阿里云大数据 AI 一体化最佳实践
来源:互联网 更新时间:2026-05-31 16:47
# 导读
这篇文章的核心,是想聊聊在AI应用的数据处理场景下,怎么把大数据平台的规模优势真正用起来,同时把开发复杂度降下去。顺便也会分享阿里云在大数据AI一体化这件事上的一些实战经验。
内容分三块:
1. 大数据AI开发范式的演变
2. 阿里云大数据AI一体化架构演进
3. Data+AI场景实践分享
---
## 01 大数据AI开发范式的演变
这几年机器学习的热度一直没降过,但说实话,开发流程本身并没有翻天覆地的变化——还是数据准备、预处理、模型开发训练、评估、上线,然后反复迭代。流程没变,可不同阶段投入的精力和时间比重,已经悄悄换了模样。
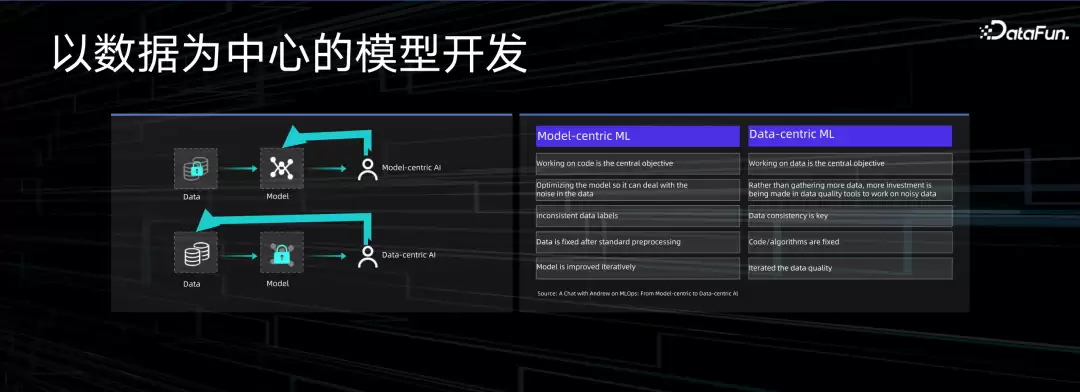 随着大模型这类项目逐渐成为主流,机器学习的开发范式正在从“以模型为中心”转向“以数据为中心”。过去算力贵,处理大规模数据成本太高,大家只能在模型上反复调参,跟过拟合、欠拟合死磕。那时候训练质量高度依赖标注数据的准确性,而标注成本可不是个小数目。到了Transformer模型出现之后,工程师的精力重心开始从调模型转向提数据质量——不再完全依赖标注数据了,数据平台的效率反而成了整条流水线的关键瓶颈。
随着大模型这类项目逐渐成为主流,机器学习的开发范式正在从“以模型为中心”转向“以数据为中心”。过去算力贵,处理大规模数据成本太高,大家只能在模型上反复调参,跟过拟合、欠拟合死磕。那时候训练质量高度依赖标注数据的准确性,而标注成本可不是个小数目。到了Transformer模型出现之后,工程师的精力重心开始从调模型转向提数据质量——不再完全依赖标注数据了,数据平台的效率反而成了整条流水线的关键瓶颈。
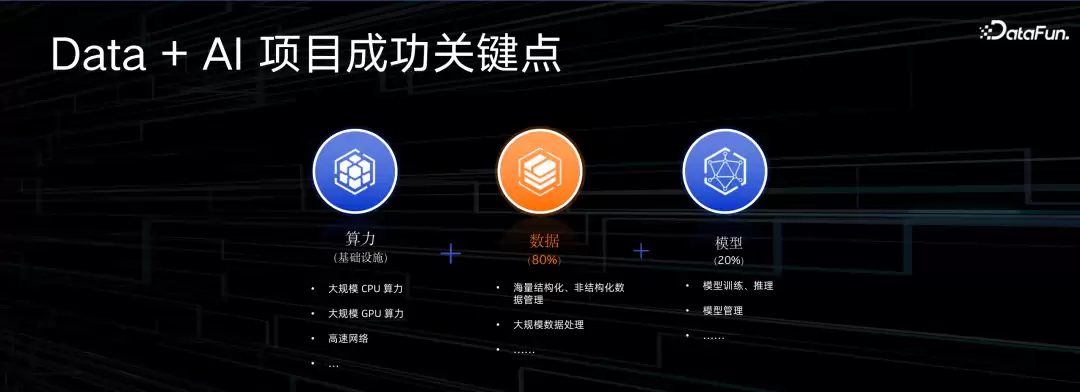 最近圈子里常说:成功的机器学习项目,80%靠数据加工效率,20%靠模型优化。算力当然不能少,但光有算力也不行。公式变成了算力+数据+模型。数据这块,又涉及结构化数据、非结构化数据、海量文件数据等等。
最近圈子里常说:成功的机器学习项目,80%靠数据加工效率,20%靠模型优化。算力当然不能少,但光有算力也不行。公式变成了算力+数据+模型。数据这块,又涉及结构化数据、非结构化数据、海量文件数据等等。
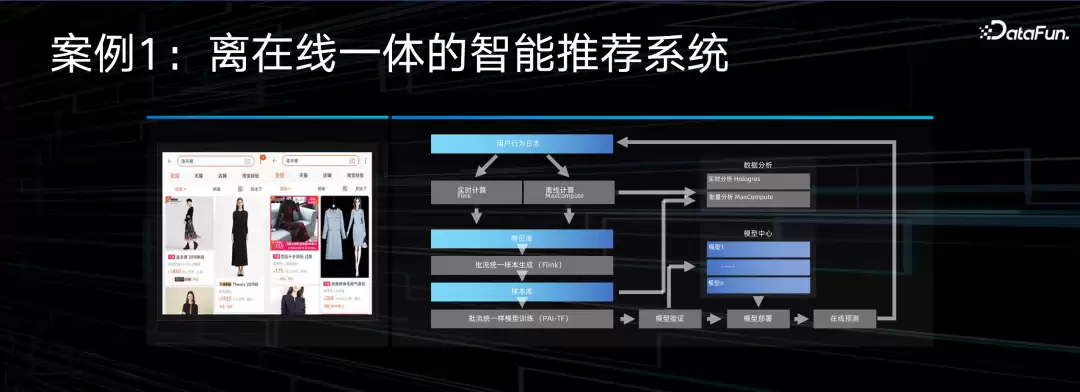 大数据AI一体化并不是新鲜课题,很多公司都在做的推荐系统就是个典型例子——通过数据做标签化、建特征库、训练推荐模型,模型版本不断迭代,AB test反复跑,调完再上线。有离线的,有在线的,也有离在线一体的。
上图展示的是一条典型实现路径,也是阿里云上最经典的方案:用Flink做标签实时加工,MaxCompute处理离线批量数据,PAI-TF做在线训练。训练出的模型上线后,还要实时采集指标、做多维度对比分析,这时候多数交互式分析场景会用到Hologres这样的OLAP工具,支持秒级快速查询。
大数据AI一体化并不是新鲜课题,很多公司都在做的推荐系统就是个典型例子——通过数据做标签化、建特征库、训练推荐模型,模型版本不断迭代,AB test反复跑,调完再上线。有离线的,有在线的,也有离在线一体的。
上图展示的是一条典型实现路径,也是阿里云上最经典的方案:用Flink做标签实时加工,MaxCompute处理离线批量数据,PAI-TF做在线训练。训练出的模型上线后,还要实时采集指标、做多维度对比分析,这时候多数交互式分析场景会用到Hologres这样的OLAP工具,支持秒级快速查询。
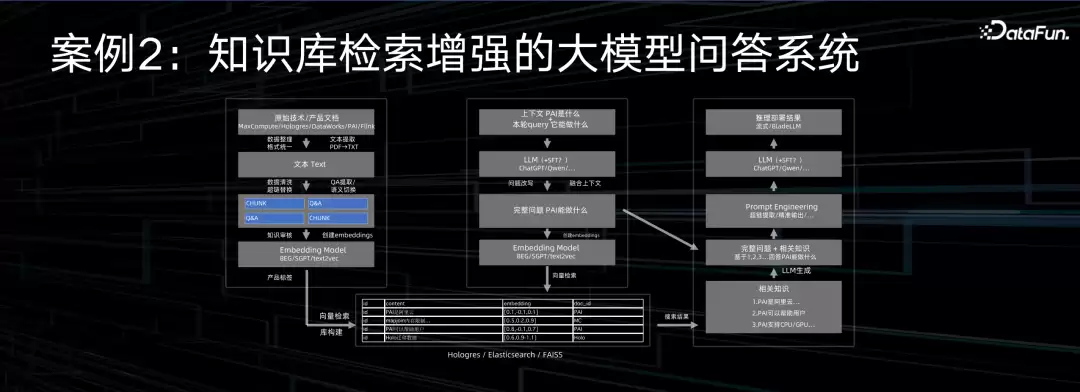 过去一年,大模型成了焦点。一个很典型的落地场景是——各家公司都在搭建自己的专属知识库。阿里云的网站也做了类似的事情:每个工单控制台有个提问按钮,以前背后是真人在服务,响应时间没保障;现在第一轮交给智能机器人,它能结合上下文和产品知识库,给出更相关、更准确、更及时的回复。
具体做法是:先把技术文档和产品使用文档做向量化处理,存进向量数据库。用户提问时,系统会对问题进行改写,让上下文更丰富,然后和向量数据库做近似度匹配,把最相关的上下文文档抽出来,连同问题一起喂给大模型,让大模型输出一份准确、可理解、有上下文、可解读的回答。这个流程里用到的技术包括文本处理、向量数据库、大模型等等。
过去一年,大模型成了焦点。一个很典型的落地场景是——各家公司都在搭建自己的专属知识库。阿里云的网站也做了类似的事情:每个工单控制台有个提问按钮,以前背后是真人在服务,响应时间没保障;现在第一轮交给智能机器人,它能结合上下文和产品知识库,给出更相关、更准确、更及时的回复。
具体做法是:先把技术文档和产品使用文档做向量化处理,存进向量数据库。用户提问时,系统会对问题进行改写,让上下文更丰富,然后和向量数据库做近似度匹配,把最相关的上下文文档抽出来,连同问题一起喂给大模型,让大模型输出一份准确、可理解、有上下文、可解读的回答。这个流程里用到的技术包括文本处理、向量数据库、大模型等等。
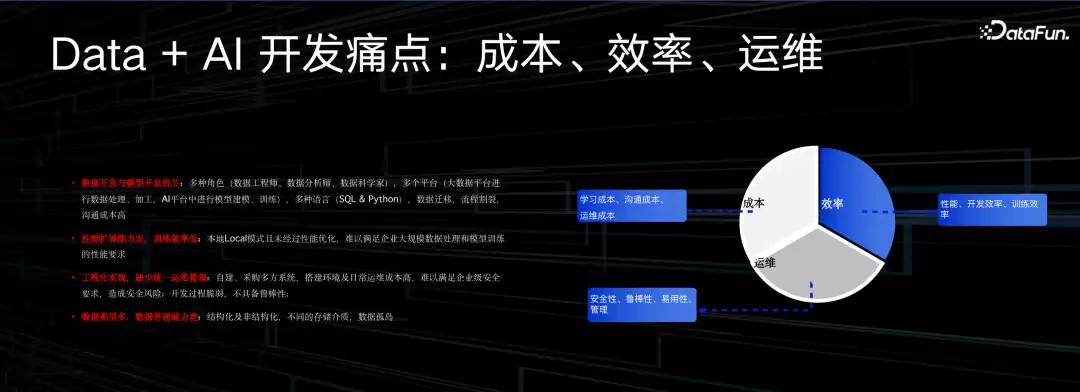 但真要落地一个这样的系统,并不容易。成本、效率、运维……方方面面都要考虑,踩坑的地方不少。
第一个问题是研发阶段割裂感很强。做数据和做AI的人,往往分属不同团队,用不同平台、不同开发语言,交流起来很费劲。数据同学喜欢搞数仓、搞结构化,聚焦元数据生产;AI同学通常基于Python在单机上开发,开发完跟数据就不再闭环交互,数据单向流动,造成很多割裂。
其次,效率也是个坎。大数据同学擅长处理分布式并行问题,AI同学更擅长在单机上把模型调参调到最优。但现在的关键已经不是模型要不要反复调优,而是数据处理的量要上几个数量级——这时候单机算子还能不能扛住新场景?很可能就遇到性能瓶颈。
第三个是工程化问题。过去公司的数据平台和AI平台,往往因为不同场景、不同目的采购了不同供应商,平台之间很难打通。很多公司买了多个系统,用不同账号、不同权限、由不同人运维,脆弱性一下子就暴露出来了。
最后是数据管理能力,这才是整个项目的核心。由于系统割裂,很难看到全局统一的数据治理能力。大数据平台和AI开发平台的元数据割裂,始终是个难啃的骨头。
