X平台疯传!这个国产开源模型,把信息图生成整明白了|附实测
来源:互联网 更新时间:2026-05-30 15:08
今年4月底,GPT-Image 2一发布,信息图生成的热度就被彻底点燃了。从书籍摘要到商业报告,那些过去非得设计师出马才能搞定的复杂版面,如今AI批量生产,速度惊人。“AI信息图”也迅速成了内容创作领域最出圈的话题之一。
不过,热度背后有个现实问题摆在那里:GPT-Image 2是闭源的,按Token计费,每百万输出Token就要30美元。对于那些需要本地部署和二次开发的团队来说,这显然不是一个可以长期依赖的选项。
“有没有可商用的开源替代方案?”成了开发者社区里高频出现的提问。正是在这个节骨眼上,商汤科技在4月底开源的SenseNova U1进入了越来越多开发者的视野,并在X平台上引发了不少讨论。
一个抛弃了“翻译思维”的模型
SenseNova U1采用的是商汤自研的NEO-unify架构。它直接丢弃了传统图像模型必备的VAE和视觉编码器,把像素和文字放到同一个表征空间里进行原生建模。换句话说,模型不再需要“翻译”图像,而是同时用两种语言思考——这从根本上解决了压缩带来的细节丢失和噪声问题。
Hugging Face中国开发者社区的工作人员Adina Yakup评价说:“这实现了纯粹的端到端像素-文字建模。”
在结构化版面、密集中英文混排、图文精准对齐这些任务上,SenseNova U1的表现相当不错。而这些领域,一直以来都是开源生图模型的软肋。AI博主Rohan Paul直言它“攻克了图像生成最难啃的骨头”。
成本方面同样是个亮点。该模型采用Apache 2.0协议,支持商用,权重全开,单卡就能跑。科技分析媒体Testing Catalog算过一笔账:它的成本大约是闭源方案的十分之一。开源不到一周,社区就已经自发提供了GGUF量化权重,进一步降低了部署门槛。

持续的高关注度之下,商汤最近又进一步开源了SenseNova-U1-8B-MoT-Infographic,直接瞄准信息图这个高需求场景。跟GPT-Image 2这类主流闭源方案相比,它在成本、可部署性和二次开发空间上提供了截然不同的选择。
实际效果究竟如何?我们通过一轮实测来检验一下。
一、七大硬核任务实测:从行程梳理到论文直出
开发者在X平台上讨论SenseNova U1时,反复提到两个核心问题:文字渲染能不能稳?复杂版面能不能控?这其实就是信息图生成最本质的难点。我们把这两个问题放在实测的最前面,先验证基础能力,再延伸到海报、学术文档等更多场景,最后跟GPT-Image 2做个横向对比,看看两款模型的设计取向到底有什么不同。
还原老黄“特种兵式”访华细节
第一个案例是最近很火的黄仁勋同款行程:老黄先去了人民大会堂,然后在北京南锣鼓巷开启特种兵模式,吃炸酱面、喝豆汁儿、买蜜雪冰城、尝稻香村,接着又飞去了台北。
面对这个任务,SenseNova U1信息图增强版先把复杂行程做了完整拆解,按合适的方式安排布局。生成的信息图结构清晰,图文结合也颇为贴切,配上生动形象的描述,现场感十足。

文字渲染方面,在这种高密度场景下,地点、餐品名称和细节都准确呈现,整体可读性很强。这证明了模型在复杂版面对文字有稳定的控制力。
梳理大模型演进时间线
接着,我们让SenseNova U1信息图增强版制作了一张“LLM Architectures 大语言模型架构演进”的横向知识图解。这个案例的难点在于包含大量数据:如何在柱状图中体现110M到1.8T的悬殊比例,如何让表格内的中英双语参数精准对齐,这些都不简单。
