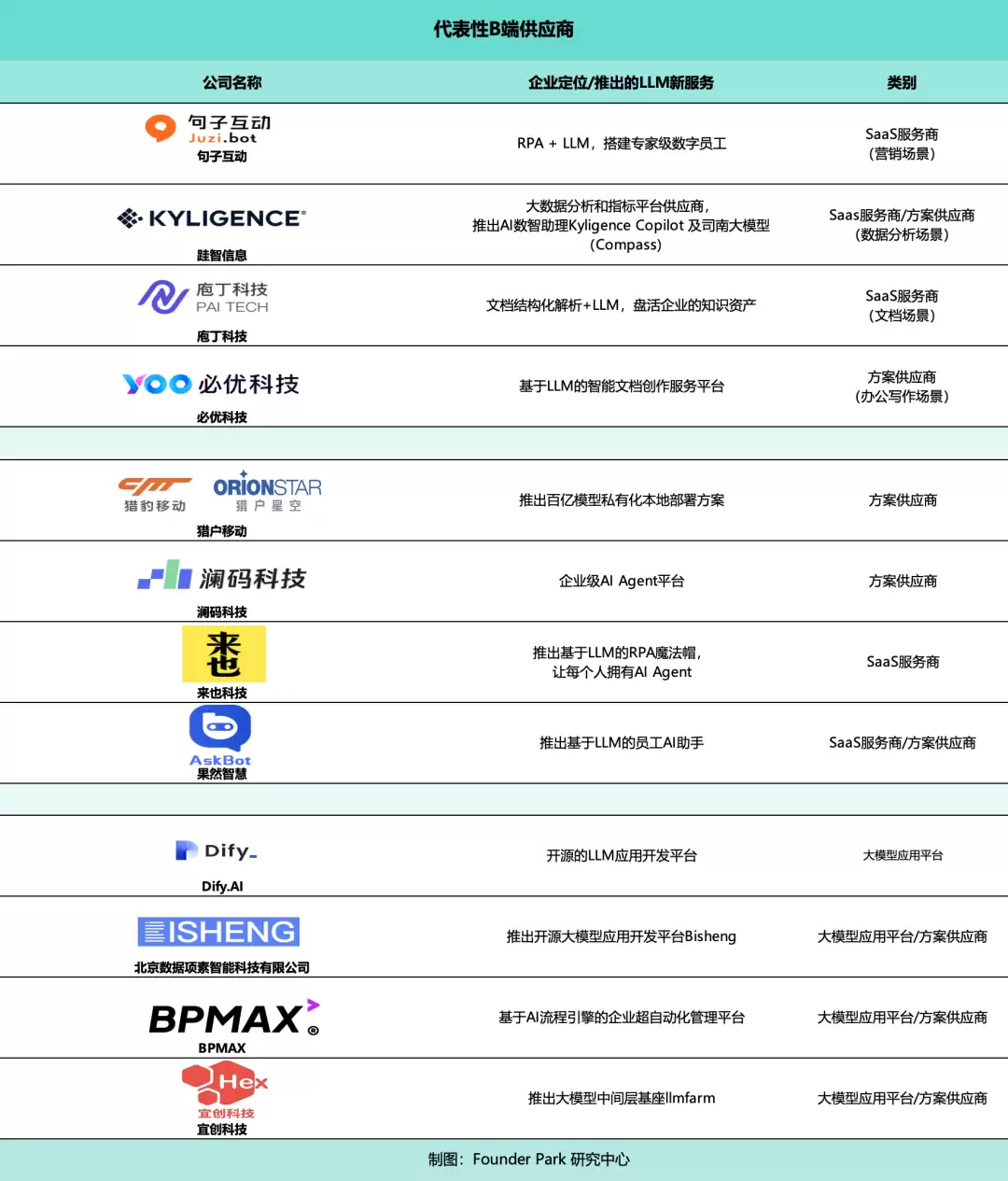
从技术门槛和时间人力成本考虑,复杂的项目,采购供应商的服务或方案是个不错的选择。根据多方调研,我们总结了目前市场上B端项目的收费情况。费用主要包括算力成本和人力成本,主要受是否部署本地模型(以及模型规模)、实施复杂度等因素影响。如果调用通用模型API,还会产生Token费。
购买本地部署+方案搭建:
简单问答类应用,使用13B、14B的免费开源模型部署,包括GPU算力费用,价格大约30万起步。
复杂应用,比如涉及数据分析的,需要用到30B及以上的免费开源模型,包括GPU算力费用,价格在百万元以上。
购买SaaS化解决方案:
主要费用包含实施费、产品使用年费/人头费、咨询费和Token费。如果调用外部通用大模型API,则按Token量支付模型调用费或购买流量包。前期产品梳理、数据治理工作量重的项目,还会收取咨询费。
这种形式下,如果不涉及本地模型部署,起步价更低,也更灵活。有供应商表示,理想情况下,涉及前期数据治理、百亿参数模型微调、复杂配套工程,对100到500人左右的企业,预算范围在500万以内。
可以预见的是,随着算力层Infra成熟、端侧模型性能提升以及大模型Token价格进一步降低,未来应用的成本还会更低。
04 基础实践经验总结:这套组合拳得打好
没有大模型不行,只有大模型万万不行。
把通用智能引入具体工作环节,就像把高压电引入单个房间,得靠一整套技术组合来实现。除了微调、Post Training、向量检索、Prompt Engineering,还包括其他检索技术、传统NLP技术等。
如何有效组合这些工具,全靠实践中积累的经验。有供应商认为,“技术落地的过程里,能形成一个合适的应用组合框架,才会产生更大的壁垒。”
在访谈中,多位供应商表示,
一套有效的方案中,大模型的作用占比不宜过高,甚至可能只占到20%~30%
数据安全和幻觉,靠配套工程来搞定。
企业最关心的幻觉和数据隐私问题,主要通过恰当的技术组合来解决。因为LLM是概率模型,所以在工程实施时,通过增加规则限制、RAG技术、上下游流程把控等方式,让回答正确率达标就行。必要时,遇到corner case可以直接拒答,最终实现0误答率。
企业本地部署的知识库和微调模型,能保证大部分数据循环在本地。涉及运营的关键数据,由本地模型(通常是微调过的小模型)直接处理。如果需要用大模型的推理、阅读和写作能力,调用外部API时只会流出局部、零散的不敏感数据,这在企业的接受范围内。
微调必须针对具体任务才有用。
一开始,很多人认为“垂直行业大模型”是解决方案,也就是用领域数据微调模型,让它既有通用智能,又有行业知识。但实践表明,那种面向发散性场景的微调,对落地用处不大。
这就好比有了行业百科全书,不等于就具备专家技能。如果企业觉得“内部微调一个垂直模型,每个岗位加几行prompt,就能变出专属GPTs”,那在生产场景里是很难搭建成应用的。只有在定义好具体需求的基础上进行微调,才能体现效用。而微调的前提,是必须定义清楚模型在特定语境下,“标准答案”是什么,并准备好问答对。
比如在招聘领域,面对批量招聘的岗位,在简历初筛时,让大模型阅读简历并给出评价,供HR进一步筛选。这就是一个非常具体的功能需求。
梳理面向任务的数据,是关键中的关键。
成功的企业实践里,产品最终交付的往往是某一工作环节的生产力,也就是执行具体任务。大模型有通用性,要让通用性和具体专业知识有效结合,就得让模型去理解某一类型的数据。这些就是“面向任务的数据”,它们的内容、格式、质量等要求,和工程方案紧密挂钩。