但真要落地一个这样的系统,并不容易。成本、效率、运维……方方面面都要考虑,踩坑的地方不少。
第一个问题是研发阶段割裂感很强。做数据和做AI的人,往往分属不同团队,用不同平台、不同开发语言,交流起来很费劲。数据同学喜欢搞数仓、搞结构化,聚焦元数据生产;AI同学通常基于Python在单机上开发,开发完跟数据就不再闭环交互,数据单向流动,造成很多割裂。
其次,效率也是个坎。大数据同学擅长处理分布式并行问题,AI同学更擅长在单机上把模型调参调到最优。但现在的关键已经不是模型要不要反复调优,而是数据处理的量要上几个数量级——这时候单机算子还能不能扛住新场景?很可能就遇到性能瓶颈。
第三个是工程化问题。过去公司的数据平台和AI平台,往往因为不同场景、不同目的采购了不同供应商,平台之间很难打通。很多公司买了多个系统,用不同账号、不同权限、由不同人运维,脆弱性一下子就暴露出来了。
最后是数据管理能力,这才是整个项目的核心。由于系统割裂,很难看到全局统一的数据治理能力。大数据平台和AI开发平台的元数据割裂,始终是个难啃的骨头。
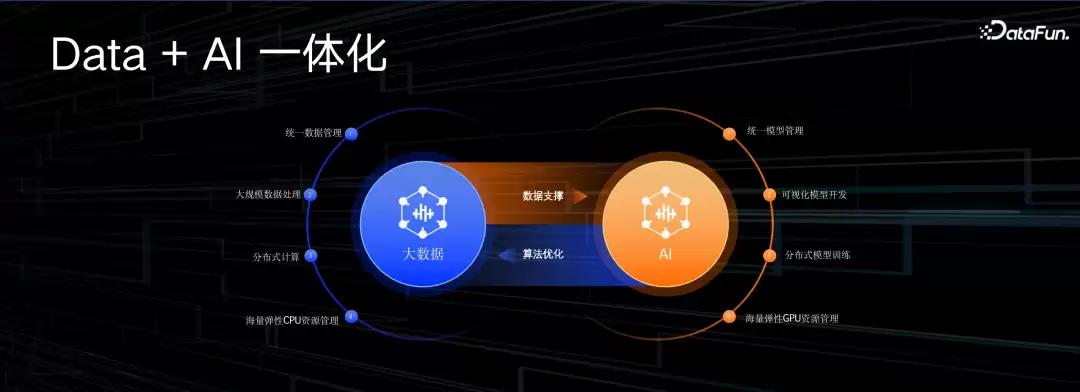 大数据AI一体化,就是要解决这些问题。大数据平台需要做好统一元数据管理、大规模数据处理、分布式计算算子,还要提供丰富、海量、弹性的计算资源。AI平台则需要统一模型管理、可视化建模流程、分布式训练环境,以及丰富的GPU资源。大数据和AI结合,本质上是互相支撑——大数据平台为AI提供数据底座,AI平台则通过智能算法让数据平台更好用。下面就来聊聊阿里云在这两方面的具体工作。
---
## 02 阿里云大数据AI一体化架构演进
大数据AI一体化,就是要解决这些问题。大数据平台需要做好统一元数据管理、大规模数据处理、分布式计算算子,还要提供丰富、海量、弹性的计算资源。AI平台则需要统一模型管理、可视化建模流程、分布式训练环境,以及丰富的GPU资源。大数据和AI结合,本质上是互相支撑——大数据平台为AI提供数据底座,AI平台则通过智能算法让数据平台更好用。下面就来聊聊阿里云在这两方面的具体工作。
---
## 02 阿里云大数据AI一体化架构演进
 上图是阿里云提供的整体解决方案,从底层的资源层,到中间的大数据AI一体化PaaS平台服务层,再到模型服务层和应用层。大部分应用和模型来自合作伙伴,蓝色部分是阿里云原生产品和服务。我们今天重点说数据平台的部分——在丰富的计算资源之上,提供一个易用、可扩展的数据处理平台,同时和AI机器学习平台PAI集成打通。
上图是阿里云提供的整体解决方案,从底层的资源层,到中间的大数据AI一体化PaaS平台服务层,再到模型服务层和应用层。大部分应用和模型来自合作伙伴,蓝色部分是阿里云原生产品和服务。我们今天重点说数据平台的部分——在丰富的计算资源之上,提供一个易用、可扩展的数据处理平台,同时和AI机器学习平台PAI集成打通。
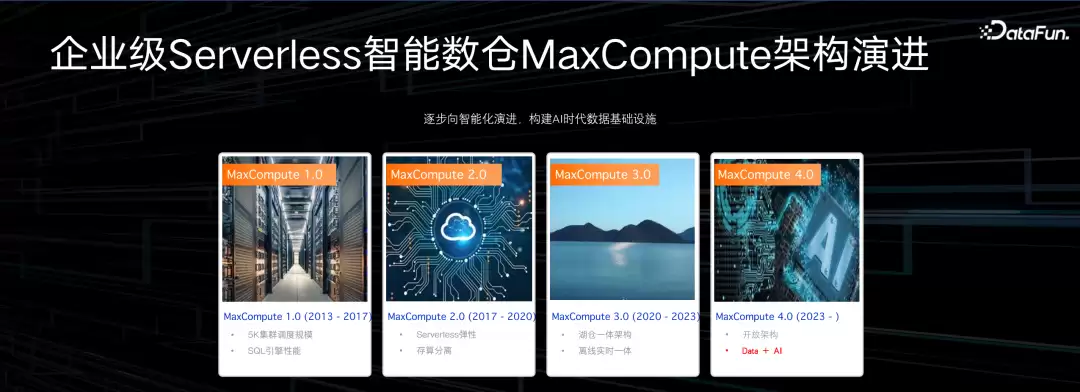 数据平台的核心是MaxCompute,以前叫ODPS(Open Data Processing Service)。它包含了两个主要引擎:离线数仓MaxCompute和实时数仓Hologres。MaxCompute是一款比Spark更易用、执行效率更高、企业级能力更丰富的大数据平台。
MaxCompute经历了15年迭代,不同阶段重点解决的问题不一样。最早从09年开始做,是因为阿里集团内部有海量数据需要分析,既要替换Oracle降低成本,又要很强的扩展性来支撑业务快速发展。当时做了5K项目——单集群超过5000个节点,解决了扩展性问题,从此数据量不再是瓶颈。
17年之后开始做公有云服务,做Serverless,这其实是运维方式的本质性变革。背后的挑战非常大:升级怎么做到业务无感、无中断?流量分配怎么均衡?灰度回滚怎么做?Serverless背后是租户体系的改革——一个集群服务一个Region的所有用户、所有类型的作业。
第三个阶段是湖仓一体的改造。这时候发现结构化数据已经不够用了,大量非结构化、半结构化数据需要管理和加工,很多第三方Hadoop集群需要托管,数据治理也需要更有质量。我们提出了湖仓一体架构,把基于开放存储、开放格式的数据统一纳管到MaxCompute的元数据体系下。同时还做了离线实时一体——让在线交互式分析引擎Hologres和离线数据加工引擎MaxCompute之间的元数据和数据集成打通。
从2023年开始进入下一个阶段。这个阶段的一个特征是开放架构——我们希望数仓是开放的、多元的。在数仓存储层提供了MaxCompute Storage API,第三方的计算引擎可以直接以原生、底层、高吞吐的方式访问数仓里的数据。过去数仓是为性能优化设计的,但今天不再封闭。同时我们也提出了Data+AI的解决方案,稍后会进一步解析。
数据平台的核心是MaxCompute,以前叫ODPS(Open Data Processing Service)。它包含了两个主要引擎:离线数仓MaxCompute和实时数仓Hologres。MaxCompute是一款比Spark更易用、执行效率更高、企业级能力更丰富的大数据平台。
MaxCompute经历了15年迭代,不同阶段重点解决的问题不一样。最早从09年开始做,是因为阿里集团内部有海量数据需要分析,既要替换Oracle降低成本,又要很强的扩展性来支撑业务快速发展。当时做了5K项目——单集群超过5000个节点,解决了扩展性问题,从此数据量不再是瓶颈。
17年之后开始做公有云服务,做Serverless,这其实是运维方式的本质性变革。背后的挑战非常大:升级怎么做到业务无感、无中断?流量分配怎么均衡?灰度回滚怎么做?Serverless背后是租户体系的改革——一个集群服务一个Region的所有用户、所有类型的作业。
第三个阶段是湖仓一体的改造。这时候发现结构化数据已经不够用了,大量非结构化、半结构化数据需要管理和加工,很多第三方Hadoop集群需要托管,数据治理也需要更有质量。我们提出了湖仓一体架构,把基于开放存储、开放格式的数据统一纳管到MaxCompute的元数据体系下。同时还做了离线实时一体——让在线交互式分析引擎Hologres和离线数据加工引擎MaxCompute之间的元数据和数据集成打通。