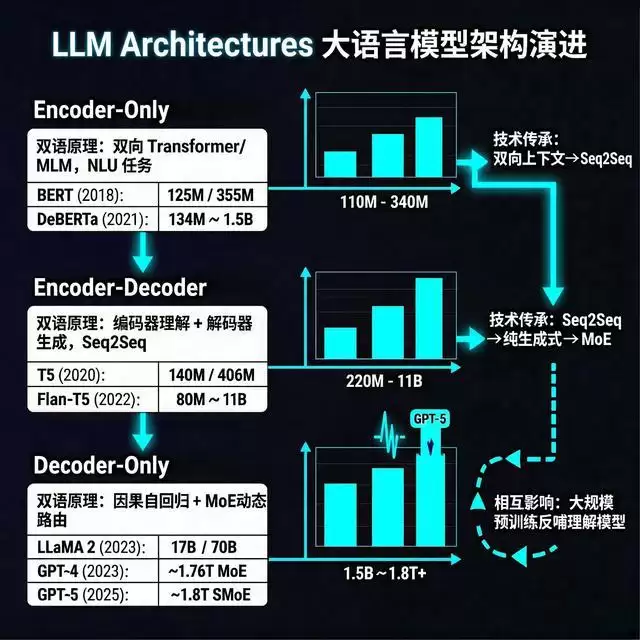
SenseNova U1信息图增强版完美渲染了我们提供的所有文字信息,从BERT到GPT-5,年代和参数规模一目了然,没有出现任何文字乱码。图表部分,柱状图的渲染效果也基本符合数据大小,它还用了箭头来体现模型之间的技术传承。
生成音乐节与诗歌节海报
信息图还有一个非常常见的用法:海报生成。跟知识图解对数据精度的严苛要求不同,海报更考验模型对视觉冲击力和排版美学的理解。
在音乐节海报任务中,我们要求生成一张以富士山为主要视觉元素的海报。结果令人满意:中央的富士山和舞台元素融合自然,下半部分的演出阵容以网格状整齐排列,12组音乐人的英文名和时间清晰列出。整体信息层级按大标题、日期、阵容的顺序展开,视觉引导流畅。

总体来看,深夜音乐节的氛围感被很好地还原了出来。
在诗歌节海报任务中,我们在提示词中特别强调了“中间留白约占画面40%”以及“呼吸感极强”。模型准确理解了这些要求,没有为了追求视觉效果而塞入多余装饰,严格遵循了克制的原则。

它选择了深色衬线字体搭配米色纸张纹理,画面气质沉静。左下角的竖排小字与右下角线描月亮的构图,精准捕捉到了东方留白诗意与现代排版的平衡。这种对“少即是多”的理解能力,在文生图领域并不多见。
SenseNova U1信息图增强版在执行精准排版指令时展现了不错的执行力,生成的画面既能看,也能用于实际宣发场景。
直出一页学术论文
最后,我们考验了它在办公场景的应用。这类场景要求模型精准理解文档的常见格式,并准确渲染所有文字。
第一个案例是Q2业务回顾的演示文稿单页。SenseNova U1信息图增强版生成了深灰底、左侧竖排标题、右侧进度条的分栏结构。中英文副标题右对齐到位,进度条上“Revenue 128%”标注清晰,底部页码和公司名摆放工整。
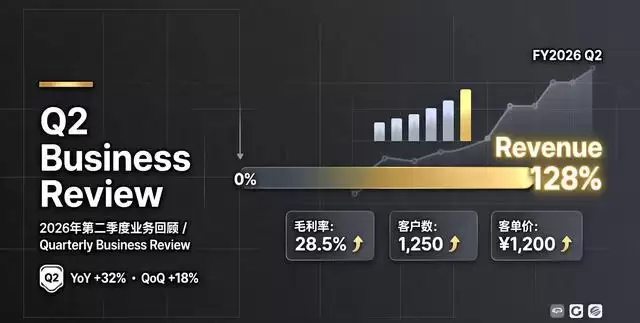
处理这类商务页面时,模型对版面的留白控制得很舒适,没有多余的装饰元素去干扰信息层级,重点数据一目了然。
第二个案例是生成高密度的论文页面。核心难度在于对复杂视觉元素与严谨逻辑关系的精确控制。提示词要求按arXiv风格渲染,并符合严格的学术排版规范。
最终,SenseNova U1信息图增强版准确输出了完整的页面排版,格式清晰、段落完整,复杂的数学公式也没有出现结构性错误。在文字密度极高、格式复杂的情况下,整体呈现出可直接使用的完成度。

最后一个案例是难度拉满的高密度中文小字——展示一家企业的品牌运营逻辑和市场表现全景解析。SenseNova U1信息图增强版不仅准确渲染了几乎所有中文小字,排版也清晰易读。
总体来看,SenseNova U1信息图增强版在信息图任务上展现了不错的版面控制力和复杂指令遵循能力。它有潜力成为内容创作与办公场景中得力的视觉工具。
二、与GPT-Image 2横向对比:两种不同的设计取向
X平台上有不少网友把SenseNova U1信息图增强版与GPT-Image 2放在一起比较。我们也做了对照测试,看看这两个模型在实际任务中有何异同。
分镜生成:跑酷动作序列
第一个案例聚焦于当前火爆的分镜生成玩法。我们要求两个模型分别生成一段跑酷动作序列:在一栋未完工的灰色混凝土建筑内,一名运动员以动作捕捉剪影的形式,完成精准跳跃、墙跑和落地翻滚等一系列连贯动作。
GPT-Image 2先交出结果:

SenseNova U1信息图增强版随后完成生成。