准备好这类数据,既需要有工程经验的实施方,也需要对业务本身有深刻理解。定义和梳理好这部分数据,需要企业与技术供应商之间密切协作。SOP(标准作业程序)的梳理和打磨,也是重要的前提。
不过,一个明显的变化是,在LLM时代,传统NLP那种知识标注的工作量已经大大减少了。有相关从业者表示,“以前工程师得帮企业做专家知识库,现在大模型自己就能做一部分。”因为LLM具备了理解和推理能力,也就有了直接从数据中读取知识并使用的本事。
05 想要应用深入,还得解决哪些问题?
跳出ChatBot和Agent的框架,站到Workflow的角度看应用。
有从业者提到,ChatGPT的对话界面火了以后,所有做企业级产品的人,第一反应都是在自己原有的功能上加一层Bot。结果往往是给用户增加了工作量。有时候,用户还得专门去养成和ChatBot交互的习惯。
微软定义了Copilot的范式后,大家又开始琢磨怎么在企业内部岗位里加Copilot。OpenAI强调了Agent概念后,大家又开始想怎么在企业场景里加Agent。从功能实现角度看,ChatBot只是一个交互触点,而Agent则是结合上下文、按特定规则去做判断和动作执行。
但如果真想考虑大模型怎么在企业工作中发挥价值,
日常工作的Workflow和数据流转,或许是更合适的视角
建立以数据反馈为视角的产品优化思路。
围绕产品构建数据循环,是提升应用能力的前提。
产品的探索和深入,也需要从数据反馈和数据回路设计的角度去思考。有B端产品开发者表示,尽管目前使用产品中的数据反馈,还没有形成“数据飞轮”,但它能提供如何优化产品的“Knowhow”。单个功能产生的价值终究有限,只有把“知识的生产和流动”放在产品体系内去完成,才能更好地与原有工作流结合,给生产带来更大价值。
基础模型的能力和成本还需要继续优化,才能支持大规模使用。
大家普遍觉得,目前国内模型的能力
更接近GPT-3.5,离GPT-4还有一段距离
有从业者表示,模型虽然能实现不错的生成质量,但表现不稳定,30%的情况下会出现比较差的结果。那些用过国内外模型的搭建者则表示,跟GPT-4和Claude相比,国内模型的指令跟随能力有明显差距,这就得写更复杂的prompt。当指令跟随性不够强时,想控制住结果,就得多来回交互几次,这样Token消耗量就上去了,也增加了执行任务的成本。所以,降低整体的推理成本,也是大家共同的期盼。

-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
免费影视剧APP推荐
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
好用的手环阅读app下载安装
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
1 半年涨价40%!AI带火这种算力金属:业内预计全球仅够开采15年 06-01
-
2 AI科技赋能 世界将会怎样 06-01
-
4 复合人工智能:企业使用AI成功的关键 06-01
-
5 长兴搭建人工智能公共服务平台 06-01
-
6 神奇!你见过生成Prompt的Prompt? 06-01
-
7 AI提示词大模型,解决教育教学大问题 06-01
-
8 通义智文:引领智能写作新风尚,让创作更高效更精彩 06-01
-
9 AI应用分享-AI智能助手 06-01
-
10 Google I/O大会释放竞争决心:搜索迎来历史性更新,AI进入一切 06-01