从2023年开始进入下一个阶段。这个阶段的一个特征是开放架构——我们希望数仓是开放的、多元的。在数仓存储层提供了MaxCompute Storage API,第三方的计算引擎可以直接以原生、底层、高吞吐的方式访问数仓里的数据。过去数仓是为性能优化设计的,但今天不再封闭。同时我们也提出了Data+AI的解决方案,稍后会进一步解析。
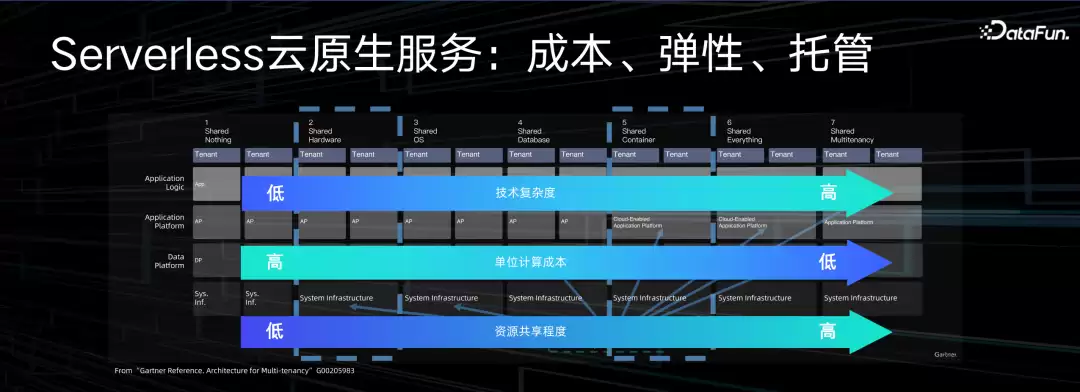 MaxCompute的核心形态是完全Serverless。上图来自Gartner的分析报告,Serverless分很多级别,体现在资源共享力度的不同。从最原始的机器资源共享,到操作系统层面、容器层面、应用层面、租户层面的共享——每提高一层共享力度,对服务提供方的技术难度是指数级提升,但对用户来说收益越来越大。资源复用得好,整个服务的成本就能降得足够低,给用户更便宜的计算服务。当然,这对资源隔离要求更高,系统升级也更难。
MaxCompute从设计之初就是Serverless定位——只有把运维效率解决好、资源利用率提上去,才能提供有竞争力的数据计算服务。除了成本,另一个好处是弹性。尤其机器学习场景,很多时候只有部分时段有大量资源需求,如果采购一台机器大部分时间闲置,就是巨大浪费。所以机器学习对Serverless的诉求非常强。
MaxCompute的核心形态是完全Serverless。上图来自Gartner的分析报告,Serverless分很多级别,体现在资源共享力度的不同。从最原始的机器资源共享,到操作系统层面、容器层面、应用层面、租户层面的共享——每提高一层共享力度,对服务提供方的技术难度是指数级提升,但对用户来说收益越来越大。资源复用得好,整个服务的成本就能降得足够低,给用户更便宜的计算服务。当然,这对资源隔离要求更高,系统升级也更难。
MaxCompute从设计之初就是Serverless定位——只有把运维效率解决好、资源利用率提上去,才能提供有竞争力的数据计算服务。除了成本,另一个好处是弹性。尤其机器学习场景,很多时候只有部分时段有大量资源需求,如果采购一台机器大部分时间闲置,就是巨大浪费。所以机器学习对Serverless的诉求非常强。
 接下来聊聊Data+AI的解决方案。MaxCompute针对AI场景的创新,主要体现在这几个方面:
- 数据管理层:数仓擅长处理结构化数据,但机器学习场景有大量非结构化数据、文件数据、图像数据等。我们在非结构化数据管理上做了创新,引入了Object Table这种新型表类型。
- 计算框架:推出了面向Python开发的分布式执行框架MaxFrame。过去数据平台主要用SQL接口开发,但数据科学家最习惯用Python和各类Python开源工具。通过MaxFrame,MaxCompute提供了SQL+Python双引擎能力,Python成为数据平台的一级开发语言。
- 交互式Notebook开发环境:这是AI同学非常喜欢的开发环境,可以在里面做交互式验证和作业分享。
- 镜像管理:Python开发中版本管理、镜像打包等一系列工程问题,也是效率的关键。
接下来聊聊Data+AI的解决方案。MaxCompute针对AI场景的创新,主要体现在这几个方面:
- 数据管理层:数仓擅长处理结构化数据,但机器学习场景有大量非结构化数据、文件数据、图像数据等。我们在非结构化数据管理上做了创新,引入了Object Table这种新型表类型。
- 计算框架:推出了面向Python开发的分布式执行框架MaxFrame。过去数据平台主要用SQL接口开发,但数据科学家最习惯用Python和各类Python开源工具。通过MaxFrame,MaxCompute提供了SQL+Python双引擎能力,Python成为数据平台的一级开发语言。
- 交互式Notebook开发环境:这是AI同学非常喜欢的开发环境,可以在里面做交互式验证和作业分享。
- 镜像管理:Python开发中版本管理、镜像打包等一系列工程问题,也是效率的关键。
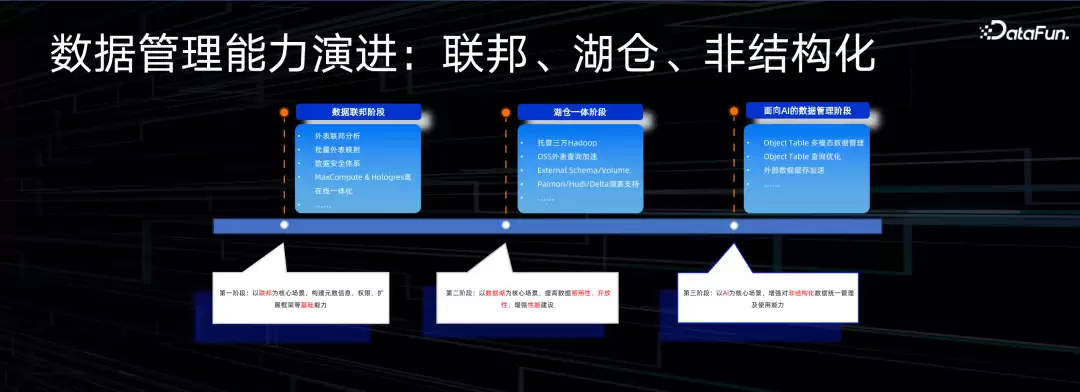 数据管理能力的演进,可以分成几个阶段。
第一阶段解决联邦问题。当数据交互双方使用不同引擎时,数据能不能兼容?能不能不搬迁就实现联邦查询?我们希望以联邦为中心,打通元数据管理,给用户统一的元数据视图和权限管理。
第二阶段,光有联邦还不够,还希望不同存储格式能放在湖上,提供一份数据多引擎的能力。所以做了湖仓一体,提高数据易用性,提供原生查询和元数据管理能力。
第三阶段,越来越多用户提出非结构化数据管理的需求。大量非结构化数据作为输入,给Python库做向量化转化,但这些文件背后缺乏元数据管理能力,也很难做分布式计算。因此我们做了Object Table来解决这个问题。
Object Table是一种新的表类型,专门处理非结构化数据。它存储的是非结构化数据的元数据,而不是数据本身——包括文件路径、文件名、文件大小、更新时间等,还有不少可扩展的tag值。
基于这些元数据,可以做很多提升开发效率的事情。比如有1000万个PDF文件,希望平台并行处理这些文件、从中抽取文本。一种简单做法是一个文件启动一个进程,但1000万个文件就要启动1000万个进程,调度开销太大。如果有些文件可以跳过——比如太小的不打开、很久没动过的可以忽略——那有很多需要对元数据过滤的场景。过去没有元数据信息很难做,现在表里有了元信息就可以处理。
还有并行化处理的问题。一个进程处理一个文件,还是一个进程处理10个文件?对吞吐的影响非常大。过去没有元信息很难做,现在有了元信息,worker可以判断:假设一个worker能处理100MB数据,就可以把100MB数据以批量的形式输入给一个进程worker并行处理,整体吞吐量会有本质性提升。这也是工程化中很常见的做法。
除了元数据管理,还有很多性能优化,比如海量小文件、碎片文件处理有几十倍的提效,单一大文件的IO访问也做了提效。
数据管理能力的演进,可以分成几个阶段。
第一阶段解决联邦问题。当数据交互双方使用不同引擎时,数据能不能兼容?能不能不搬迁就实现联邦查询?我们希望以联邦为中心,打通元数据管理,给用户统一的元数据视图和权限管理。
第二阶段,光有联邦还不够,还希望不同存储格式能放在湖上,提供一份数据多引擎的能力。所以做了湖仓一体,提高数据易用性,提供原生查询和元数据管理能力。