从视觉质感与逼真度来看,GPT-Image 2生成的光影、材质、环境氛围比较逼真,富有视觉冲击力。而SenseNova U1信息图增强版则偏向概念化,更强调动作路径和图形化表达。
但说到信息呈现与分镜实用性,SenseNova U1信息图增强版的结果专业且清晰。它将每个镜头细致拆解为:镜头语言、动作、视觉特效。拿到这个分镜脚本,基本就可以开始制作了。相比之下,GPT-Image 2的结果虽然看起来很酷、很科幻,但缺乏具体的制作指令,实用性稍逊一筹。
复古航海图:信息图生成
在另一个信息图生成测试中,我们为两个模型输入了同一份复古航海图风格的提示词:要求生成一张横版信息图,以做旧纸张为基底,用虚线航线串联起从“创意萌芽”到“产品上市”的六个阶段岛屿,并标注风险暗礁、资源漩涡等危险标记。GPT-Image 2与SenseNova U1信息图增强版再次展现出不同的设计取向。
GPT-Image 2延续了艺术化取向,较好地还原了做旧纸张纹理、手绘风格地标和古典装饰元素,整体沉浸感强;但细节繁复,字号较小,阅读效率不高。
SenseNova U1信息图增强版则选择弱化了厚重纹理,视觉负担更轻,信息获取更直接,更契合商业图表的高效传递需求。
综合这两个案例,两款模型在信息图生成上的分化清晰可见。GPT-Image 2是“视觉派”,擅长通过光影和材质打造具有冲击力和情绪的视觉作品。但在需要精确拆解逻辑、清晰传递密集信息的场景中,它往往过于重视觉而轻信息,导致可读性下降。SenseNova U1信息图增强版则更像是“生产工具派”:它优先保障信息的结构清晰与获取效率,短板在于视觉质感和稳定性仍有提升空间。
三、回到开发者的问题:架构、部署与真实价值
实测结果回应了X平台上那些讨论的核心判断,但也带来了一些值得深挖的新问题:为什么能用8B参数做到这些?开发者真正部署时会面临什么成本?它在哪些场景下是可靠的生产工具,在哪些场景下还需要谨慎?
8B参数的秘密:NEO-unify架构
作为一款仅有8B参数的大模型,尺寸并不是SenseNova U1系列模型唯一的特点。过去,多模态大模型长期受困于“理解”与“生成”的二分——通过视觉编码器看懂图像,再经由变分自编码器生成图像,中间依靠适配器连接。这种拼接式架构就像“讲不同语言的工作组”,信息在模块间来回传递,不仅损耗大,更让模型不得不依赖堆参数来弥补性能损失。
商汤的SenseNova-U1系列模型从根本上解决了这个难题——它采用自研的NEO-unify架构范式,在单一模型中原生统一了多模态理解、推理与生成,真正将图像和文本放到同一个表征空间中直接建模。
在此前发布的SenseNova-U1基础上,商汤专门强化了信息图增强版的能力。为了避免通用理解能力在生成能力提升的过程中退化,他们用高质量数据延长了MT训练阶段,在MT与SFT阶段优化了理解与生成任务的数据配比,在RL阶段进一步打磨了奖励设计。最终,增强版在信息图相关基准上实现了显著提升:在BizGenEval任务中,较原版模型提升了6.8分;在IGenBench的Q-ACC测试(该基准用于评估信息图是否同时满足文本、图表、数据与结构等多重要求)中,增强版较原版更是大幅跃升了18.2分。
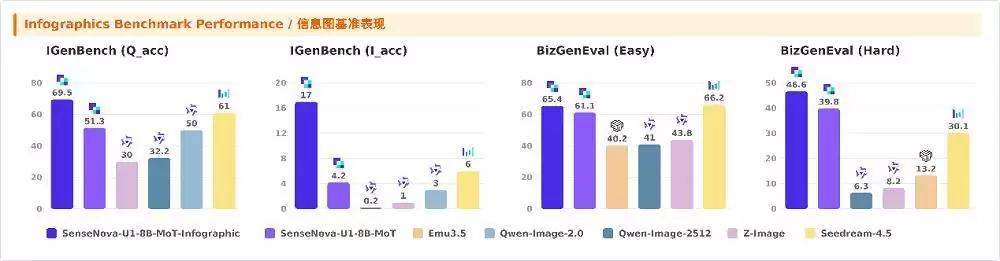
统一架构还赋予了SenseNova U1信息图增强版更丰富的任务边界:它不只是一个生图工具,还可以完成多类型任务,让内容创作整个链路都能在一个模型内闭环。
部署成本:一张消费级显卡就够了
