字节跳动自研LPU芯片聚焦AI推理,对标Groq打造国产
来源:互联网 更新时间:2026-05-30 17:00
人工智能推理算力需求持续走高,国内芯片研发的路线图正在悄然调整——从传统GPU转向以中央处理器为核心的新思路。最新消息显示,字节跳动已经悄悄启动了自研CPU项目,而且瞄准的并不是常规处理器,而是逻辑处理单元(LPU)这种新型芯片。
一位长期跟踪行业动态的海外分析师透露,字节跳动正与国内一家阻变存储器(RRAM)企业深度合作,试图打造一款对标Groq LPU的技术方案。这个消息值得关注,因为它意味着头部玩家已经开始认真押注LPU这条赛道。
要知道,过去不少人觉得LPU只能在小众场景里跑跑,但字节跳动的动向说明,这种专为大语言模型优化的张量处理架构,正在成为全球科技巨头争相布局的关键方向。LPU在公众认知里远不如GPU或TPU那样普及,不过最近一次出圈是今年三月——某国际厂商在年度技术大会上发布了LPU30芯片。需要说明的是,这款芯片并非他们自研的,而是去年底花了200亿美元从Groq那里拿到的技术授权。
200亿美元砸下去,背后是LPU不可忽视的技术价值。Groq的创始人乔纳森·罗斯,正是十年前谷歌TPU项目的核心负责人之一。2016年,他带着多位TPU骨干一起出来创办了Groq,目标就是打造面向AI推理的专用硬件。从根上看,LPU和通用型GPU的思路完全不同——它从底层架构出发,全面适配大语言模型的计算特征。
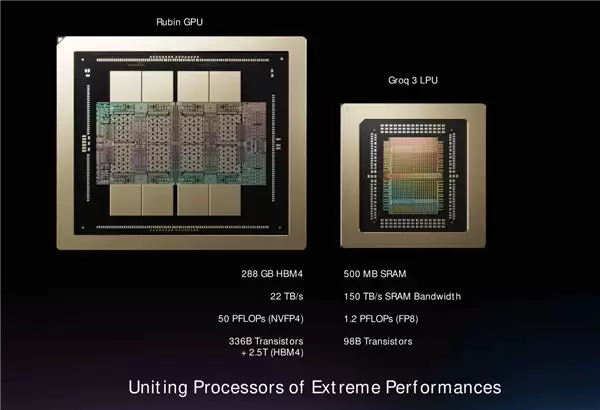
实测数据挺有说服力:LPU的推理速度可以达到H100 GPU的十倍,而单位算力成本只有后者的十分之一。这恰好切中了企业对实时性和低延迟AI服务的痛点。拿LPU30来说,单颗芯片集成了500MB SRAM缓存,晶体管规模达到980亿,FP8精度下算力1.2 PFLOPS。峰值AI算力可能还没超过新一代GPU,但内存带宽高达150 TB/s——相比之下,当前主流HBM4标准才22 TB/s,差距显而易见。
后续推出的Groq 3 LPU芯片采用了模块化部署方式,以Groq 3 LPX机架为载体,单机架能塞下256颗LPU30,总缓存容量128GB,内存总带宽飙到40 PB/s,芯片间互联带宽也达到640 TB/s。看得出,LPU不是要和GPU拼绝对算力,而是在数据吞吐、访问延迟这些影响推理效率的关键维度上实现数倍跃升,从而大幅改善AI服务的响应质量和运行经济性。
如果字节跳动真能把类LPU芯片搞出来并且落地,用户端体验可能会有质的飞跃。举个例子,现在大家熟悉的智能助手产品,虽然交互挺自然,但在复杂任务理解和多步推理上还有提升空间——说白了,背后就是推理算力资源不够。一旦引入LPU级别的硬件支持,运营成本能降下来,产品的理解力、响应力和任务执行能力也会上一个台阶,智能化潜力才能真正释放出来。
-
下饭影视APP下载安装指南
-
灵宝派对手游下载安装地址推荐
-
和平精英如何做到压枪稳-和平精英怎样才能压枪稳
-
下载浏览器app下载安装选择推荐
-
初中英语同步课文跟读APP推荐|免费下载高口碑跟读软件排行榜
-
BuuPo官网在哪下载 最新官方下载安装地址
-
4D采矿者官网在哪下载 最新官方下载安装地址
-
阅读app安卓版下载推荐
-
碎片人偶Vragmeet官网在哪下载 最新官方下载安装地址
-
免费影视剧APP推荐
-
Elysium Above 履云录官网在哪下载 最新官方下载安装地址
-
喧哗番长乙女 2nd Rumble !!官网在哪下载 最新官方下载安装地址
-
纸嫁衣9官网在哪下载 最新官方下载安装地址
-
萌神契约手游下载安装
-
儿子穿新中式现身大会堂 马斯克罕见用中文回应:他正在学习普通话
-
好用的手环阅读app下载安装
-
人声接近真人!OpenAI一口气更新三款超强语音AI
-
名单曝光!库克、马斯克等将随团到访中国 黄仁勋不在其中
-
短视频软件推荐
-
苹果macOS 27将优化界面设计并测试AI驱动的Safari标签页自动分组功能
-
1 北京建成最大具身智能训练基地,120台人形机器人同训真实 05-30
-
2 神鬼寓言延期至2027年2月发售,避让圣诞档期激战,聚焦 05-30
-
3 Claude Opus 4.8发布:一句指令生成可运行3 05-30
-
4 冰镇碳酸饮料解渴不等于补水:科学饮水需看水合指数与成分 05-30
-
5 崖山数据库分布式版获安全最高认证,全栈自主可控达国际领先 05-30
-
6 AI落地催生老科技价值重估:英特尔、康宁等传统巨头重获A 05-30
-
7 美资在华投资逆势增长24.5%,高技术与绿色领域成新热点 05-30
-
8 007:初露锋芒全球热销:首发24小时售150万套,中国 05-30
-
9 英特尔发布ATX12VO V3电源规范:单12V输出+P 05-30
-
10 雷曼:起源或将推出4K/60帧增强复刻版,官方尚未正式确 05-30