第三阶段,越来越多用户提出非结构化数据管理的需求。大量非结构化数据作为输入,给Python库做向量化转化,但这些文件背后缺乏元数据管理能力,也很难做分布式计算。因此我们做了Object Table来解决这个问题。
Object Table是一种新的表类型,专门处理非结构化数据。它存储的是非结构化数据的元数据,而不是数据本身——包括文件路径、文件名、文件大小、更新时间等,还有不少可扩展的tag值。
基于这些元数据,可以做很多提升开发效率的事情。比如有1000万个PDF文件,希望平台并行处理这些文件、从中抽取文本。一种简单做法是一个文件启动一个进程,但1000万个文件就要启动1000万个进程,调度开销太大。如果有些文件可以跳过——比如太小的不打开、很久没动过的可以忽略——那有很多需要对元数据过滤的场景。过去没有元数据信息很难做,现在表里有了元信息就可以处理。
还有并行化处理的问题。一个进程处理一个文件,还是一个进程处理10个文件?对吞吐的影响非常大。过去没有元信息很难做,现在有了元信息,worker可以判断:假设一个worker能处理100MB数据,就可以把100MB数据以批量的形式输入给一个进程worker并行处理,整体吞吐量会有本质性提升。这也是工程化中很常见的做法。
除了元数据管理,还有很多性能优化,比如海量小文件、碎片文件处理有几十倍的提效,单一大文件的IO访问也做了提效。
 第二大创新是MaxFrame,把Python的开发体验做到原生化。我们希望给用户的心智是:在单机上本地开发的Python程序,基于主流的Pandas接口写的,可以100%透明地迁移到MaxFrame平台上,享受平台上可扩展的计算算力。MaxFrame提供并行化计算能力。
用户写的Python code并不是针对分布式场景,而是单机场景。但数据输入来自MaxCompute表,MaxFrame会将算子并行化,运行在不同分布式节点上。这意味着以前在单机上跑几十个小时的Python作业,现在可能只需要几十分钟甚至更快。MaxFrame的核心理念就是:让用Pandas接口开发的数据分析、数据加工程序,能无缝、透明地迁移到大数据平台上。同时平台与MaxCompute底层数据原生打通,可以高吞吐、高效率地访问所有数据——不只是读,也包括写。
第二大创新是MaxFrame,把Python的开发体验做到原生化。我们希望给用户的心智是:在单机上本地开发的Python程序,基于主流的Pandas接口写的,可以100%透明地迁移到MaxFrame平台上,享受平台上可扩展的计算算力。MaxFrame提供并行化计算能力。
用户写的Python code并不是针对分布式场景,而是单机场景。但数据输入来自MaxCompute表,MaxFrame会将算子并行化,运行在不同分布式节点上。这意味着以前在单机上跑几十个小时的Python作业,现在可能只需要几十分钟甚至更快。MaxFrame的核心理念就是:让用Pandas接口开发的数据分析、数据加工程序,能无缝、透明地迁移到大数据平台上。同时平台与MaxCompute底层数据原生打通,可以高吞吐、高效率地访问所有数据——不只是读,也包括写。
 上图左侧是Pandas算子——表连接、关联、过滤、聚合等,几乎所有常见的数据分析Pandas算子都支持。右边是机器学习平台数据处理部分的55个算子——大量文本处理、文本过滤、文本去重、文本计数等,都是MaxFrame原生支持的。这些算子背后都做了性能和可扩展性支持,用起来非常简单。
上图左侧是Pandas算子——表连接、关联、过滤、聚合等,几乎所有常见的数据分析Pandas算子都支持。右边是机器学习平台数据处理部分的55个算子——大量文本处理、文本过滤、文本去重、文本计数等,都是MaxFrame原生支持的。这些算子背后都做了性能和可扩展性支持,用起来非常简单。
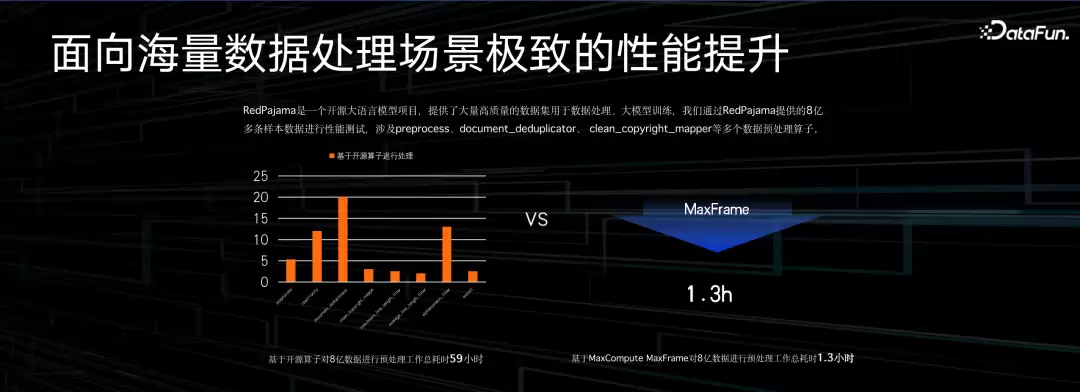 这里有个对比例子。左侧是开源的RedPajama,在大模型场景下,端到端从数据采集加工到产出结果,七八个环节,每个环节有不同算子。以前单机运行,跑完整个流程需要59个小时。转成MaxFrame之后,仅用1.3小时就跑完了,效率提升非常明显。
这里有个对比例子。左侧是开源的RedPajama,在大模型场景下,端到端从数据采集加工到产出结果,七八个环节,每个环节有不同算子。以前单机运行,跑完整个流程需要59个小时。转成MaxFrame之后,仅用1.3小时就跑完了,效率提升非常明显。
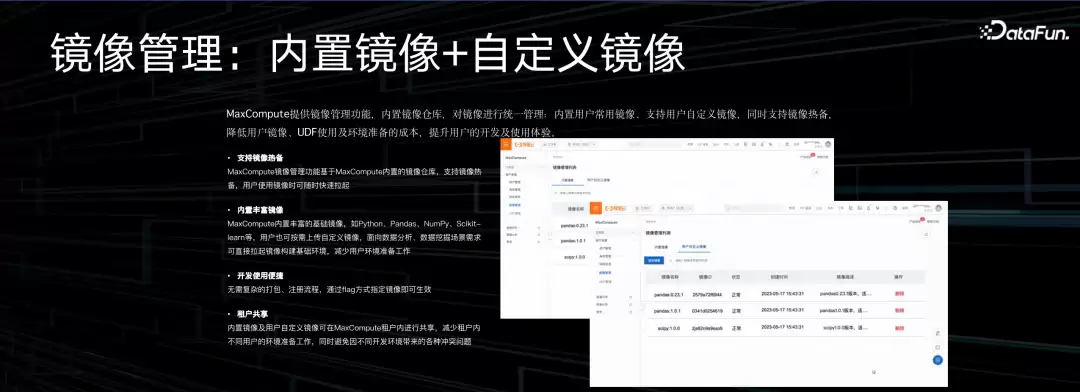 Python开发非常依赖版本管理和镜像管理。一份作业里可能依赖几十个不同的library。所以我们做了一套镜像管理方案,包含内置镜像和自定义镜像。内置镜像把很多主流的常见数据分析、数据加工用到的Python library都内置了,用户直接引用就行。
Python开发非常依赖版本管理和镜像管理。一份作业里可能依赖几十个不同的library。所以我们做了一套镜像管理方案,包含内置镜像和自定义镜像。内置镜像把很多主流的常见数据分析、数据加工用到的Python library都内置了,用户直接引用就行。
 讲完加工环节,再聊聊数据服务环节,以向量检索服务为例。这两年向量数据库特别火,但业界一直有个困惑:每家公司是应该采购一个专属的向量数据库,还是选一款带有向量扩展能力的通用分析数据库?我们看到主流的云厂商大多选了后者——在数据库里增加向量化检索能力,和原生的OLAP能力结合起来,场景更丰富、开发更易用,用户门槛也更低。阿里云也是这个思路。
Hologres是一款分布式高性能OLAP引擎。2020年,Hologres与达摩院合作,把高性能的向量化引擎Proxima集成到SQL引擎中,提供SQL查询接口。Proxima性能优异、精度高、计算效率快,内置多种检索算法。
Proxima和Hologres结合在一起,能把Hologres的强大性能充分发挥出来。Hologres面向高并发、低延迟场景设计,性能可以做到毫秒级响应。同时易用性也很好——不需要学新接口,直接用SQL,数据同学非常容易上手。
讲完加工环节,再聊聊数据服务环节,以向量检索服务为例。这两年向量数据库特别火,但业界一直有个困惑:每家公司是应该采购一个专属的向量数据库,还是选一款带有向量扩展能力的通用分析数据库?我们看到主流的云厂商大多选了后者——在数据库里增加向量化检索能力,和原生的OLAP能力结合起来,场景更丰富、开发更易用,用户门槛也更低。阿里云也是这个思路。