在上述信息图和视觉理解任务中,SenseNova U1信息图增强版都展现了扎实的实力。而更值得开发者关注的是,这份实力并非以高昂的算力或API调用成本为代价。
作为一款Apache 2.0协议全开源、支持商用的模型,它支持轻量化的本地部署。本次实测中我们选择了一张RTX 5880显卡(48GB显存),实际跑下来显存占用大概30多GB。我们还尝试将显卡显存调整到24GB、8GB,结合虚拟显存后,这些配置也能成功跑出结果。在RTX 5880配置下,生成一张信息图的时间大概在70秒左右。GGUF量化后的模型则适用于约10~12 GB显存的消费级显卡。
这让SenseNova-U1系列模型具备了很高的性价比。以GPT-Image 2为代表的主流闭源模型采用按Token计费模式,每百万输出Token价格高达30美元,生成一张高分辨率信息图的估算成本在0.005美元至0.4美元不等。单张调用似乎不贵,但对于日均生成上千张图像的团队来说,成本压力会迅速累积。相比之下,SenseNova-U1系列模型可以在开发者自己的服务器上无限次运行。这种成本结构对团队来说高度可预测,边际成本极低。
结语:统一架构的想象力,远不止信息图
回到最初网友们讨论的焦点,实测给出了答案。SenseNova-U1系列模型的架构突破是真实的——NEO-Unify去掉VAE和视觉编码器之后,模型在信息层级理解和版面控制上确实获得了结构性的改善,而不只是基准分数的跃升。
此外,模型在信息图这一场景的细分能力也十分突出。在行程梳理、海报生成、学术文档等高密度场景中,它能交出可用的结果,并非噱头。
而其开放的姿态和极低的部署成本,让这种能力不再只是实验室里的演示,而是真正有机会落地到开发者自己的产品和工作流中。
当然,极高密度文字场景下偶发的乱码、视觉质感与GPT-Image 2之间的差距,都是它还在打磨的空间。但一个8B的开源模型,能把这场对话推进到这里,本身已经说明了一件事:统一架构的想象力,远不止信息图。
-
摩托车活塞环性能如何
-
ThinkBook系列最新价格全解析:2026年选购避坑与实时询价指南
-
GPT5.6惨遭切脑,Fable 5回归要变弱鸡版?
-
Ondo将于今日上线股票永续合约
-
电视剧《罗曼诺夫后裔》剧情介绍
-
暗黑4S14野蛮人终局BD攻略
-
区块链OTC交易所有哪几家比较正规?
-
什么是山寨币?山寨币指数如何查看?全球前10大山寨币盘点
-
Binance新增15种bStocks代币化证券为杠杆抵押资产
-
全球十大加密货币APP v3.11.5正版下载
-
GLM-4.5发布,全网最全测评和使用教程来了!
-
洛的网名三字男生霸气(精选100个)
-
本周比特币行情预判:BTC后市的三种推演与两强对决
-
剑侠世界3雪峰论剑怎么打-剑侠世界3雪峰论剑打法介绍
-
Meme币DOGS今晚上线!开局就解锁91%代币是否带来风险?
-
五千元以下的笔记本几乎消失!经销商:至少一年看不到涨价尽头
-
姓徐和李取网名男生霸气(精选100个)
-
25年来最惨单月 微软市值本月重挫近4万亿:押注AI也没赢麻
-
超长高标准质保+总部直保售后体系:小牛真实售后体验大起底
-
比特币守住关键支撑,HYPE市值升至第九并反超DOGE
-
3 李开复:开源模型是实现“AI主权”的更优路径 06-08
-
6 留给开源模型的时间,就剩6个月? 07-15
-
8 国产视觉AI老大,用一款开源模型宣告“缝合怪”时代终结 07-17