Hologres是一款分布式高性能OLAP引擎。2020年,Hologres与达摩院合作,把高性能的向量化引擎Proxima集成到SQL引擎中,提供SQL查询接口。Proxima性能优异、精度高、计算效率快,内置多种检索算法。
Proxima和Hologres结合在一起,能把Hologres的强大性能充分发挥出来。Hologres面向高并发、低延迟场景设计,性能可以做到毫秒级响应。同时易用性也很好——不需要学新接口,直接用SQL,数据同学非常容易上手。
 向量这件事其实不复杂——把文本、图片等转化为向量数组,存在数据库表的一个字段里,Hologres在底层自动构建各类向量索引。向量计算广泛应用在推荐引擎、大模型推理等场景。
向量这件事其实不复杂——把文本、图片等转化为向量数组,存在数据库表的一个字段里,Hologres在底层自动构建各类向量索引。向量计算广泛应用在推荐引擎、大模型推理等场景。
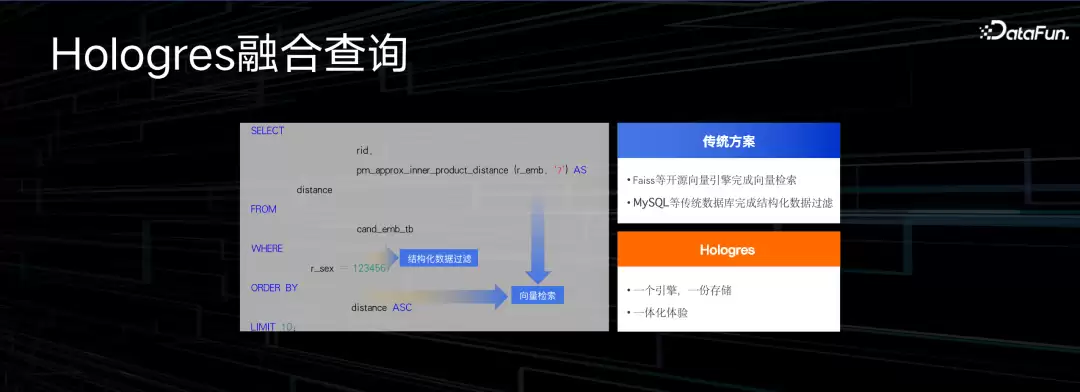 数据库和向量融合的好处在哪里?以前向量引擎只能做向量查询,数据库只能做结构化查询。现在两者合在一起,既可以做结构化过滤,也可以做向量化检索。写SQL语句变得很简单——很多以前必须在专业向量数据库里做的事,现在一个通用数据库就搞定了。一个SQL就能实现向量检索、过滤、排序、去重等操作。真正实现了“一个引擎、一份数据、多个场景”。
数据库和向量融合的好处在哪里?以前向量引擎只能做向量查询,数据库只能做结构化查询。现在两者合在一起,既可以做结构化过滤,也可以做向量化检索。写SQL语句变得很简单——很多以前必须在专业向量数据库里做的事,现在一个通用数据库就搞定了。一个SQL就能实现向量检索、过滤、排序、去重等操作。真正实现了“一个引擎、一份数据、多个场景”。
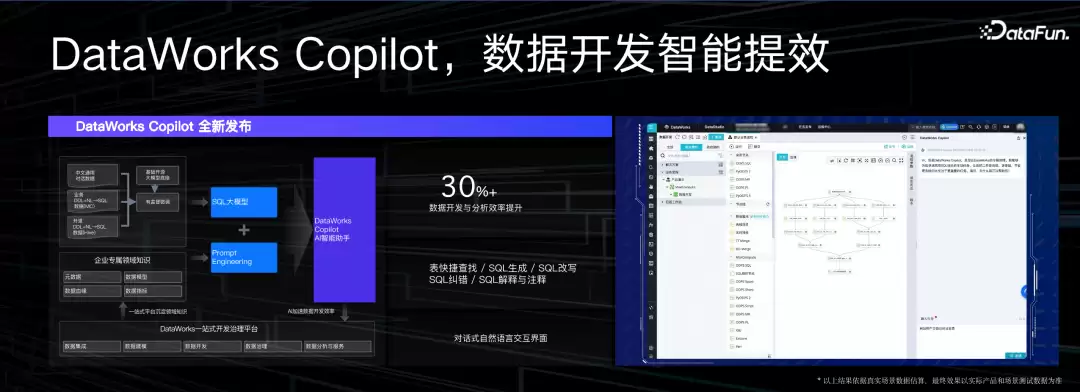 以上说的是数据平台如何为AI提供支持,是Data for AI的视角。反过来,AI平台怎么让数据平台变得更好用?今天所有数据分析都在从BI演化到BI+AI的场景。
Copilot从去年开始成为主流,NL2SQL是常见场景——帮用户写SQL、找表、更容易地诊断SQL错误。阿里云推出了DataWorks Copilot,工程师把大量SQL语料喂给Copilot模型,希望产出好用的、更智能的SQL Copilot能力。
以上说的是数据平台如何为AI提供支持,是Data for AI的视角。反过来,AI平台怎么让数据平台变得更好用?今天所有数据分析都在从BI演化到BI+AI的场景。
Copilot从去年开始成为主流,NL2SQL是常见场景——帮用户写SQL、找表、更容易地诊断SQL错误。阿里云推出了DataWorks Copilot,工程师把大量SQL语料喂给Copilot模型,希望产出好用的、更智能的SQL Copilot能力。
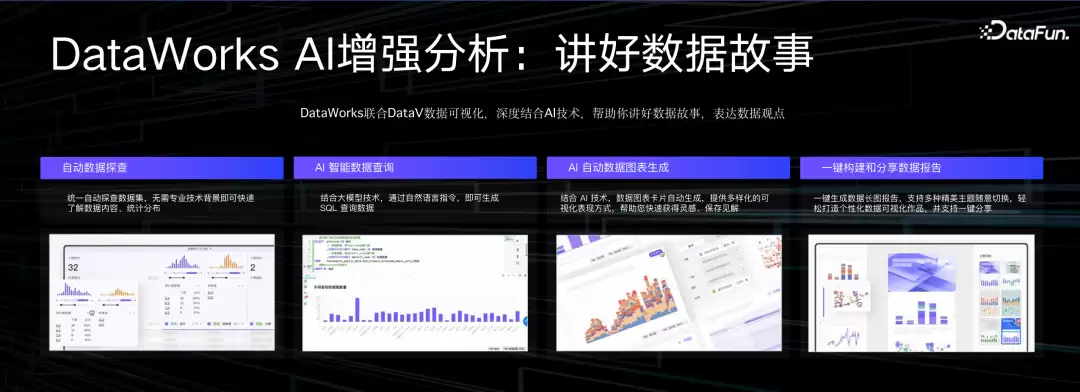 除了写SQL的开发阶段,分析阶段更为重要。DataWorks和DataV也在合作实现增强分析——过去以经验为主的分析范式,正在转化为由机器做推断。增强分析可以自动生成各种洞察、不同的报表、不同的视图、不同的看数角度。
---
## 03 Data+AI场景实践分享
最后通过一个具体场景,来看看数据平台怎么用。
除了写SQL的开发阶段,分析阶段更为重要。DataWorks和DataV也在合作实现增强分析——过去以经验为主的分析范式,正在转化为由机器做推断。增强分析可以自动生成各种洞察、不同的报表、不同的视图、不同的看数角度。
---
## 03 Data+AI场景实践分享
最后通过一个具体场景,来看看数据平台怎么用。
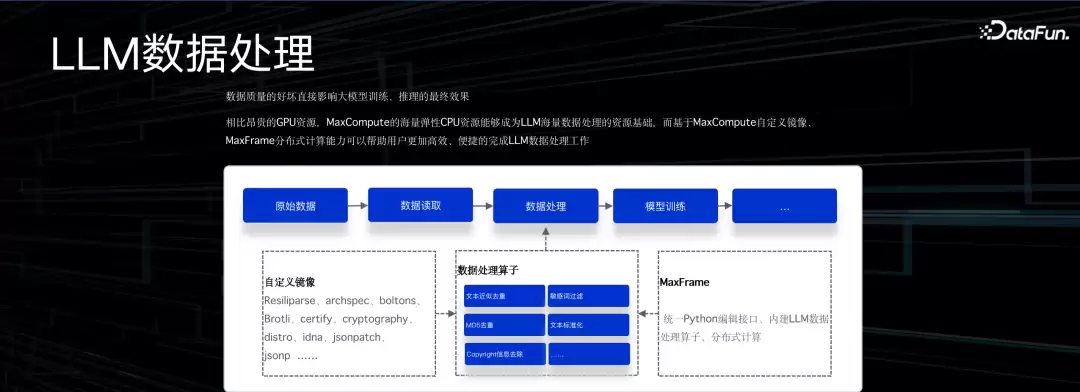 这是通义大模型的一个加工场景的简化版本,主要在处理文本去重。核心环节包括数据采集、读取、处理到模型训练,中间有很多小环节——文本去重、敏感词过滤、版权删除、文本标准化等,依赖了很多不同的Python library。
文本去重的基本流程是:先做分词,然后计算哈希值,再求哈希近邻。
我们的做法是:先把依赖镜像做好管理——这个镜像里用户依赖了很多第三方library,不同Python版本、不同library版本,大家需要共享的开发环境。所以第一步是做镜像管理,把这些依赖镜像做成团队内可共享的。
之后是开发环节。右侧是一段demo代码,总共不超过100行。初始化依赖4-5行代码——初始化框架资源、身份认证,然后几行代码做数据过滤,再几行做分词,背后用的是Pandas开发接口,里面有各种数据转换逻辑。这100行代码,可以跑在几乎无限扩展的计算平台上。我们希望的效果是:用小代码快速迭代的方式,在规模化计算平台上处理规模化问题。至于分布式怎么调度、怎么容错、数据怎么切分、怎么做并行化——大量类似的工程细节都由底层大数据平台完成,效率提升非常明显。
如果不喜欢写代码,也可以用拖拽的方式。平台提供了可拖拽的pipeline组合方式,把整个计算流程中不同算子拖拽组合在一起就行。
从通用场景来看,绝大部分性能提升在70%到90%之间,数据量越大,提升越明显。同时环境准备方面,我们反复强调工程一定要提效率——效率不一定只是计算效率,开发、调试、环境准备往往会占用大量精力。我们希望通过平台来减少这部分工作量,实际效果也相当不错。
最后总结一下大数据AI一体化的工作。这次分享没有专门讲大数据做什么,也没有专门讲AI做什么,更多是在讨论二者如何更好地集成。阿里云大数据平台MaxCompute做了非结构化元数据管理,支持Python开发语言,让Python可以跑在并行化运行环境里,还有大量IO优化、调度优化,提供了Notebook交互式开发环境和镜像管理能力。这些工程化能力实现之后,大数据和AI之间实现了数据一体化、权限一体化和开发界面一体化。通过这些一体化,可以让AI同学更熟悉数据平台,也让数据平台同学能更快上手AI应用。这正是我们希望实现的效果。
**以上就是本次分享的内容,谢谢大家。**
这是通义大模型的一个加工场景的简化版本,主要在处理文本去重。核心环节包括数据采集、读取、处理到模型训练,中间有很多小环节——文本去重、敏感词过滤、版权删除、文本标准化等,依赖了很多不同的Python library。
文本去重的基本流程是:先做分词,然后计算哈希值,再求哈希近邻。
我们的做法是:先把依赖镜像做好管理——这个镜像里用户依赖了很多第三方library,不同Python版本、不同library版本,大家需要共享的开发环境。所以第一步是做镜像管理,把这些依赖镜像做成团队内可共享的。
之后是开发环节。右侧是一段demo代码,总共不超过100行。初始化依赖4-5行代码——初始化框架资源、身份认证,然后几行代码做数据过滤,再几行做分词,背后用的是Pandas开发接口,里面有各种数据转换逻辑。这100行代码,可以跑在几乎无限扩展的计算平台上。我们希望的效果是:用小代码快速迭代的方式,在规模化计算平台上处理规模化问题。至于分布式怎么调度、怎么容错、数据怎么切分、怎么做并行化——大量类似的工程细节都由底层大数据平台完成,效率提升非常明显。
如果不喜欢写代码,也可以用拖拽的方式。平台提供了可拖拽的pipeline组合方式,把整个计算流程中不同算子拖拽组合在一起就行。
从通用场景来看,绝大部分性能提升在70%到90%之间,数据量越大,提升越明显。同时环境准备方面,我们反复强调工程一定要提效率——效率不一定只是计算效率,开发、调试、环境准备往往会占用大量精力。我们希望通过平台来减少这部分工作量,实际效果也相当不错。
最后总结一下大数据AI一体化的工作。这次分享没有专门讲大数据做什么,也没有专门讲AI做什么,更多是在讨论二者如何更好地集成。阿里云大数据平台MaxCompute做了非结构化元数据管理,支持Python开发语言,让Python可以跑在并行化运行环境里,还有大量IO优化、调度优化,提供了Notebook交互式开发环境和镜像管理能力。这些工程化能力实现之后,大数据和AI之间实现了数据一体化、权限一体化和开发界面一体化。通过这些一体化,可以让AI同学更熟悉数据平台,也让数据平台同学能更快上手AI应用。这正是我们希望实现的效果。
**以上就是本次分享的内容,谢谢大家。**
随着大模型这类项目逐渐成为主流,机器学习的开发范式正在从“以模型为中心”转向“以数据为中心”。过去算力贵,处理大规模数据成本太高,大家只能在模型上反复调参,跟过拟合、欠拟合死磕。那时候训练质量高度依赖标注数据的准确性,而标注成本可不是个小数目。到了Transformer模型出现之后,工程师的精力重心开始从调模型转向提数据质量——不再完全依赖标注数据了,数据平台的效率反而成了整条流水线的关键瓶颈。
最近圈子里常说:成功的机器学习项目,80%靠数据加工效率,20%靠模型优化。算力当然不能少,但光有算力也不行。公式变成了算力+数据+模型。数据这块,又涉及结构化数据、非结构化数据、海量文件数据等等。
大数据AI一体化并不是新鲜课题,很多公司都在做的推荐系统就是个典型例子——通过数据做标签化、建特征库、训练推荐模型,模型版本不断迭代,AB test反复跑,调完再上线。有离线的,有在线的,也有离在线一体的。
上图展示的是一条典型实现路径,也是阿里云上最经典的方案:用Flink做标签实时加工,MaxCompute处理离线批量数据,PAI-TF做在线训练。训练出的模型上线后,还要实时采集指标、做多维度对比分析,这时候多数交互式分析场景会用到Hologres这样的OLAP工具,支持秒级快速查询。
过去一年,大模型成了焦点。一个很典型的落地场景是——各家公司都在搭建自己的专属知识库。阿里云的网站也做了类似的事情:每个工单控制台有个提问按钮,以前背后是真人在服务,响应时间没保障;现在第一轮交给智能机器人,它能结合上下文和产品知识库,给出更相关、更准确、更及时的回复。
具体做法是:先把技术文档和产品使用文档做向量化处理,存进向量数据库。用户提问时,系统会对问题进行改写,让上下文更丰富,然后和向量数据库做近似度匹配,把最相关的上下文文档抽出来,连同问题一起喂给大模型,让大模型输出一份准确、可理解、有上下文、可解读的回答。这个流程里用到的技术包括文本处理、向量数据库、大模型等等。
但真要落地一个这样的系统,并不容易。成本、效率、运维……方方面面都要考虑,踩坑的地方不少。
第一个问题是研发阶段割裂感很强。做数据和做AI的人,往往分属不同团队,用不同平台、不同开发语言,交流起来很费劲。数据同学喜欢搞数仓、搞结构化,聚焦元数据生产;AI同学通常基于Python在单机上开发,开发完跟数据就不再闭环交互,数据单向流动,造成很多割裂。
其次,效率也是个坎。大数据同学擅长处理分布式并行问题,AI同学更擅长在单机上把模型调参调到最优。但现在的关键已经不是模型要不要反复调优,而是数据处理的量要上几个数量级——这时候单机算子还能不能扛住新场景?很可能就遇到性能瓶颈。
第三个是工程化问题。过去公司的数据平台和AI平台,往往因为不同场景、不同目的采购了不同供应商,平台之间很难打通。很多公司买了多个系统,用不同账号、不同权限、由不同人运维,脆弱性一下子就暴露出来了。
最后是数据管理能力,这才是整个项目的核心。由于系统割裂,很难看到全局统一的数据治理能力。大数据平台和AI开发平台的元数据割裂,始终是个难啃的骨头。
大数据AI一体化,就是要解决这些问题。大数据平台需要做好统一元数据管理、大规模数据处理、分布式计算算子,还要提供丰富、海量、弹性的计算资源。AI平台则需要统一模型管理、可视化建模流程、分布式训练环境,以及丰富的GPU资源。大数据和AI结合,本质上是互相支撑——大数据平台为AI提供数据底座,AI平台则通过智能算法让数据平台更好用。下面就来聊聊阿里云在这两方面的具体工作。
---
## 02 阿里云大数据AI一体化架构演进
上图是阿里云提供的整体解决方案,从底层的资源层,到中间的大数据AI一体化PaaS平台服务层,再到模型服务层和应用层。大部分应用和模型来自合作伙伴,蓝色部分是阿里云原生产品和服务。我们今天重点说数据平台的部分——在丰富的计算资源之上,提供一个易用、可扩展的数据处理平台,同时和AI机器学习平台PAI集成打通。
数据平台的核心是MaxCompute,以前叫ODPS(Open Data Processing Service)。它包含了两个主要引擎:离线数仓MaxCompute和实时数仓Hologres。MaxCompute是一款比Spark更易用、执行效率更高、企业级能力更丰富的大数据平台。
MaxCompute经历了15年迭代,不同阶段重点解决的问题不一样。最早从09年开始做,是因为阿里集团内部有海量数据需要分析,既要替换Oracle降低成本,又要很强的扩展性来支撑业务快速发展。当时做了5K项目——单集群超过5000个节点,解决了扩展性问题,从此数据量不再是瓶颈。
17年之后开始做公有云服务,做Serverless,这其实是运维方式的本质性变革。背后的挑战非常大:升级怎么做到业务无感、无中断?流量分配怎么均衡?灰度回滚怎么做?Serverless背后是租户体系的改革——一个集群服务一个Region的所有用户、所有类型的作业。
第三个阶段是湖仓一体的改造。这时候发现结构化数据已经不够用了,大量非结构化、半结构化数据需要管理和加工,很多第三方Hadoop集群需要托管,数据治理也需要更有质量。我们提出了湖仓一体架构,把基于开放存储、开放格式的数据统一纳管到MaxCompute的元数据体系下。同时还做了离线实时一体——让在线交互式分析引擎Hologres和离线数据加工引擎MaxCompute之间的元数据和数据集成打通。
从2023年开始进入下一个阶段。这个阶段的一个特征是开放架构——我们希望数仓是开放的、多元的。在数仓存储层提供了MaxCompute Storage API,第三方的计算引擎可以直接以原生、底层、高吞吐的方式访问数仓里的数据。过去数仓是为性能优化设计的,但今天不再封闭。同时我们也提出了Data+AI的解决方案,稍后会进一步解析。
MaxCompute的核心形态是完全Serverless。上图来自Gartner的分析报告,Serverless分很多级别,体现在资源共享力度的不同。从最原始的机器资源共享,到操作系统层面、容器层面、应用层面、租户层面的共享——每提高一层共享力度,对服务提供方的技术难度是指数级提升,但对用户来说收益越来越大。资源复用得好,整个服务的成本就能降得足够低,给用户更便宜的计算服务。当然,这对资源隔离要求更高,系统升级也更难。
MaxCompute从设计之初就是Serverless定位——只有把运维效率解决好、资源利用率提上去,才能提供有竞争力的数据计算服务。除了成本,另一个好处是弹性。尤其机器学习场景,很多时候只有部分时段有大量资源需求,如果采购一台机器大部分时间闲置,就是巨大浪费。所以机器学习对Serverless的诉求非常强。
接下来聊聊Data+AI的解决方案。MaxCompute针对AI场景的创新,主要体现在这几个方面:
- 数据管理层:数仓擅长处理结构化数据,但机器学习场景有大量非结构化数据、文件数据、图像数据等。我们在非结构化数据管理上做了创新,引入了Object Table这种新型表类型。
- 计算框架:推出了面向Python开发的分布式执行框架MaxFrame。过去数据平台主要用SQL接口开发,但数据科学家最习惯用Python和各类Python开源工具。通过MaxFrame,MaxCompute提供了SQL+Python双引擎能力,Python成为数据平台的一级开发语言。
- 交互式Notebook开发环境:这是AI同学非常喜欢的开发环境,可以在里面做交互式验证和作业分享。
- 镜像管理:Python开发中版本管理、镜像打包等一系列工程问题,也是效率的关键。
数据管理能力的演进,可以分成几个阶段。
第一阶段解决联邦问题。当数据交互双方使用不同引擎时,数据能不能兼容?能不能不搬迁就实现联邦查询?我们希望以联邦为中心,打通元数据管理,给用户统一的元数据视图和权限管理。
第二阶段,光有联邦还不够,还希望不同存储格式能放在湖上,提供一份数据多引擎的能力。所以做了湖仓一体,提高数据易用性,提供原生查询和元数据管理能力。
第三阶段,越来越多用户提出非结构化数据管理的需求。大量非结构化数据作为输入,给Python库做向量化转化,但这些文件背后缺乏元数据管理能力,也很难做分布式计算。因此我们做了Object Table来解决这个问题。
Object Table是一种新的表类型,专门处理非结构化数据。它存储的是非结构化数据的元数据,而不是数据本身——包括文件路径、文件名、文件大小、更新时间等,还有不少可扩展的tag值。
基于这些元数据,可以做很多提升开发效率的事情。比如有1000万个PDF文件,希望平台并行处理这些文件、从中抽取文本。一种简单做法是一个文件启动一个进程,但1000万个文件就要启动1000万个进程,调度开销太大。如果有些文件可以跳过——比如太小的不打开、很久没动过的可以忽略——那有很多需要对元数据过滤的场景。过去没有元数据信息很难做,现在表里有了元信息就可以处理。
还有并行化处理的问题。一个进程处理一个文件,还是一个进程处理10个文件?对吞吐的影响非常大。过去没有元信息很难做,现在有了元信息,worker可以判断:假设一个worker能处理100MB数据,就可以把100MB数据以批量的形式输入给一个进程worker并行处理,整体吞吐量会有本质性提升。这也是工程化中很常见的做法。
除了元数据管理,还有很多性能优化,比如海量小文件、碎片文件处理有几十倍的提效,单一大文件的IO访问也做了提效。
第二大创新是MaxFrame,把Python的开发体验做到原生化。我们希望给用户的心智是:在单机上本地开发的Python程序,基于主流的Pandas接口写的,可以100%透明地迁移到MaxFrame平台上,享受平台上可扩展的计算算力。MaxFrame提供并行化计算能力。
用户写的Python code并不是针对分布式场景,而是单机场景。但数据输入来自MaxCompute表,MaxFrame会将算子并行化,运行在不同分布式节点上。这意味着以前在单机上跑几十个小时的Python作业,现在可能只需要几十分钟甚至更快。MaxFrame的核心理念就是:让用Pandas接口开发的数据分析、数据加工程序,能无缝、透明地迁移到大数据平台上。同时平台与MaxCompute底层数据原生打通,可以高吞吐、高效率地访问所有数据——不只是读,也包括写。
上图左侧是Pandas算子——表连接、关联、过滤、聚合等,几乎所有常见的数据分析Pandas算子都支持。右边是机器学习平台数据处理部分的55个算子——大量文本处理、文本过滤、文本去重、文本计数等,都是MaxFrame原生支持的。这些算子背后都做了性能和可扩展性支持,用起来非常简单。
这里有个对比例子。左侧是开源的RedPajama,在大模型场景下,端到端从数据采集加工到产出结果,七八个环节,每个环节有不同算子。以前单机运行,跑完整个流程需要59个小时。转成MaxFrame之后,仅用1.3小时就跑完了,效率提升非常明显。
Python开发非常依赖版本管理和镜像管理。一份作业里可能依赖几十个不同的library。所以我们做了一套镜像管理方案,包含内置镜像和自定义镜像。内置镜像把很多主流的常见数据分析、数据加工用到的Python library都内置了,用户直接引用就行。
讲完加工环节,再聊聊数据服务环节,以向量检索服务为例。这两年向量数据库特别火,但业界一直有个困惑:每家公司是应该采购一个专属的向量数据库,还是选一款带有向量扩展能力的通用分析数据库?我们看到主流的云厂商大多选了后者——在数据库里增加向量化检索能力,和原生的OLAP能力结合起来,场景更丰富、开发更易用,用户门槛也更低。阿里云也是这个思路。
Hologres是一款分布式高性能OLAP引擎。2020年,Hologres与达摩院合作,把高性能的向量化引擎Proxima集成到SQL引擎中,提供SQL查询接口。Proxima性能优异、精度高、计算效率快,内置多种检索算法。
Proxima和Hologres结合在一起,能把Hologres的强大性能充分发挥出来。Hologres面向高并发、低延迟场景设计,性能可以做到毫秒级响应。同时易用性也很好——不需要学新接口,直接用SQL,数据同学非常容易上手。
向量这件事其实不复杂——把文本、图片等转化为向量数组,存在数据库表的一个字段里,Hologres在底层自动构建各类向量索引。向量计算广泛应用在推荐引擎、大模型推理等场景。
数据库和向量融合的好处在哪里?以前向量引擎只能做向量查询,数据库只能做结构化查询。现在两者合在一起,既可以做结构化过滤,也可以做向量化检索。写SQL语句变得很简单——很多以前必须在专业向量数据库里做的事,现在一个通用数据库就搞定了。一个SQL就能实现向量检索、过滤、排序、去重等操作。真正实现了“一个引擎、一份数据、多个场景”。
以上说的是数据平台如何为AI提供支持,是Data for AI的视角。反过来,AI平台怎么让数据平台变得更好用?今天所有数据分析都在从BI演化到BI+AI的场景。
Copilot从去年开始成为主流,NL2SQL是常见场景——帮用户写SQL、找表、更容易地诊断SQL错误。阿里云推出了DataWorks Copilot,工程师把大量SQL语料喂给Copilot模型,希望产出好用的、更智能的SQL Copilot能力。
除了写SQL的开发阶段,分析阶段更为重要。DataWorks和DataV也在合作实现增强分析——过去以经验为主的分析范式,正在转化为由机器做推断。增强分析可以自动生成各种洞察、不同的报表、不同的视图、不同的看数角度。
---
## 03 Data+AI场景实践分享
最后通过一个具体场景,来看看数据平台怎么用。
这是通义大模型的一个加工场景的简化版本,主要在处理文本去重。核心环节包括数据采集、读取、处理到模型训练,中间有很多小环节——文本去重、敏感词过滤、版权删除、文本标准化等,依赖了很多不同的Python library。
文本去重的基本流程是:先做分词,然后计算哈希值,再求哈希近邻。
我们的做法是:先把依赖镜像做好管理——这个镜像里用户依赖了很多第三方library,不同Python版本、不同library版本,大家需要共享的开发环境。所以第一步是做镜像管理,把这些依赖镜像做成团队内可共享的。
之后是开发环节。右侧是一段demo代码,总共不超过100行。初始化依赖4-5行代码——初始化框架资源、身份认证,然后几行代码做数据过滤,再几行做分词,背后用的是Pandas开发接口,里面有各种数据转换逻辑。这100行代码,可以跑在几乎无限扩展的计算平台上。我们希望的效果是:用小代码快速迭代的方式,在规模化计算平台上处理规模化问题。至于分布式怎么调度、怎么容错、数据怎么切分、怎么做并行化——大量类似的工程细节都由底层大数据平台完成,效率提升非常明显。
如果不喜欢写代码,也可以用拖拽的方式。平台提供了可拖拽的pipeline组合方式,把整个计算流程中不同算子拖拽组合在一起就行。
从通用场景来看,绝大部分性能提升在70%到90%之间,数据量越大,提升越明显。同时环境准备方面,我们反复强调工程一定要提效率——效率不一定只是计算效率,开发、调试、环境准备往往会占用大量精力。我们希望通过平台来减少这部分工作量,实际效果也相当不错。
最后总结一下大数据AI一体化的工作。这次分享没有专门讲大数据做什么,也没有专门讲AI做什么,更多是在讨论二者如何更好地集成。阿里云大数据平台MaxCompute做了非结构化元数据管理,支持Python开发语言,让Python可以跑在并行化运行环境里,还有大量IO优化、调度优化,提供了Notebook交互式开发环境和镜像管理能力。这些工程化能力实现之后,大数据和AI之间实现了数据一体化、权限一体化和开发界面一体化。通过这些一体化,可以让AI同学更熟悉数据平台,也让数据平台同学能更快上手AI应用。这正是我们希望实现的效果。
**以上就是本次分享的内容,谢谢大家。** 
-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
免费影视剧APP推荐
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
好用的手环阅读app下载安装
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
1 钉钉 7.6 上新:全新 AI 搜索、AI 助理来了 05-31
-
2 AI Agent:你的智能办公搭子,越用越懂你的亲密伙伴 05-31
-
3 智慧社区也用人工智能了 05-31
-
4 使用AI生成PPT模型,创新力与便利性的双重结合 05-31
-
5 使用AI生成表格图片,再也不用担心繁琐的编辑工作 05-31
-
6 使用AI技术提高表格处理效率的趋势 05-31
-
7 新华读报|人工智能正以五种方式改变航空业 05-31
-
8 未来产业四大展望:2026年迎产业化关键跨越 05-31
-
10 原来我们可以使用Skills+Github做这么有趣的项目 05-31



